Recognition: unknown
IAD-Unify: A Region-Grounded Unified Model for Industrial Anomaly Segmentation, Understanding, and Generation
Pith reviewed 2026-05-10 15:46 UTC · model grok-4.3
The pith
A frozen DINOv2 region expert injects precise anomaly evidence into a Qwen3.5 vision-language backbone to enable one model to segment defects, explain them in language, and generate controlled edits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
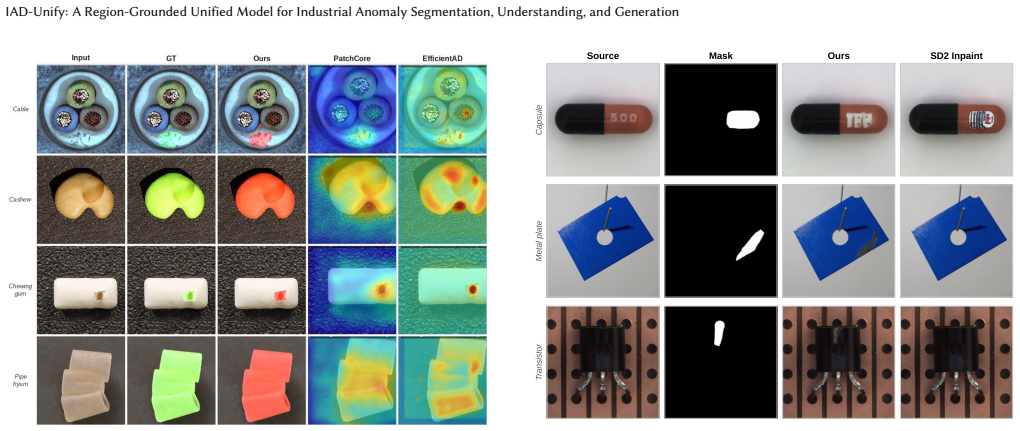
IAD-Unify is a dual-encoder unified framework in which a frozen DINOv2-based region expert supplies precise anomaly evidence to a shared Qwen3.5-4B vision-language backbone via lightweight token injection, jointly enabling anomaly segmentation, region-grounded understanding, and mask-guided generation. The framework is evaluated on the new Anomaly-56K platform covering 59,916 images across 24 categories and 104 defect variants. Controlled experiments confirm that region grounding drives understanding accuracy, predicted regions nearly match oracle performance, and joint training preserves generation quality.
What carries the argument
Lightweight token injection of anomaly evidence from a frozen DINOv2-based region expert into the shared Qwen3.5-4B vision-language backbone
If this is right
- Region grounding improves location accuracy in understanding by more than 76 percentage points.
- Using the model's own predicted regions yields performance nearly identical to using ground-truth oracle regions.
- Region-grounded generation produces the highest full-image fidelity and masked-region perceptual quality.
- Pre-initialized joint training improves understanding performance at negligible cost to generation quality.
- The model shows robust generalization on the MMAD benchmark, including categories not seen during training.
Where Pith is reading between the lines
- The injection approach could be tested on other vision-language tasks where precise localization must support both description and conditional generation.
- Freezing the region expert while training only the injection and backbone layers suggests a route to lower training cost for multi-task models in related inspection domains.
- The Anomaly-56K construction method could be replicated for other multi-task settings that combine detection, language output, and image editing.
Load-bearing premise
The frozen DINOv2 region expert can transfer sufficiently precise anomaly location information through lightweight token injection to support segmentation, understanding, and generation without major loss or the need to fine-tune the expert.
What would settle it
Running the model on a new set of industrial images with fine-grained or ambiguous defects and measuring whether removing the region-expert injection causes understanding accuracy to fall by a large margin or whether predicted-mask generation quality drops below oracle-mask quality.
