Recognition: unknown
Unleashing Implicit Rewards: Prefix-Value Learning for Distribution-Level Optimization
Pith reviewed 2026-05-10 15:41 UTC · model grok-4.3
The pith
Training a prefix value function on outcome labels alone produces reliable step rewards for reasoning chains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
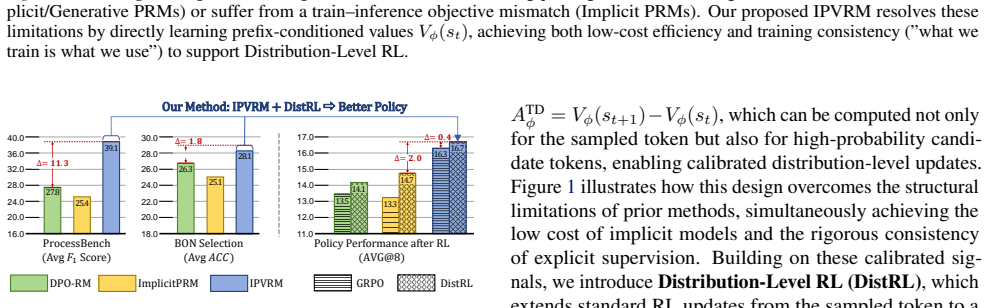
The central claim is that a prefix-conditioned value function trained solely on final outcome labels can estimate the probability of eventual correctness for any reasoning prefix, so that the difference between consecutive prefix values supplies a faithful local signal of step quality. This resolves the train-inference mismatch of earlier implicit reward models, raises step-verification performance, and enables distribution-level RL that performs dense counterfactual updates over multiple candidate tokens.
What carries the argument
The Implicit Prefix-Value Reward Model (IPVRM), a value function that maps each reasoning prefix to the estimated probability it leads to a correct final answer, with step rewards derived as temporal-difference residuals between adjacent prefixes.
If this is right
- Step-verification F1 scores rise substantially on ProcessBench.
- Distribution-Level RL produces consistent gains on downstream reasoning benchmarks when paired with the calibrated prefix values.
- Dense counterfactual updates become feasible across sampled and high-probability tokens without requiring separate rollouts.
- Reward-model training for reasoning tasks no longer requires expensive step-level human annotations.
Where Pith is reading between the lines
- The same prefix-value construction could be tested on sequential decision problems outside language-model reasoning where only terminal outcomes are labeled.
- Online RL loops might continuously refresh prefix values during training to adapt step signals as the policy improves.
- The approach could be combined with lightweight verification oracles to further reduce error reinforcement in safety-critical domains.
Load-bearing premise
That a value function trained only on whether the full sequence succeeded can produce differences between prefix values that accurately reflect the quality of each individual step without systematic bias.
What would settle it
A side-by-side evaluation on human-annotated steps showing that IPVRM step scores align more closely with actual correctness than earlier implicit methods, or an intervention where changing one step predictably alters the prefix value in the expected direction.
Figures




read the original abstract
Process reward models (PRMs) provide fine-grained reward signals along the reasoning process, but training reliable PRMs often requires step annotations or heavy verification pipelines, making them expensive to scale and refresh during online RL. Implicit PRMs mitigate this cost by learning decomposable token- or step-level rewards from trajectory-level outcome labels. However, they suffer from a train-inference mismatch: training only constrains a sequence-level aggregate, whereas inference requires token-level scores to reflect local step quality. As a result, token-level credits are weakly identified and may fail to faithfully reflect which reasoning steps are actually correct. This unreliability undermines a key promise of implicit PRMs: scoring many candidate tokens. In practice, noisy per-token advantages may systematically reinforce incorrect continuations. We address this problem with a novel Implicit Prefix-Value Reward Model (IPVRM), which directly learns a prefix-conditioned value function estimating the probability of eventual correctness, and derives step signals via temporal-difference (TD) differences. IPVRM substantially improves step-verification F1 on ProcessBench. Building on these calibrated prefix values, we further propose Distribution-Level RL (DistRL), which computes TD advantages for both sampled tokens and high-probability candidate tokens, enabling dense counterfactual updates without additional rollouts. While DistRL offers limited gains when powered by miscalibrated implicit rewards, it consistently improves downstream reasoning once paired with IPVRM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Implicit Prefix-Value Reward Model (IPVRM) to overcome limitations in implicit Process Reward Models (PRMs) for LLM reasoning. Implicit PRMs suffer from train-inference mismatch where sequence-level training leads to weakly identified token-level rewards. IPVRM learns a prefix-conditioned value function V(prefix) from outcome labels to estimate P(eventual correctness), deriving step-quality signals from TD differences. It claims substantial F1 improvements on ProcessBench for step verification. Additionally, it introduces Distribution-Level RL (DistRL) that computes TD advantages over sampled and high-probability tokens for dense updates without extra rollouts, showing consistent downstream improvements when combined with IPVRM.
