Recognition: unknown
AffectAgent: Collaborative Multi-Agent Reasoning for Retrieval-Augmented Multimodal Emotion Recognition
Pith reviewed 2026-05-10 15:17 UTC · model grok-4.3
The pith
AffectAgent uses three collaborating agents to retrieve and reason about multimodal emotions more accurately than single-round methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
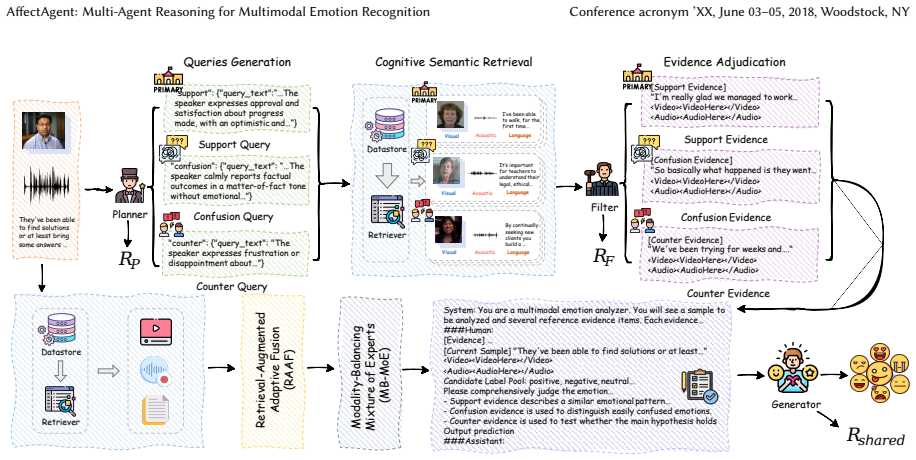
AffectAgent is an affect-oriented multi-agent retrieval-augmented generation framework comprising a query planner, an evidence filter, and an emotion generator that collaboratively retrieve cross-modal samples, assess evidence, and generate predictions; the agents are optimized end-to-end with MAPPO using a shared affective reward, augmented by MB-MoE to regulate modality contributions and RAAF to complete semantics under missing modalities.
What carries the argument
The three-agent collaborative structure (query planner, evidence filter, emotion generator) jointly optimized via MAPPO with a shared affective reward, which decomposes retrieval-augmented reasoning into planning, filtering, and generation steps for consistent cross-modal affective understanding.
If this is right
- AffectAgent achieves superior performance across complex scenarios on MER-UniBench.
- MB-MoE dynamically balances modality contributions to reduce representation mismatch from cross-modal heterogeneity.
- RAAF improves semantic completion under missing-modality conditions by incorporating retrieved audiovisual embeddings.
- End-to-end MAPPO optimization with the shared reward produces more consistent emotion predictions than independent agent training.
Where Pith is reading between the lines
- The same agent decomposition could be tested on other ambiguous multimodal tasks such as medical image-text diagnosis.
- Shared-reward reinforcement learning may generalize as a way to align specialized agents in retrieval-augmented pipelines beyond emotion recognition.
- Scaling experiments on larger or real-time multimodal streams would show whether the added coordination cost remains acceptable.
Load-bearing premise
Joint optimization via MAPPO with a shared affective reward will align the three agents to produce consistent cross-modal understanding without coordination failures or reward exploitation that hides underlying modal ambiguity.
What would settle it
If the system shows no accuracy gain over single-round RAG baselines or exhibits persistent disagreements among the three agents when tested on a dataset of known cross-modal ambiguities, the claim of reliable collaborative affective understanding would not hold.
