Recognition: 2 theorem links
· Lean TheoremAD-Copilot: A Vision-Language Assistant for Industrial Anomaly Detection via Visual In-context Comparison
Pith reviewed 2026-05-15 11:50 UTC · model grok-4.3
The pith
AD-Copilot detects industrial anomalies by comparing image pairs visually rather than through language alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
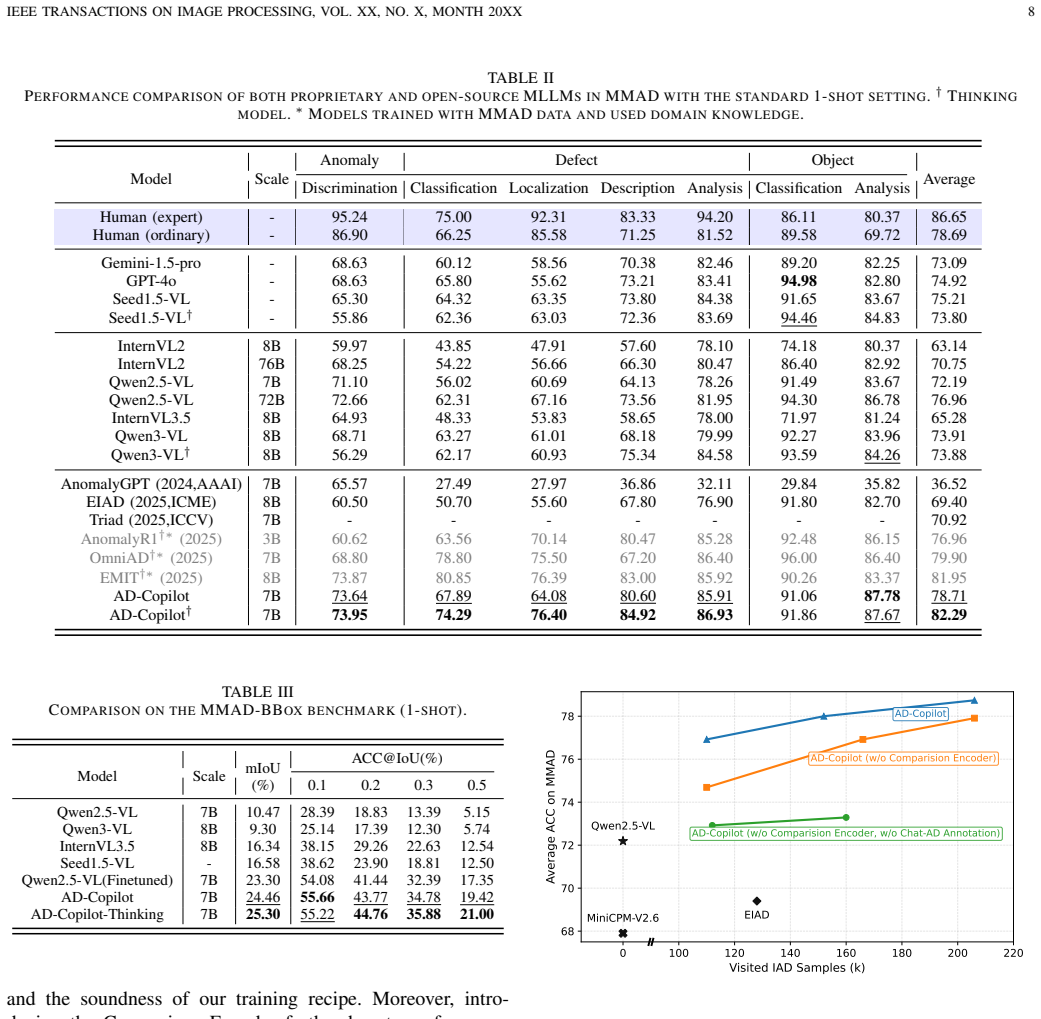
AD-Copilot achieves 82.3 percent accuracy on the MMAD benchmark and a maximum 3.35 times improvement on MMAD-BBox by incorporating a Comparison Encoder that uses cross-attention between paired image features to enable fine-grained visual comparison, trained through a multi-stage process on the Chat-AD dataset mined from sparsely labeled industrial images for captioning, VQA, and defect localization.
What carries the argument
Comparison Encoder that applies cross-attention between features of paired images to support multi-image fine-grained perception during anomaly detection.
Load-bearing premise
The data curation pipeline extracts accurate inspection knowledge from sparsely labeled industrial images and produces high-quality training samples without introducing major label noise or domain mismatch.
