Recognition: unknown
Local-Splitter: A Measurement Study of Seven Tactics for Reducing Cloud LLM Token Usage on Coding-Agent Workloads
Pith reviewed 2026-05-10 15:26 UTC · model grok-4.3
The pith
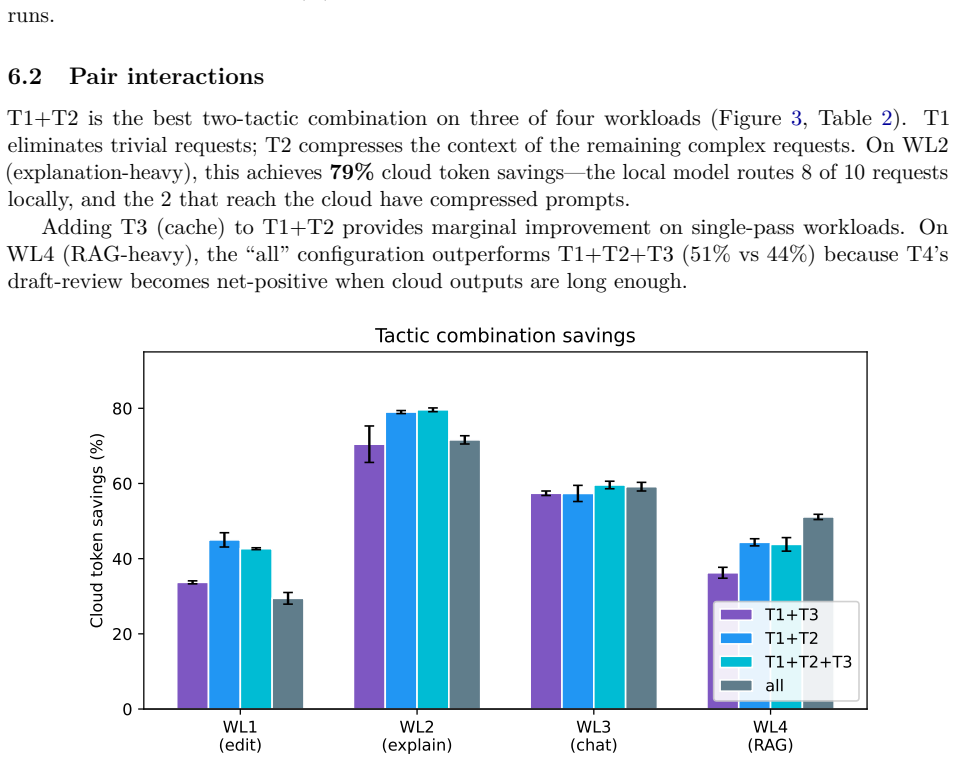
Local routing combined with prompt compression cuts cloud LLM token use by 45-79% on coding-agent tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Local routing (T1) plus prompt compression (T2) produces 45-79% cloud token savings on edit-heavy and explanation-heavy workloads, while the full set of tactics including local drafting with cloud review (T4) reaches 51% savings on RAG-heavy workloads.
What carries the argument
A local model used as a triage layer that performs routing, compression, drafting, or intent extraction before the cloud model is called.
If this is right
- Token savings vary sharply by workload class, so practitioners should select tactic subsets based on whether tasks are edit-heavy, explanation-heavy, or RAG-heavy.
- The open-source shim supports any Ollama local model and any OpenAI-compatible cloud endpoint, allowing direct measurement of cost and latency trade-offs.
- Combining tactics in a greedy-additive way reveals that later tactics add value only after the first two are applied on certain workloads.
- Dollar cost and latency both drop when cloud tokens fall, though the exact numbers depend on the chosen local and cloud models.
Where Pith is reading between the lines
- Teams building coding agents may need separate configurations for different user patterns rather than a single default setup.
- The same triage approach could be tested on non-coding tasks such as data analysis or document editing to see if savings generalize.
- Smaller local models might still deliver most of the routing and compression benefit, which would lower the hardware bar for deployment.
Load-bearing premise
The local model's choices about which queries to route, how to compress prompts, and what to draft still leave the cloud model with enough information to return correct final answers.
What would settle it
A run on the same workloads where the hybrid outputs contain clear errors in code edits or explanations that a pure cloud model would have avoided.
