Recognition: unknown
Bridging MARL to SARL: An Order-Independent Multi-Agent Transformer via Latent Consensus
Pith reviewed 2026-05-10 13:37 UTC · model grok-4.3
The pith
CMAT reformulates cooperative MARL as hierarchical SARL by generating a latent consensus vector that conditions simultaneous order-independent actions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CMAT treats the collection of agents as a single unified entity whose joint observation space is processed by a Transformer encoder. A Transformer decoder then autoregressively produces a high-level consensus vector that encodes the agents' agreement in latent space. Conditioned on this vector, all agents emit their actions simultaneously, yielding an order-independent joint policy that is optimized directly with single-agent PPO while retaining coordination through the latent representation.
What carries the argument
The high-level consensus vector autoregressively generated by the Transformer decoder, which encodes strategic agreement among agents and conditions their simultaneous action outputs.
If this is right
- Joint action selection becomes independent of the sequence in which actions are produced.
- The entire system trains with standard single-agent PPO rather than specialized multi-agent algorithms.
- Coordination is preserved through the latent consensus without requiring explicit inter-agent messages.
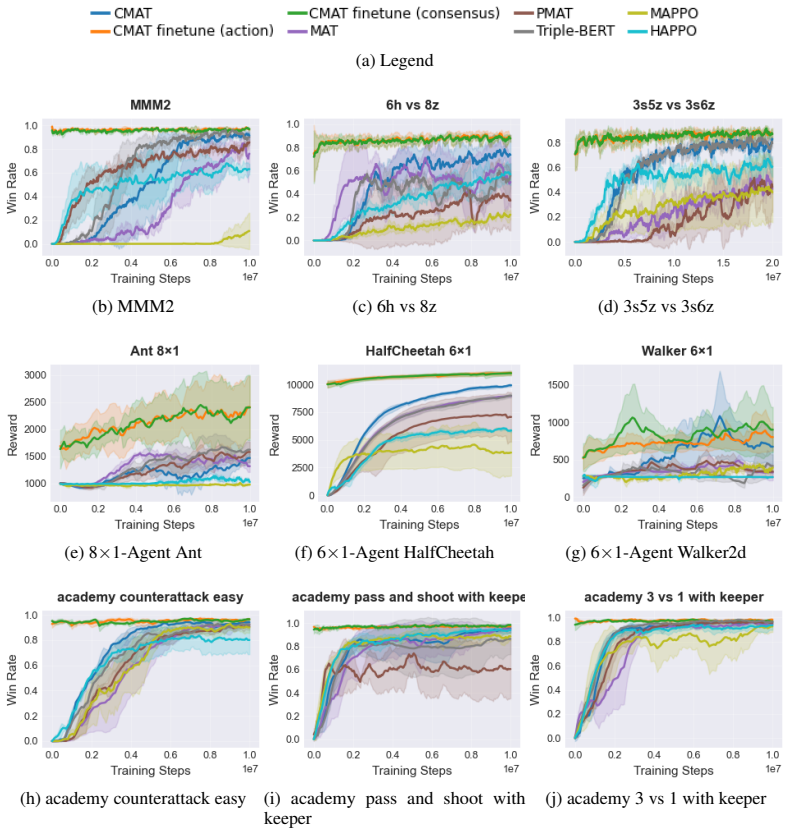
- Empirical gains appear across StarCraft II, Multi-Agent MuJoCo, and Google Research Football.
Where Pith is reading between the lines
- The same latent-consensus structure could be tested in decentralized execution by broadcasting only the consensus vector at inference time.
- If the vector proves sufficient, many existing MARL coordination modules might be replaceable by this single learned representation.
- Scaling experiments on tasks with dozens of agents would reveal whether the autoregressive decoder remains stable as agent count grows.
Load-bearing premise
The latent consensus vector is assumed to encode enough coordination information to substitute for explicit agent-to-agent communication or a centralized critic.
What would settle it
Replacing the consensus vector with random noise during training and observing that performance on the StarCraft II or Multi-Agent MuJoCo benchmarks collapses to the level of uncoordinated baselines would falsify the claim.
