Recognition: no theorem link
Skill Drift Is Contract Violation: Proactive Maintenance for LLM Agent Skill Libraries
Pith reviewed 2026-05-13 07:25 UTC · model grok-4.3
The pith
Skill drift in LLM agent libraries is contract violation, detected precisely by extracting and validating role-bearing environment assumptions from skill documents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
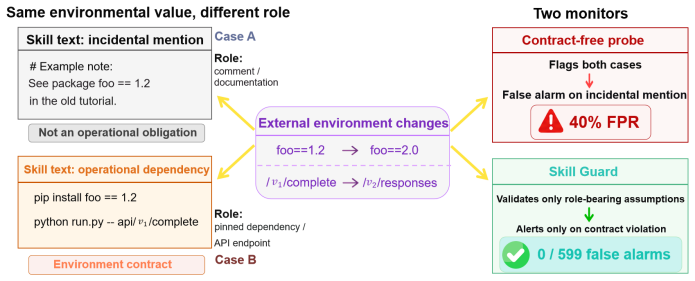
Skill drift is contract violation. SkillGuard extracts executable environment contracts from skill documents and validates only the role-bearing assumptions within them against known or live conditions, converting noisy change detection into a precision-first maintenance signal that achieves zero false alarms over 599 no-drift cases, 100 percent precision in known-drift verification, and 86 percent conservative precision on live drift across 49 real skills while raising one-round repair success from 10 percent to 78 percent.
What carries the argument
SkillGuard, which extracts executable environment contracts from skill documents and validates only role-bearing assumptions against known or live conditions.
If this is right
- Contract-free CI probes produce 40 percent false positives while the contract-based method raises zero false alarms over 599 no-drift and hard-negative cases.
- In known-drift verification the method reaches 100 percent precision and 76 percent recall with the strongest backbone.
- Over 49 real skills the method discovers live drift with 86 percent conservative precision.
- Violated contracts localize the exact assumption that failed, raising one-round repair success from 10 percent to 78 percent.
- An 880-pair benchmark for skill degradation is released to support further evaluation.
Where Pith is reading between the lines
- The contract view could be applied to other reusable components such as prompt templates or tool descriptions that also reference external state.
- Live validation might be combined with automated rollback or version pinning to reduce manual intervention further.
- The released benchmark could become a standard testbed for comparing drift detectors across different agent frameworks.
Load-bearing premise
Executable environment contracts can be accurately and completely extracted from existing skill documents without missing critical dependencies or misinterpreting role-bearing statements.
What would settle it
A documented skill that contains an unextracted dependency or mislabeled assumption, followed by an undetected live change in that dependency that breaks the skill's function.
Figures



read the original abstract
LLM agents increasingly rely on reusable skill libraries, but these skills silently decay as the external services, packages, APIs, and configurations they reference evolve. Existing monitors detect such changes at the wrong granularity: they observe values, not the role those values play in a skill. A version string in a comment is noise; the same string in a pinned dependency is an operational obligation. We formulate skill drift as contract violation and introduce \sgname{}, which extracts executable environment contracts from skill documents and validates only those role-bearing assumptions against known or live conditions. This distinction turns noisy monitoring into a precision-first maintenance signal. Contract-free CI probes produce 40\% false positives, while \sgname{} raises zero false alarms over 599 no-drift and hard-negative cases (Wilson 95\% CI $[0,0.6]\%$). In known-drift verification, \sgname{} achieves 100\% precision and 76\% recall with the strongest backbone; in a pre-registered study over 49 real skills, it discovers live drift with 86\% conservative precision. Violated contracts also make repair actionable, improving one-round success from 10\% without localization to 78\%. We release \dbname{}, an 880-pair benchmark for skill degradation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that skill drift in LLM agent skill libraries can be formulated as contract violation. It introduces SkillGuard, which extracts executable environment contracts from skill documents and validates only role-bearing assumptions against known or live conditions. This yields zero false positives over 599 no-drift cases (Wilson 95% CI [0, 0.6]%), 100% precision and 76% recall in known-drift verification, 86% conservative precision in a pre-registered 49-skill study, and improved one-round repair success from 10% to 78%. A benchmark of 880 skill-degradation pairs is released.
