Recognition: unknown
RobotPan: A 360^circ Surround-View Robotic Vision System for Embodied Perception
Pith reviewed 2026-05-10 13:19 UTC · model grok-4.3
The pith
RobotPan turns six surround cameras into compact 3D Gaussians for real-time 360-degree robotic rendering.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
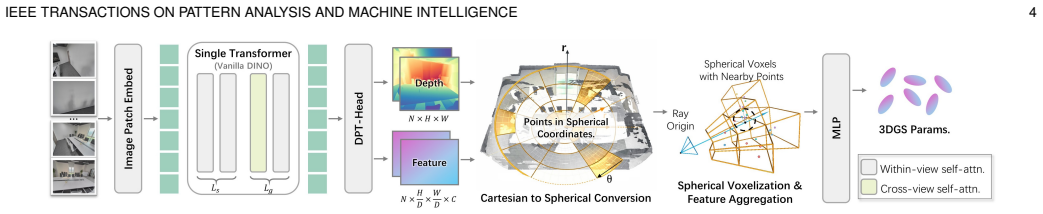
RobotPan lifts multi-view features into a unified spherical coordinate representation and decodes Gaussians using hierarchical spherical voxel priors, allocating fine resolution near the robot and coarser resolution at larger radii to reduce computational redundancy without sacrificing fidelity. To support long sequences, our online fusion updates dynamic content while preventing unbounded growth in static regions by selectively updating appearance.
What carries the argument
Hierarchical spherical voxel priors that allocate resolution by distance from the robot to decode compact metric 3D Gaussians from sparse calibrated views.
If this is right
- Achieves competitive quality against prior feed-forward reconstruction and view-synthesis methods.
- Produces substantially fewer Gaussians than those methods, enabling practical real-time embodied deployment.
- Delivers full 360-degree visual coverage that meets the geometric and real-time constraints of robotic platforms.
- Supports navigation, manipulation, and locomotion tasks via the released multi-sensor dataset.
Where Pith is reading between the lines
- Head-mounted display users in teleoperation could see reduced simulator sickness because jitter is avoided at the source.
- The compact representation may allow longer continuous operation than methods that accumulate unbounded elements.
- The spherical prior design could be tested on platforms with different camera counts or LiDAR densities to measure robustness.
Load-bearing premise
The hierarchical spherical voxel priors and selective online fusion can maintain fidelity and prevent unbounded growth in real-world robotic sequences with dynamic content.
What would settle it
Run the system on an extended sequence containing moving objects and check whether Gaussian count stays below practical limits while visual quality remains competitive with prior feed-forward baselines.
Figures








read the original abstract
Surround-view perception is increasingly important for robotic navigation and loco-manipulation, especially in human-in-the-loop settings such as teleoperation, data collection, and emergency takeover. However, current robotic visual interfaces are often limited to narrow forward-facing views, or, when multiple on-board cameras are available, require cumbersome manual switching that interrupts the operator's workflow. Both configurations suffer from motion-induced jitter that causes simulator sickness in head-mounted displays. We introduce a surround-view robotic vision system that combines six cameras with LiDAR to provide full 360$^\circ$ visual coverage, while meeting the geometric and real-time constraints of embodied deployment. We further present \textsc{RobotPan}, a feed-forward framework that predicts \emph{metric-scaled} and \emph{compact} 3D Gaussians from calibrated sparse-view inputs for real-time rendering, reconstruction, and streaming. \textsc{RobotPan} lifts multi-view features into a unified spherical coordinate representation and decodes Gaussians using hierarchical spherical voxel priors, allocating fine resolution near the robot and coarser resolution at larger radii to reduce computational redundancy without sacrificing fidelity. To support long sequences, our online fusion updates dynamic content while preventing unbounded growth in static regions by selectively updating appearance. Finally, we release a multi-sensor dataset tailored to 360$^\circ$ novel view synthesis and metric 3D reconstruction for robotics, covering navigation, manipulation, and locomotion on real platforms. Experiments show that \textsc{RobotPan} achieves competitive quality against prior feed-forward reconstruction and view-synthesis methods while producing substantially fewer Gaussians, enabling practical real-time embodied deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RobotPan, a feed-forward framework that predicts metric-scaled compact 3D Gaussians from calibrated sparse multi-view camera and LiDAR inputs for 360° surround-view robotic perception. It lifts features into a unified spherical coordinate representation, decodes Gaussians via hierarchical spherical voxel priors that allocate finer resolution near the robot and coarser at distance, and employs selective online fusion to update dynamic content while preventing unbounded growth in static regions. A new multi-sensor dataset for navigation, manipulation, and locomotion is released, with experiments claiming competitive quality against prior feed-forward reconstruction and view-synthesis methods alongside substantially fewer Gaussians for real-time embodied deployment.
