Recognition: unknown
The Enforcement and Feasibility of Hate Speech Moderation on Twitter
Pith reviewed 2026-05-10 15:36 UTC · model grok-4.3
The pith
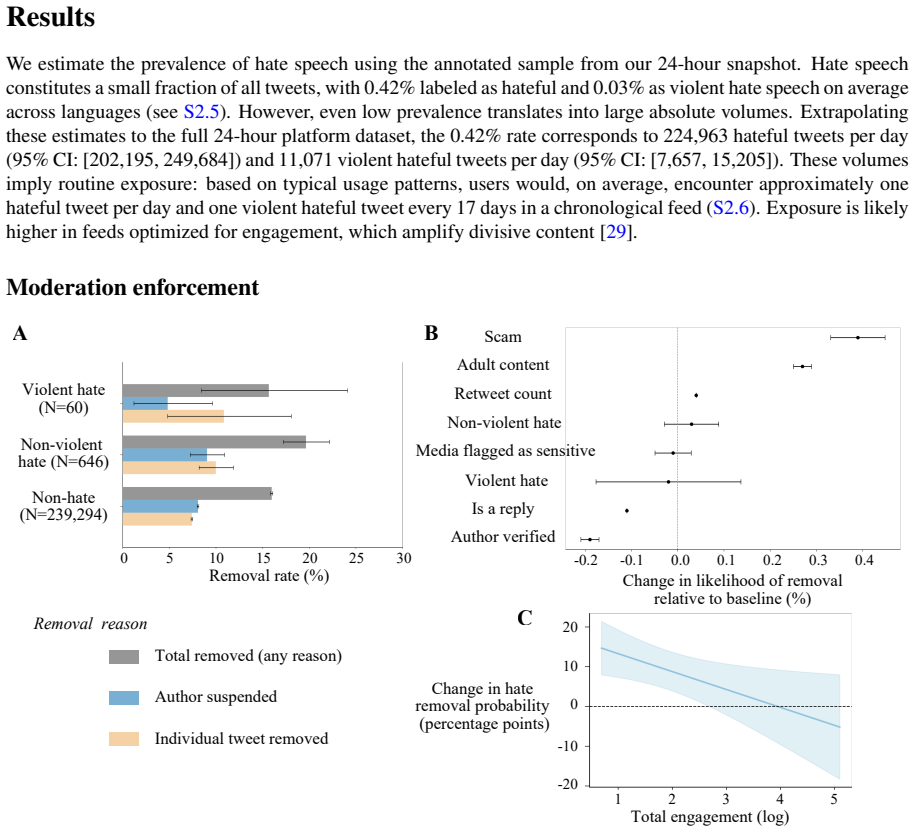
Hateful tweets on Twitter remain online 80 percent of the time after five months and face removal rates identical to non-hateful content.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
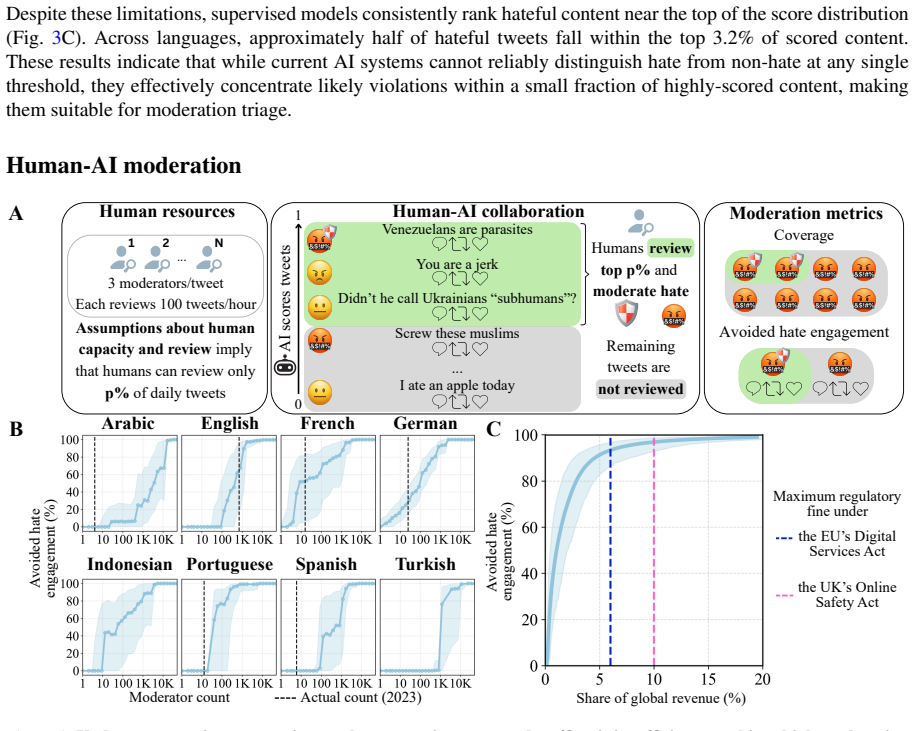
Analysis of a complete 24-hour global snapshot of public tweets, with 540,000 items annotated for hate speech by trained raters in eight languages, shows that 80 percent of hateful tweets remain online five months later, including those containing explicit violent content. Removal probability is statistically indistinguishable between hateful and non-hateful tweets, and neither greater severity nor higher visibility raises the chance of deletion. Simulations of a pipeline that applies automated classifiers only to prioritize items for human review demonstrate that platforms could achieve large reductions in user exposure to hate speech at total operating costs below current regulatory fines.
What carries the argument
A large-scale annotated audit of 540,000 tweets from one global day combined with economic simulations of an AI-prioritized human review pipeline.
Load-bearing premise
The 540,000 annotated tweets drawn from a single 24-hour snapshot accurately represent how hate speech is posted, viewed, and moderated across languages and over longer time periods.
What would settle it
A repeat audit using tweets from a different day or set of languages that finds hateful content removed at substantially higher rates than non-hateful content would contradict the claim of uniform low enforcement.
Figures


read the original abstract
Online hate speech is associated with substantial social harms, yet it remains unclear how consistently platforms enforce hate speech policies or whether enforcement is feasible at scale. We address these questions through a global audit of hate speech moderation on Twitter (now X). Using a complete 24-hour snapshot of public tweets, we construct representative samples comprising 540,000 tweets annotated for hate speech by trained annotators across eight major languages. Five months after posting, 80% of hateful tweets remain online, including explicitly violent hate speech. Such tweets are no more likely to be removed than non-hateful tweets, with neither severity nor visibility increasing