Figures



read the original abstract
LLM-based multimodal emotion recognition relies on static parametric memory and often hallucinates when interpreting nuanced affective states. In this paper, given that single-round retrieval-augmented generation is highly susceptible to modal ambiguity and therefore struggles to capture complex affective dependencies across modalities, we introduce AffectAgent, an affect-oriented multi-agent retrieval-augmented generation framework that leverages collaborative decision-making among agents for fine-grained affective understanding. Specifically, AffectAgent comprises three jointly optimized specialized agents, namely a query planner, an evidence filter, and an emotion generator, which collaboratively perform analytical reasoning to retrieve cross-modal samples, assess evidence, and generate predictions. These agents are optimized end-to-end using Multi-Agent Proximal Policy Optimization (MAPPO) with a shared affective reward to ensure consistent emotion understanding. Furthermore, we introduce Modality-Balancing Mixture of Experts (MB-MoE) and Retrieval-Augmented Adaptive Fusion (RAAF), where MB-MoE dynamically regulates the contributions of different modalities to mitigate representation mismatch caused by cross-modal heterogeneity, while RAAF enhances semantic completion under missing-modality conditions by incorporating retrieved audiovisual embeddings. Extensive experiments on MER-UniBench demonstrate that AffectAgent achieves superior performance across complex scenarios. Our code will be released at: https://github.com/Wz1h1NG/AffectAgent.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes AffectAgent, a collaborative multi-agent RAG framework for multimodal emotion recognition to address modal ambiguity in LLM-based systems. It features three agents (query planner, evidence filter, emotion generator) optimized end-to-end via MAPPO with a shared affective reward. Additional modules MB-MoE and RAAF are introduced for modality balancing and adaptive fusion. The paper reports superior performance on the MER-UniBench dataset across complex scenarios.
Significance. If validated, the results would indicate that multi-agent collaborative reasoning can improve fine-grained affective understanding in retrieval-augmented settings. This has potential significance for affective computing and multi-agent RL applications. The planned code release is a strength that aids reproducibility.
major comments (3)
- [Abstract] Abstract: The claim of superior performance lacks any quantitative support, such as specific accuracy or F1 scores, baseline comparisons, or p-values, which is essential for substantiating the effectiveness of the proposed framework.
- [§3.3] §3.3: The MAPPO training with shared reward is described without addressing non-stationarity or providing evidence that it leads to stable collaboration and distinct roles among agents, which is load-bearing for the collaborative decision-making claim.
- [§4.2] §4.2: No ablation studies are presented that isolate the MAPPO multi-agent component from MB-MoE and RAAF, making it impossible to determine if the performance gains stem from the collaborative reasoning or other elements.
minor comments (1)
- [Abstract] Abstract: The description of RAAF could be clarified by specifying how retrieved audiovisual embeddings are incorporated.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps clarify the presentation of our results and the analysis of the multi-agent framework. We address each major comment below and will revise the manuscript accordingly to strengthen the claims and supporting evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim of superior performance lacks any quantitative support, such as specific accuracy or F1 scores, baseline comparisons, or p-values, which is essential for substantiating the effectiveness of the proposed framework.
Authors: We agree that the abstract would be strengthened by including quantitative results. The full manuscript contains detailed tables with accuracy, F1 scores, and baseline comparisons on MER-UniBench, but these are not summarized in the abstract. In the revised version, we will update the abstract to report key metrics (e.g., overall accuracy and F1 improvements) and note the statistical significance where applicable. revision: yes
-
Referee: [§3.3] §3.3: The MAPPO training with shared reward is described without addressing non-stationarity or providing evidence that it leads to stable collaboration and distinct roles among agents, which is load-bearing for the collaborative decision-making claim.
Authors: We acknowledge that §3.3 focuses on the architectural setup and shared reward design but does not explicitly discuss non-stationarity or include empirical evidence of stable collaboration. In the revision, we will expand this section to explain how MAPPO's centralized value function and the shared affective reward mitigate non-stationarity, and we will add training curves or convergence metrics demonstrating stable policy updates and the differentiation of agent roles (query planner, evidence filter, emotion generator) over the course of training. revision: yes
-
Referee: [§4.2] §4.2: No ablation studies are presented that isolate the MAPPO multi-agent component from MB-MoE and RAAF, making it impossible to determine if the performance gains stem from the collaborative reasoning or other elements.