Significance. If the extraction of executable contracts proves accurate and complete, the work provides a meaningful advance in proactive maintenance for LLM agents by converting noisy value monitoring into precise, actionable signals. Credit is due for the concrete metrics (zero false positives, pre-registered study), the released benchmark supporting reproducibility, and the demonstration that violated contracts improve repair localization.
major comments (2)
- [§3] §3 (contract extraction): The zero false-positive rate over 599 cases and 100% precision in known-drift verification both presuppose that the LLM-mediated extraction neither invents spurious contracts nor omits critical dependencies. No ablation study, error analysis, or independent verification of extraction correctness is reported, leaving the central precision advantage ungrounded.
- [§4.3] §4.3 (pre-registered study): The 86% conservative precision on 49 real skills is promising, but without reporting how many contracts were extracted per skill or the distribution of missed vs. spurious contracts, it is unclear whether the result generalizes beyond the tested backbones.
minor comments (2)
- The abstract and introduction should explicitly define the commands or macros for SkillGuard and the benchmark dataset on first use.
- [Table 2] Table 2 (or equivalent results table): Clarify whether the contract-free CI baseline uses the same skill documents or a different monitoring granularity.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments on our work. We address each major comment below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (contract extraction): The zero false-positive rate over 599 cases and 100% precision in known-drift verification both presuppose that the LLM-mediated extraction neither invents spurious contracts nor omits critical dependencies. No ablation study, error analysis, or independent verification of extraction correctness is reported, leaving the central precision advantage ungrounded.
Authors: The referee correctly notes the absence of a dedicated ablation study or error analysis focused on the contract extraction process. Our reported results are end-to-end evaluations of the complete SkillGuard system. The zero false-positive rate across 599 no-drift cases offers supporting evidence that the extraction did not introduce a significant number of spurious contracts, as such inventions would have manifested as false alarms during validation. Similarly, the 100% precision in known-drift tests suggests that the extracted contracts captured the relevant dependencies. Nevertheless, we concur that direct verification of extraction quality would provide stronger grounding for the precision claims. In the revised version, we will incorporate an error analysis of the extraction step, including a manual review of a subset of extracted contracts for accuracy and completeness, as well as an ablation on the impact of extraction errors. revision: yes
-
Referee: [§4.3] §4.3 (pre-registered study): The 86% conservative precision on 49 real skills is promising, but without reporting how many contracts were extracted per skill or the distribution of missed vs. spurious contracts, it is unclear whether the result generalizes beyond the tested backbones.
Authors: We agree that the pre-registered study would benefit from more granular reporting on contract extraction. The manuscript currently presents aggregate metrics without detailing the per-skill contract counts or breaking down the sources of imprecision into missed drifts versus spurious detections. To address this, the revised manuscript will include additional statistics on the number of contracts extracted per skill in the 49-skill study, along with an analysis of the distribution of missed and spurious contracts. This will allow readers to better assess generalizability across different LLM backbones and skill types. revision: yes
Circularity Check
No significant circularity; empirical results independent of inputs
full rationale