Significance. If the quantitative claims are substantiated, the work has clear significance for robotic vision by enabling practical real-time 360° rendering and reconstruction that mitigates motion jitter and supports teleoperation and loco-manipulation without the computational burden of dense representations or manual view switching.
major comments (2)
- [Online Fusion] The selective online fusion (described after the hierarchical priors in the method) is load-bearing for the central claim of bounded Gaussian count and real-time viability in long sequences, yet the manuscript provides no explicit criteria, thresholds, or pseudocode for the dynamic-content selection heuristic. This leaves open the risk that slow-moving or lighting-varying elements are misclassified, undermining the 'preventing unbounded growth' assertion.
- [Experiments] The experimental claims of 'competitive quality' and 'substantially fewer Gaussians' (abstract and §5) rest on comparisons to prior feed-forward methods, but the provided text references results without detailing specific metrics such as PSNR/SSIM deltas, per-frame Gaussian counts, or runtime tables; this weakens verification of the practical deployment advantage.
minor comments (2)
- [Abstract] The abstract would benefit from approximate numerical values (e.g., 'X% fewer Gaussians' or 'Y ms/frame') to make the 'substantially fewer' claim more concrete.
- [Method] Clarify the exact definition of 'hierarchical resolution allocation thresholds' in the voxel prior description to avoid ambiguity in reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and describe the revisions we will implement to strengthen the manuscript.
read point-by-point responses
-
Referee: [Online Fusion] The selective online fusion (described after the hierarchical priors in the method) is load-bearing for the central claim of bounded Gaussian count and real-time viability in long sequences, yet the manuscript provides no explicit criteria, thresholds, or pseudocode for the dynamic-content selection heuristic. This leaves open the risk that slow-moving or lighting-varying elements are misclassified, undermining the 'preventing unbounded growth' assertion.
Authors: We agree that the selective online fusion requires more explicit documentation to substantiate the bounded Gaussian count claim. In the revised manuscript we will add the precise selection criteria (feature-difference and depth-consistency thresholds), the decision logic for classifying dynamic versus static content, and pseudocode for the fusion step. These additions will also clarify safeguards against misclassification of slow-moving objects or lighting changes. revision: yes
-
Referee: [Experiments] The experimental claims of 'competitive quality' and 'substantially fewer Gaussians' (abstract and §5) rest on comparisons to prior feed-forward methods, but the provided text references results without detailing specific metrics such as PSNR/SSIM deltas, per-frame Gaussian counts, or runtime tables; this weakens verification of the practical deployment advantage.