Figures






read the original abstract
Real-world industrial inspection requires not only localizing defects, but also explaining them in natural language and generating controlled defect edits. However, existing approaches fail to jointly support all three capabilities within a unified framework and evaluation protocol. We propose IAD-Unify, a dual-encoder unified framework in which a frozen DINOv2-based region expert supplies precise anomaly evidence to a shared Qwen3.5-4B vision-language backbone via lightweight token injection, jointly enabling anomaly segmentation, region-grounded understanding, and mask-guided generation. To enable unified evaluation, we further construct Anomaly-56K, a comprehensive unified multi-task IAD evaluation platform, spanning 59,916 images across 24 categories and 104 defect variants. Controlled ablations yield four findings: (i) region grounding is the decisive mechanism for understanding, removing it degrades location accuracy by >76 pp; (ii) predicted-region performance closely matches oracle, confirming deployment viability; (iii) region-grounded generation achieves the best full-image fidelity and masked-region perceptual quality; and (iv) pre-initialized joint training improves understanding at negligible generation cost (-0.16 dB). IAD-Unify further achieves strong performance on the MMAD benchmark, including categories unseen during training, demonstrating robust cross-category generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes IAD-Unify, a dual-encoder unified framework for industrial anomaly detection tasks. A frozen DINOv2-based region expert supplies anomaly evidence to a shared Qwen3.5-4B vision-language backbone via lightweight token injection, enabling joint anomaly segmentation, region-grounded natural language understanding, and mask-guided generation. The authors introduce the Anomaly-56K benchmark (59,916 images, 24 categories, 104 defect variants) and report controlled ablations showing region grounding as decisive for understanding (>76 pp accuracy drop when removed), predicted regions nearly matching oracle performance, strong full-image fidelity in generation, and negligible cost to joint training.
Significance. If the empirical results hold, this work offers a practical advance toward multi-capability systems for real-world industrial inspection, where localization, explanation, and controlled editing are needed together. The token-injection design with a frozen expert is efficient and the new unified benchmark addresses a clear gap; the reported cross-category generalization on MMAD further supports deployment potential in varied manufacturing settings.
major comments (2)
- Abstract and Ablations: the central claim that predicted-region performance closely matches oracle (confirming deployment viability) is load-bearing, yet the manuscript provides only summary statements without the full quantitative metrics, per-task tables, or error bars that would allow independent verification of effect sizes and variance.
- Methods (token injection): the assumption that lightweight injection from the frozen DINOv2 expert transfers sufficiently precise anomaly evidence without major loss is tested indirectly via ablations, but additional diagnostics (e.g., feature similarity metrics or ablation on injection depth) would strengthen that no critical information bottleneck occurs for the three tasks.
minor comments (4)
- The exact token-injection mechanism (number of tokens, injection layer, fusion operation) is described only at high level; a diagram or pseudocode in the methods section would improve reproducibility.
- Implementation details such as optimizer settings, learning-rate schedule, and exact loss weighting for the joint multi-task training are missing and should be supplied to support the claim of negligible generation cost.
- The Anomaly-56K construction (annotation protocol, train/test splits, handling of the 104 defect variants) requires a dedicated subsection or appendix to allow other researchers to extend or replicate the benchmark.
- Figure captions and axis labels in the ablation plots should explicitly state the metrics used (e.g., IoU, accuracy, FID) rather than relying on the main text.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the practical advance, and recommendation for minor revision. The feedback on empirical presentation and diagnostics is constructive, and we will strengthen the manuscript accordingly while preserving the core contributions.
read point-by-point responses
-
Referee: Abstract and Ablations: the central claim that predicted-region performance closely matches oracle (confirming deployment viability) is load-bearing, yet the manuscript provides only summary statements without the full quantitative metrics, per-task tables, or error bars that would allow independent verification of effect sizes and variance.
Authors: We agree that the claim requires full supporting data for verification. In the revised manuscript we will add comprehensive per-task tables (segmentation IoU, understanding accuracy, generation FID/LPIPS) comparing predicted-region vs. oracle performance across all 24 categories, together with standard deviations from repeated runs to report effect sizes and variance explicitly. revision: yes
-
Referee: Methods (token injection): the assumption that lightweight injection from the frozen DINOv2 expert transfers sufficiently precise anomaly evidence without major loss is tested indirectly via ablations, but additional diagnostics (e.g., feature similarity metrics or ablation on injection depth) would strengthen that no critical information bottleneck occurs for the three tasks.