Figures


read the original abstract
We present a systematic measurement study of seven tactics for reducing cloud LLM token usage when a small local model can act as a triage layer in front of a frontier cloud model. The tactics are: (1) local routing, (2) prompt compression, (3) semantic caching, (4) local drafting with cloud review, (5) minimal-diff edits, (6) structured intent extraction, and (7) batching with vendor prompt caching. We implement all seven in an open-source shim that speaks both MCP and the OpenAI-compatible HTTP surface, supporting any local model via Ollama and any cloud model via an OpenAI-compatible endpoint. We evaluate each tactic individually, in pairs, and in a greedy-additive subset across four coding-agent workload classes (edit-heavy, explanation-heavy, general chat, RAG-heavy). We measure tokens saved, dollar cost, latency, and routing accuracy. Our headline finding is that T1 (local routing) combined with T2 (prompt compression) achieves 45-79% cloud token savings on edit-heavy and explanation-heavy workloads, while on RAG-heavy workloads the full tactic set including T4 (draft-review) achieves 51% savings. We observe that the optimal tactic subset is workload-dependent, which we believe is the most actionable finding for practitioners deploying coding agents today.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a measurement study of seven tactics for reducing cloud LLM token usage in coding-agent workloads using a local model as a triage layer. The tactics include local routing (T1), prompt compression (T2), semantic caching (T3), local drafting with cloud review (T4), minimal-diff edits (T5), structured intent extraction (T6), and batching with vendor prompt caching (T7). Implemented in an open-source shim supporting Ollama and OpenAI-compatible endpoints, the study evaluates individual tactics, pairs, and greedy-additive subsets on four workload classes: edit-heavy, explanation-heavy, general chat, and RAG-heavy. Key measurements include tokens saved, dollar cost, latency, and routing accuracy. The main findings are that T1 combined with T2 achieves 45-79% cloud token savings on edit-heavy and explanation-heavy workloads, while the full tactic set including T4 achieves 51% savings on RAG-heavy workloads, with the optimal subset being workload-dependent.
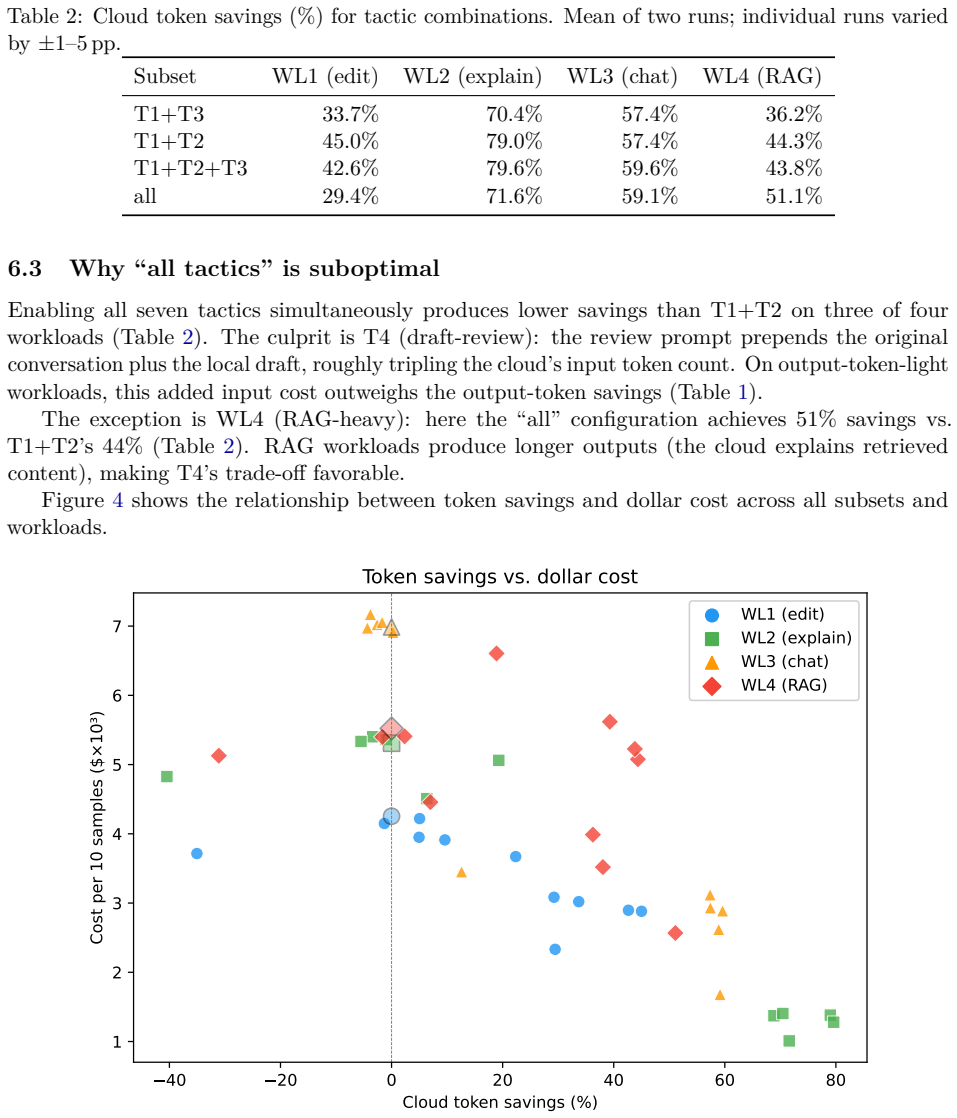
Significance. If the results hold, this study is significant for providing concrete, workload-specific guidance on cost-saving tactics for deploying coding agents with hybrid local-cloud LLM setups. The open-source implementation of the shim is a strength, enabling reproducibility and extension by practitioners. The emphasis on workload dependence offers actionable insights beyond generic claims.