Significance. If the central claims hold, this could be a meaningful contribution to scalable RL for reasoning models by providing a way to obtain reliable fine-grained rewards from cheap outcome supervision. The prefix-value approach and DistRL could reduce the cost of training PRMs and enable better optimization over token distributions. However, the significance is tempered by the need to confirm that the value estimates are unbiased and calibrated as claimed.
major comments (2)
- Abstract: The claim that IPVRM 'directly learns' calibrated prefix values estimating the probability of eventual correctness is central but under-specified. The abstract does not detail the loss, negative sampling, or regularization used to ensure V(prefix) ≈ P(correct | prefix) without the bias from labeling all prefixes in failed trajectories negatively, which the paper itself identifies as a problem in prior implicit PRMs. This mechanism is load-bearing for both the verification F1 gains and the DistRL advantages.
- The TD advantage construction (abstract): Without explicit equations or ablation on how prefix values are trained solely from terminal outcomes, it remains unclear whether the derived step signals are free of systematic bias or simply reflect fitted aggregates of outcome labels. This directly affects the claim that IPVRM yields faithful local step-quality signals.
minor comments (1)
- Abstract: Quantitative results (e.g., exact F1 gains on ProcessBench, downstream accuracy deltas) and baseline comparisons are referenced but not reported; these should be added with error bars or statistical tests to support 'substantially improves' and 'consistently improves'.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback on our work. The comments correctly identify that the abstract is concise and could better support the central claims regarding calibration and TD construction. We address each point below and will revise the manuscript accordingly to improve clarity without altering the technical contributions.
read point-by-point responses
-
Referee: Abstract: The claim that IPVRM 'directly learns' calibrated prefix values estimating the probability of eventual correctness is central but under-specified. The abstract does not detail the loss, negative sampling, or regularization used to ensure V(prefix) ≈ P(correct | prefix) without the bias from labeling all prefixes in failed trajectories negatively, which the paper itself identifies as a problem in prior implicit PRMs. This mechanism is load-bearing for both the verification F1 gains and the DistRL advantages.
Authors: We agree the abstract is too brief on this load-bearing detail. The full manuscript (Section 3.2) specifies a binary cross-entropy loss applied to prefix values against terminal outcome labels, combined with negative sampling restricted to prefixes from failed trajectories and a monotonicity regularization term that penalizes value decreases along incorrect paths. This avoids the uniform negative labeling bias identified in prior implicit PRMs. We will revise the abstract to concisely reference the loss and sampling approach, thereby strengthening the calibration claim. revision: yes
-
Referee: The TD advantage construction (abstract): Without explicit equations or ablation on how prefix values are trained solely from terminal outcomes, it remains unclear whether the derived step signals are free of systematic bias or simply reflect fitted aggregates of outcome labels. This directly affects the claim that IPVRM yields faithful local step-quality signals.
Authors: The manuscript presents the TD advantage explicitly in Equation (3) as the difference V(prefix_t) − V(prefix_{t+1}), with prefix values trained end-to-end from terminal outcomes via TD learning. The ProcessBench F1 gains (Table 2) provide evidence that the resulting step signals capture local quality beyond aggregate fitting, as IPVRM outperforms standard implicit PRMs that suffer from the identified mismatch. We acknowledge that an additional ablation isolating bias would further strengthen the presentation and will add this analysis in the revision. revision: partial
Circularity Check
No significant circularity; derivation is self-contained modeling choice with external empirical grounding.