What would settle it
A controlled experiment that replaces the cross-attention Comparison Encoder with independent image encoding and measures whether accuracy on subtle defect pairs falls back to baseline levels would test whether the visual comparison mechanism drives the reported gains.
Figures






read the original abstract
Multimodal Large Language Models (MLLMs) have achieved impressive success in natural visual understanding, yet they consistently underperform in industrial anomaly detection (IAD). This is because MLLMs trained mostly on general web data differ significantly from industrial images. Moreover, they encode each image independently and can only compare images in the language space, making them insensitive to subtle visual differences that are key to IAD. To tackle these issues, we present AD-Copilot, an interactive MLLM specialized for IAD via visual in-context comparison. We first design a novel data curation pipeline to mine inspection knowledge from sparsely labeled industrial images and generate precise samples for captioning, VQA, and defect localization, yielding a large-scale multimodal dataset Chat-AD rich in semantic signals for IAD. On this foundation, AD-Copilot incorporates a novel Comparison Encoder that employs cross-attention between paired image features to enhance multi-image fine-grained perception, and is trained with a multi-stage strategy that incorporates domain knowledge and gradually enhances IAD skills. In addition, we introduce MMAD-BBox, an extended benchmark for anomaly localization with bounding-box-based evaluation. The experiments show that AD-Copilot achieves 82.3% accuracy on the MMAD benchmark, outperforming all other models without any data leakage. In the MMAD-BBox test, it achieves a maximum improvement of $3.35\times$ over the baseline. AD-Copilot also exhibits excellent generalization of its performance gains across other specialized and general-purpose benchmarks. Remarkably, AD-Copilot surpasses human expert-level performance on several IAD tasks, demonstrating its potential as a reliable assistant for real-world industrial inspection. All datasets and models will be released for the broader benefit of the community.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AD-Copilot, a specialized multimodal large language model for industrial anomaly detection (IAD) that performs visual in-context comparison. It proposes a novel data curation pipeline to extract inspection knowledge from sparsely labeled industrial images and generate the Chat-AD dataset for captioning, VQA, and defect localization tasks. The architecture includes a Comparison Encoder using cross-attention between paired image features, trained via a multi-stage strategy incorporating domain knowledge. A new MMAD-BBox benchmark for bounding-box anomaly localization is introduced. Reported results include 82.3% accuracy on MMAD (outperforming baselines without data leakage), up to 3.35× improvement on MMAD-BBox, generalization across other benchmarks, and surpassing human expert performance on several IAD tasks, with plans to release datasets and models.
Significance. If the empirical claims hold after verification of data quality and no leakage, the work would advance the application of MLLMs to specialized industrial domains by addressing the domain gap and the limitation of language-only comparison for subtle visual differences. The release of Chat-AD and MMAD-BBox would provide reusable resources for the community. The multi-stage training and visual cross-attention mechanism represent a targeted adaptation that could inform future domain-specific MLLM development.
major comments (2)
- [Data Curation Pipeline] The headline results (82.3% MMAD accuracy, 3.35× MMAD-BBox gain, human-expert surpassing) depend entirely on the data curation pipeline producing high-quality samples without significant label noise or domain mismatch. No quantitative validation (noise rate, inter-annotator agreement, or domain-shift metrics) is reported for the mined Chat-AD data, leaving the foundation of all gains unverified.
- [Experiments] The claim of 'without any data leakage' for the 82.3% MMAD accuracy and generalization results is load-bearing but unsupported by details on train/test split construction or leakage verification for the mined industrial images.
minor comments (2)
- [Abstract] The abstract asserts 'excellent generalization' across benchmarks but omits specific accuracy numbers or tables summarizing those results, reducing clarity for readers.
- [Method] Notation for the Comparison Encoder's cross-attention (e.g., how paired features are fused before the language model) could be formalized with an equation to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each major comment below and will revise the manuscript to provide the requested clarifications and additional validation details.
read point-by-point responses
-
Referee: [Data Curation Pipeline] The headline results (82.3% MMAD accuracy, 3.35× MMAD-BBox gain, human-expert surpassing) depend entirely on the data curation pipeline producing high-quality samples without significant label noise or domain mismatch. No quantitative validation (noise rate, inter-annotator agreement, or domain-shift metrics) is reported for the mined Chat-AD data, leaving the foundation of all gains unverified.