Authors: We agree that isolating the MAPPO multi-agent optimization from the MB-MoE and RAAF modules is necessary to attribute performance gains precisely. The current experiments evaluate the full system against external baselines but lack internal ablations that disable or replace the collaborative MAPPO component. In the revised manuscript, we will add ablation studies (e.g., single-agent MAPPO variants or non-collaborative optimization baselines) while keeping MB-MoE and RAAF fixed, to quantify the contribution of the multi-agent reasoning. revision: yes
Circularity Check
No circularity: empirical multi-agent framework with no derivations or self-referential reductions
full rationale
The paper describes an empirical framework (AffectAgent with query planner, evidence filter, and emotion generator optimized via MAPPO and shared reward, plus MB-MoE and RAAF modules) evaluated on MER-UniBench. No mathematical equations, derivations, fitted parameters presented as predictions, or load-bearing self-citations appear in the provided text. Claims rest on experimental results rather than any chain that reduces to its own inputs by construction. This is a standard empirical ML contribution with independent experimental validation and no circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mohammad Mahdi Abootorabi, Amirhosein Zobeiri, Mahdi Dehghani, Mohammadali Mohammadkhani, Bardia Mohammadi, Omid Ghahroodi, and Mahdieh Baghshah. 2025. Ask in Any Modality: A Comprehensive Survey on Multimodal Retrieval-Augmented Generation. InFindings of the Association for Computational Linguistics: ACL 2025
2025
-
[2]
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Ha- jishirzi. 2024. Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection. InProceedings of the 12th International Confer- ence on Learning Representations (ICLR)
2024
-
[3]
Julia Belikova et al. 2024. DeepPavlov at SemEval-2024 Task 3: Multi- modal Large Language Models in Emotion Reasoning. InProceedings of the 18th International Workshop on Semantic Evaluation (SemEval-2024)
2024
-
[4]
Wenhu Chen, Hexiang Hu, Chitwan Saharia, and William W. Co- hen. 2022. MuRAG: Multimodal Retrieval-Augmented Generator for Open Question Answering over Images and Text. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP). 5558–5570
2022
-
[5]
Yiqun Chen, Lingyong Yan, Weiwei Sun, Xinyu Ma, Yi Zhang, Shuaiqiang Wang, Dawei Yin, Yiming Yang, and Jiaxin Mao. 2025. MMoA: Improving Retrieval-Augmented Generation through Multi- Agent Reinforcement Learning. InAdvances in Neural Information Pro- cessing Systems (NeurIPS)
2025
-
[6]
Hauptmann
Zebang Cheng, Zhi-Qi Cheng, Jun-Yan He, Kai Wang, Yuxiang Lin, Zheng Lian, Xiaojiang Peng, and Alexander G. Hauptmann. 2024. Emotion-LLaMA: Multimodal Emotion Recognition and Reasoning with Instruction Tuning. InAdvances in Neural Information Processing Sys- tems
2024
-
[7]
Zesen Cheng, Sicong Li, Jiaming Chen, Fuzhao Chen, Hang Zhang, Yuzi Dong, Mude Sun, Xin Li, Mingyu Gao, Jianwei Liu, et al . 2024. VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Un- derstanding in Video-LLMs.arXiv preprint arXiv:2406.07476(2024)
work page internal anchor Pith review arXiv 2024
-
[8]
Zebang Cheng, Yuxiang Lin, Zhiqi Chen, Xiang Li, Shuyi Mao, Fan Zhang, Dongdong Ding, Bowen Zhang, and Xiaojiang Peng. 2023. Semi- supervised multimodal emotion recognition with expression MAE. In Proceedings of the 31st ACM International Conference on Multimedia. 9436–9440
2023
-
[9]
Roddy Cowie, Ellen Douglas-Cowie, Nicolas Tsapatsoulis, George Votsis, Stefanos Kollias, Winfried Fellenz, and John G Taylor. 2001. Emotion recognition in human-computer interaction.IEEE Signal Processing Magazine18, 1 (2001), 32–80
2001
-
[10]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova
-
[11]
InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Hu- man Language Technologies
BERT: Pre-training of deep bidirectional transformers for lan- guage understanding. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Hu- man Language Technologies. 4171–4186
