Recognition: unknown
Safe reinforcement learning with online filtering for fatigue-predictive human-robot task planning and allocation in production
Pith reviewed 2026-05-10 14:45 UTC · model grok-4.3
The pith
Particle filters update fatigue parameters online to constrain reinforcement learning actions and keep human fatigue safe during human-robot task allocation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By combining particle filter-based online estimation of fatigue model parameters with constrained dueling double deep Q-learning, the PF-CD3Q method makes task-level fatigue predictions during decision-making, excludes actions that exceed fatigue thresholds, and thereby solves the human-robot task planning and allocation problem as a constrained Markov decision process that respects safety limits while pursuing production efficiency.
What carries the argument
PF-CD3Q, the integration of particle filter estimators that track and update fatigue parameters in real time with a constrained dueling double deep Q-learning agent that uses those predictions to shrink the allowable action space.
If this is right
- Task allocation can adapt automatically to daily changes in worker fatigue sensitivity without requiring manually tuned static parameters.
- The reinforcement learning agent never selects tasks whose predicted fatigue contribution would violate the safety constraint at any future time step.
- Production throughput can increase because idle time inserted only to respect fatigue limits is minimized through better online forecasts.
- The overall planning problem is solved by treating it as a constrained Markov decision process whose feasible actions are filtered in real time.
- The same estimators can be reused across shifts or workers once the particle filter has converged on updated parameter values.
Where Pith is reading between the lines
- The same online filtering pattern could be applied to other uncertain human states such as skill level or cognitive load in collaborative robotics.
- If the particle filter proves reliable, similar safety-constrained reinforcement learning pipelines might be tested in domains like autonomous driving or medical scheduling where state estimates must be updated from noisy observations.
- Real-factory deployment would require checking how quickly the filter adapts when a new worker replaces the previous one mid-shift.
- The approach might reduce reliance on periodic manual fatigue surveys by treating observed progression data as the primary input for model updating.
Load-bearing premise
