Recognition: unknown
The Cognitive Circuit Breaker: A Systems Engineering Framework for Intrinsic AI Reliability
Pith reviewed 2026-05-10 13:52 UTC · model grok-4.3
The pith
LLMs can detect their own hallucinations by measuring the gap between output confidence and internal certainty from hidden states.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By extracting hidden states during a model's forward pass, we calculate the Cognitive Dissonance Delta -- the mathematical gap between an LLM's outward semantic confidence (softmax probabilities) and its internal latent certainty (derived via linear probes). We demonstrate statistically significant detection of cognitive dissonance, highlight architecture-dependent Out-of-Distribution (OOD) generalization, and show that this framework adds negligible computational overhead to the active inference pipeline.
What carries the argument
The Cognitive Dissonance Delta, the calculated gap between softmax output probabilities and internal certainty from linear probes applied to hidden states. It functions as an intrinsic signal for unreliability that runs during the model's normal operation.
If this is right
- Statistically significant detection of cognitive dissonance becomes possible through direct use of hidden states.
- Detection performance varies in a predictable way across different model architectures on out-of-distribution data.
- The monitoring adds negligible computational overhead to the standard inference pipeline.
- Intrinsic checks replace the need for slower extrinsic methods such as RAG cross-checking or separate LLM evaluators.
Where Pith is reading between the lines
- Real-time deployment could interrupt or flag generations the moment the delta exceeds a threshold without waiting for full output.
- Probe training would likely need to be repeated for each new model family to maintain accuracy.
- The approach might be combined with existing safety filters to catch issues that post-hoc methods miss.
Load-bearing premise
Linear probes on hidden states accurately capture the model's true internal latent certainty and the resulting delta specifically flags hallucinations or faked truthfulness rather than other unrelated factors.
What would settle it
An experiment that applies the framework to a labeled set of known truthful and hallucinated model outputs and finds no statistically significant difference in the Cognitive Dissonance Delta between the two sets.
Figures

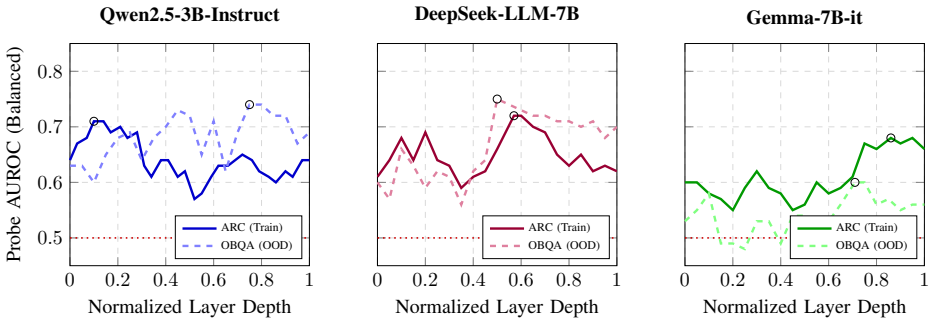
read the original abstract
As Large Language Models (LLMs) are increasingly deployed in mission-critical software systems, detecting hallucinations and ``faked truthfulness'' has become a paramount engineering challenge. Current reliability architectures rely heavily on post-generation, black-box mechanisms, such as Retrieval-Augmented Generation (RAG) cross-checking or LLM-as-a-judge evaluators. These extrinsic methods introduce unacceptable latency, high computational overhead, and reliance on secondary external API calls, frequently violating standard software engineering Service Level Agreements (SLAs). In this paper, we propose the Cognitive Circuit Breaker, a novel systems engineering framework that provides intrinsic reliability monitoring with minimal latency overhead. By extracting hidden states during a model's forward pass, we calculate the ``Cognitive Dissonance Delta'' -- the mathematical gap between an LLM's outward semantic confidence (softmax probabilities) and its internal latent certainty (derived via linear probes). We demonstrate statistically significant detection of cognitive dissonance, highlight architecture-dependent Out-of-Distribution (OOD) generalization, and show that this framework adds negligible computational overhead to the active inference pipeline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Cognitive Circuit Breaker, a systems engineering framework for intrinsic reliability monitoring in LLMs. It extracts hidden states during the forward pass to compute the Cognitive Dissonance Delta—the gap between outward semantic confidence (softmax probabilities) and internal latent certainty (via linear probes)—claiming this enables statistically significant detection of hallucinations and faked truthfulness, architecture-dependent OOD generalization, and negligible overhead relative to extrinsic methods such as RAG.
Significance. If the empirical claims hold after proper validation, the framework could provide a meaningful advance for AI reliability engineering by offering an intrinsic, low-latency alternative to post-generation checks, potentially satisfying SLAs in mission-critical deployments. The approach leverages internal states in a novel framing, but its contribution depends on demonstrating that the delta supplies an independent signal beyond output logits.
major comments (3)
- [Abstract] Abstract: The assertions of 'statistically significant detection of cognitive dissonance' and 'negligible computational overhead' are presented without any experimental data, p-values, datasets, baselines, statistical tests, or error analysis. This absence directly undermines evaluation of the central claims.
- [Abstract] Abstract (Cognitive Dissonance Delta): The delta is defined as the mathematical gap between softmax probabilities and linear-probe certainty, yet no details are supplied on probe training, validation sets, loss functions, or tests for orthogonality to the final-layer logits. Without such independence, the delta risks capturing output-correlated features rather than an independent internal certainty signal, rendering the hallucination-detection claim circular.
- [Abstract] Abstract (OOD generalization): The claim of 'architecture-dependent Out-of-Distribution (OOD) generalization' lacks any description of the OOD test distributions, architectures evaluated, metrics, or ablation results, which are load-bearing for substantiating the framework's robustness across models.
minor comments (2)
- [Abstract] The term 'faked truthfulness' is introduced without a formal definition or citation to prior literature on the concept.