Authors: We agree that explicit quantitative validation strengthens the claims. The manuscript describes the curation pipeline but does not report noise rates, inter-annotator agreement, or domain-shift metrics. In the revision we will add these: (i) noise rate estimates from manual inspection of 500 randomly sampled instances, (ii) inter-annotator agreement on a subset of VQA and localization annotations, and (iii) domain-shift metrics (e.g., Fréchet distance on CLIP features) between Chat-AD and the MMAD test distribution. revision: yes
-
Referee: [Experiments] The claim of 'without any data leakage' for the 82.3% MMAD accuracy and generalization results is load-bearing but unsupported by details on train/test split construction or leakage verification for the mined industrial images.
Authors: We acknowledge that the current text states the no-leakage claim without sufficient procedural detail. The splits were constructed by source-level partitioning and hash-based deduplication to ensure no image or caption overlap. In the revision we will add a dedicated paragraph (and appendix table) that specifies the exact partitioning rules, deduplication method, and verification steps performed to confirm zero leakage between Chat-AD training data and all reported test sets. revision: yes
Circularity Check
No circularity: results rest on external empirical benchmarks
full rationale
The paper presents an empirical system: a data-curation pipeline that produces the Chat-AD dataset, a Comparison Encoder using cross-attention, and multi-stage training. All headline numbers (82.3 % MMAD accuracy, 3.35× MMAD-BBox gain, human-expert surpassing) are obtained by evaluating the trained model on held-out external benchmarks (MMAD, MMAD-BBox, and others) with an explicit “no data leakage” claim. No equation, parameter, or prediction is defined in terms of itself; the derivation chain consists of standard supervised training followed by independent test-set measurement. Therefore the central claims do not reduce to tautology or self-citation load-bearing.
Axiom & Free-Parameter Ledger
free parameters (1)
- Multi-stage training hyperparameters
axioms (1)
- domain assumption Base MLLMs can acquire fine-grained industrial anomaly detection skills through supervised fine-tuning on curated multimodal data
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We design a novel Comparison Encoder that employs cross-attention between paired image features to generate a compact set of learnable comparison tokens
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
multi-stage training curriculum that progressively builds comparison capability from general visual differences to industrial anomaly detection
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
IAD-Unify: A Region-Grounded Unified Model for Industrial Anomaly Segmentation, Understanding, and Generation
IAD-Unify unifies industrial anomaly segmentation, region-grounded language understanding, and mask-guided generation in one framework using DINOv2 token injection into Qwen3.5, supported by the new Anomaly-56K datase...
Reference graph
Works this paper leans on
-
[1]
On domain-adaptive post-training for multimodal large language models,
D. Cheng, S. Huang, Z. Zhu, X. Zhang, W. X. Zhao, Z. Luan, B. Dai, and Z. Zhang, “On domain-adaptive post-training for multimodal large language models,” arXiv preprint arXiv:2411.19930, 2024
-
[2]
Lingshu: A Generalist Foundation Model for Unified Multimodal Medical Understanding and Reasoning
W. Xu, H. P. Chan, L. Li, M. Aljunied, R. Yuan, J. Wang, C. Xiao, G. Chen, C. Liu, Z. Liet al., “Lingshu: A generalist foundation model for unified multimodal medical understanding and reasoning,”arXiv preprint arXiv:2506.07044, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tanget al., “Qwen2. 5-vl technical report,”arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
W. Wang, Z. Gao, L. Gu, H. Pu, L. Cui, X. Wei, Z. Liu, L. Jing, S. Ye, J. Shaoet al., “Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency,”arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
D. Guo, F. Wu, F. Zhu, F. Leng, G. Shi, H. Chen, H. Fan, J. Wang, J. Jiang, J. Wanget al., “Seed1. 5-vl technical report,”arXiv preprint arXiv:2505.07062, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
A survey of visual sensory anomaly detection,
X. Jiang, G. Xie, J. Wang, Y . Liu, C. Wang, F. Zheng, and Y . Jin, “A survey of visual sensory anomaly detection,” arXiv preprint arXiv:2202.07006, 2022
-
[7]
Softpatch+: Fully unsupervised anomaly classification and segmentation,
C. Wang, X. Jiang, B.-B. Gao, Z. Gan, Y . Liu, F. Zheng, and L. Ma, “Softpatch+: Fully unsupervised anomaly classification and segmentation,”Pattern Recognition, vol. 161, p. 111295, 2025
work page 2025
-
[8]
X. Jiang, J. Li, H. Deng, Y . Liu, B.-B. Gao, Y . Zhou, J. Li, C. Wang, and F. Zheng, “Mmad: A comprehensive benchmark for multimodal large language models in industrial anomaly detection,” inThe Thirteenth Inter- national Conference on Learning Representations, 2025
work page 2025
-
[9]
Efficient multi- modal large language models: A survey,
Y . Jin, J. Li, Y . Liu, T. Gu, K. Wu, Z. Jiang, M. He, B. Zhao, X. Tan, Z. Ganet al., “Efficient multi- modal large language models: A survey,”arXiv preprint arXiv:2405.10739, 2024
-
[10]
Ader: A comprehensive benchmark for multi-class visual anomaly detection,
J. Zhang, H. He, Z. Gan, Q. He, Y . Cai, Z. Xue, Y . Wang, C. Wang, L. Xie, and Y . Liu, “Ader: A comprehensive benchmark for multi-class visual anomaly detection,” arXiv preprint arXiv:2406.03262, vol. 2, no. 3, 2024
-
[11]
Can multimodal large language models be guided to im- prove industrial anomaly detection?