That the fatigue values observed during actual production runs supply enough information for the particle filter to estimate and update the fatigue model parameters accurately enough that the resulting predictions will keep future fatigue within safe limits when used to constrain the reinforcement learning decisions.
What would settle it
A controlled production trial in which actual measured fatigue levels are compared against the particle filter predictions at each decision point, and any task chosen by the system is checked to see whether cumulative fatigue ever exceeds the preset safety threshold.
Figures















read the original abstract
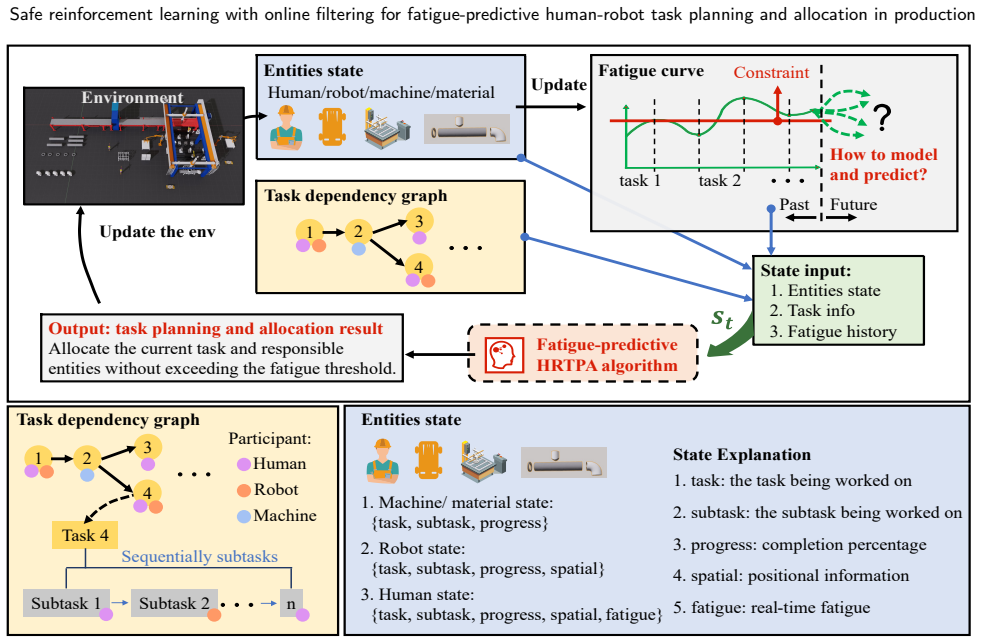
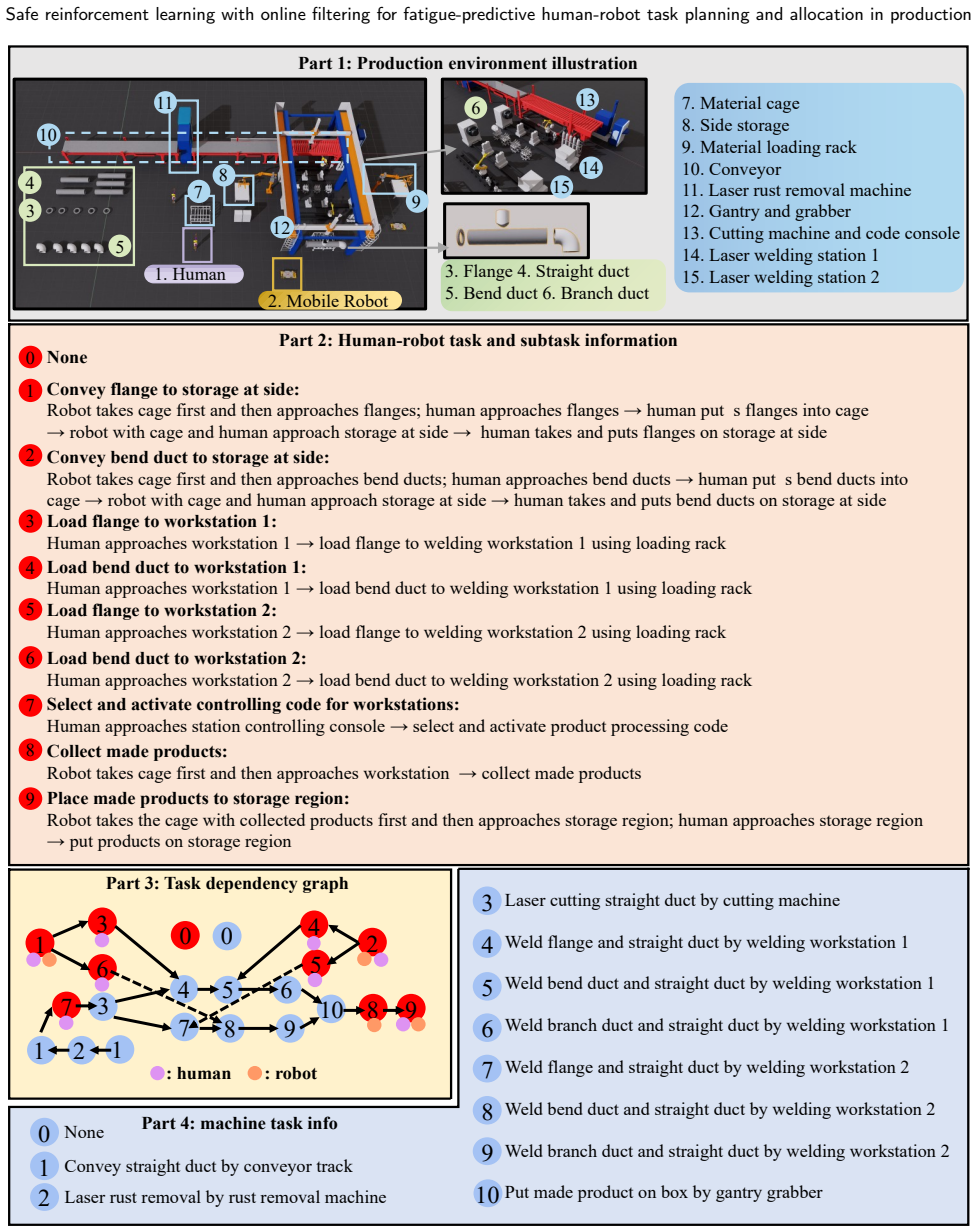
Human-robot collaborative manufacturing, a core aspect of Industry 5.0, emphasizes ergonomics to enhance worker well-being. This paper addresses the dynamic human-robot task planning and allocation (HRTPA) problem, which involves determining when to perform tasks and who should execute them to maximize efficiency while ensuring workers' physical fatigue remains within safe limits. The inclusion of fatigue constraints, combined with production dynamics, significantly increases the complexity of the HRTPA problem. Traditional fatigue-recovery models in HRTPA often rely on static, predefined hyperparameters. However, in practice, human fatigue sensitivity varies daily due to factors such as changed work conditions and insufficient sleep. To better capture this uncertainty, we treat fatigue-related parameters as inaccurate and estimate them online based on observed fatigue progression during production. To address these challenges, we propose PF-CD3Q, a safe reinforcement learning (safe RL) approach that integrates the particle filter with constrained dueling double deep Q-learning for real-time fatigue-predictive HRTPA. Specifically, we first develop PF-based estimators to track human fatigue and update fatigue model parameters in real-time. These estimators are then integrated into CD3Q by making task-level fatigue predictions during decision-making and excluding tasks that exceed fatigue limits, thereby constraining the action space and formulating the problem as a constrained Markov decision process (CMDP).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PF-CD3Q, a safe RL method for dynamic human-robot task planning and allocation (HRTPA) that treats fatigue model parameters as unknown and uses particle-filter estimators to track fatigue state and update parameters online from observed progression; these predictions are then used to prune unsafe tasks from the action space of constrained dueling double deep Q-learning, thereby casting the problem as a CMDP that respects fatigue limits while optimizing efficiency.