the likelihood of removal. We then examine whether these enforcement gaps reflect technical limits of large-scale moderation systems. While fully automated detection systems cannot reliably identify hate speech without generating large numbers of false positives, they effectively prioritize likely violations for human review. Simulations of a human-AI moderation pipeline indicate that substantially reducing user exposure to hate speech is economically feasible at a cost below existing regulatory penalties. These results suggest that the persistence of online hate cannot be explained by technical constraints alone but also reflects institutional choices in the allocation of moderation resources.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a global audit of hate speech moderation on Twitter (X) via a complete 24-hour snapshot of public tweets. It constructs representative samples of 540,000 tweets annotated for hate speech by trained annotators across eight major languages, tracks removal status after five months, and reports that 80% of hateful tweets (including violent ones) remain online with no differential removal likelihood by severity or visibility. Simulations of a human-AI moderation pipeline then assess economic feasibility of reducing exposure, concluding that costs fall below existing regulatory penalties and that persistence reflects institutional resource allocation rather than technical limits.
Significance. If the core empirical patterns hold, the work supplies large-scale observational evidence on enforcement consistency and a practical simulation framework for feasibility, strengthening arguments that moderation gaps are policy-driven. The scale of the annotation effort (540k tweets, multilingual) and explicit cost modeling are notable strengths that could inform regulatory debates. However, the single-snapshot design limits claims about typical behavior.
major comments (3)
- [Methods] Methods / Sampling: The central claims on 80% persistence, absence of differential removal by severity/visibility, and simulation-derived feasibility all rest on a single 24-hour global snapshot of 540k annotated tweets. No multi-period replication, event-window analysis, or stationarity tests are reported to address whether hate-speech volume, reporting, or platform response rates are stable across days, news cycles, or policy changes; this directly affects generalizability of the removal-rate and cost conclusions.