Figures



read the original abstract
Cooperative multi-agent reinforcement learning (MARL) is widely used to address large joint observation and action spaces by decomposing a centralized control problem into multiple interacting agents. However, such decomposition often introduces additional challenges, including non-stationarity, unstable training, weak coordination, and limited theoretical guarantees. In this paper, we propose the Consensus Multi-Agent Transformer (CMAT), a centralized framework that bridges cooperative MARL to a hierarchical single-agent reinforcement learning (SARL) formulation. CMAT treats all agents as a unified entity and employs a Transformer encoder to process the large joint observation space. To handle the extensive joint action space, we introduce a hierarchical decision-making mechanism in which a Transformer decoder autoregressively generates a high-level consensus vector, simulating the process by which agents reach agreement on their strategies in latent space. Conditioned on this consensus, all agents generate their actions simultaneously, enabling order-independent joint decision making and avoiding the sensitivity to action-generation order in conventional Multi-Agent Transformers (MAT). This factorization allows the joint policy to be optimized using single-agent PPO while preserving expressive coordination through the latent consensus. To evaluate the proposed method, we conduct experiments on benchmark tasks from StarCraft II, Multi-Agent MuJoCo, and Google Research Football. The results show that CMAT achieves superior performance over recent centralized solutions, sequential MARL methods, and conventional MARL baselines. The code for this paper is available at:https://github.com/RS2002/CMAT .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Consensus Multi-Agent Transformer (CMAT), a centralized architecture that bridges cooperative MARL to hierarchical SARL. A Transformer encoder processes the joint observation space while a decoder autoregressively generates a high-level latent consensus vector; conditioning on this vector permits simultaneous, order-independent action generation for all agents. The resulting joint policy is optimized end-to-end with single-agent PPO. Experiments on StarCraft II, Multi-Agent MuJoCo, and Google Research Football report superior performance relative to recent centralized, sequential, and standard MARL baselines.
Significance. If the performance gains are robustly attributable to the latent consensus mechanism rather than ancillary design choices, the work would provide a practical route to simplify cooperative MARL training by reducing it to a hierarchical SARL problem, mitigating non-stationarity and action-order sensitivity. The open-sourced code is a clear strength for reproducibility.
major comments (3)
- [§3.2] §3.2 (Hierarchical Decision-Making): The central claim that the autoregressively generated consensus vector is expressive enough to capture all inter-agent coordination dependencies (thereby justifying the SARL reduction) is stated without a supporting completeness argument, information-theoretic bound, or proof that the latent space can represent the full joint policy class.
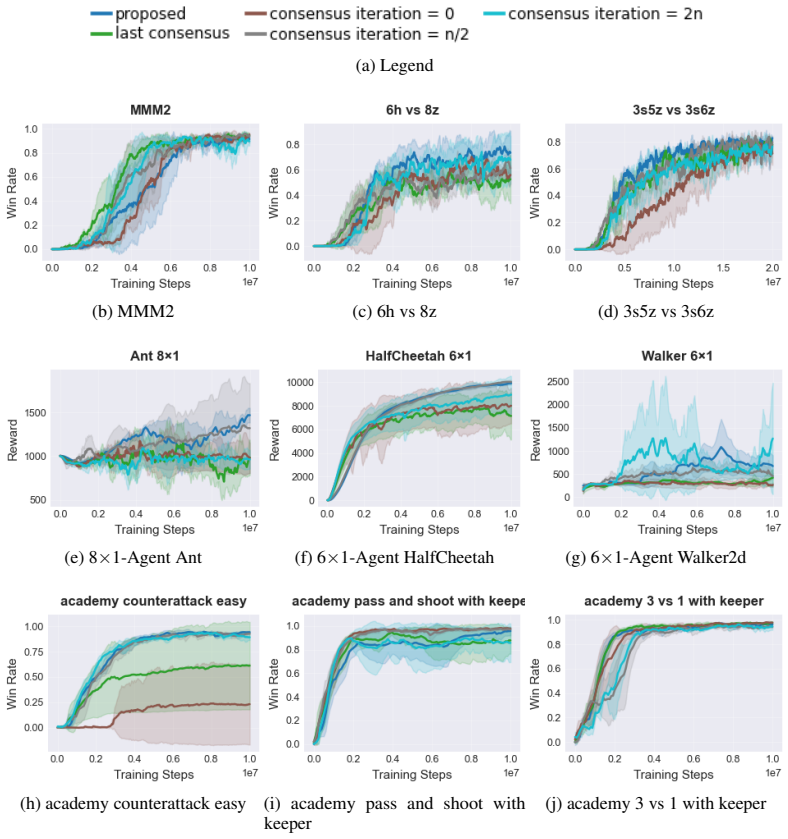
- [§4] §4 (Experiments): No ablation isolates the consensus component (e.g., a variant with the decoder removed, the consensus vector zeroed, or replaced by a fixed non-learned embedding). Without such controls, the reported benchmark superiority cannot be confidently attributed to the proposed mechanism rather than the joint encoder or PPO implementation.