major comments (1)
- [Abstract] Abstract: The headline findings report specific percentage savings (45-79% for T1+T2 and 51% for full set) but the measurements described focus on tokens, cost, latency, and routing accuracy without mention of end-to-end output quality metrics such as task success rates, unit test pass rates, or fidelity scores against a cloud-only baseline. This is load-bearing because the central claim of useful token reduction assumes that local triage, compression, and drafting decisions do not degrade final output correctness.
minor comments (3)
- The abstract and evaluation lack details on sample sizes, number of workload instances per class, statistical tests, error bars, or confidence intervals for the reported savings percentages.
- It is unclear how routing accuracy was measured and whether it correlates with overall task success.
- The selection of tactic subsets appears post-hoc; clarification on whether this was pre-specified or exploratory would strengthen the claims.
Simulated Author's Rebuttal
Thank you for your thorough review and constructive feedback on our manuscript. We appreciate the emphasis on output quality metrics and address the major comment below. We will revise the manuscript to better contextualize our measurements and acknowledge limitations.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline findings report specific percentage savings (45-79% for T1+T2 and 51% for full set) but the measurements described focus on tokens, cost, latency, and routing accuracy without mention of end-to-end output quality metrics such as task success rates, unit test pass rates, or fidelity scores against a cloud-only baseline. This is load-bearing because the central claim of useful token reduction assumes that local triage, compression, and drafting decisions do not degrade final output correctness.
Authors: We agree that the lack of explicit end-to-end output quality metrics represents a limitation when claiming the practical value of token reductions. This study is a focused measurement of token, cost, latency, and routing accuracy for the seven tactics, with the headline results derived directly from those quantities. The tactics were designed to avoid quality loss where possible (local routing escalates difficult cases to the cloud model; compression targets redundant tokens while retaining intent; draft-review uses the cloud for final output). However, we did not collect task success rates, unit test pass rates, or direct fidelity comparisons to a cloud-only baseline. We will revise the abstract to explicitly note the scope of our measurements, add a limitations subsection discussing the quality-preservation assumption and risks of degradation, and include future-work directions for incorporating quality metrics on coding workloads. revision: yes
Circularity Check
No circularity: empirical measurement study with direct token counts
full rationale
This is a measurement study that implements seven tactics in an open-source shim, runs them on four workload classes, and reports observed token savings, costs, latency, and routing accuracy from direct instrumentation. No derivations, equations, fitted parameters, or predictions appear in the abstract or described methodology. The headline claims (45-79% savings from T1+T2, 51% from full set on RAG) are explicit empirical aggregates of measured token counts rather than quantities derived from any self-referential definition, ansatz, or self-citation chain. The central results therefore remain independent of the paper's own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The four workload classes (edit-heavy, explanation-heavy, general chat, RAG-heavy) are representative of real coding-agent usage.
Reference graph
Works this paper leans on
-
[1]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Marah Abdin, Sam Ade Jacobs, Ammar Ahmad Awan, Jyoti Aneja, et al. Phi-3 technical report: A highly capable language model locally on your phone.arXiv preprint arXiv:2404.14219, 2024
work page internal anchor Pith review arXiv 2024
-
[2]
Prompt caching with Claude
Anthropic. Prompt caching with Claude. Anthropic Documentation, 2024. URL https: //docs.anthropic.com/en/docs/build-with-claude/prompt-caching
2024
-
[3]
Model context protocol specification, 2024
Anthropic. Model context protocol specification, 2024. URLhttps://modelcontextprotocol. io
2024
-
[4]
LongBench: A bilingual, multitask benchmark for long context understanding
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. LongBench: A bilingual, multitask benchmark for long context understanding. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, pages 3119–3137. Association f...