- [Methods] Annotation procedure: The abstract and methods describe annotation by trained annotators across eight languages but report no inter-annotator agreement statistics (e.g., Cohen’s or Fleiss’ kappa), disagreement-resolution protocol, or language-specific reliability checks. Without these, the binary hateful/non-hateful labels used for the removal-rate comparisons and simulation inputs cannot be assessed for measurement error.
- [Simulation] Simulation section: The human-AI pipeline cost estimates (review time, false-positive handling) are calibrated to statistics from the same 24-hour snapshot. No sensitivity analyses varying these parameters or removal-rate inputs are presented, so the claim that costs remain below regulatory penalties is not shown to be robust to plausible deviations from the observed snapshot.
minor comments (2)
- [Abstract] The abstract and introduction could more explicitly state the exact sampling fractions and stratification criteria used to construct the 540k-tweet representative samples from the full snapshot.
- [Results] Table or figure presenting removal-rate breakdowns by severity/visibility should include confidence intervals or standard errors to accompany the reported percentages.
Simulated Author's Rebuttal
Thank you for the referee's constructive comments. We address each major point below with honest responses and proposed revisions to strengthen the manuscript. We maintain the value of the single-snapshot global audit while acknowledging its limits.
read point-by-point responses
-
Referee: [Methods] Methods / Sampling: The central claims on 80% persistence, absence of differential removal by severity/visibility, and simulation-derived feasibility all rest on a single 24-hour global snapshot of 540k annotated tweets. No multi-period replication, event-window analysis, or stationarity tests are reported to address whether hate-speech volume, reporting, or platform response rates are stable across days, news cycles, or policy changes; this directly affects generalizability of the removal-rate and cost conclusions.
Authors: We agree the single 24-hour snapshot limits assessment of temporal stability and generalizability. The design provides a unique complete global cross-section but cannot capture variations across periods. We will revise to add an expanded limitations section with explicit discussion of this constraint, its implications for the 80% persistence and feasibility claims, and suggestions for future multi-period work. We do not claim the results are stationary but argue the evidence remains informative for policy debates. revision: partial
-
Referee: [Methods] Annotation procedure: The abstract and methods describe annotation by trained annotators across eight languages but report no inter-annotator agreement statistics (e.g., Cohen’s or Fleiss’ kappa), disagreement-resolution protocol, or language-specific reliability checks. Without these, the binary hateful/non-hateful labels used for the removal-rate comparisons and simulation inputs cannot be assessed for measurement error.
Authors: We acknowledge that inter-annotator agreement metrics are necessary to evaluate label reliability. The process used trained annotators with detailed guidelines and a consensus-based disagreement resolution protocol. We will add Fleiss' kappa (or Cohen's where pairwise), the resolution protocol, and language-specific reliability checks to the methods section in revision, allowing readers to assess measurement error in the labels. revision: yes
-
Referee: [Simulation] Simulation section: The human-AI pipeline cost estimates (review time, false-positive handling) are calibrated to statistics from the same 24-hour snapshot. No sensitivity analyses varying these parameters or removal-rate inputs are presented, so the claim that costs remain below regulatory penalties is not shown to be robust to plausible deviations from the observed snapshot.
Authors: We agree sensitivity analyses are required to support robustness of the cost-feasibility claims. We will incorporate these in the revised simulation section by varying key inputs (review time, false-positive rates, removal rates) over plausible ranges and showing that costs stay below regulatory penalties under most scenarios. revision: yes
- We cannot perform multi-period replication, event-window analysis, or stationarity tests, as the study used a one-time complete 24-hour global snapshot and new longitudinal data collection is outside the scope of this revision.
Circularity Check
No circularity in observational measurements or simulations
full rationale
The paper's core results derive from direct empirical measurement: a complete 24-hour global tweet snapshot, annotation of 540k tweets for hate speech across languages, and follow-up checks five months later for removal status. Removal likelihoods by severity/visibility are computed from these observed outcomes. The human-AI pipeline feasibility assessment uses explicit cost modeling with stated parameters for review time and false positives, not any fitted parameter renamed as a prediction. No equations, uniqueness theorems, ansatzes, or self-citations are invoked in a load-bearing way that reduces claims to inputs by construction. The derivation chain is self-contained against external benchmarks (observed removal rates and cost arithmetic).