The paper defines skill drift as contract violation and presents SkillGuard as an extraction-plus-validation system evaluated on external benchmarks (599 no-drift cases, 49 real skills, known-drift verification). Reported metrics (0% false positives, 100% precision, 86% conservative precision) are direct empirical outcomes from those datasets and live checks, not obtained by fitting parameters to the target quantities or by self-referential definitions. No equations, uniqueness theorems, or ansatzes are invoked that reduce the central claim to its own inputs by construction. The extraction step is a methodological component whose accuracy is tested rather than presupposed tautologically.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Skill documents contain sufficient information to extract executable environment contracts that capture all role-bearing assumptions
Reference graph
Works this paper leans on
-
[1]
Sami Abuzakuk, Lucas Crijns, Anne-Marie Kermarrec, Rafael Pires, and Martijn de V os. Riva: Leveraging llm agents for reliable configuration drift detection.arXiv preprint arXiv:2603.02345, 2026. doi: 10.48550/arXiv.2603.02345
-
[2]
Graph of thoughts: Solving elaborate problems with large language models
Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Michal Podstawski, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadomski, Piotr Nyczyk, et al. Graph of thoughts: Solving elaborate problems with large language models. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 17682–17690, 2024
work page 2024
-
[3]
Agent Behavioral Contracts: Formal Specification and Runtime Enforcement,
Varun Pratap Bhardwaj. Agent behavioral contracts: Formal specification and runtime enforce- ment for reliable autonomous ai agents.arXiv preprint arXiv:2602.22302, 2026
-
[4]
Repairagent: An autonomous, llm-based agent for program repair
Islem Bouzenia, Premkumar Devanbu, and Michael Pradel. Repairagent: An autonomous, llm-based agent for program repair. In2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE), pages 2188–2200. IEEE, 2025
work page 2025
-
[5]
Teaching Large Language Models to Self-Debug
Xinyun Chen, Maxwell Lin, Nathanael Schärli, and Denny Zhou. Teaching large language models to self-debug.arXiv preprint arXiv:2304.05128, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
CodeSpecBench: Benchmarking LLMs for Executable Behavioral Specification Generation
Zaoyu Chen, Jianbo Dai, Boyu Zhu, Jingdong Wang, Huiming Wang, Xin Xu, Haoyang Yuan, Zhijiang Guo, and Xiao-Ming Wu. Codespecbench: Benchmarking llms for executable behavioral specification generation.arXiv preprint arXiv:2604.12268, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
Danny Dig and Ralph Johnson. How do apis evolve? a story of refactoring.Journal of software maintenance and evolution: Research and Practice, 18(2):83–107, 2006
work page 2006
-
[8]
Building guardrails for large lan- guage models.arXiv preprint arXiv:2402.01822, 2024
Yi Dong, Ronghui Mu, Gaojie Jin, Yi Qi, Jinwei Hu, Xingyu Zhao, Jie Meng, Wenjie Ruan, and Xiaowei Huang. Building guardrails for large language models.arXiv preprint arXiv:2402.01822, 2024
-
[9]
Towards Verifiably Safe Tool Use for LLM Agents,
Aarya Doshi, Yining Hong, Congying Xu, Eunsuk Kang, Alexandros Kapravelos, and Christian Kästner. Towards verifiably safe tool use for llm agents.arXiv preprint arXiv:2601.08012, 2026
-
[10]
Michael D Ernst, Jeff H Perkins, Philip J Guo, Stephen McCamant, Carlos Pacheco, Matthew S Tschantz, and Chen Xiao. The daikon system for dynamic detection of likely invariants.Science of computer programming, 69(1-3):35–45, 2007
work page 2007
-
[11]
Lukas Fruntke and Jens Krinke. Automatically fixing dependency breaking changes.Proceed- ings of the ACM on Software Engineering, 2(FSE):2146–2168, 2025
work page 2025
-
[12]
Tingxu Han, Yi Zhang, Wei Song, Chunrong Fang, Zhenyu Chen, Youcheng Sun, and Lijie Hu. Swe-skills-bench: Do agent skills actually help in real-world software engineering?arXiv preprint arXiv:2603.15401, 2026
-
[13]
SoK: Agentic Skills -- Beyond Tool Use in LLM Agents
Yanna Jiang, Delong Li, Haiyu Deng, Baihe Ma, Xu Wang, Qin Wang, and Guangsheng Yu. Sok: Agentic skills – beyond tool use in llm agents.arXiv preprint arXiv:2602.20867, 2026. doi: 10.48550/arXiv.2602.20867
work page internal anchor Pith review doi:10.48550/arxiv.2602.20867 2026
-
[14]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Shuvendu K Lahiri. Intent formalization: A grand challenge for reliable coding in the age of ai agents.arXiv preprint arXiv:2603.17150, 2026. 10
-
[16]