2024
-
[5]
Fu Bang. GPTCache: An open-source semantic cache for LLM applications enabling faster answers and cost savings. InProceedings of the 3rd Workshop for Natural Language Process- ing Open Source Software (NLP-OSS 2023), pages 212–218. Association for Computational Linguistics, 2023. doi: 10.18653/v1/2023.nlposs-1.24. URL https://aclanthology.org/2023. nlposs-1.24/
-
[6]
Lee, Deming Chen, and Tri Dao
Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D. Lee, Deming Chen, and Tri Dao. Medusa: Simple LLM inference acceleration framework with multiple decoding heads. In Proceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 5209–5235, 2024
2024
-
[7]
FrugalGPT: How to use large language models while reducing cost and improving performance.Transactions on Machine Learning Research,
Lingjiao Chen, Matei Zaharia, and James Zou. FrugalGPT: How to use large language models while reducing cost and improving performance.Transactions on Machine Learning Research,
-
[8]
FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance
URLhttps://openreview.net/forum?id=cSimKw5p6R. arXiv:2305.05176
work page internal anchor Pith review arXiv
-
[9]
Gemma: Open Models Based on Gemini Research and Technology
Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, et al. Gemma: Open models based on Gemini research and technology.arXiv preprint arXiv:2403.08295, 2024
work page internal anchor Pith review arXiv 2024
-
[10]
Aaron Grattafiori et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024. URLhttps://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Huiqiang Jiang, Qianhui Wu, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. LLMLingua: Com- pressing prompts for accelerated inference of large language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 13358–13376. Association for Computational Linguistics, 2023. doi: 10.18653/v1/2023.emnlp-main.825. URL htt...
-
[12]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R. Narasimhan. SWE-bench: Can language models resolve real-world GitHub issues? InThe Twelfth International Conference on Learning Representations, 2024. URL https: //openreview.net/forum?id=VTF8yNQM66. 14
2024
-
[13]
Fast inference from transformers via speculative decoding
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding. InProceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 19274–19286. PMLR, 2023. URLhttps://proceedings.mlr.press/v202/leviathan23a.html
2023
-
[14]
Retrieval-augmented generation for knowledge-intensive NLP tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive NLP tasks. InAdvances in Neural Information Processing Systems, volume 33, pages 9459–9474, 2020
2020
-
[15]
Junwei Liu, Kaixin Wang, Yixuan Chen, Xin Peng, Zhenpeng Chen, Lingming Zhang, and Yiling Lou. Large language model-based agents for software engineering: A survey.arXiv preprint arXiv:2409.02977, 2024
-
[16]
Small language models: Survey, measurements, and insights.arXiv preprint arXiv:2409.15790, 2024
Zhenyan Lu, Xiang Li, Dongqi Cai, Rongjie Yi, Fangming Liu, Xiwen Zhang, Nicholas D. Lane, and Mengwei Xu. Small language models: Survey, measurements, and insights.arXiv preprint arXiv:2409.15790, 2024. URLhttps://arxiv.org/abs/2409.15790
-
[17]
Ollama: Get up and running with large language models locally, 2024
Ollama. Ollama: Get up and running with large language models locally, 2024. URLhttps: //ollama.com
2024
-
[18]
RouteLLM: Learning to Route LLMs with Preference Data
Isaac Ong, Amjad Almahairi, Vincent Wu, Wei-Lin Chiang, Tianhao Wu, Joseph E. Gonzalez, M. Waleed Kadous, and Ion Stoica. RouteLLM: Learning to route LLMs with preference data. arXiv preprint arXiv:2406.18665, 2024. URLhttps://arxiv.org/abs/2406.18665
work page internal anchor Pith review arXiv 2024
-
[19]
Prompt caching in the API
OpenAI. Prompt caching in the API. OpenAI Developer Documentation, 2024. URLhttps: //openai.com/index/api-prompt-caching/
2024
-
[20]
Vicky Zhao, Lili Qiu, and Dongmei Zhang
Zhuoshi Pan, Qianhui Wu, Huiqiang Jiang, Menglin Xia, Xufang Luo, Jue Zhang, Qingwei Lin, Victor Rühle, Yuqing Yang, Chin-Yew Lin, H. Vicky Zhao, Lili Qiu, and Dongmei Zhang. LLMLingua-2: Data distillation for efficient and faithful task-agnostic prompt compression. In Findings of the Association for Computational Linguistics: ACL 2024, pages 963–981, 2024
2024
-
[21]
Qwen Team, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, et al. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Sentence-BERT: Sentence embeddings using siamese BERT- networks
Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence embeddings using siamese BERT- networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, pages 3982–3992. Association for Computational Linguistics, 2019. doi: 10.18653/ v1/D19-1410
2019
-
[23]
Efficient Guided Generation for Large Language Models
Brandon T. Willard and Rémi Louf. Efficient guided generation for large language models. arXiv preprint arXiv:2307.09702, 2023
work page internal anchor Pith review arXiv 2023
-
[24]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging LLM-as-a-judge with MT-Bench and Chatbot Arena. InAdvances in Neural Information Processing Systems, volume 36, 2023. 15
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.