2019
-
[12]
Moataz El Ayadi, Mohamed S Kamel, and Fakhri Karray. 2011. Survey on speech emotion recognition: Features, classification schemes, and databases.Pattern Recognition44, 3 (2011), 572–587
2011
- [13]
-
[14]
Wei Han, Hui Chen, and Soujanya Poria. 2021. Improving multimodal fusion with hierarchical mutual information maximization for mul- timodal sentiment analysis. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 9180–9192
2021
-
[15]
Ross, Cordelia Schmid, and Karteek Alahari
Ziniu Hu, Ahmet Iscen, Chen Sun, Kai-Wei Chang, Yizhou Sun, David A. Ross, Cordelia Schmid, and Karteek Alahari. 2023. REVEAL: Retrieval- Augmented Visual-Language Pre-Training with Multi-Source Multi- modal Knowledge Memory. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 23369–23379
2023
-
[16]
Ao Jia, Yu He, Yazhou Zhang, Sagar Uprety, Dawei Song, and Christina Lioma. 2022. Beyond emotion: A multi-modal dataset for human desire understanding. InProceedings of the 2022 Conference of the North Amer- ican Chapter of the Association for Computational Linguistics: Human Language Technologies. 1512–1522
2022
-
[17]
Xu, Luyu Gao, Zhiqing Sun, Qiao Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig
Zhengbao Jiang, Frank F. Xu, Luyu Gao, Zhiqing Sun, Qiao Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023. Active Retrieval Augmented Generation. InProceedings of the 2023 Con- ference on Empirical Methods in Natural Language Processing (EMNLP). 7969–7992
2023
-
[18]
Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2019. Billion-scale similarity search with GPUs.IEEE Transactions on Big Data7, 3 (2019), 535–547
2019
- [19]
-
[20]
Zhenglun Kong, Yize Li, Fanhu Zeng, Lei Xin, Shvat Messica, Xue Lin, Pu Zhao, Manolis Kellis, Hao Tang, and Marinka Zitnik. 2026. Token Reduction Should Go Beyond Efficiency in Generative Models – From Vision, Language to Multimodality. arXiv:2505.18227 [cs.LG] https://arxiv.org/abs/2505.18227
- [21]
-
[22]
Kunchang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. 2025. VideoChat: Chat-centric video understanding.Science China Information Sciences68, 10 (2025), 200102
2025
-
[23]
Shan Li and Weihong Deng. 2022. Deep facial expression recognition: A survey.IEEE Transactions on Affective Computing13, 3 (2022), 1195– 1215
2022
-
[24]
Xinze Li, Sen Mei, Zhenghao Liu, Yukun Yan, Shuo Wang, Shi Yu, Zheni Zeng, Hao Chen, Ge Yu, Zhiyuan Liu, Maosong Sun, and Chenyan Xiong
-
[25]
InProceedings of the 13th International Conference on Learning Representations (ICLR)
RAG-DDR: Optimizing Retrieval-Augmented Generation Using Differentiable Data Rewards. InProceedings of the 13th International Conference on Learning Representations (ICLR)
-
[26]
Zheng Lian, Haoyu Chen, Lan Chen, Haiyang Sun, Licai Sun, Yong Ren, Zebang Cheng, Bin Liu, Rui Liu, Xiaojiang Peng, Jiangyan Yi, and Jianhua Tao. 2025. AffectGPT: A New Dataset, Model, and Benchmark for Emotion Understanding with Multimodal Large Language Models. InProceedings of the 42nd International Conference on Machine Learning
2025
-
[27]
Tian Liang, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Ru, Zhaopeng Tu, Shuming Shi, and Xing Xu. 2024. Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP)
2024
-
[28]
Zhun Liu, Ying Shen, Varun Bharadhwaj Lakshminarasimhan, Paul Pu Liang, Amir Zadeh, and Louis-Philippe Morency. 2018. Efficient low- rank multimodal fusion with modality-specific factors. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics. 2247–2256
2018
- [29]
-
[30]
Zhishu Liu, Kaishen Yuan, Bo Zhao, Yong Xu, and Zitong Yu. 2025. Au-llm: Micro-expression action unit detection via enhanced llm-based feature fusion. InChinese Conference on Biometric Recognition. Springer, 355–365
2025
- [31]
-
[32]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wain- wright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Chris- tiano, Jan Leike, and Ryan Lowe. 2022. Training Language Models to Follow Instructions with...