Authors: We acknowledge that direct diagnostics would increase confidence. We will add (i) cosine-similarity measurements between injected tokens and original DINOv2 region features and (ii) an ablation varying injection depth into the Qwen3.5 backbone, demonstrating that the lightweight mechanism preserves the necessary anomaly evidence for segmentation, understanding, and generation without introducing a critical bottleneck. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is an empirical proposal of a dual-encoder architecture (frozen DINOv2 region expert + Qwen3.5-4B backbone with lightweight token injection) for three industrial anomaly tasks. No mathematical derivations, equations, or uniqueness theorems are presented that reduce by construction to fitted parameters or self-citations. Ablations directly test the injection mechanism and report independent metrics (e.g., >76 pp degradation without region grounding, near-oracle performance with predicted regions). The Anomaly-56K benchmark and MMAD results are external evaluations. No load-bearing step matches any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Kilian Batzner, Lars Heckler, and Rebecca König. 2024. Efficientad: Accurate visual anomaly detection at millisecond-level latencies. InProceedings of the IEEE/CVF winter conference on applications of computer vision. 128–138
2024
-
[2]
Paul Bergmann, Michael Fauser, David Sattlegger, and Carsten Steger. 2019. MVTec AD–A comprehensive real-world dataset for unsupervised anomaly detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 9592–9600
2019
-
[3]
Tim Brooks, Aleksander Holynski, and Alexei A Efros. 2023. Instructpix2pix: Learning to follow image editing instructions. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 18392–18402
2023
-
[4]
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexan- der Kirillov, and Sergey Zagoruyko. 2020. End-to-end object detection with transformers. InEuropean conference on computer vision. Springer, 213–229
2020
-
[5]
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. 2021. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF international conference on computer vision. 9650–9660
2021
-
[6]
Qiyu Chen, Huiyuan Luo, Chengkan Lv, and Zhengtao Zhang. 2024. A unified anomaly synthesis strategy with gradient ascent for industrial anomaly detection and localization. InEuropean Conference on Computer Vision. Springer, 37–54
2024
-
[7]
Gheorghe Comanici et al . 2025. Gemini 2.5: Pushing the Frontier with Ad- vanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities.arXiv preprint arXiv:2507.06261(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Simon Damm, Mike Laszkiewicz, Johannes Lederer, and Asja Fischer. 2025. Anomalydino: Boosting patch-based few-shot anomaly detection with dinov2. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (W ACV). IEEE, 1319–1329
2025
-
[9]
Thomas Defard, Aleksandr Setkov, Angelique Loesch, and Romaric Audigier
-
[10]
InInternational conference on pattern recognition
Padim: a patch distribution modeling framework for anomaly detection and localization. InInternational conference on pattern recognition. Springer, 475–489
-
[11]
Hanqiu Deng and Xingyu Li. 2022. Anomaly detection via reverse distillation from one-class embedding. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 9737–9746
2022
-
[12]
Zhaopeng Gu, Bingke Zhu, Guibo Zhu, Yingying Chen, Ming Tang, and Jinqiao Wang. 2024. Anomalygpt: Detecting industrial anomalies using large vision- language models. InProceedings of the AAAI conference on artificial intelligence, Vol. 38. 1932–1940
2024
-
[13]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models.Advances in neural information processing systems33 (2020), 6840–6851
2020
-
[14]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. 2022. Lora: Low-rank adaptation of large language models.Iclr1, 2 (2022), 3
2022
-
[15]
Teng Hu, Jiangning Zhang, Ran Yi, Yuzhen Du, Xu Chen, Liang Liu, Yabiao Wang, and Chengjie Wang. 2024. Anomalydiffusion: Few-shot anomaly image generation with diffusion model. InProceedings of the AAAI conference on artificial intelligence, Vol. 38. 8526–8534
2024
-
[16]
Jongheon Jeong, Yang Zou, Taewan Kim, Dongqing Zhang, Avinash Ravichan- dran, and Onkar Dabeer. 2023. Winclip: Zero-/few-shot anomaly classification and segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 19606–19616
2023
-
[17]
Stepan Jezek, Martin Jonak, Radim Burget, Pavel Dvorak, and Milos Skotak
-
[18]
In2021 13th International congress on ultra modern telecommunications and control systems and workshops (ICUMT)
Deep learning-based defect detection of metal parts: evaluating current methods in complex conditions. In2021 13th International congress on ultra modern telecommunications and control systems and workshops (ICUMT). IEEE, 66–71
-
[19]