full rationale
The paper defines IPVRM as learning a prefix-conditioned value function from outcome labels and deriving TD step signals from it. This is a standard supervised modeling approach, not a self-referential reduction where the output is forced by construction from the inputs. No equations are provided that equate the claimed estimates directly to fitted aggregates without independent content. No self-citations, uniqueness theorems, or ansatz smuggling appear in the abstract or description. The method is validated against ProcessBench F1 scores, satisfying the self-contained benchmark criterion. The under-identification concern raised is a question of correctness and bias, not circularity per the rules.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Stabi- lizing policy optimization via logits convexity.arXiv preprint arXiv:2603.00963,
Chen, H., Yang, T., Zhu, Y ., Gao, S., Quan, X., and Yao, T. Stabi- lizing policy optimization via logits convexity.arXiv preprint arXiv:2603.00963,
-
[2]
Process Reinforcement through Implicit Rewards
Cui, G., Yuan, L., Wang, Z., Wang, H., Zhang, Y ., Chen, J., Li, W., He, B., Fan, Y ., Yu, T., et al. Process reinforcement through implicit rewards.arXiv preprint arXiv:2502.01456,
work page internal anchor Pith review arXiv
-
[3]
Fei, W., Kong, H., Liang, S., Lin, Y ., Yang, Y ., Tang, J., Chen, L., and Hua, X. Self-guided process reward optimization with re- defined step-wise advantage for process reinforcement learning. arXiv preprint arXiv:2507.01551,
-
[4]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Measuring Mathematical Problem Solving With the MATH Dataset
Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., and Steinhardt, J. Measuring mathemat- ical problem solving with the math dataset.arXiv preprint arXiv:2103.03874,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Process reward models that think.arXiv preprint arXiv:2504.16828, 2025
Khalifa, M., Agarwal, R., Logeswaran, L., Kim, J., Peng, H., Lee, M., Lee, H., and Wang, L. Process reward models that think. arXiv preprint arXiv:2504.16828,
-
[7]
arXiv preprint arXiv:2506.23235 , year=
Li, Y .-C., Xu, T., Yu, Y ., Zhang, X., Chen, X.-H., Ling, Z., Chao, N., Yuan, L., and Zhou, Z.-H. Generalist reward models: Found inside large language models.arXiv preprint arXiv:2506.23235,
-
[8]
On the lim- ited generalization capability of the implicit reward model in- duced by direct preference optimization
Lin, Y ., Seto, S., Ter Hoeve, M., Metcalf, K., Theobald, B.-J., Wang, X., Zhang, Y ., Huang, C., and Zhang, T. On the lim- ited generalization capability of the implicit reward model in- duced by direct preference optimization. InFindings of the Association for Computational Linguistics: EMNLP 2024, pp. 16015–16026,
2024
-
[9]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
Schulman, J., Moritz, P., Levine, S., Jordan, M., and Abbeel, P. High-dimensional continuous control using generalized advan- tage estimation.arXiv preprint arXiv:1506.02438,
work page internal anchor Pith review arXiv
-
[10]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y ., Wu, Y ., et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025a. Yang, Z., Wan, F., Zhong, L., Shi, T., and Quan, X. Weighted- reward preference optimization for implicit model fusion. In The Thirteenth International Conference on Learning Represen- tations...
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
What’s behind ppo’s collapse in long-cot? value optimization holds the secret, 2025
URL https://openreview. net/forum?id=2a36EMSSTp. Yuan, L., Li, W., Chen, H., Cui, G., Ding, N., Zhang, K., Zhou, B., Liu, Z., and Peng, H. Free process rewards without process labels. InInternational Conference on Machine Learning, pp. 73511–73525. PMLR, 2025a. Yuan, Y ., Yue, Y ., Zhu, R., Fan, T., and Yan, L. What’s behind ppo’s collapse in long-cot? va...
-
[13]
R., Zhao, S., Song, K., Xu, S., and Zhu, C
Zhou, W., Agrawal, R., Zhang, S., Indurthi, S. R., Zhao, S., Song, K., Xu, S., and Zhu, C. Wpo: Enhancing rlhf with weighted preference optimization. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 8328–8340,
2024
-
[14]
10 Unleashing Implicit Rewards: Prefix-Value Learning for Distribution-Level Optimization A. Related Work RL with Verifiable Rewards for Reasoning.Recent progress in mathematical and code reasoning has been largely driven by Reinforcement Learning with Verifiable Rewards (RLVR) (Lambert et al., 2025), where correctness is automatically verified and used a...
2025
-
[15]
In parallel,generativePRMs (Khalifa et al., 2025; Zhao et al.,
further reduces labeling by actively selecting uncertain steps and querying either human experts or model-based annotators. In parallel,generativePRMs (Khalifa et al., 2025; Zhao et al.,
2025
-
[16]
think-then-judge
adopt a “think-then-judge” paradigm that generates critiques/verifications before producing step scores, improving semantic grounding but incurring additional overhead in inference, training, and data collection. Despite reducing manual annotation, both paradigms remain expensive to refresh: they often require heavy rollout-based label construction or lon...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.