2022
-
[33]
Rosalind W Picard, Elias Vyzas, and Jennifer Healey. 2001. Toward machine emotional intelligence: Analysis of affective physiological state.IEEE Transactions on Pattern Analysis and Machine Intelligence23, 10 (2001), 1175–1191
2001
-
[34]
Vittorio Pipoli, Alessia Saporita, Federico Bolelli, Marcella Cornia, Lorenzo Baraldi, Costantino Grana, Rita Cucchiara, and Elisa Ficarra
-
[35]
InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision (ICCV)
MISSRAG: Addressing the Missing Modality Challenge in Multi- modal Large Language Models. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision (ICCV)
-
[36]
Soujanya Poria, Erik Cambria, Rajiv Bajpai, and Amir Hussain. 2017. A review of affective computing: From unimodal analysis to multimodal emotion recognition.Information Fusion37 (2017), 98–125
2017
-
[37]
Wasifur Rahman, Md Kamrul Hasan, Sangwu Lee, AmirAli Bagher Zadeh, Chengfeng Mao, Louis-Philippe Morency, and Ehsan Hoque
-
[38]
InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics
Integrating multimodal information in large pretrained trans- formers. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2359–2369
-
[39]
Björn W Schuller. 2018. Speech emotion recognition: Two decades in a nutshell, benchmarks, and ongoing trends.Commun. ACM61, 5 (2018), 90–99
2018
-
[40]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
John Schulman, Philipp Moritz, Sergey Levine, Michael I. Jordan, and Pieter Abbeel. 2016. High-Dimensional Continuous Control Using Generalized Advantage Estimation. InProc. Int. Conf. Learn. Represent. (ICLR). https://arxiv.org/abs/1506.02438
work page internal anchor Pith review arXiv 2016
-
[41]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Proximal Policy Optimization Algorithms (PPO).arXiv preprint arXiv:1707.06347(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[42]
Mohammad Soleymani, David Garcia, Brendan Jou, Björn Schuller, Shih- Fu Chang, and Maja Pantic. 2017. A survey of multimodal emotion recognition.Image and Vision Computing65 (2017), 1–14
2017
-
[43]
Yixuan Su, Tian Lan, Huayang Li, Jialu Xu, Yan Wang, and Deng Cai
- [44]
-
[45]
Ma, Muqiao Yang, Ruslan Salakhutdi- nov, and Louis-Philippe Morency
Yao-Hung Hubert Tsai, Martin Q. Ma, Muqiao Yang, Ruslan Salakhutdi- nov, and Louis-Philippe Morency. 2020. Multimodal routing: Improving local and global interpretability of multimodal language analysis. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing
2020
-
[46]
Kai Wang, Xiaojiang Peng, Jianfei Yang, Debin Meng, and Yu Qiao
-
[47]
Region attention networks for pose and occlusion robust facial expression recognition.IEEE Transactions on Image Processing29 (2020), 4057–4069
2020
-
[48]
Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Ma- jumder, and Furu Wei. 2024. Multilingual E5 Text Embeddings: A Technical Report.arXiv preprint arXiv:2402.05672(2024)
work page internal anchor Pith review arXiv 2024
-
[49]
Tao Wang, X. Lin, Y. Xu, Q. Ye, D. Guo, Sergio Escalera, G. Khoriba, and Z. Yu. 2026. Micro-gesture Recognition: A Comprehensive Survey of Datasets, Methods, and Challenges.Machine Intelligence Research23, 2 (2026), 308–331. doi:10.1007/s11633-025-1629-x
-
[50]
Zhuofan Wen, Zheng Lian, Shun Chen, Hailiang Yao, Longjiang Yang, Bin Liu, and Jianhua Tao. 2025. Listen, Watch, and Learn to Feel: Retrieval-Augmented Emotion Reasoning for Compound Emotion Gen- eration. InFindings of the Association for Computational Linguistics: ACL 2025