Z. Chen, H. Chen, M. Imani, and F. Imani, “Can multimodal large language models be guided to im- prove industrial anomaly detection?”arXiv preprint arXiv:2501.15795, 2025
-
[12]
Promptad: Learning prompts with only normal samples for few-shot anomaly detection,
X. Li, Z. Zhang, X. Tan, C. Chen, Y . Qu, Y . Xie, and L. Ma, “Promptad: Learning prompts with only normal samples for few-shot anomaly detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2024, pp. 16 838– 16 848
work page 2024
-
[13]
Manta: A large-scale multi-view and visual-text anomaly detection dataset for tiny ob- jects,
L. Fan, D. Fan, Z. Hu, Y . Ding, D. Di, K. Yi, M. Pag- nucco, and Y . Song, “Manta: A large-scale multi-view and visual-text anomaly detection dataset for tiny ob- jects,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 25 518–25 527
work page 2025
-
[14]
Towards zero-shot anomaly detection and reasoning with multimodal large language models,
J. Xu, S.-Y . Lo, B. Safaei, V . M. Patel, and I. Dwivedi, “Towards zero-shot anomaly detection and reasoning with multimodal large language models,” inProceedings of the Computer Vision and Pattern Recognition Confer- ence, 2025, pp. 20 370–20 382
work page 2025
-
[15]
Y . Li, S. Yuan, H. Wang, Q. Li, M. Liu, C. Xu, G. Shi, and W. Zuo, “Triad: Empowering lmm-based anomaly detection with expert-guided region-of-interest tokenizer and manufacturing process,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 21 917–21 926
work page 2025
-
[16]
Anomalygpt: Detecting industrial anomalies using large vision-language models,
Z. Gu, B. Zhu, G. Zhu, Y . Chen, M. Tang, and J. Wang, “Anomalygpt: Detecting industrial anomalies using large vision-language models,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, 2024, pp. 1932–1940
work page 2024
-
[17]
Eiad: Explainable industrial anomaly detection via multi-modal large language models,
Z. Zhang, J. Ruan, X. Gao, T. Liu, and Y . Fu, “Eiad: Explainable industrial anomaly detection via multi-modal large language models,”arXiv preprint arXiv:2503.14162, 2025
-
[18]
Mvtec ad–a comprehensive real-world dataset for un- supervised anomaly detection,
P. Bergmann, M. Fauser, D. Sattlegger, and C. Steger, “Mvtec ad–a comprehensive real-world dataset for un- supervised anomaly detection,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 9592–9600
work page 2019
-
[19]
Spot-the-difference self-supervised pre-training for anomaly detection and segmentation,
Y . Zou, J. Jeong, L. Pemula, D. Zhang, and O. Dabeer, “Spot-the-difference self-supervised pre-training for anomaly detection and segmentation,” inEuropean Con- ference on Computer Vision. Springer, 2022, pp. 392– 408
work page 2022
-
[20]
OpenAI, A. Jaech, A. Kalai, A. Lerer, A. Richardson, A. El-Kishky, A. Low, A. Helyar, A. Madry, A. Beutel, A. Carneyet al., “Openai o1 system card,”arXiv preprint arXiv:2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning,
DeepSeek-AI, D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Bi et al., “Deepseek-r1 incentivizes reasoning in llms through reinforcement learning,”Nature, vol. 645, 633–638, 2025. [Online]. Available: https://doi.org/10. 1038/s41586-025-09422-z
work page 2025
-
[22]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . Li, Y . Wuet al., “Deepseekmath: Pushing the limits of mathematical reasoning in open lan- guage models,”arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Y . Chao, J. Liu, J. Tang, and G. Wu, “Anomalyr1: A grpo- IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. XX, NO. X, MONTH 20XX 12 based end-to-end mllm for industrial anomaly detection,” arXiv preprint arXiv:2504.11914, 2025
-
[24]
Omniad: Detect and understand industrial anomaly via multimodal reasoning,
S. Zhao, Y . Lin, L. Han, Y . Zhao, and Y . Wei, “Omniad: Detect and understand industrial anomaly via multimodal reasoning,”arXiv preprint arXiv:2505.22039, 2025