- [§4] §4 (Experiments): Training curves, multiple random seeds with error bars, and statistical significance tests are absent, so it is impossible to verify that the gains are stable and not the result of hyperparameter tuning or implementation details.
minor comments (2)
- [§3] The notation for the consensus vector and its conditioning on the decoder output should be introduced with explicit equations rather than prose descriptions alone.
- [Abstract] The GitHub link appears only in the abstract; a permanent reference or DOI should be added to the main text and reproducibility statement.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below, providing our responses and indicating planned revisions to the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Hierarchical Decision-Making): The central claim that the autoregressively generated consensus vector is expressive enough to capture all inter-agent coordination dependencies (thereby justifying the SARL reduction) is stated without a supporting completeness argument, information-theoretic bound, or proof that the latent space can represent the full joint policy class.
Authors: We acknowledge that the manuscript presents the expressiveness of the latent consensus vector through design intuition and empirical results rather than a formal completeness argument, information-theoretic bound, or proof of universality for the joint policy class. The autoregressive decoder is intended to model coordination dependencies in latent space, enabling the hierarchical SARL reduction while preserving order independence. In the revised version, we will expand Section 3.2 with additional discussion of the design rationale, limitations on expressiveness, and connections to related latent-variable approaches in RL. A rigorous theoretical proof lies beyond the scope of this empirical work. revision: partial
-
Referee: [§4] §4 (Experiments): No ablation isolates the consensus component (e.g., a variant with the decoder removed, the consensus vector zeroed, or replaced by a fixed non-learned embedding). Without such controls, the reported benchmark superiority cannot be confidently attributed to the proposed mechanism rather than the joint encoder or PPO implementation.
Authors: We agree that targeted ablations are necessary to attribute gains specifically to the consensus mechanism. In the revised manuscript, we will add experiments comparing the full CMAT against variants with the consensus vector zeroed, replaced by a fixed non-learned embedding, and a decoder-ablated version. These controls will be evaluated on the StarCraft II, Multi-Agent MuJoCo, and Google Research Football benchmarks to isolate the contribution of the latent consensus. revision: yes
-
Referee: [§4] §4 (Experiments): Training curves, multiple random seeds with error bars, and statistical significance tests are absent, so it is impossible to verify that the gains are stable and not the result of hyperparameter tuning or implementation details.
Authors: We appreciate this feedback on reporting standards. While the original experiments used multiple random seeds, only aggregate means were presented. The revised version will include training curves, performance averaged over at least five seeds with standard error bars, and statistical significance tests (e.g., paired t-tests against baselines) to demonstrate stability and rule out implementation artifacts. revision: yes
Circularity Check
No circularity: empirical architecture proposal with independent benchmark validation
full rationale
The paper introduces CMAT as a new transformer-based architecture that encodes joint observations, autoregressively decodes a latent consensus vector, and conditions simultaneous action generation to enable single-agent PPO optimization. This is presented as a design choice justified by empirical results on StarCraft II, Multi-Agent MuJoCo, and Google Research Football, without any equations, fitted parameters, or self-citations that reduce the central claim to its own inputs by construction. The coordination mechanism is an explicit architectural ansatz, not a derived result that loops back to itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A transformer decoder can generate a latent consensus vector that is sufficient to condition coordinated actions without explicit inter-agent messages.