2025
-
[51]
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, and Chi Wang
-
[52]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation.arXiv preprint arXiv:2308.08155(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [53]
-
[54]
Lei Xin, Caiyun Huang, Hao Li, Shihong Huang, Yuling Feng, Zhenglun Kong, Zicheng Liu, Siyuan Li, Chang Yu, Fei Shen, and Hao Tang
-
[55]
arXiv:2412.12668 [q-bio.GN] https: //arxiv.org/abs/2412.12668
Artificial Intelligence for Central Dogma-Centric Multi-Omics: Challenges and Breakthroughs. arXiv:2412.12668 [q-bio.GN] https: //arxiv.org/abs/2412.12668
- [56]
- [57]
-
[58]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. InProceedings of the 11th International Conference on Learning Representations (ICLR)
2023
-
[59]
Michihiro Yasunaga, Armen Aghajanyan, Weijia Shi, Richard James, Jure Leskovec, Percy Liang, Mike Lewis, Luke Zettlemoyer, and Wen- tau Yih. 2023. Retrieval-Augmented Multimodal Language Modeling. InProceedings of the 40th International Conference on Machine Learning (ICML). 39755–39769
2023
-
[60]
Chao Yu, Akash Velu, Eugene Vinitsky, Jiaxuan Gao, Yu Wang, Alexan- dre Bayen, and Yi Wu. 2022. The Surprising Effectiveness of PPO in Cooperative Multi-Agent Games. InAdvances in Neural Information Processing Systems (NeurIPS), Vol. 35. 24611–24624
2022
- [61]
-
[62]
Amir Zadeh, Minghai Chen, Soujanya Poria, Erik Cambria, and Louis- Philippe Morency. 2017. Tensor fusion network for multimodal sen- timent analysis. InProceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. 1103–1114
2017
-
[63]
AmirAli Bagher Zadeh, Paul Pu Liang, Jonathan Vanbriesen, Soujanya Poria, Edmund Tong, Erik Cambria, Minghai Chen, and Louis-Philippe Morency. 2018. Multimodal language analysis in the wild: CMU-MOSEI dataset and interpretable dynamic fusion graph. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics. 2236–2246
2018
-
[64]
Hang Zhang, Xin Li, and Lidong Bing. 2023. Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understand- ing. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP): System Demonstrations. 443–453
2023
-
[65]
Sitao Zhang, Yimu Pan, and James Z. Wang. 2023. Learning emotion rep- resentations from verbal and nonverbal communication. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 18993–19004
2023
- [66]
-
[67]
Zengqun Zhao, Qingshan Liu, and Feng Zhou. 2022. Robust facial expression recognition: A survey.IEEE Transactions on Affective Com- puting13, 4 (2022), 1805–1823
2022
- [68]
-
[69]
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elho- seiny. 2024. MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models. InInternational Conference on Learning Representations
2024
- [70]
-
[71]
Yijie Zhu, Yibo Lyu, Zitong Yu, Rui Shao, Kaiyang Zhou, and Liqiang Nie. 2025. EmoSym: A Symbiotic Framework for Unified Emotional Understanding and Generation via Latent Reasoning. InProceedings of the 33nd ACM International Conference on Multimedia
2025
-
[72]
Yijie Zhu, Rui Shao, Ziyang Liu, Jie He, Jizhihui Liu, Jiuru Wang, and Zitong Yu. 2026. H-GAR: A Hierarchical Interaction Framework via Goal-Driven Observation-Action Refinement for Robotic Manipulation. InProceedings of the AAAI Conference on Artificial Intelligence
2026
- [73]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.