-
[25]
Emit: Enhancing mllms for industrial anomaly detection via difficulty-aware grpo,
W. Guan, J. Lan, J. Cao, H. Tan, H. Zhu, and W. Wang, “Emit: Enhancing mllms for industrial anomaly detection via difficulty-aware grpo,”arXiv preprint arXiv:2507.21619, 2025
-
[26]
J. Liao, Y . Su, R.-C. Tu, Z. Jin, W. Sun, Y . Li, D. Tao, X. Xu, and X. Yang, “Ad-fm: Multimodal llms for anomaly detection via multi-stage reasoning and fine-grained reward optimization,”arXiv preprint arXiv:2508.04175, 2025
-
[27]
End-to-end object detection with transformers,
N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kir- illov, and S. Zagoruyko, “End-to-end object detection with transformers,” inEuropean conference on computer vision. Springer, 2020, pp. 213–229
work page 2020
-
[28]
H. Li, J. Wu, D. Liu, L. Y . Wu, H. Chen, and C. Shen, “Accurate industrial anomaly detection and localization using weakly-supervised residual transformers,”IEEE Transactions on Image Processing, 2026
work page 2026
-
[29]
Unipcb: A unified vision-language benchmark for open-ended pcb quality inspection,
F. Sun, X. Jiang, J. Wuet al., “Unipcb: A unified vision-language benchmark for open-ended pcb quality inspection,”arXiv preprint arXiv:2601.19222, 2026
-
[30]
Omnidiff: A comprehensive benchmark for fine-grained image difference captioning,
Y . Liu, S. Hou, S. Hou, J. Du, S. Meng, and Y . Huang, “Omnidiff: A comprehensive benchmark for fine-grained image difference captioning,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025, pp. 21 440–21 449
work page 2025
-
[31]
Softpatch: Unsupervised anomaly detection with noisy data,
X. Jiang, J. Liu, J. Wang, Q. Nie, K. Wu, Y . Liu, C. Wang, and F. Zheng, “Softpatch: Unsupervised anomaly detection with noisy data,”Advances in Neural Information Processing Systems, vol. 35, pp. 15 433– 15 445, 2022
work page 2022
-
[32]
Anomaly detection via reverse distillation from one-class embedding,
H. Deng and X. Li, “Anomaly detection via reverse distillation from one-class embedding,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 9737–9746
work page 2022
-
[33]
Efficientad: Accurate visual anomaly detection at millisecond-level latencies,
K. Batzner, L. Heckler, and R. K ¨onig, “Efficientad: Accurate visual anomaly detection at millisecond-level latencies,” inProceedings of the IEEE/CVF winter con- ference on applications of computer vision, 2024, pp. 128–138
work page 2024
-
[34]
Focus- patch ad: Few-shot multi-class anomaly detection with unified keywords patch prompts,
X. Ding, X. Li, M. Chen, J. Gong, and Y . Xie, “Focus- patch ad: Few-shot multi-class anomaly detection with unified keywords patch prompts,”IEEE Transactions on Image Processing, vol. 35, pp. 112–123, 2025
work page 2025
-
[35]
A unified model for multi-class anomaly detection,
Z. You, L. Cui, Y . Shen, K. Yang, X. Lu, Y . Zheng, and X. Le, “A unified model for multi-class anomaly detection,”Advances in Neural Information Processing Systems, vol. 35, pp. 4571–4584, 2022
work page 2022
-
[36]
X. Jiang, Y . Chen, Q. Nie, J. Liu, Y . Liu, C. Wang, and F. Zheng, “Toward multi-class anomaly detection: Exploring class-aware unified model against inter-class interference,”arXiv preprint arXiv:2403.14213, 2024
-
[37]
Normal- abnormal guided generalist anomaly detection,
Y . Wang, X. Wang, Y . Gong, and J. Xiao, “Normal- abnormal guided generalist anomaly detection,”arXiv preprint arXiv:2510.00495, 2025
-
[38]
Seas: few-shot industrial anomaly image generation with separation and sharing fine-tuning,
Z. Dai, S. Zeng, H. Liu, X. Li, F. Xue, and Y . Zhou, “Seas: few-shot industrial anomaly image generation with separation and sharing fine-tuning,”arXiv preprint arXiv:2410.14987, 2024
-
[39]