Significance. If the particle-filter estimates prove accurate and the resulting one-step-ahead predictions reliably enforce the safety constraints, the work would offer a concrete mechanism for adapting to daily variability in human fatigue sensitivity, which static models cannot address. The integration of online Bayesian filtering with action-space constraints in deep RL is a natural and potentially reusable pattern for safe decision-making under parametric uncertainty.
major comments (2)
- [Abstract] Abstract: the PF-based estimators are asserted to 'track human fatigue and update fatigue model parameters in real-time,' yet the abstract supplies no state-space definition, transition or observation model, likelihood function, or particle-filter hyperparameters. Without these, it is impossible to determine whether the filter can converge under realistic measurement noise and inter-day parameter drift, which is load-bearing for the safety guarantee.
- [Abstract] Abstract: the claim that 'excluding tasks that exceed fatigue limits' yields a safe CMDP rests on the unverified assumption that the PF predictions are sufficiently tight and unbiased. No convergence analysis, observability conditions, synthetic tracking-error results, or real fatigue trajectories are referenced, leaving the central safety assertion without empirical or theoretical support.
minor comments (1)
- The abstract is written as a single dense paragraph; separating the problem motivation, method components, and claimed contributions would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. The feedback correctly identifies that the abstract is too high-level to convey the technical foundations of the PF estimators and the empirical basis for the safety claims. We address each point below, agreeing to revise the abstract while noting where details and results already appear in the main text.
read point-by-point responses
-
Referee: [Abstract] Abstract: the PF-based estimators are asserted to 'track human fatigue and update fatigue model parameters in real-time,' yet the abstract supplies no state-space definition, transition or observation model, likelihood function, or particle-filter hyperparameters. Without these, it is impossible to determine whether the filter can converge under realistic measurement noise and inter-day parameter drift, which is load-bearing for the safety guarantee.
Authors: We agree the abstract omits these specifics. Section 3.2 defines the state-space model for fatigue dynamics, the transition and observation models derived from the fatigue-recovery equations, the likelihood function based on observed fatigue progression, and the PF hyperparameters (particle count, process/measurement noise variances, and resampling threshold). We will revise the abstract to briefly reference the PF model components and direct readers to Section 3.2 for assessing convergence behavior under noise and drift. revision: yes
-
Referee: [Abstract] Abstract: the claim that 'excluding tasks that exceed fatigue limits' yields a safe CMDP rests on the unverified assumption that the PF predictions are sufficiently tight and unbiased. No convergence analysis, observability conditions, synthetic tracking-error results, or real fatigue trajectories are referenced, leaving the central safety assertion without empirical or theoretical support.
Authors: The manuscript reports synthetic tracking-error results and real fatigue trajectories in Sections 4.1 and 5, showing low parameter estimation error and zero fatigue-limit violations under the constrained action space. We will update the abstract to cite these empirical results as support for the safety claims. A formal convergence analysis and observability conditions for the PF under inter-day drift are not provided. revision: partial
- Formal theoretical convergence analysis and observability conditions for the particle filter under inter-day parameter drift are absent from the manuscript.
Circularity Check
No significant circularity in the PF-CD3Q derivation chain
full rationale
The paper's core construction uses particle-filter estimators to track fatigue states and update model parameters online from observed progression data during production. These estimates are then fed into the CD3Q policy to generate one-step-ahead task-level fatigue predictions that prune unsafe actions, thereby enforcing CMDP constraints. This separation keeps the online estimation step independent of the RL reward and performance metric; the predictions are generated from the updated fatigue model rather than being fitted or redefined to match any downstream objective. No equations, self-citations, or ansatzes are shown that would make any claimed prediction equivalent to its inputs by construction. The derivation therefore remains non-circular and self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- fatigue model parameters
axioms (2)
- domain assumption Human fatigue progression can be tracked and its model parameters updated in real time from observed data during production.