Authors: We acknowledge that the current presentation of quantitative results could be more explicit. In the revised manuscript we will include expanded tables reporting PSNR, SSIM, LPIPS, per-frame Gaussian counts, and runtime measurements with direct comparisons to baselines, thereby making the claimed advantages in quality and efficiency fully verifiable. revision: yes
Circularity Check
No circularity: derivation rests on independent architectural choices
full rationale
The paper presents RobotPan as a feed-forward network that lifts multi-view features into spherical coordinates and decodes Gaussians via hierarchical voxel priors plus selective online fusion. These are explicit design decisions allocating resolution and controlling growth; no equation or claim equates a prediction to its own fitted inputs by construction. No self-citations appear in the provided text, and the fewer-Gaussians outcome is stated as an empirical result of the priors and fusion heuristic rather than a definitional identity. The framework is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- hierarchical resolution allocation thresholds
axioms (1)
- domain assumption Calibrated sparse-view inputs from six cameras suffice for metric-scaled 3D reconstruction in robotic environments
invented entities (2)
-
hierarchical spherical voxel priors
no independent evidence
-
selective online fusion for dynamic content
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Dust3r: Geometric 3d vision made easy,
S. Wang, V . Leroy, Y. Cabon, B. Chidlovskii, and J. Revaud, “Dust3r: Geometric 3d vision made easy,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 20 697–20 709
2024
-
[2]
Grounding image matching in 3d with mast3r,
V . Leroy, Y. Cabon, and J. Revaud, “Grounding image matching in 3d with mast3r,” inEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[3]
Reloc3r: Large-scale training of relative camera pose regression for generalizable, fast, and accurate visual localization,
S. Dong, S. Wang, S. Liu, L. Cai, Q. Fan, J. Kannala, and Y. Yang, “Reloc3r: Large-scale training of relative camera pose regression for generalizable, fast, and accurate visual localization,” inPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[4]
3d reconstruction with spatial memory,
H. Wang and L. Agapito, “3d reconstruction with spatial memory,” inInternational Conference on 3D Vision (3DV), 2025
2025
-
[5]
Must3r: Multi-view network for stereo 3d reconstruction,
Y. Cabon, L. Stoffl, L. Antsfeld, G. Csurka, B. Chidlovskii, J. Re- vaud, and V . Leroy, “Must3r: Multi-view network for stereo 3d reconstruction,” inProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), 2025
2025
-
[6]
Slam3r: Real-time dense scene reconstruction from monocular rgb videos,
Y. Liu, S. Dong, S. Wang, Y. Yang, Q. Fan, and B. Chen, “Slam3r: Real-time dense scene reconstruction from monocular rgb videos,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[7]
Continuous 3d perception model with persistent state,
Q. Wang, Y. Zhang, A. Holynski, A. A. Efros, and A. Kanazawa, “Continuous 3d perception model with persistent state,” inPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[8]
Vggt: Visual geometry grounded transformer,
J. Wang, M. Chen, N. Karaev, A. Vedaldi, C. Rupprecht, and D. Novotny, “Vggt: Visual geometry grounded transformer,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[9]
Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass,
J. Yang, A. Sax, K. J. Liang, M. Henaff, H. Tang, A. Cao, J. Chai, F. Meier, and M. Feiszli, “Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[10]