X. Li, Z. Huang, F. Xue, and Y . Zhou, “Musc: Zero-shot industrial anomaly classification and segmentation with mutual scoring of the unlabeled images,” inThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[40]
Winclip: Zero-/few-shot anomaly classifica- tion and segmentation,
J. Jeong, Y . Zou, T. Kim, D. Zhang, A. Ravichandran, and O. Dabeer, “Winclip: Zero-/few-shot anomaly classifica- tion and segmentation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 19 606–19 616
work page 2023
-
[41]
Adaclip: Adapting clip with hybrid learnable prompts for zero-shot anomaly detection,
Y . Cao, J. Zhang, L. Frittoli, Y . Cheng, W. Shen, and G. Boracchi, “Adaclip: Adapting clip with hybrid learnable prompts for zero-shot anomaly detection,” in European Conference on Computer Vision. Springer, 2024, pp. 55–72
work page 2024
-
[42]
Anoma- lyclip: Object-agnostic prompt learning for zero-shot anomaly detection,
Q. Zhou, G. Pang, Y . Tian, S. He, and J. Chen, “Anoma- lyclip: Object-agnostic prompt learning for zero-shot anomaly detection,”arXiv preprint arXiv:2310.18961, 2023
-
[43]
Y . Sadikaj, H. Zhou, L. Halilaj, S. Schmid, S. Staab, and C. Plant, “Multiads: Defect-aware supervision for multi- type anomaly detection and segmentation in zero-shot learning,”arXiv preprint arXiv:2504.06740, 2025
-
[44]
Y . Cao, X. Xu, C. Sun, X. Huang, and W. Shen, “Towards generic anomaly detection and understanding: Large- scale visual-linguistic model (gpt-4v) takes the lead,” arXiv preprint arXiv:2311.02782, 2023
-
[45]
Cus- tomizing visual-language foundation models for multi- modal anomaly detection and reasoning,
X. Xu, Y . Cao, H. Zhang, N. Sang, and X. Huang, “Cus- tomizing visual-language foundation models for multi- modal anomaly detection and reasoning,” in2025 28th International Conference on Computer Supported Coop- erative Work in Design (CSCWD). IEEE, 2025, pp. 1443–1448
work page 2025
-
[46]
Do llms understand visual anomalies? uncovering llm’s capabil- ities in zero-shot anomaly detection,
J. Zhu, S. Cai, F. Deng, B. C. Ooi, and J. Wu, “Do llms understand visual anomalies? uncovering llm’s capabil- ities in zero-shot anomaly detection,” inProceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 48–57
work page 2024
-
[47]
Gpt-4v-ad: Exploring grounding potential of vqa-oriented gpt-4v for zero-shot anomaly detection,
J. Zhang, H. He, X. Chen, Z. Xue, Y . Wang, C. Wang, L. Xie, and Y . Liu, “Gpt-4v-ad: Exploring grounding potential of vqa-oriented gpt-4v for zero-shot anomaly detection,” inInternational Joint Conference on Artificial Intelligence. Springer, 2024, pp. 3–16
work page 2024
-
[48]
Detect, classify, act: Categorizing industrial anomalies with multi-modal large language models,
S. Mokhtar, A. Mousakhan, S. Galesso, J. Tayyub, and T. Brox, “Detect, classify, act: Categorizing industrial anomalies with multi-modal large language models,” in Proceedings of the Computer Vision and Pattern Recog- nition Conference, 2025, pp. 4058–4067
work page 2025
-
[49]
Iad-r1: Reinforcing consistent reasoning in industrial anomaly detection,
Y . Li, Y . Cao, C. Liu, Y . Xiong, X. Dong, and C. Huang, “Iad-r1: Reinforcing consistent reasoning in industrial anomaly detection,”arXiv preprint arXiv:2508.09178, 2025
-
[50]
P. Zeng, F. Pang, Z. Wang, and A. Yang, “Lr-iad: Mask- IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. XX, NO. X, MONTH 20XX 13 free industrial anomaly detection with logical reasoning,” arXiv preprint arXiv:2504.19524, 2025
-
[51]
A transformer- based siamese network for change detection,
W. G. C. Bandara and V . M. Patel, “A transformer- based siamese network for change detection,” inIEEE In- ternational Geoscience and Remote Sensing Symposium (IGARSS), 2022, pp. 207–210
work page 2022
-
[52]
D. H. Park, T. Darrell, and A. Rohrbach, “Robust change captioning,” inProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, 2019, pp. 4624– 4633