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Bye Bye Perspective API: Lessons for Measurement Infrastructure in NLP, CSS and LLM Evaluation
Closure of the Perspective API exposes structural dependence on a single proprietary toxicity scorer, leaving non-updatable benchmarks and irreproducible results while risking continued reliance on closed LLMs.
Reference graph
Works this paper leans on
-
[1]
A 61-million-person experiment in social influence and political mobilization.Nature, 489(7415):295–298, 2012
Robert M Bond, Christopher J Fariss, Jason J Jones, Adam DI Kramer, Cameron Marlow, Jaime E Settle, and James H Fowler. A 61-million-person experiment in social influence and political mobilization.Nature, 489(7415):295–298, 2012
2012
-
[2]
Yale University Press, 2017
Zeynep Tufekci.Twitter and tear gas: The power and fragility of networked protest. Yale University Press, 2017
2017
-
[3]
Social media and protest participation: Evidence from russia.Econometrica, 88(4):1479–1514, 2020
Ruben Enikolopov, Alexey Makarin, and Maria Petrova. Social media and protest participation: Evidence from russia.Econometrica, 88(4):1479–1514, 2020
2020
-
[4]
Can social media reliably estimate unemployment?PNAS Nexus, 4(12):pgaf309, 12 2025
Do Lee, Manuel Tonneau, Boris Sobol, Nir Grinberg, and Samuel P Fraiberger. Can social media reliably estimate unemployment?PNAS Nexus, 4(12):pgaf309, 12 2025. ISSN 2752-6542. doi: 10.1093/pnasnexus/pgaf309. URLhttps://doi.org/10.1093/pnasnexus/ pgaf309
-
[5]
Survey on the Impact of Online Disinformation and Hate Speech
UNESCO. Survey on the Impact of Online Disinformation and Hate Speech. Tech. report, UNESCO / Ipsos, September 2023. URLhttps://www.ipsos.com/sites/default/files/ct/news/documents/2023-11/ unesco-ipsos-online-disinformation-hate-speech.pdf. Embargoed until 6 November, 4:00pm Paris Time for internal distribution; survey conducted August–September 2023 in 1...
2023
-
[6]
Social media and mental health.American Economic Review, 112(11):3660–3693, 2022
Luca Braghieri, Ro’ee Levy, and Alexey Makarin. Social media and mental health.American Economic Review, 112(11):3660–3693, 2022
2022
-
[7]
Fanning the flames of hate: Social media and hate crime.Journal of the European Economic Association, 19(4):2131–2167, 2021
Karsten M ¨uller and Carlo Schwarz. Fanning the flames of hate: Social media and hate crime.Journal of the European Economic Association, 19(4):2131–2167, 2021
2021
-
[8]
Kleinberg, Ardeth Thawnghmung, and Myat The Thitsar
Jenifer Whitten-Woodring, Mona S. Kleinberg, Ardeth Thawnghmung, and Myat The Thitsar. Poison if you don’t know how to use it: Facebook, democracy, and human rights in myanmar.The International Journal of Press/Politics, 25(3):407–425, 2020. doi: 10.1177/ 1940161220919666. URLhttps://doi.org/10.1177/1940161220919666
-
[9]
Hate speech on social media networks: towards a regulatory framework?Information & Communications Technology Law, 28(1):19–35, 2019
Natalie Alkiviadou. Hate speech on social media networks: towards a regulatory framework?Information & Communications Technology Law, 28(1):19–35, 2019
2019
-
[10]
Elections, institutions, and the regulatory politics of platform governance: The case of the german netzdg
Robert Gorwa. Elections, institutions, and the regulatory politics of platform governance: The case of the german netzdg. Telecommunications Policy, 45(6):102145, 2021
2021
-
[11]
Illusory interparty disagreement: Partisans agree on what hate speech to censor but do not know it.Proceedings of the National Academy of Sciences, 121(39):e2402428121, 2024
Brittany C Solomon, Matthew EK Hall, Abigail Hemmen, and James N Druckman. Illusory interparty disagreement: Partisans agree on what hate speech to censor but do not know it.Proceedings of the National Academy of Sciences, 121(39):e2402428121, 2024
2024
-
[12]
Citizen preferences for online hate speech regulation.PNAS Nexus, page pgaf032, 2025
Simon Munzert, Richard Traunm ¨uller, Pablo Barber´a, Andrew Guess, and JungHwan Yang. Citizen preferences for online hate speech regulation.PNAS Nexus, page pgaf032, 2025