Reference graph
Works this paper leans on
-
[1]
Multi-agent reinforcement learning for resources allocation optimization: a survey,
M. A. Hady, S. Hu, M. Pratama, Z. Cao, and R. Kowalczyk, “Multi-agent reinforcement learning for resources allocation optimization: a survey,”Artificial Intelligence Review, vol. 58, no. 11, p. 354, 2025
2025
-
[2]
W. Jin, H. Du, B. Zhao, X. Tian, B. Shi, and G. Yang, “A comprehensive survey on multi- agent cooperative decision-making: Scenarios, approaches, challenges and perspectives,”arXiv preprint arXiv:2503.13415, 2025
-
[3]
Monotonic value function factorisation for deep multi-agent reinforcement learning,
T. Rashid, M. Samvelyan, C. S. De Witt, G. Farquhar, J. Foerster, and S. Whiteson, “Monotonic value function factorisation for deep multi-agent reinforcement learning,”Journal of Machine Learning Research, vol. 21, no. 178, pp. 1–51, 2020
2020
-
[4]
Mean field multi-agent reinforcement learning,
Y . Yang, R. Luo, M. Li, M. Zhou, W. Zhang, and J. Wang, “Mean field multi-agent reinforcement learning,” inInternational conference on machine learning, pp. 5571–5580, PMLR, 2018
2018
-
[5]
Counterfactual multi-agent policy gradients,
J. Foerster, G. Farquhar, T. Afouras, N. Nardelli, and S. Whiteson, “Counterfactual multi-agent policy gradients,” inProceedings of the AAAI conference on artificial intelligence, vol. 32, 2018
2018
-
[6]
A review of cooperative multi-agent deep reinforcement learning,
A. Oroojlooy and D. Hajinezhad, “A review of cooperative multi-agent deep reinforcement learning,”Applied Intelligence, vol. 53, no. 11, pp. 13677–13722, 2023
2023
-
[7]
Exponential topology-enabled scalable communication in multi-agent reinforcement learning,
X. Li, X. Wang, C. Bai, and J. Zhang, “Exponential topology-enabled scalable communication in multi-agent reinforcement learning,” inThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[8]
Multi-agent reinforcement learning is a sequence modeling problem,
M. Wen, J. Kuba, R. Lin, W. Zhang, Y . Wen, J. Wang, and Y . Yang, “Multi-agent reinforcement learning is a sequence modeling problem,”Advances in Neural Information Processing Systems, vol. 35, pp. 16509–16521, 2022
2022
-
[9]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[10]
Pmat: Optimizing action generation order in multi-agent reinforcement learning,
K. Hu, M. Wen, X. Wang, S. Zhang, Y . Shi, M. Li, M. Li, and Y . Wen, “Pmat: Optimizing action generation order in multi-agent reinforcement learning,” inProceedings of the 24th International Conference on Autonomous Agents and Multiagent Systems, pp. 997–1005, 2025
2025
-
[11]
Aoad-mat: Transformer-based multi-agent deep reinforcement learning model considering agents’ order of action decisions,
S. Takayama and K. Fujita, “Aoad-mat: Transformer-based multi-agent deep reinforcement learning model considering agents’ order of action decisions,” inInternational Conference on Principles and Practice of Multi-Agent Systems, pp. 303–310, Springer, 2025. 10
2025
-
[12]
Triple-bert: Do we really need marl for order dispatch on ride-sharing platforms?,
Z. Zhao and S. Li, “Triple-bert: Do we really need marl for order dispatch on ride-sharing platforms?,” inThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[13]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[14]
The starcraft multi-agent challenge,
S. Whiteson, M. Samvelyan, T. Rashid, C. De Witt, G. Farquhar, N. Nardelli, T. Rudner, C. Hung, P. Torr, and J. Foerster, “The starcraft multi-agent challenge,” inProceedings of the International Joint Conference on Autonomous Agents and Multiagent Systems, AAMAS, pp. 2186–2188, 2019
2019
-
[15]
Deep multi- agent reinforcement learning for decentralized continuous cooperative control,
C. S. de Witt, B. Peng, P.-A. Kamienny, P. Torr, W. Böhmer, and S. Whiteson, “Deep multi- agent reinforcement learning for decentralized continuous cooperative control,”arXiv preprint arXiv:2003.06709, vol. 19, 2020
-
[16]