- domain assumption The HRTPA problem with fatigue limits can be formulated as a constrained Markov decision process.
Reference graph
Works this paper leans on
-
[1]
Anoteontwoproblemsinconnexionwithgraphs,in:Edsger Wybe Dijkstra: his life, work, and legacy, pp
,2022. Anoteontwoproblemsinconnexionwithgraphs,in:Edsger Wybe Dijkstra: his life, work, and legacy, pp. 287–290. doi:10.1145/ 3544585.3544600
-
[2]
Constrainedpolicy optimization, in: International Conference on Machine Learning, PMLR
Achiam,J.,Held,D.,Tamar,A.,Abbeel,P.,2017. Constrainedpolicy optimization, in: International Conference on Machine Learning, PMLR. pp. 22–31. doi:10.48550/arXiv.1705.09209
-
[3]
Safe reinforcement learning via shielding, in: Pro- ceedings of the AAAI Conference on Artificial Intelligence
Alshiekh, M., Bloem, R., Ehlers, R., Könighofer, B., Niekum, S., Topcu, U., 2018. Safe reinforcement learning via shielding, in: Pro- ceedings of the AAAI Conference on Artificial Intelligence. doi:10. 1609/aaai.v32i1.11797
2018
-
[4]
Asymptotic properties of constrained markov decisionprocesses
Altman, E., 1993. Asymptotic properties of constrained markov decisionprocesses. ZeitschriftfürOperationsResearch37,151–170. doi:10.1007/bf01414154
-
[5]
Constrained Markov Decision Processes
Altman, E., 2021. Constrained Markov Decision Processes. Rout- ledge. doi:10.1201/9781315140223-3
-
[6]
Asadayoobi, N., Taghipour, S., Jaber, M.Y., 2023. Optimising stochastic task allocation and scheduling plans for mission workers subject to learning-forgetting, fatigue-recovery, and stress-recovery effects. ExpertSystemswithApplications229,120524. doi: 10.1016/ j.eswa.2023.120524
-
[7]
Bänziger,T.,Kunz,A.,Wegener,K.,2020. Optimizinghuman–robot task allocation using a simulation tool based on standardized work descriptions. Journal of Intelligent Manufacturing 31, 1635–1648. doi:10.1007/s10845-018-1411-1
-
[8]
International Journal of Production Research 61, 2895–2916
Cai, M., Liang, R., Luo, X., Liu, C., 2023. Task allocation strategies considering task matching and ergonomics in the human-robot col- laborative hybrid assembly cell. International Journal of Production Research 61, 7213–7232. doi:10.1080/00207543.2022.2147234
-
[9]
Calzavara, M., Persona, A., Sgarbossa, F., Visentin, V., 2019. A model for rest allowance estimation to improve tasks assignment to operators. InternationalJournalofProductionResearch57,948–962. doi:10.1080/00207543.2018.1497816
-
[10]
Kalman filter for robot vision: a survey
Chen, S.Y., 2011. Kalman filter for robot vision: a survey. IEEE Transactions on Industrial Electronics 59, 4409–4420. doi:10.1109/ tie.2011.2162714
-
[11]
Bayesian filtering: From kalman filters to particle filters, and beyond
Chen, Z., 2003. Bayesian filtering: From kalman filters to particle filters, and beyond. Statistics 182, 1–69
2003
-
[12]
Taskallocationinmanu- facturing:Areview
Cheng,Y.,Sun,F.,Zhang,Y.,Tao,F.,2019. Taskallocationinmanu- facturing:Areview. JournalofIndustrialInformationIntegration15, 207–218. doi:10.1016/j.jii.2018.08.001
-
[13]
Cherubini, A., Passama, R., Crosnier, A., Lasnier, A., Fraisse, P.,
-
[14]
Robotics and Computer-Integrated Manufacturing 40, 1–13
Collaborativemanufacturingwithphysicalhuman–robotinter- action. Robotics and Computer-Integrated Manufacturing 40, 1–13. doi:10.1016/j.rcim.2015.12.007
-
[15]
Chow, Y., Nachum, O., Faust, A., Duenez-Guzman, E., Ghavamzadeh, M., 2019. Lyapunov-based safe policy optimization for continuous control. arXiv Preprint arXiv:1901.10031 doi:10.48550/arXiv.1901.10031
-
[16]
Managingfatigue:it’saboutsleep
Dawson,D.,McCulloch,K.,2005. Managingfatigue:it’saboutsleep. Sleep Medicine Reviews 9, 365–380. doi:10.1016/j.smrv.2005.03. 002
-
[17]