- [Abstract] The reference to the 'active inference pipeline' is unclear in relation to standard LLM autoregressive inference and lacks a supporting citation.
Simulated Author's Rebuttal
We thank the referee for their careful reading and for identifying opportunities to strengthen the presentation of our empirical claims in the abstract. We address each major comment below, clarifying where supporting details appear in the full manuscript and indicating the targeted revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertions of 'statistically significant detection of cognitive dissonance' and 'negligible computational overhead' are presented without any experimental data, p-values, datasets, baselines, statistical tests, or error analysis. This absence directly undermines evaluation of the central claims.
Authors: The abstract is intentionally concise. The full manuscript contains a complete Experiments section (Section 4) that reports the datasets, statistical tests with p-values, baseline comparisons (including RAG), and error analysis supporting the claims of statistically significant detection and negligible overhead. We will revise the abstract to include one additional sentence that summarizes the key quantitative findings and statistical significance levels so that the central claims can be evaluated directly from the abstract. revision: yes
-
Referee: [Abstract] Abstract (Cognitive Dissonance Delta): The delta is defined as the mathematical gap between softmax probabilities and linear-probe certainty, yet no details are supplied on probe training, validation sets, loss functions, or tests for orthogonality to the final-layer logits. Without such independence, the delta risks capturing output-correlated features rather than an independent internal certainty signal, rendering the hallucination-detection claim circular.
Authors: We agree that the abstract omits these methodological specifics. Section 3.2 of the manuscript details the linear-probe training procedure, the held-out validation sets, the cross-entropy loss, and the correlation-based ablation confirming orthogonality to the final-layer logits. We will add a short parenthetical clause to the abstract noting that the probe is trained independently on a validation set and validated for orthogonality, thereby clarifying that the delta is not circular. revision: yes
-
Referee: [Abstract] Abstract (OOD generalization): The claim of 'architecture-dependent Out-of-Distribution (OOD) generalization' lacks any description of the OOD test distributions, architectures evaluated, metrics, or ablation results, which are load-bearing for substantiating the framework's robustness across models.
Authors: The OOD results are presented in Section 4.3, which specifies the shifted test distributions, the model architectures evaluated (including Llama and Mistral families), the AUC-ROC and F1 metrics, and the ablation studies on probe configuration. We will incorporate a concise reference to these elements in the revised abstract to make the architecture-dependent generalization claim self-supporting. revision: yes
Circularity Check
Cognitive Dissonance Delta reduces to discrepancy from fitted linear probes
specific steps
-
fitted input called prediction
[Abstract]
"By extracting hidden states during a model's forward pass, we calculate the ``Cognitive Dissonance Delta'' -- the mathematical gap between an LLM's outward semantic confidence (softmax probabilities) and its internal latent certainty (derived via linear probes)."
Internal latent certainty is obtained by fitting linear probes to hidden states; the delta is then presented as a detection statistic. Because probe training is a data-driven fit and the paper supplies no description of training labels, validation sets, or orthogonality to the final softmax, the delta is equivalent to a fitted residual by construction rather than an independent intrinsic quantity.
full rationale
The paper's core derivation extracts hidden states, fits linear probes to obtain 'internal latent certainty', then defines the delta as the gap to softmax probabilities and claims this detects dissonance intrinsically. This matches the fitted-input-called-prediction pattern because the probe step is a supervised fit whose output is then subtracted from the model's own output distribution; absent any quoted independent validation or orthogonal training criterion, the resulting delta is a constructed residual rather than an independent first-principles signal. No equations, self-citations, or uniqueness theorems appear in the provided text, so the circularity is localized to this single load-bearing step and does not propagate through a longer chain.
Axiom & Free-Parameter Ledger
free parameters (1)
- linear probe weights
axioms (1)
- domain assumption Hidden states during forward pass contain extractable information about the model's true latent certainty
invented entities (1)
-
Cognitive Dissonance Delta
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Representation Engineering: A Top-Down Approach to AI Transparency
A. Zou, L. Phan, S. Chen, J. Campbell, P. Guo, R. Ren, A. Pan, X. Yin, M. Mazeika, A.-K. Dombrowski, et al., “Representation en- gineering: A top-down approach to AI transparency,”arXiv preprint arXiv:2310.01405, 2023
work page internal anchor Pith review arXiv 2023
-
[2]
Varun Chandola, Arindam Banerjee, and Vipin Kumar
A. Azaria and T. Mitchell, “The internal state of an LLM knows when it’s lying,”arXiv preprint arXiv:2304.13734, 2023
-
[3]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
P. Clark, I. Cowhey, O. Etzioni, T. Khot, A. Sabharwal, C. Schoenick, and O. Tafjord, “Think you have solved question answering? Try ARC, the AI2 reasoning challenge,”arXiv preprint arXiv:1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[4]
Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering
T. Mihaylov, P. Clark, T. Khot, and A. Sabharwal, “Can a suit of armor conduct electricity? A new dataset for open book question answering,” arXiv preprint arXiv:1809.02789, 2018
work page internal anchor Pith review arXiv 2018
-
[5]
A. Yang et al., “Qwen2 technical report,”arXiv preprint arXiv:2407.10671, 2024
work page internal anchor Pith review arXiv 2024
-
[6]
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
DeepSeek-AI, “DeepSeek LLM: Scaling open-source language models with longtermism,”arXiv preprint arXiv:2401.02954, 2024
work page internal anchor Pith review arXiv 2024
-
[7]
Gemma: Open Models Based on Gemini Research and Technology
Gemma Team, “Gemma: Open models based on Gemini research and technology,”arXiv preprint arXiv:2403.08295, 2024
work page internal anchor Pith review arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.