3d gaus- sian splatting for real-time radiance field rendering
B. Kerbl, G. Kopanas, T. Leimk ¨uhler, and G. Drettakis, “3d gaus- sian splatting for real-time radiance field rendering.”ACM Trans. Graph., vol. 42, no. 4, pp. 139–1, 2023
2023
-
[11]
Mv-dust3r+: Single-stage scene reconstruction from sparse views in 2 seconds,
Z. Tang, Y. Fan, D. Wang, H. Xu, R. Ranjan, A. Schwing, and Z. Yan, “Mv-dust3r+: Single-stage scene reconstruction from sparse views in 2 seconds,” inProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), 2025, pp. 5283–5293
2025
-
[12]
Flare: Feed-forward geometry, appearance and camera estimation from uncalibrated sparse views,
S. Zhang, J. Wang, Y. Xu, N. Xue, C. Rupprecht, X. Zhou, Y. Shen, and G. Wetzstein, “Flare: Feed-forward geometry, appearance and camera estimation from uncalibrated sparse views,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 21 936–21 947
2025
-
[13]
π 3: Permutation-equivariant visual geometry learning,
Y. Wang, J. Zhou, H. Zhu, W. Chang, Y. Zhou, Z. Li, J. Chen, J. Pang, C. Shen, and T. He, “π 3: Permutation-equivariant visual geometry learning,” inInternational Conference on Learning Repre- sentations (ICLR), 2026
2026
-
[14]
TTT3R: 3D Reconstruction as Test-Time Train- ing.arXiv preprint :2509.26645, 2025
X. Chen, Y. Chen, Y. Xiu, A. Geiger, and A. Chen, “Ttt3r: 3d re- construction as test-time training,”arXiv preprint arXiv:2509.26645, 2025
-
[15]
Y. Shen, Z. Zhang, Y. Qu, X. Zheng, J. Ji, S. Zhang, and L. Cao, “Fastvggt: Training-free acceleration of visual geometry trans- former,”arXiv preprint arXiv:2509.02560, 2025
-
[16]
Nerf: Representing scenes as neural radiance fields for view synthesis,
B. Mildenhall, P . P . Srinivasan, M. Tancik, J. T. Barron, R. Ra- mamoorthi, and R. Ng, “Nerf: Representing scenes as neural radiance fields for view synthesis,”Communications of the ACM, vol. 65, no. 1, pp. 99–106, 2021
2021
-
[17]
pixelnerf: Neural radiance fields from one or few images,
A. Yu, V . Ye, M. Tancik, and A. Kanazawa, “pixelnerf: Neural radiance fields from one or few images,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021
2021
-
[18]
Mvsnerf: Fast generalizable radiance field reconstruction from multi-view stereo,
A. Chen, Z. Xu, F. Zhao, X. Zhang, F. Xiang, J. Yu, and H. Su, “Mvsnerf: Fast generalizable radiance field reconstruction from multi-view stereo,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021
2021
-
[19]
Hashpoint: Accelerated point searching and sampling for neural rendering,
J. Ma, M. Liu, D. Ahmedt-Aristizabal, and C. Nguyen, “Hashpoint: Accelerated point searching and sampling for neural rendering,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 4462–4472
2024
-
[20]
K. Ren, L. Jiang, T. Lu, M. Yu, L. Xu, Z. Ni, and B. Dai, “Octree- gs: Towards consistent real-time rendering with lod-structured 3d gaussians,”arXiv preprint arXiv:2403.17898, 2024
-
[21]
Scaffold-gs: Structured 3d gaussians for view-adaptive render- ing,
T. Lu, M. Yu, L. Xu, Y. Xiangli, L. Wang, D. Lin, and B. Dai, “Scaffold-gs: Structured 3d gaussians for view-adaptive render- ing,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 20 654–20 664
2024
-
[22]
Mip-splatting: Alias-free 3d gaussian splatting,
Z. Yu, A. Chen, B. Huang, T. Sattler, and A. Geiger, “Mip-splatting: Alias-free 3d gaussian splatting,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[23]
Puzzles: Unbounded video-depth augmentation for scalable end-to-end 3d reconstruction,
J. Ma, L. Wang, D. Ahmedt-Aristizabal, C. Nguyenet al., “Puzzles: Unbounded video-depth augmentation for scalable end-to-end 3d reconstruction,”arXiv preprint arXiv:2506.23863, 2025