Acomparativestudyofdeep reinforcement learning models: Dqn vs ppo vs a2c
DeLaFuente,N.,Guerra,D.A.V.,2024. Acomparativestudyofdeep reinforcement learning models: Dqn vs ppo vs a2c. arXiv Preprint arXiv:2407.14151 doi:10.48550/arXiv.2407.14151
-
[18]
Dhanda,M.,Rogers,B.A.,Hall,S.,Dekoninck,E.,Dhokia,V.,2025. Reviewing human-robot collaboration in manufacturing: Opportuni- ties and challenges in the context of industry 5.0. Robotics and Computer-IntegratedManufacturing93,102937.doi: 10.1016/j.rcim. 2024.102937
-
[19]
Theeffect of dynamic worker behavior on flow line performance
Digiesi,S.,Kock,A.A.,Mummolo,G.,Rooda,J.E.,2009. Theeffect of dynamic worker behavior on flow line performance. International JournalofProductionEconomics120,368–377. doi: 10.1016/j.ijpe. 2008.12.012
-
[20]
Proximal Policy Optimization Algorithms
Faccio,M.,Granata,I.,Menini,A.,Milanese,M.,Rossato,C.,Bottin, M., Minto, R., Pluchino, P., Gamberini, L., Boschetti, G., 2023. Human factors in cobot era: a review of modern production systems features. Journal of Intelligent Manufacturing 34, 85–106. doi:10. 48550/arXiv.1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Task allocation model for human-robot collaboration with variable cobot speed
Faccio, M., Granata, I., Minto, R., 2024. Task allocation model for human-robot collaboration with variable cobot speed. Jour- nal of Intelligent Manufacturing 35, 793–806. doi: 10.1007/ s10845-023-02073-9
2024
-
[23]
Fontes, D.B., Homayouni, S.M., Gonçalves, J.F., 2023. A hybrid particle swarm optimization and simulated annealing algorithm for the job shop scheduling problem with transport resources. European Journal of Operational Research 306, 1140–1157. doi:10.1016/j. ejor.2022.09.006
work page doi:10.1016/j 2023
-
[24]
Noisy Networks for Exploration
Fortunato,M.,Azar,M.G.,Piot,B.,Menick,J.,Osband,I.,Graves,A., Mnih, V., Munos, R., Hassabis, D., Pietquin, O., Blundell, C., Legg, S., 2017. Noisy networks for exploration. CoRR abs/1706.10295. doi:10.48550/arXiv.1706.10295
-
[26]
Gong, X., Wang, T., Huang, T., Cui, Y., 2022. Toward safe and effi- cienthuman–swarmcollaboration:Ahierarchicalmulti-agentpickup and delivery framework. IEEE Transactions on Intelligent Vehicles 8, 1664–1675. doi:10.1109/tiv.2022.3172342
-
[27]
Gu, S., Yang, L., Du, Y., Chen, G., Walter, F., Wang, J., Knoll, A.,
-
[28]
A review of safe reinforcement learning: Methods, theories andapplications.IEEETransactionsonPatternAnalysisandMachine Intelligence doi:10.1109/tpami.2024.3457538
-
[29]
Particle filters for positioning, navigation,andtracking
Gustafsson, F., Gunnarsson, F., Bergman, N., Forssell, U., Jansson, J., Karlsson, R., Nordlund, P.J., 2002. Particle filters for positioning, navigation,andtracking. IEEETransactionsonSignalProcessing50, 425–437. doi:10.1109/78.978396
-
[30]
Deep residual learning for image recognition, in: Proceedings of the IEEE Conference on ComputerVisionandPatternRecognition,pp.770–778
He, K., Zhang, X., Ren, S., Sun, J., 2016. Deep residual learning for image recognition, in: Proceedings of the IEEE Conference on ComputerVisionandPatternRecognition,pp.770–778. doi: 10.1109/ CVPR.2016.90
2016
-
[31]
Hietanen,A.,Pieters,R.,Lanz,M.,Latokartano,J.,Kämäräinen,J.K.,
-
[32]
doi:10.1016/j.rcim.2019.101891
Ar-based interaction for human-robot collaborative manufac- turing.RoboticsandComputer-IntegratedManufacturing63,101891. doi:10.1016/j.rcim.2019.101891
-
[33]
Huang, S., Wang, B., Li, X., Zheng, P., Mourtzis, D., Wang, L.,
-
[34]
Journal of Manufacturing Systems 64, 424–428
Industry 5.0 and society 5.0—comparison, complementation and co-evolution. Journal of Manufacturing Systems 64, 424–428. doi:10.1016/j.jmsy.2022.07.010
-
[35]