2025
-
[13]
Sarah T Roberts.Content moderation. 2017
2017
-
[14]
Do not recommend? reduction as a form of content moderation.Social Media+ Society, 8(3):20563051221117552, 2022
Tarleton Gillespie. Do not recommend? reduction as a form of content moderation.Social Media+ Society, 8(3):20563051221117552, 2022
2022
-
[15]
Yale University Press, 2018
Tarleton Gillespie.Custodians of the Internet: Platforms, content moderation, and the Hidden Decisions that Shape Social Media. Yale University Press, 2018
2018
-
[16]
Facebook uses deceptive math to hide its hate speech problem.Wired, 2021
Noah Giansiracusa. Facebook uses deceptive math to hide its hate speech problem.Wired, 2021
2021
-
[17]
An end to shadow banning? transparency rights in the digital services act between content moderation and curation
Paddy Leerssen. An end to shadow banning? transparency rights in the digital services act between content moderation and curation. Computer Law & Security Review, 48:105790, 2023
2023
-
[18]
Tweets are forever: a large-scale quantitative analysis of deleted tweets
Hazim Almuhimedi, Shomir Wilson, Bin Liu, Norman Sadeh, and Alessandro Acquisti. Tweets are forever: a large-scale quantitative analysis of deleted tweets. InProceedings of the 2013 conference on Computer supported cooperative work, pages 897–908, 2013
2013
-
[19]
Characterizing deleted tweets and their authors
Parantapa Bhattacharya and Niloy Ganguly. Characterizing deleted tweets and their authors. InProceedings of the International AAAI Conference on Web and Social Media, volume 10, pages 547–550, 2016
2016
-
[20]
Tweet properly: Analyzing deleted tweets to understand and identify regrettable ones
Lu Zhou, Wenbo Wang, and Keke Chen. Tweet properly: Analyzing deleted tweets to understand and identify regrettable ones. In Proceedings of the 25th International Conference on World Wide Web, pages 603–612, 2016
2016
-
[21]
On twitter purge: a retrospective analysis of suspended users
Farhan Asif Chowdhury, Lawrence Allen, Mohammad Yousuf, and Abdullah Mueen. On twitter purge: a retrospective analysis of suspended users. InCompanion proceedings of the web conference 2020, pages 371–378, 2020
2020
-
[22]
How does twitter account moderation work? dynamics of account creation and suspension on twitter during major geopolitical events.EPJ Data Science, 12(1):43, 2023
Francesco Pierri, Luca Luceri, Emily Chen, and Emilio Ferrara. How does twitter account moderation work? dynamics of account creation and suspension on twitter during major geopolitical events.EPJ Data Science, 12(1):43, 2023
2023
-
[23]
The efficacy of facebook’s vaccine misinformation policies and architecture during the covid-19 pandemic.Science Advances, 9(37):eadh2132, 2023
David A Broniatowski, Joseph R Simons, Jiayan Gu, Amelia M Jamison, and Lorien C Abroms. The efficacy of facebook’s vaccine misinformation policies and architecture during the covid-19 pandemic.Science Advances, 9(37):eadh2132, 2023
2023
-
[24]
The diffusion and reach of (mis) information on facebook during the us 2020 election.Sociological Science, 11:1124–1146, 2024
Sandra Gonz ´alez-Bail´on, David Lazer, Pablo Barber ´a, William Godel, Hunt Allcott, Taylor Brown, Adriana Crespo-Tenorio, Deen Freelon, Matthew Gentzkow, Andrew M Guess, et al. The diffusion and reach of (mis) information on facebook during the us 2020 election.Sociological Science, 11:1124–1146, 2024
2020
-
[25]
Ian Goldstein, Laura Edelson, Minh-Kha Nguyen, Oana Goga, Damon McCoy, and Tobias Lauinger. Understanding the (in) effectiveness of content moderation: A case study of facebook in the context of the us capitol riot.arXiv preprint arXiv:2301.02737, 2023. 36
-
[26]
Detection of Abusive Language: the Problem of Biased Datasets
Michael Wiegand, Josef Ruppenhofer, and Thomas Kleinbauer. Detection of Abusive Language: the Problem of Biased Datasets. In Jill Burstein, Christy Doran, and Thamar Solorio, editors,Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, V olume 1 (Long and Short Pape...