-
[24]
Dchm: Depth-consistent human modeling for multiview detec- tion,
J. Ma, T. Wang, M. Liu, D. Ahmedt-Aristizabal, and C. Nguyen, “Dchm: Depth-consistent human modeling for multiview detec- tion,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 7731–7740
2025
-
[25]
Geonerf: Generalizing nerf with geometry priors,
M. Johari, C. Carta, and F. Fleuret, “Geonerf: Generalizing nerf with geometry priors,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[26]
pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction,
D. Charatan, S. Li, A. Tagliasacchi, and V . Sitzmann, “pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 19 457– 19 467
2024
-
[27]
Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images,
Y. Chen, H. Xu, C. Zheng, B. Zhuang, M. Pollefeys, A. Geiger, T.-J. Cham, and J. Cai, “Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images,” inEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[28]
Freesplat: Gen- eralizable 3d gaussian splatting towards free-view synthesis of indoor scenes,
Y. Wang, T. Huang, H. Chen, and G. H. Lee, “Freesplat: Gen- eralizable 3d gaussian splatting towards free-view synthesis of indoor scenes,” inAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[29]
Streamgs: Online generalizable gaussian splatting reconstruction for unposed image streams,
Y. Li, J. Wang, L. Chu, X. Li, S.-H. Kao, Y.-C. Chen, and Y. Lu, “Streamgs: Online generalizable gaussian splatting reconstruction for unposed image streams,” inProceedings of the IEEE/CVF Inter- national Conference on Computer Vision (ICCV), October 2025, pp. 25 841–25 850
2025
-
[30]
Salon3r: Structure-aware long-term generaliz- able 3d reconstruction from unposed images,
J. Guo, T. Guan, W. Dong, W. Zheng, W. Wang, Y. Wang, Y. Yam, and Y.-H. Liu, “Salon3r: Structure-aware long-term generaliz- able 3d reconstruction from unposed images,”arXiv preprint arXiv:2510.15072, 2025
-
[31]
No pose, no problem: Surprisingly simple 3d gaussian splats from sparse unposed images,
B. Ye, S. Liu, H. Xu, X. Li, M. Pollefeys, M.-H. Yang, and S. Peng, “No pose, no problem: Surprisingly simple 3d gaussian splats from sparse unposed images,” inInternational Conference on Learn- ing Representations (ICLR), 2025
2025
-
[32]
Splatt3r: Zero- shot gaussian splatting from uncalibrated image pairs,
B. Smart, C. Zheng, I. Laina, and V . A. Prisacariu, “Splatt3r: Zero- shot gaussian splatting from uncalibrated image pairs,” 2024
2024
-
[33]
Anysplat: Feed-forward 3d gaussian splatting from unconstrained views,
L. Jiang, Y. Mao, L. Xu, T. Lu, K. Ren, Y. Jin, X. Xu, M. Yu, J. Pang, F. Zhao, D. Lin, and B. Dai, “Anysplat: Feed-forward 3d gaussian splatting from unconstrained views,”ACM Transactions on Graphics (TOG), 2025
2025
-
[34]
Depthsplat: Connecting gaussian splatting and depth,
H. Xu, S. Peng, F. Wang, H. Blum, D. Barath, A. Geiger, and M. Pollefeys, “Depthsplat: Connecting gaussian splatting and depth,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 16 453–16 463
2025
-
[35]
Gs-lrm: Large reconstruction model for 3d gaussian splatting,
K. Zhang, S. Bi, H. Tan, Y. Xiangli, N. Zhao, K. Sunkavalli, and Z. Xu, “Gs-lrm: Large reconstruction model for 3d gaussian splatting,” inEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[36]
Compgs: Efficient 3d scene representation via compressed gaussian splatting,
X. Liu, X. Wu, P . Zhang, S. Wang, Z. Li, and S. Kwong, “Compgs: Efficient 3d scene representation via compressed gaussian splatting,” inProceedings of the 32nd ACM International Conference on Multimedia, 2024. [Online]. Available: https: //dl.acm.org/doi/10.1145/3610977.3630138