Incorporating human fatigue and recovery into the learning–forgetting process
Jaber, M.Y., Givi, Z., Neumann, W.P., 2013. Incorporating human fatigue and recovery into the learning–forgetting process. Applied MathematicalModelling37,7287–7299. doi:10.1016/j.apm.2013.02. 028
-
[36]
Omnisafe: An infrastructure for acceleratingsafereinforcementlearningresearch
Ji, J., Zhou, J., Zhang, B., Dai, J., Pan, X., Sun, R., Huang, W., Geng, Y., Liu, M., Yang, Y., 2024. Omnisafe: An infrastructure for acceleratingsafereinforcementlearningresearch. JournalofMachine Learning Research 25, 1–6
2024
-
[37]
Kalweit, G., Huegle, M., Werling, M., Boedecker, J., 2020. Deep constrained q-learning. arXiv Preprint arXiv:2003.09398 doi: 10. 48550/arXiv.2003.09398
-
[38]
Ergonomic design of human-robot collaborative workstation in the era of industry 5.0
Keshvarparast,A.,Berti,N.,Chand,S.,Guidolin,M.,Lu,Y.,Battaia, O., Xu, X., Battini, D., 2024. Ergonomic design of human-robot collaborative workstation in the era of industry 5.0. Computers & Industrial Engineering 198, 110729. doi:10.1016/j.cie.2024.110729
-
[39]
Kim, E., Kirschner, R., Yamada, Y., Okamoto, S., 2020. Estimating probability of human hand intrusion for speed and separation moni- toring using interference theory. Robotics and Computer-Integrated Manufacturing 61, 101819. doi:10.1016/j.rcim.2019.101819
-
[40]
Adam: A Method for Stochastic Optimization
Kingma,D.P.,Ba,J.,2015. Adam:Amethodforstochasticoptimiza- tion, in: ICLR (Poster). doi:10.48550/arXiv.1412.6980
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1412.6980 2015
-
[41]
Work/rest: Part ii-the scientific basis (knowledge base) for the guide
Konz, S., 1998. Work/rest: Part ii-the scientific basis (knowledge base) for the guide. International Journal of Industrial Ergonomics 22, 73–99. doi:10.1016/s0169-8141(97)00069-3
-
[42]
Krupas, M., Chand, S., Lu, Y., Xu, X., Kajati, E., Zolotova, I.,
-
[43]
Human-centric uav-ugv collaboration, in: 2023 IEEE 19th International Conference on Automation Science and Engineering (CASE), IEEE. pp. 1–6. doi:10.1109/case56687.2023.10260412
-
[44]
Digital twin-driven deep reinforcement learning for adaptive task allocation in robotic construction
Lee, D., Lee, S., Masoud, N., Krishnan, M., Li, V.C., 2022a. Digital twin-driven deep reinforcement learning for adaptive task allocation in robotic construction. Advanced Engineering Informatics 53, 101710. doi:10.1016/j.aei.2022.101710
-
[45]
Lee, M.L., Behdad, S., Liang, X., Zheng, M., 2022b. Task allocation and planning for product disassembly with human–robot collabora- tion. Robotics and Computer-Integrated Manufacturing 76, 102306. doi:10.1016/j.rcim.2021.102306
-
[46]
Industry 5.0: Prospect and retrospect
Leng,J.,Sha,W.,Wang,B.,Zheng,P.,Zhuang,C.,Liu,Q.,Wuest,T., Mourtzis, D., Wang, L., 2022. Industry 5.0: Prospect and retrospect. Journal of Manufacturing Systems 65, 279–295. doi:10.1016/j.jmsy. 2022.09.017
-
[47]
A q-learning improved differential evolution algorithm for human-centric dynamic distributed flexible job shop scheduling problem
Li, X., Guo, A., Yin, X., Tang, H., Wu, R., Zhao, Q., Li, Y., Wang, X., 2025. A q-learning improved differential evolution algorithm for human-centric dynamic distributed flexible job shop scheduling problem. Journal of Manufacturing Systems 80, 794–823. doi:10. 1016/j.jmsy.2025.04.001
2025
-
[48]
Knowledgegraph- enabled adaptive work packaging approach in modular construction
Li,X.,Wu,C.,Yang,Z.,Guo,Y.,Jiang,R.,2023. Knowledgegraph- enabled adaptive work packaging approach in modular construction. Knowledge-BasedSystems260,110115. doi: 10.1016/j.knosys.2022. 110115
-
[49]