work page 2019
-
[53]
Learning to de- scribe differences between pairs of similar images,
H. Jhamtani and T. Berg-Kirkpatrick, “Learning to de- scribe differences between pairs of similar images,” in Proceedings of the 2018 Conference on Empirical Meth- ods in Natural Language Processing (EMNLP), 2018
work page 2018
-
[54]
Changes to captions: An attentive network for remote sensing change captioning,
S. Chang and P. Ghamisi, “Changes to captions: An attentive network for remote sensing change captioning,” IEEE Transactions on Image Processing, vol. 32, pp. 6047–6060, 2023
work page 2023
-
[55]
Mag- icbrush: A manually annotated dataset for instruction- guided image editing,
K. Zhang, L. Mo, W. Chen, H. Sun, and Y . Su, “Mag- icbrush: A manually annotated dataset for instruction- guided image editing,” inAdvances in Neural Informa- tion Processing Systems, 2023
work page 2023
-
[56]
Onediff: A generalist model for image difference cap- tioning,
E. Hu, L. Guo, T. Yue, Z. Zhao, S. Xue, and J. Liu, “Onediff: A generalist model for image difference cap- tioning,” inProceedings of the Asian Conference on Computer Vision (ACCV), 2024, pp. 2439–2455
work page 2024
-
[57]
Img-diff: Contrastive data synthesis for multimodal large language models,
Q. Jiao, D. Chen, Y . Huang, B. Ding, Y . Li, and Y . Shen, “Img-diff: Contrastive data synthesis for multimodal large language models,”arXiv preprint arXiv:2408.04594, 2024
-
[58]
Coft-ad: Contrastive fine-tuning for few-shot anomaly detection,
J. Liao, X. Xu, M. C. Nguyen, A. Goodge, and C. S. Foo, “Coft-ad: Contrastive fine-tuning for few-shot anomaly detection,”IEEE Transactions on Image Processing, vol. 33, pp. 2090–2103, 2024
work page 2090
-
[59]
R. Zhang and H.-M. Hu, “A multi-category anomaly edit- ing network with correlation exploration and voxel-level attention for unsupervised surface anomaly detection,” IEEE Transactions on Image Processing, 2025
work page 2025
-
[60]
Ad3: Introducing a score for anomaly detection dataset difficulty assessment using viaduct dataset,
J. Lehr, J. Philipps, A. Sargsyan, M. Pape, and J. Kr ¨uger, “Ad3: Introducing a score for anomaly detection dataset difficulty assessment using viaduct dataset,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 449–464
work page 2024
-
[61]
Real-iad: A real-world multi-view dataset for benchmarking versatile industrial anomaly detection,
C. Wang, W. Zhu, B.-B. Gao, Z. Gan, J. Zhang, Z. Gu, S. Qian, M. Chen, and L. Ma, “Real-iad: A real-world multi-view dataset for benchmarking versatile industrial anomaly detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 22 883–22 892
work page 2024
-
[62]
3cad: A large-scale real-world 3c product dataset for unsupervised anomaly detection,
E. Yang, P. Xing, H. Sun, W. Guo, Y . Ma, Z. Li, and D. Zeng, “3cad: A large-scale real-world 3c product dataset for unsupervised anomaly detection,” inProceed- ings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 9, 2025, pp. 9175–9183
work page 2025
-
[63]
S. Jezek, M. Jonak, R. Burget, P. Dvorak, and M. Sko- tak, “Deep learning-based defect detection of metal parts: evaluating current methods in complex conditions,” in2021 13th International congress on ultra modern telecommunications and control systems and workshops (ICUMT). IEEE, 2021, pp. 66–71
work page 2021
-
[64]
P. Bergmann, K. Batzner, M. Fauser, D. Sattlegger, and C. Steger, “Beyond dents and scratches: Logical constraints in unsupervised anomaly detection and local- ization,”International Journal of Computer Vision, vol. 130, no. 4, pp. 947–969, 2022
work page 2022
-
[65]
Pku-goodsad: A supermarket goods dataset for unsupervised anomaly detection and segmentation,
J. Zhang, R. Ding, M. Ban, and L. Dai, “Pku-goodsad: A supermarket goods dataset for unsupervised anomaly detection and segmentation,”IEEE Robotics and Automa- tion Letters, 2024