-
[27]
2025 transparency report.https://transparency.x.com/en/reports/global-reports/ 2025-transparency-report, 2025
X (formerly Twitter). 2025 transparency report.https://transparency.x.com/en/reports/global-reports/ 2025-transparency-report, 2025. Accessed March 4, 2026
2025
-
[28]
Just another day on twitter: a complete 24 hours of twitter data
Juergen Pfeffer, Daniel Matter, Kokil Jaidka, Onur Varol, Afra Mashhadi, Jana Lasser, Dennis Assenmacher, Siqi Wu, Diyi Yang, Cornelia Brantner, et al. Just another day on twitter: a complete 24 hours of twitter data. InProceedings of the international AAAI conference on web and social media, volume 17, pages 1073–1081, 2023
2023
-
[29]
Smitha Milli, Micah Carroll, Yike Wang, Sashrika Pandey, Sebastian Zhao, and Anca D Dragan. Engagement, user satisfaction, and the amplification of divisive content on social media.PNAS Nexus, 4(3):pgaf062, 03 2025. ISSN 2752-6542. doi: 10.1093/pnasnexus/ pgaf062. URLhttps://doi.org/10.1093/pnasnexus/pgaf062
-
[30]
Out-group animosity drives engagement on social media.Proceedings of the national academy of sciences, 118(26):e2024292118, 2021
Steve Rathje, Jay J Van Bavel, and Sander Van Der Linden. Out-group animosity drives engagement on social media.Proceedings of the national academy of sciences, 118(26):e2024292118, 2021
2021
-
[31]
I missed this one: Someone did get a prompt leak attack to work against the bot, Sep 2022
Twitter. Hateful conduct policy.Twitter, 2022. URLhttp://web.archive.org/web/20220921181521/https://help.twitter.com/ en/rules-and-policies/hateful-conduct-policy
-
[32]
Who moderates the social media giants.Center for Business, 102, 2020
Paul M Barrett. Who moderates the social media giants.Center for Business, 102, 2020
2020
-
[33]
X. Dsa transparency report - april 2024.https://web.archive.org/web/20240710051711/https://transparency.x.com/ dsa-transparency-report.html, April 2024. URLhttps://web.archive.org/web/20240710051711/https://transparency. x.com/dsa-transparency-report.html. Report covers content moderation activities of Twitter International Unlimited Company (TIUC) under ...
-
[34]
Rules enforcement (report 20).Twitter transparency, 2022
Twitter. Rules enforcement (report 20).Twitter transparency, 2022. URLhttps://transparency.twitter.com/en/reports/ rules-enforcement.html#2021-jul-dec
2022
-
[35]
Language disparities in moderation workforce allocation by social media platforms, 2025
Manuel Tonneau, Diyi Liu, Ryan McGrady, Kevin Zheng, Ralph Schroeder, Ethan Zuckerman, and Scott Hale. Language disparities in moderation workforce allocation by social media platforms, 2025. URLhttps://osf.io/preprints/socarxiv/amfws v1. SocArXiv preprint
2025
-
[36]
Frances haugen: ’i never wanted to be a whistleblower
Dan Milmo. Frances haugen: ’i never wanted to be a whistleblower. but lives were in danger’.The Guardian, 2021. URLhttps://www.theguardian.com/technology/2021/oct/24/ frances-haugen-i-never-wanted-to-be-a-whistleblower-but-lives-were-in-danger
2021
-
[37]
Does ai understand arabic? evaluating the politics behind the algorithmic arabic content moderation.Carr Center for Human Rights Policy research publications, 2023
Mona Elswah. Does ai understand arabic? evaluating the politics behind the algorithmic arabic content moderation.Carr Center for Human Rights Policy research publications, 2023
2023
-
[38]
#SaveSheikhJarrah and Arabic Content Moderation
Mahsa Alimardani and Mona Elswah. #SaveSheikhJarrah and Arabic Content Moderation. InPOMEPS Studies 43: Digital Activism and Authoritarian Adaptation in the Middle East, page 7, 2021
2021
-
[39]
Indonesia’s new social media regulations are already reshaping the internet.Rest of World, 2022
Antonia Timmerman. Indonesia’s new social media regulations are already reshaping the internet.Rest of World, 2022. URLhttps: //restofworld.org/2022/indonesia-social-media-regulations/. Accessed: 2025-04-03
2022
-
[40]