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
Xiangyi Li, Wenbo Chen, Yimin Liu, Shenghan Zheng, Xiaokun Chen, Yifeng He, Yubo Li, Bingran You, Haotian Shen, Jiankai Sun, Shuyi Wang, Binxu Li, Qunhong Zeng, Di Wang, Xuandong Zhao, Yuanli Wang, Roey Ben Chaim, Zonglin Di, Yipeng Gao, Junwei He, Yizhuo He, Liqiang Jing, Luyang Kong, Xin Lan, Jiachen Li, Songlin Li, Yijiang Li, Yueqian Lin, Xinyi Liu, X...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.12670 2026
-
[17]
AgentBench: Evaluating LLMs as Agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, et al. Agentbench: Evaluating llms as agents.arXiv preprint arXiv:2308.03688, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
SkillForge: Forging Domain-Specific, Self-Evolving Agent Skills in Cloud Technical Support
Xingyan Liu, Xiyue Luo, Linyu Li, Ganghong Huang, Jianfeng Liu, and Honglin Qiao. Skill- forge: Forging domain-specific, self-evolving agent skills in cloud technical support.arXiv preprint arXiv:2604.08618, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Structured Security Auditing and Robustness Enhancement for Untrusted Agent Skills
Lijia Lv, Xuehai Tang, Jie Wen, Jizhong Han, and Songlin Hu. Structured security auditing and robustness enhancement for untrusted agent skills.arXiv preprint arXiv:2604.25109, 2026. doi: 10.48550/arXiv.2604.25109
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.25109 2026
-
[20]
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-refine: Iterative refinement with self-feedback.Advances in neural information processing systems, 36:46534–46594, 2023
work page 2023
-
[21]
Applying’design by contract’.Computer, 25(10):40–51, 2002
Bertrand Meyer. Applying’design by contract’.Computer, 25(10):40–51, 2002
work page 2002
-
[22]
Generative agents: Interactive simulacra of human behavior
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. InProceed- ings of the 36th annual acm symposium on user interface software and technology, pages 1–22, 2023
work page 2023
-
[23]
Team et al.Scaling Instructable Agents Across Many Simulated Worlds
Maria Abi Raad, Arun Ahuja, Catarina Barros, Frederic Besse, Andrew Bolt, Adrian Bolton, Bethanie Brownfield, Gavin Buttimore, Max Cant, Sarah Chakera, et al. Scaling instructable agents across many simulated worlds.arXiv preprint arXiv:2404.10179, 2024
-
[24]
Melika Sepidband, Hamed Taherkhani, Hung Viet Pham, and Hadi Hemmati. Rgfl: Reasoning guided fault localization for automated program repair using large language models.arXiv preprint arXiv:2601.18044, 2026
-
[25]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
work page 2023
-
[26]
Pagkratios Tagkopoulos, Fangzhou Li, and Ilias Tagkopoulos. Skillflow: Efficient skill and code transfer through communication in adapting ai agents.arXiv preprint arXiv:2504.06188, 2025
-
[27]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models
Lei Wang, Wanyu Xu, Yihuai Lan, Zhiqiang Hu, Yunshi Lan, Roy Ka-Wei Lee, and Ee- Peng Lim. Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models. InProceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers), pages 2609–2634, 2023
work page 2023
-
[29]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
work page 2022
-
[30]
GraSP: Graph-Structured Skill Compositions for LLM Agents
Tianle Xia, Lingxiang Hu, Yiding Sun, Ming Xu, Lan Xu, Siying Wang, Wei Xu, and Jie Jiang. Grasp: Graph-structured skill compositions for llm agents.arXiv preprint arXiv:2604.17870, 2026. 11
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
Agent Skills for Large Language Models: Architecture, Acquisition, Security, and the Path Forward
Renjun Xu and Yang Yan. Agent skills for large language models: Architecture, acquisition, security, and the path forward.arXiv preprint arXiv:2602.12430, 2026
work page internal anchor Pith review arXiv 2026
-
[32]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[33]
Memento-skills: Let agents design agents
Huichi Zhou, Siyuan Guo, Anjie Liu, Zhongwei Yu, Ziqin Gong, Bowen Zhao, Zhixun Chen, Menglong Zhang, Yihang Chen, Jinsong Li, et al. Memento-skills: Let agents design agents. arXiv preprint arXiv:2603.18743, 2026. A Appendix Overview The appendix provides the evidence needed to audit the claims made in the main paper. Sections B to E specify the contract...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.