Google research football: A novel reinforcement learning environment,
K. Kurach, A. Raichuk, P. Sta´nczyk, M. Zaj ˛ ac, O. Bachem, L. Espeholt, C. Riquelme, D. Vincent, M. Michalski, O. Bousquet,et al., “Google research football: A novel reinforcement learning environment,” inProceedings of the AAAI conference on artificial intelligence, vol. 34, pp. 4501– 4510, 2020
2020
-
[17]
Markov games as a framework for multi-agent reinforcement learning,
M. L. Littman, “Markov games as a framework for multi-agent reinforcement learning,” in Machine learning proceedings 1994, pp. 157–163, Elsevier, 1994
1994
-
[18]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
J. Schulman, P. Moritz, S. Levine, M. Jordan, and P. Abbeel, “High-dimensional continuous control using generalized advantage estimation,”arXiv preprint arXiv:1506.02438, 2015
work page internal anchor Pith review arXiv 2015
-
[19]
Trust region policy optimisa- tion in multi-agent reinforcement learning,
J. Kuba, R. Chen, M. Wen, Y . Wen, F. Sun, J. Wang, and Y . Yang, “Trust region policy optimisa- tion in multi-agent reinforcement learning,” inICLR 2022-10th International Conference on Learning Representations, p. 1046, The International Conference on Learning Representations (ICLR), 2022
2022
-
[20]
Heterogeneous-agent reinforcement learning,
Y . Zhong, J. G. Kuba, X. Feng, S. Hu, J. Ji, and Y . Yang, “Heterogeneous-agent reinforcement learning,”Journal of Machine Learning Research, vol. 25, no. 32, pp. 1–67, 2024
2024
-
[21]
Maximum entropy heterogeneous-agent reinforcement learning,
J. Liu, Y . Zhong, S. Hu, H. Fu, Q. FU, X. Chang, and Y . Yang, “Maximum entropy heterogeneous-agent reinforcement learning,” inThe Twelfth International Conference on Learning Representations, 2024
2024
-
[22]
Bert: Pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” inProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technolo- gies, volume 1 (long and short papers), pp. 4171–4186, 2019
2019
-
[23]
Csi-bert2: A bert-inspired framework for efficient csi prediction and classification in wireless communication and sensing,
Z. Zhao, F. Meng, Z. Lyu, H. Li, X. Li, and G. Zhu, “Csi-bert2: A bert-inspired framework for efficient csi prediction and classification in wireless communication and sensing,”IEEE Transactions on Mobile Computing, 2025
2025
-
[24]
Midibert-piano: Large-scale pre-training for symbolic music classification tasks,
Y .-H. Chou, I.-C. Chen, J. Ching, C.-J. Chang, and Y .-H. Yang, “Midibert-piano: Large-scale pre-training for symbolic music classification tasks,”Journal of Creative Music Systems, vol. 8, no. 1, 2024
2024
-
[25]
R. D. Luceet al.,Individual choice behavior, vol. 4. Wiley New York, 1959
1959
-
[26]
The analysis of permutations,
R. L. Plackett, “The analysis of permutations,”Journal of the Royal Statistical Society Series C: Applied Statistics, vol. 24, no. 2, pp. 193–202, 1975
1975
-
[27]
The surprising effectiveness of ppo in cooperative multi-agent games,
C. Yu, A. Velu, E. Vinitsky, J. Gao, Y . Wang, A. Bayen, and Y . Wu, “The surprising effectiveness of ppo in cooperative multi-agent games,”Advances in neural information processing systems, vol. 35, pp. 24611–24624, 2022
2022
-
[28]
L. Yuan, Z. Zhang, L. Li, C. Guan, and Y . Yu, “A survey of progress on cooperative multi-agent reinforcement learning in open environment,”arXiv preprint arXiv:2312.01058, 2023. 11
-
[29]
Hysteretic q-learning: an algorithm for decentralized reinforcement learning in cooperative multi-agent teams,
L. Matignon, G. J. Laurent, and N. Le Fort-Piat, “Hysteretic q-learning: an algorithm for decentralized reinforcement learning in cooperative multi-agent teams,” in2007 IEEE/RSJ International Conference on Intelligent Robots and Systems, pp. 64–69, IEEE, 2007
2007
-
[30]
Modelling the Dynamic Joint Policy of Teammates with Attention Multi-agent DDPG
H. Mao, Z. Zhang, Z. Xiao, and Z. Gong, “Modelling the dynamic joint policy of teammates with attention multi-agent ddpg,”arXiv preprint arXiv:1811.07029, 2018