The balancing acts: Communicating legitimacy in global speech governance.Social Media+ Society, 11(2): 20563051251340855, 2025
Diyi Liu. The balancing acts: Communicating legitimacy in global speech governance.Social Media+ Society, 11(2): 20563051251340855, 2025
2025
-
[41]
Hate speech detection is not as easy as you may think: A closer look at model validation
Aym ´e Arango, Jorge P ´erez, and Barbara Poblete. Hate speech detection is not as easy as you may think: A closer look at model validation. InProceedings of the 42nd international acm sigir conference on research and development in information retrieval, pages 45–54, 2019
2019
-
[42]
Automated hate speech detection and the problem of offensive language
Thomas Davidson, Dana Warmsley, Michael Macy, and Ingmar Weber. Automated hate speech detection and the problem of offensive language. InProceedings of the international AAAI conference on web and social media, volume 11, pages 512–515, 2017
2017
-
[43]
LongEval: Guidelines for human evaluation of faithfulness in long-form summariza- tion
Kristina Gligoric, Myra Cheng, Lucia Zheng, Esin Durmus, and Dan Jurafsky. NLP systems that can’t tell use from mention censor counterspeech, but teaching the distinction helps. In Kevin Duh, Helena Gomez, and Steven Bethard, editors,Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human La...
-
[44]
Cinoo Lee, Kristina Gligori ´c, Pratyusha Ria Kalluri, Maggie Harrington, Esin Durmus, Kiara L Sanchez, Nay San, Danny Tse, Xuan Zhao, MarYam G Hamedani, et al. People who share encounters with racism are silenced online by humans and machines, but a guideline-reframing intervention holds promise.Proceedings of the National Academy of Sciences, 121(38):e2...
2024
-
[45]
arXiv preprint arXiv:2211.06516 , year=
Vashist Avadhanula, Omar Abdul Baki, Hamsa Bastani, Osbert Bastani, Caner Gocmen, Daniel Haimovich, Darren Hwang, Dima Karamshuk, Thomas Leeper, Jiayuan Ma, et al. Bandits for online calibration: An application to content moderation on social media platforms.arXiv preprint arXiv:2211.06516, 2022
-
[46]
Tackling racial bias in automated online hate detection: Towards fair and accurate detection of hateful users with geometric deep learning.EPJ Data Science, 11(1):8, 2022
Zo Ahmed, Bertie Vidgen, and Scott A Hale. Tackling racial bias in automated online hate detection: Towards fair and accurate detection of hateful users with geometric deep learning.EPJ Data Science, 11(1):8, 2022. 37
2022
-
[47]
Commission fines X C120 million under the Digital Services Act, December 2025
European Commission. Commission fines X C120 million under the Digital Services Act, December 2025. URLhttps://ec.europa. eu/commission/presscorner/detail/en/ip 25 2934
2025
-
[48]
Toxic content and user engagement on social media: Evidence from a field experiment
George Beknazar-Yuzbashev, Rafael Jim ´enez-Dur´an, Jesse McCrosky, and Mateusz Stalinski. Toxic content and user engagement on social media: Evidence from a field experiment. 2025
2025
-
[49]
More speech and fewer mistakes.Meta, January 2025
Joel Kaplan. More speech and fewer mistakes.Meta, January 2025. URLhttps://about.fb.com/news/2025/01/ meta-more-speech-fewer-mistakes/. Accessed: 2025-04-01
2025
-
[50]
Bytedance’s tiktok cuts hundreds of jobs in shift towards ai content moderation.Reuters, October 2024
Rozanna Latiff. Bytedance’s tiktok cuts hundreds of jobs in shift towards ai content moderation.Reuters, October 2024. URLhttps:// www.reuters.com/technology/bytedance-cuts-over-700-jobs-malaysia-shift-towards-ai-moderation-sources-say-2024-10-11/. Accessed: YYYY-MM-DD
2024
-
[51]
Rachel Elizabeth Moran, Joseph Schafer, Mert Bayar, and Kate Starbird. The end of trust and safety?: Examining the future of content moderation and upheavals in professional online safety efforts. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems, CHI ’25, New York, NY , USA, 2025. Association for Computing Machinery. ISBN 979...