work page 2024
-
[66]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkatet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[67]
Llava-med: Training a large language-and-vision assistant for biomedicine in one day,
C. Li, C. Wong, S. Zhang, N. Usuyama, H. Liu, J. Yang, T. Naumann, H. Poon, and J. Gao, “Llava-med: Training a large language-and-vision assistant for biomedicine in one day,”Advances in Neural Information Processing Systems, vol. 36, pp. 28 541–28 564, 2023
work page 2023
-
[68]
T. OLMo, P. Walsh, L. Soldaini, D. Groeneveld, K. Lo, S. Arora, A. Bhagia, Y . Gu, S. Huang, M. Jordanet al., “2 olmo 2 furious,”arXiv preprint arXiv:2501.00656, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[69]
Molmo and pixmo: Open weights and open data for state-of-the-art vision-language models,
M. Deitke, C. Clark, S. Lee, R. Tripathi, Y . Yang, J. S. Park, M. Salehi, N. Muennighoff, K. Lo, L. Soldaini et al., “Molmo and pixmo: Open weights and open data for state-of-the-art vision-language models,” inProceed- ings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 91–104
work page 2025
-
[70]
LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models
F. Li, R. Zhang, H. Zhang, Y . Zhang, B. Li, W. Li, Z. Ma, and C. Li, “Llava-next-interleave: Tackling multi- image, video, and 3d in large multimodal models,”arXiv preprint arXiv:2407.07895, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[71]
SFT memorizes, RL generalizes: A comparative study of foundation model post-training,
T. Chu, Y . Zhai, J. Yang, S. Tong, S. Xie, D. Schuurmans, Q. V . Le, S. Levine, and Y . Ma, “SFT memorizes, RL generalizes: A comparative study of foundation model post-training,” inForty-second International Conference on Machine Learning, 2025. [Online]. Available: https://openreview.net/forum?id=dYur3yabMj
work page 2025
-
[72]
Detect anything via next point prediction,
Q. Jiang, J. Huo, X. Chen, Y . Xiong, Z. Zeng, Y . Chen, T. Ren, J. Yu, and L. Zhang, “Detect anything via next point prediction,”arXiv preprint arXiv:2510.12798, 2025
-
[73]
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models
Y . Zheng, R. Zhang, J. Zhang, Y . Ye, Z. Luo, Z. Feng, and Y . Ma, “Llamafactory: Unified efficient fine-tuning of 100+ language models,”arXiv preprint arXiv:2403.13372, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[74]
Perception-r1: Pioneering perception policy with reinforcement learning,
E. Yu, K. Lin, L. Zhao, jisheng yin, Y . Wei, Y . Peng, H. Wei, J. Sun, C. Han, Z. Ge, X. Zhang, D. Jiang, J. Wang, and W. Tao, “Perception-r1: Pioneering perception policy with reinforcement learning,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. [Online]. Available: https: //openreview.net/forum?id=BeXcXrXetA
work page 2025
-
[75]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
M. Reid, N. Savinov, D. Teplyashin, D. Lepikhin, T. Lil- licrap, J.-b. Alayrac, R. Soricut, A. Lazaridou, O. Firat, J. Schrittwieseret al., “Gemini 1.5: Unlocking multi- modal understanding across millions of tokens of con- IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. XX, NO. X, MONTH 20XX 14 text,”arXiv preprint arXiv:2403.05530, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[76]
Qwen3-vl: Sharper vision, deeper thought, broader action,
Q. Team, “Qwen3-vl: Sharper vision, deeper thought, broader action,”Qwen Blog. Accessed, pp. 10–04, 2025
work page 2025
-
[77]
InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
Z. Chen, J. Wu, W. Wang, W. Su, G. Chen, S. Xing, M. Zhong, Q. Zhang, X. Zhu, L. Lu, B. Li, P. Luo, T. Lu, Y . Qiao, and J. Dai, “Internvl: Scaling up vision foun- dation models and aligning for generic visual-linguistic tasks,”arXiv preprint arXiv:2312.14238, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.