work page Pith review arXiv 2018
-
[31]
Shapley counterfactual credits for multi-agent reinforcement learning,
J. Li, K. Kuang, B. Wang, F. Liu, L. Chen, F. Wu, and J. Xiao, “Shapley counterfactual credits for multi-agent reinforcement learning,” inProceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, pp. 934–942, 2021
2021
-
[32]
Value-decomposition networks for cooperative multi- agent learning based on team reward,
P. Sunehag, G. Lever, A. Gruslys, W. M. Czarnecki, V . Zambaldi, M. Jaderberg, M. Lanctot, N. Sonnerat, J. Z. Leibo, K. Tuyls,et al., “Value-decomposition networks for cooperative multi- agent learning based on team reward,” inProceedings of the 17th International Conference on Autonomous Agents and MultiAgent Systems, pp. 2085–2087, 2018
2085
-
[33]
Value-decomposition multi-agent actor-critics,
J. Su, S. Adams, and P. Beling, “Value-decomposition multi-agent actor-critics,” inProceedings of the AAAI conference on artificial intelligence, vol. 35, pp. 11352–11360, 2021
2021
-
[34]
Qtran: Learning to factorize with transformation for cooperative multi-agent reinforcement learning,
K. Son, D. Kim, W. J. Kang, D. E. Hostallero, and Y . Yi, “Qtran: Learning to factorize with transformation for cooperative multi-agent reinforcement learning,” inInternational conference on machine learning, pp. 5887–5896, PMLR, 2019
2019
-
[35]
Hierarchical value decomposition for effective on-demand ride- pooling,
J. Hao and P. Varakantham, “Hierarchical value decomposition for effective on-demand ride- pooling,” inProceedings of the 21st International Conference on Autonomous Agents and Multiagent Systems, pp. 580–587, 2022
2022
-
[36]
Efficient distributed reinforcement learning through agreement,
P. Varshavskaya, L. P. Kaelbling, and D. Rus, “Efficient distributed reinforcement learning through agreement,” inDistributed Autonomous Robotic Systems 8, pp. 367–378, Springer, 2009
2009
-
[37]
Learning multiagent communication with backpropagation,
S. Sukhbaatar, R. Fergus,et al., “Learning multiagent communication with backpropagation,” Advances in neural information processing systems, vol. 29, 2016
2016
-
[38]
Tarmac: Targeted multi-agent communication,
A. Das, T. Gervet, J. Romoff, D. Batra, D. Parikh, M. Rabbat, and J. Pineau, “Tarmac: Targeted multi-agent communication,” inInternational Conference on machine learning, pp. 1538–1546, PMLR, 2019
2019
-
[39]
Context-aware communication for multi-agent reinforcement learning,
X. Li and J. Zhang, “Context-aware communication for multi-agent reinforcement learning,” inProceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems, pp. 1156–1164, 2024
2024
-
[40]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Transformers for image recognition at scale,” inInternational Conference on Learning Representations, 2021
2021
-
[41]
Automatic stage lighting control: Is it a rule- driven process or generative task?,
Z. Zhao, D. Jin, Z. Zhou, and X. Zhang, “Automatic stage lighting control: Is it a rule- driven process or generative task?,” inThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[42]
On transforming reinforcement learning with transformers: The development trajectory,
S. Hu, L. Shen, Y . Zhang, Y . Chen, and D. Tao, “On transforming reinforcement learning with transformers: The development trajectory,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 12, pp. 8580–8599, 2024
2024
-
[43]
Deep recurrent q-learning for partially observable mdps.,
M. J. Hausknecht and P. Stone, “Deep recurrent q-learning for partially observable mdps.,” in AAAI fall symposia, vol. 45, p. 141, 2015
2015
-
[44]
Stabilizing transformers for reinforcement learning,
E. Parisotto, F. Song, J. Rae, R. Pascanu, C. Gulcehre, S. Jayakumar, M. Jaderberg, R. L. Kaufman, A. Clark, S. Noury,et al., “Stabilizing transformers for reinforcement learning,” in International conference on machine learning, pp. 7487–7498, PMLR, 2020