-
[52]
Explainability and hate speech: Structured explanations make social media moderators faster
Agostina Calabrese, Leonardo Neves, Neil Shah, Maarten Bos, Bj ¨orn Ross, Mirella Lapata, and Francesco Barbieri. Explainability and hate speech: Structured explanations make social media moderators faster. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V o...
-
[53]
The risks of industry influence in tech research.arXiv preprint arXiv:2510.19894, 2025
Joseph Bak-Coleman, Cailin O’Connor, Carl Bergstrom, and Jevin West. The risks of industry influence in tech research.arXiv preprint arXiv:2510.19894, 2025
-
[54]
We need transparency standards for social media research that involves companies
Georgia Turner, Ian Anderson, and Luisa Fassi. We need transparency standards for social media research that involves companies. Proceedings of the National Academy of Sciences, 122(50):e2501819122, 2025. doi: 10.1073/pnas.2501819122. URLhttps://www. pnas.org/doi/abs/10.1073/pnas.2501819122
-
[55]
Fixing the science of digital technology harms.Science, 388(6743):152–155, 2025
Amy Orben and J Nathan Matias. Fixing the science of digital technology harms.Science, 388(6743):152–155, 2025
2025
-
[56]
’there has to be a lot that we’re missing’: Moderating ai-generated content on reddit
Travis Lloyd, Joseph Reagle, and Mor Naaman. ’there has to be a lot that we’re missing’: Moderating ai-generated content on reddit. Proc. ACM Hum.-Comput. Interact., 9(7), October 2025. doi: 10.1145/3757445. URLhttps://doi.org/10.1145/3757445
-
[57]
Two Contrasting Data Annotation Paradigms for Subjective NLP Tasks
Paul R ¨ottger, Bertie Vidgen, Dirk Hovy, and Janet Pierrehumbert. Two contrasting data annotation paradigms for subjective NLP tasks. In Marine Carpuat, Marie-Catherine de Marneffe, and Ivan Vladimir Meza Ruiz, editors,Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technol...
-
[58]
Tweets from justin bieber’s heart: the dynamics of the location field in user profiles
Brent Hecht, Lichan Hong, Bongwon Suh, and Ed H Chi. Tweets from justin bieber’s heart: the dynamics of the location field in user profiles. InProceedings of the SIGCHI conference on human factors in computing systems, pages 237–246, 2011
2011
-
[59]
Rethinking tabular data understanding with large language models
Manuel Tonneau, Diyi Liu, Samuel Fraiberger, Ralph Schroeder, Scott A. Hale, and Paul R ¨ottger. From languages to geographies: Towards evaluating cultural bias in hate speech datasets. In Yi-Ling Chung, Zeerak Talat, Debora Nozza, Flor Miriam Plaza-del Arco, Paul R¨ottger, Aida Mostafazadeh Davani, and Agostina Calabrese, editors,Proceedings of the 8th W...
-
[60]
Twitter usage statistics (2025)
Rohit Shewale. Twitter usage statistics (2025). GrabOn’s Indulge Blog, February 5 2025. URLhttps://www.grabon.in/indulge/ tech/twitter-statistics/. Accessed: 2026-02-25
2025
-
[61]
Twitter suspension reversals.https://gist.github.com/travisbrown/c966666ad583f760a568e805f36274d4, 2022
Travis Brown. Twitter suspension reversals.https://gist.github.com/travisbrown/c966666ad583f760a568e805f36274d4, 2022. Accessed: 2026-03-26
2022
-
[62]
Hale, Samuel Fraiberger, Victor Orozco-Olvera, and Paul R ¨ottger
Manuel Tonneau, Diyi Liu, Niyati Malhotra, Scott A. Hale, Samuel Fraiberger, Victor Orozco-Olvera, and Paul R ¨ottger. HateDay: Insights from a global hate speech dataset representative of a day on Twitter. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.