Liang, J., Makoviychuk, V., Handa, A., Chentanez, N., Macklin, M., Fox, D., 2018. Gpu-accelerated robotic simulation for distributed reinforcement learning, in: Conference on Robot Learning, PMLR. pp. 270–282. doi:10.11371/journmlr.v87.liang18a
-
[50]
Liu,Y.,Ding,J.,Liu,X.,2020. Ipo:Interior-pointpolicyoptimization underconstraints,in:ProceedingsoftheAAAIConferenceonArtifi- cial Intelligence, pp. 4940–4947. doi:10.1609/aaai.v34i04.5932
-
[51]
Liu, Y., Fan, J., Zhao, L., Shen, W., Zhang, C., 2023. Integration of deep reinforcement learning and multi-agent system for dynamic scheduling of re-entrant hybrid flow shop considering worker fatigue and skill levels. Robotics and Computer-Integrated Manufacturing 84, 102605. doi:10.1016/j.rcim.2023.102605
-
[52]
Brainwave-driven human-robot collaboration in construction
Liu, Y., Habibnezhad, M., Jebelli, H., 2021. Brainwave-driven human-robot collaboration in construction. Automation in Construc- tion 124, 103556. doi:10.1016/j.autcon.2021.103556
-
[53]
Human–robotcollaborative scheduling in energy-efficient welding shop
Lu,C.,Gao,R.,Yin,L.,Zhang,B.,2023. Human–robotcollaborative scheduling in energy-efficient welding shop. IEEE Transactions on Industrial Informatics 20, 963–971. doi:10.1109/tii.2023.3271749
-
[54]
Malik, A.A., Masood, T., Brem, A., 2024. Intelligent humanoid robots in manufacturing, in: Companion of the 2024 ACM/IEEE International Conference on Human-Robot Interaction, pp. 20–27. doi:10.1145/3610978.3640765
-
[55]
Matheson,E.,Minto,R.,Zampieri,E.G.,Faccio,M.,Rosati,G.,2019. Human–robot collaboration in manufacturing applications: a review. Robotics 8, 100. doi:10.3390/robotics8040100
-
[56]
Impact of environmen- tal conditions on workers’ productivity and health
Meegahapola, P.A., Prabodanie, R.R., 2018. Impact of environmen- tal conditions on workers’ productivity and health. International Journal of Workplace Health Management 11, 74–84. doi:10.1108/ ijwhm-10-2017-0082
2018
-
[57]
An ergonomic role allocation framework for dynamic human–robot collaborative tasks
Merlo, E., Lamon, E., Fusaro, F., Lorenzini, M., Carfì, A., Mas- trogiovanni, F., Ajoudani, A., 2023. An ergonomic role allocation framework for dynamic human–robot collaborative tasks. Journal of Manufacturing Systems 67, 111–121. doi:10.1016/j.jmsy.2022.12. 011
-
[58]
Playing Atari with Deep Reinforcement Learning
Mnih,V.,2013. Playingatariwithdeepreinforcementlearning. arXiv preprint doi:10.48550/arXiv.1312.5602
work page internal anchor Pith review doi:10.48550/arxiv.1312.5602 2013
-
[59]
Safe exploration in markov decision processes
Moldovan, T.M., Abbeel, P., 2012. Safe exploration in markov deci- sion processes, in: Proceedings of the 29th International Conference onMachineLearning,pp.1451–1458. doi: 10.48550/arXiv.1205.4810
-
[60]
Junior: The stanford entry in the urban challenge
Montemerlo, M., Becker, J., Bhat, S., Dahlkamp, H., Dolgov, D., Ettinger,S.,Haehnel,D.,Hilden,T.,Hoffmann,G.,Huhnke,B.,2008. Junior: The stanford entry in the urban challenge. Journal of Field Robotics 25, 569–597. doi:10.1007/978-3-642-03991-1_3
-
[61]
A survey of robot learning strategies for human-robot collaboration in industrialsettings
Mukherjee, D., Gupta, K., Chang, L.H., Najjaran, H., 2022. A survey of robot learning strategies for human-robot collaboration in industrialsettings. RoboticsandComputer-IntegratedManufacturing 73, 102231. doi:10.1016/j.rcim.2021.102231
-
[62]
Ostermeier,F.F.,2020. Theimpactofhumanconsideration,schedule types and product mix on scheduling objectives for unpaced mixed- model assembly lines. International Journal of Production Research Jintao Xue et al.:Preprint submitted to Elsevier Page 24 of 27 Safe reinforcement learning with online filtering for fatigue-predictive human-robot task planning a...