2020
-
[45]
Transdreamer: Reinforcement learning with trans- former world models,
C. Chen, J. Yoon, Y .-F. Wu, and S. Ahn, “Transdreamer: Reinforcement learning with trans- former world models,” inDeep RL Workshop NeurIPS 2021, 2021. 12
2021
-
[46]
Dream to control: Learning behaviors by latent imagination,
D. Hafner, T. Lillicrap, J. Ba, and M. Norouzi, “Dream to control: Learning behaviors by latent imagination,” inInternational Conference on Learning Representations, 2020
2020
-
[47]
Offline reinforcement learning as one big sequence modeling problem,
M. Janner, Q. Li, and S. Levine, “Offline reinforcement learning as one big sequence modeling problem,”Advances in neural information processing systems, vol. 34, pp. 1273–1286, 2021
2021
-
[48]
Decision transformer: Reinforcement learning via sequence modeling,
L. Chen, K. Lu, A. Rajeswaran, K. Lee, A. Grover, M. Laskin, P. Abbeel, A. Srinivas, and I. Mordatch, “Decision transformer: Reinforcement learning via sequence modeling,”Advances in neural information processing systems, vol. 34, pp. 15084–15097, 2021
2021
-
[49]
Online decision transformer,
Q. Zheng, A. Zhang, and A. Grover, “Online decision transformer,” ininternational conference on machine learning, pp. 27042–27059, PMLR, 2022
2022
-
[50]
Q-learning decision transformer: Leveraging dynamic programming for conditional sequence modelling in offline rl,
T. Yamagata, A. Khalil, and R. Santos-Rodriguez, “Q-learning decision transformer: Leveraging dynamic programming for conditional sequence modelling in offline rl,” inInternational Conference on Machine Learning, pp. 38989–39007, PMLR, 2023
2023
-
[51]
A survey on transfer learning,
S. J. Pan and Q. Yang, “A survey on transfer learning,”IEEE Transactions on knowledge and data engineering, vol. 22, no. 10, pp. 1345–1359, 2009
2009
-
[52]
Can Wikipedia help offline reinforcement learning? Preprint arXiv:2201.12122,
M. Reid, Y . Yamada, and S. S. Gu, “Can wikipedia help offline reinforcement learning?,”arXiv preprint arXiv:2201.12122, 2022
-
[53]
Pre-trained language models for interactive decision-making,
S. Li, X. Puig, C. Paxton, Y . Du, C. Wang, L. Fan, T. Chen, D.-A. Huang, E. Akyürek, A. Anandkumar,et al., “Pre-trained language models for interactive decision-making,”Advances in Neural Information Processing Systems, vol. 35, pp. 31199–31212, 2022
2022
-
[54]
Masked autoencoding for scalable and generalizable decision making,
F. Liu, H. Liu, A. Grover, and P. Abbeel, “Masked autoencoding for scalable and generalizable decision making,”Advances in Neural Information Processing Systems, vol. 35, pp. 12608– 12618, 2022
2022
-
[55]
Masked trajectory models for prediction, representation, and control,
P. Wu, A. Majumdar, K. Stone, Y . Lin, I. Mordatch, P. Abbeel, and A. Rajeswaran, “Masked trajectory models for prediction, representation, and control,” inInternational Conference on Machine Learning, pp. 37607–37623, PMLR, 2023
2023
-
[56]
Prompting decision transformer for few-shot policy generalization,
M. Xu, Y . Shen, S. Zhang, Y . Lu, D. Zhao, J. Tenenbaum, and C. Gan, “Prompting decision transformer for few-shot policy generalization,” ininternational conference on machine learning, pp. 24631–24645, PMLR, 2022
2022
-
[57]
Con- textual transformer for offline meta reinforcement learning,
R. Lin, Y . Li, X. Feng, Z. Zhang, X. H. W. Fung, H. Zhang, J. Wang, Y . Du, and Y . Yang, “Con- textual transformer for offline meta reinforcement learning,”arXiv preprint arXiv:2211.08016, 2022
-
[58]
Multi-game decision transformers,
K.-H. Lee, O. Nachum, M. S. Yang, L. Lee, D. Freeman, S. Guadarrama, I. Fischer, W. Xu, E. Jang, H. Michalewski,et al., “Multi-game decision transformers,”Advances in neural information processing systems, vol. 35, pp. 27921–27936, 2022
2022
-
[59]
S. Reed, K. Zolna, E. Parisotto, S. G. Colmenarejo, A. Novikov, G. Barth-Maron, M. Gimenez, Y . Sulsky, J. Kay, J. T. Springenberg,et al., “A generalist agent,”arXiv preprint arXiv:2205.06175, 2022