Xi Jiang, Yue Guo, Jian Li, Yong Liu, Bin-Bin Gao, Hanqiu Deng, Jun Liu, Heng Zhao, Chengjie Wang, and Feng Zheng. 2026. AD-Copilot: A Vision-Language Assistant for Industrial Anomaly Detection via Visual In-context Comparison. arXiv preprint arXiv:2603.13779(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [20]
-
[21]
Ying Jin, Jinlong Peng, Qingdong He, Teng Hu, Jiafu Wu, Hao Chen, Haox- uan Wang, Wenbing Zhu, Mingmin Chi, Jun Liu, et al. 2025. Dual-interrelated diffusion model for few-shot anomaly image generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 30420–30429
2025
-
[22]
Alex Kendall, Yarin Gal, and Roberto Cipolla. 2018. Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 7482–7491
2018
-
[23]
Chun-Liang Li, Kihyuk Sohn, Jinsung Yoon, and Tomas Pfister. 2021. Cutpaste: Self-supervised learning for anomaly detection and localization. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 9664–9674
2021
- [24]
-
[25]
Chin-Yew Lin. 2004. Rouge: A package for automatic evaluation of summaries. InText summarization branches out. 74–81
2004
-
[26]
Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. 2017. Feature pyramid networks for object detection. InProceed- ings of the IEEE conference on computer vision and pattern recognition. 2117–2125
2017
-
[27]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual in- struction tuning.Advances in neural information processing systems36 (2023), 34892–34916
2023
-
[28]
Wenxin Ma, Qingsong Yao, Xiang Zhang, Zhelong Huang, Zihang Jiang, and S Kevin Zhou. 2025. Towards accurate unified anomaly segmentation. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (W ACV). IEEE, 1342–1352
2025
-
[29]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El- Nouby, et al. 2023. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning Transferable Visual Models From Natural Language Supervision. InProceedings of the International Confer- ence on Machine Learning (ICML). 8748–8763
2021
-
[31]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 10684–10695
2022
-
[32]
Karsten Roth, Latha Pemula, Joaquin Zepeda, Bernhard Schölkopf, Thomas Brox, and Peter Gehler. 2022. Towards total recall in industrial anomaly detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 14318–14328
2022
- [33]
-
[34]
Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jin- sheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, et al. 2024. Emu3: Next-token prediction is all you need.arXiv preprint arXiv:2409.18869(2024)
work page internal anchor Pith review arXiv 2024
-
[35]
Zhuonan Wang, Zhenxuan Fan, Siwen Tan, Yu Zhong, Yuqian Yuan, Haoyuan Li, Hao Jiang, Wenqiao Zhang, Feifei Shao, Hongwei Wang, et al. 2026. MAU-GPT: Enhancing Multi-type Industrial Anomaly Understanding via Anomaly-aware and Generalist Experts Adaptation. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 26787–26795
2026
-
[36]
Chengyue Wu, Xiaokang Chen, Zhiyu Wu, Yiyang Ma, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, Chong Ruan, et al. 2025. Janus: Decou- pling visual encoding for unified multimodal understanding and generation. In Proceedings of the Computer Vision and Pattern Recognition Conference. 12966– 12977
2025
-
[37]
Jinheng Xie, Weijia Mao, Zechen Bai, David Junhao Zhang, Weihao Wang, Kevin Qinghong Lin, Yuchao Gu, Zhijie Chen, Zhenheng Yang, and Mike Zheng Shou. 2024. Show-o: One single transformer to unify multimodal understanding and generation.arXiv preprint arXiv:2408.12528(2024)
work page internal anchor Pith review arXiv 2024
-
[38]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Vitjan Zavrtanik, Matej Kristan, and Danijel Skočaj. 2021. Draem-a discrimi- natively trained reconstruction embedding for surface anomaly detection. In Proceedings of the IEEE/CVF international conference on computer vision. 8330– 8339
2021
-
[40]
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang
-
[41]
InProceedings of the IEEE conference on computer vision and pattern recognition
The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition. 586–595
-
[42]
Haozhe Zhao, Xiaojian Ma, Liang Chen, Shuzheng Si, Rujie Wu, Kaikai An, Peiyu Yu, Minjia Zhang, Qing Li, and Baobao Chang. 2024. Ultraedit: Instruction-based fine-grained image editing at scale.Advances in Neural Information Processing Systems37 (2024), 3058–3093
2024
- [43]
-
[44]
Haoyu Zheng, Yun Zhu, Yuqian Yuan, Bo Yuan, Wenqiao Zhang, Siliang Tang, and Jun Xiao. 2026. PILOT: Planning via Internalized Latent Optimization Trajectories for Large Language Models.arXiv preprint arXiv:2601.19917(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[45]
Yang Zou, Jongheon Jeong, Latha Pemula, Dongqing Zhang, and Onkar Dabeer
-
[46]
InEuropean conference on computer vision
Spot-the-difference self-supervised pre-training for anomaly detection and segmentation. InEuropean conference on computer vision. Springer, 392–408
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.