-
[63]
Decentralized task allocation in multi-agent systems using a decentralized genetic algorithm, in: 2020 IEEE International Conference on Robotics and Automation (ICRA), IEEE
Patel,R.,Rudnick-Cohen,E.,Azarm,S.,Otte,M.,Xu,H.,Herrmann, J.W., 2020. Decentralized task allocation in multi-agent systems using a decentralized genetic algorithm, in: 2020 IEEE International Conference on Robotics and Automation (ICRA), IEEE. pp. 3770–
2020
-
[64]
doi:10.1109/icra40945.2020.9197314
-
[65]
Aselective muscle fatigue management approach to ergonomic human-robot co- manipulation
Peternel,L.,Fang,C.,Tsagarakis,N.,Ajoudani,A.,2019. Aselective muscle fatigue management approach to ergonomic human-robot co- manipulation. Robotics and Computer-Integrated Manufacturing 58, 69–79. doi:10.1016/j.rcim.2019.01.013
-
[66]
Prunet, T., Absi, N., Borodin, V., Cattaruzza, D., 2024. Optimization ofhuman-awarelogisticsandmanufacturingsystems:Asurveyonthe human-awaremodels.EUROJournalonTransportationandLogistics , 100137doi:10.1016/j.ejtl.2024.100137
-
[67]
Benchmarking safe exploration in deep reinforcement learning,
Ray, A., Achiam, J., Amodei, D., 2019. Benchmarking safe exploration in deep reinforcement learning. arXiv Preprint arXiv:1910.01708
-
[68]
Schaul, T., 2015. Prioritized experience replay. arXiv preprint doi:10.48550/arXiv.1511.05952
-
[69]
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., Klimov, O.,
-
[70]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms. arXiv Preprint arXiv:1707.06347 doi:10.48550/arXiv.1707.06347
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1707.06347
-
[71]
Stooke, A., Achiam, J., Abbeel, P., 2020. Responsive safety in reinforcement learning by pid lagrangian methods, in: International Conference on Machine Learning, PMLR. pp. 9133–9143. doi:10. 48550/arXiv.2006.04609
-
[72]
Sutton, R.S., Barto, A.G., 1998. Reinforcement Learning: An Intro- duction. volume 1. MIT Press. doi:10.1109/TNN.1998.712192
-
[73]
Reward Constrained Policy Optimization
Tessler, C., Mankowitz, D.J., Mannor, S., 2018. Reward constrained policy optimization. arXiv Preprint arXiv:1805.11074 doi:10.48550/ arXiv.1805.11074
work page Pith review arXiv 2018
-
[74]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
VanHasselt,H.,Guez,A.,Silver,D.,2016.Deepreinforcementlearn- ing with double q-learning, in: Proceedings of the AAAI Conference on Artificial Intelligence. doi:10.1609/aaai.v30i1.10295
-
[75]
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez, A.N., Kaiser, Ł., Polosukhin, I., 2017. Attention is all you need. AdvancesinNeuralInformationProcessingSystems30. doi: 10.5555/ 3295222.3295349
-
[76]
Wang, B., Song, C., Li, X., Zhou, H., Yang, H., Wang, L., 2025a. A deep learning-enabled visual-inertial fusion method for human pose estimation in occluded human-robot collaborative assembly scenar- ios. Robotics and Computer-Integrated Manufacturing 93, 102906. doi:10.1016/j.rcim.2024.102906
-
[77]
Deep learning-based human motion recognition for predictive context-aware human-robot collaboration
Wang, P., Liu, H., Wang, L., Gao, R.X., 2018. Deep learning-based human motion recognition for predictive context-aware human-robot collaboration. CIRP annals 67, 17–20. doi:10.1016/j.cirp.2018.04. 066
-
[78]
Wang, T., Liu, Z., Wang, L., Li, M., Wang, X.V., 2025b. A design framework for high-fidelity human-centric digital twin of collabora- tive work cell in industry 5.0. Journal of Manufacturing Systems 80, 140–156. doi:10.1016/j.jmsy.2025.02.018
-
[79]
Wang,Z.,Schaul,T.,Hessel,M.,Hasselt,H.,Lanctot,M.,Freitas,N.,
-
[80]
Duelingnetworkarchitecturesfordeepreinforcementlearning, in:InternationalConferenceonMachineLearning,PMLR.pp.1995–
1995
-
[81]
doi:10.11371/journmlr.v48.wangf16
-
[82]
Learning from delayed rewards
Watkins, C.J.C.H., 1989. Learning from delayed rewards
1989
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.