work page internal anchor Pith review arXiv 2022
-
[60]
Learning multi-agent communication from graph modeling perspective,
S. Hu, L. Shen, Y . Zhang, and D. Tao, “Learning multi-agent communication from graph modeling perspective,” 2024
2024
-
[61]
MaskMA: Towards zero-shot multi-agent decision making with mask-based collaborative learning,
J. Liu, Y . Zhang, C. Li, Z. You, Z. Zhou, C. Yang, Y . Yang, Y . Liu, and W. Ouyang, “MaskMA: Towards zero-shot multi-agent decision making with mask-based collaborative learning,”Trans- actions on Machine Learning Research, 2024
2024
-
[62]
Updet: Universal multi-agent reinforcement learning via policy decoupling with transformers,
S. Hu, F. Zhu, X. Chang, and X. Liang, “Updet: Universal multi-agent reinforcement learning via policy decoupling with transformers,”arXiv preprint arXiv:2101.08001, 2021
-
[63]
Pytorch: An imperative style, high-performance deep learning library,
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga,et al., “Pytorch: An imperative style, high-performance deep learning library,”Advances in Neural Information Processing Systems, vol. 32, 2019. 13
2019
-
[64]
On the theory of policy gradient methods: Optimality, approximation, and distribution shift,
A. Agarwal, S. M. Kakade, J. D. Lee, and G. Mahajan, “On the theory of policy gradient methods: Optimality, approximation, and distribution shift,”Journal of Machine Learning Research, vol. 22, no. 98, pp. 1–76, 2021
2021
-
[65]
On the global convergence rates of softmax policy gradient methods,
J. Mei, C. Xiao, C. Szepesvari, and D. Schuurmans, “On the global convergence rates of softmax policy gradient methods,” inInternational conference on machine learning, pp. 6820–6829, PMLR, 2020
2020
-
[66]
Convergence rates of bayesian network policy gradient for cooperative multi-agent reinforcement learning,
D. Chen, Z. Zhang, X. Kuang, X. Shen, O. Ozer, and Q. Zhang, “Convergence rates of bayesian network policy gradient for cooperative multi-agent reinforcement learning,” inNeurIPS 2024 Workshop on Bayesian Decision-making and Uncertainty, 2024
2024
-
[67]
A reinforcement learning algorithm for obtaining the nash equilib- rium of multi-player matrix games,
V . Nanduri and T. K. Das, “A reinforcement learning algorithm for obtaining the nash equilib- rium of multi-player matrix games,”IIE Transactions, vol. 41, no. 2, pp. 158–167, 2009
2009
-
[68]
R. S. Sutton, A. G. Barto,et al.,Reinforcement learning: An introduction, vol. 1. MIT press Cambridge, 1998
1998
-
[69]
Q. Xiao, S. Lu, and T. Chen, “A generalized alternating method for bilevel learning under the polyak-{\L}ojasiewicz condition,”arXiv preprint arXiv:2306.02422, 2023
-
[70]
Convergence proof for actor-critic methods applied to ppo and rudder,
M. Holzleitner, L. Gruber, J. Arjona-Medina, J. Brandstetter, and S. Hochreiter, “Convergence proof for actor-critic methods applied to ppo and rudder,” inTransactions on large-scale data- and knowledge-centered systems XLVIII: special issue in memory of univ. prof. dr. roland wagner, pp. 105–130, Springer, 2021
2021
-
[71]
Ppo-clip attains global optimality: To- wards deeper understandings of clipping,
N.-C. Huang, P.-C. Hsieh, K.-H. Ho, and I.-C. Wu, “Ppo-clip attains global optimality: To- wards deeper understandings of clipping,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, pp. 12600–12607, 2024
2024
-
[72]
Implicit learning dynamics in stackelberg games: Equilibria characterization, convergence analysis, and empirical study,
T. Fiez, B. Chasnov, and L. Ratliff, “Implicit learning dynamics in stackelberg games: Equilibria characterization, convergence analysis, and empirical study,” inInternational conference on machine learning, pp. 3133–3144, PMLR, 2020. 14 Appendix Contents A Related Work 16 A.1 Cooperative Multi-Agent Reinforcement Learning . . . . . . . . . . . . . . . . ...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.