-
[38]
Available: https://arxiv.org/abs/2405.19479
[Online]. Available: https://arxiv.org/abs/2405.19479
-
[39]
Monoscene: Monocular 3d seman- tic scene completion,
A.-Q. Cao and R. de Charette, “Monoscene: Monocular 3d seman- tic scene completion,” inCVPR, 2022
2022
-
[40]
Sur- roundocc: Multi-camera 3d occupancy prediction for autonomous driving,
Y. Wei, L. Zhao, W. Zheng, Z. Zhu, J. Zhou, and J. Lu, “Sur- roundocc: Multi-camera 3d occupancy prediction for autonomous driving,” inICCV, 2023
2023
-
[41]
Tri-perspective view for vision-based 3d semantic occupancy prediction,
Y. Huang, W. Zheng, Y. Zhang, J. Zhou, and J. Lu, “Tri-perspective view for vision-based 3d semantic occupancy prediction,” in CVPR, 2023
2023
-
[42]
Gaussianformer: Scene as gaussians for vision-based 3d semantic occupancy prediction,
——, “Gaussianformer: Scene as gaussians for vision-based 3d semantic occupancy prediction,” inECCV, 2024
2024
-
[43]
Y. Wu, W. Zheng, S. Zuo, Y. Huang, J. Zhou, and J. Lu, “Embod- iedocc: Embodied 3d occupancy prediction for vision-based online scene understanding,”arXiv preprint arXiv:2412.04380, 2024. IEEE TRANSACTIONS ON PATTERN ANAL YSIS AND MACHINE INTELLIGENCE 12
-
[44]
Z. Zhang, Q. Zhang, W. Cui, S. Shi, Y. Guo, G. Han, W. Zhao, H. Ren, R. Xu, and J. Tang, “Roboocc: Enhancing the geometric and semantic scene understanding for robots,”arXiv preprint arXiv:2504.14604, 2025
-
[45]
Mobileocc: A human-aware semantic occupancy dataset for mobile robots,
J. Kimet al., “Mobileocc: A human-aware semantic occupancy dataset for mobile robots,”arXiv preprint arXiv:2511.16949, 2025
-
[46]
Humanoidpano: Hybrid spherical panoramic- lidar cross-modal perception for humanoid robots,
Q. Zhang, Z. Zhang, W. Cui, J. Sun, J. Cao, Y. Guo, G. Han, W. Zhao, J. Wang, C. Sun, L. Zhang, H. Cheng, Y. Chen, L. Wang, J. Tang, and R. Xu, “Humanoidpano: Hybrid spherical panoramic- lidar cross-modal perception for humanoid robots,”arXiv preprint arXiv:2503.09010, 2025
-
[47]
Panoramic multimodal semantic occupancy predic- tion for quadruped robots,
G. Zhaoet al., “Panoramic multimodal semantic occupancy predic- tion for quadruped robots,”arXiv preprint arXiv:2603.13108, 2026
-
[48]
Oneocc: Semantic occupancy prediction for legged robots with a single panoramic camera,
H. Shi, Z. Wang, S. Guo, M. Duan, S. Wang, T. Chen, K. Yang, L. Wang, and K. Wang, “Oneocc: Semantic occupancy prediction for legged robots with a single panoramic camera,”arXiv preprint arXiv:2511.03571, 2025
-
[49]
Z. Wang, T. Ma, Y. Jia, X. Yang, J. Zhou, W. Ouyang, Q. Zhang, and J. Liang, “Omni-perception: Omnidirectional collision avoidance for legged locomotion in dynamic environments,”arXiv preprint arXiv:2505.19214, 2025
-
[50]
Quadreamer: Controllable panoramic video generation for quadruped robots,
S. Wu, F. Teng, H. Shi, Q. Jiang, K. Luo, K. Wang, and K. Yang, “Quadreamer: Controllable panoramic video generation for quadruped robots,” inCoRL, 2025
2025
-
[51]
What makes for text to 360-degree panorama generation with stable diffusion?
J. Ni, C.-B. Zhang, Q. Zhang, and J. Zhang, “What makes for text to 360-degree panorama generation with stable diffusion?” inICCV, 2025
2025
-
[52]
W. Cui, H. Wang, W. Qin, Y. Guo, G. Han, W. Zhao, J. Cao, Z. Zhang, J. Zhong, J. Sun, P . Sun, S. Shi, B. Jiang, J. Ma, J. Wang, H. Cheng, Z. Liu, Y. Wang, Z. Zhu, G. Huang, J. Tang, and Q. Zhang, “Humanoid occupancy: Enabling a generalized multi- modal occupancy perception system on humanoid robots,”arXiv preprint arXiv:2507.20217, 2025
-
[53]
Dinov2: Learning robust visual features without supervision,
M. Oquab, T. Darcet, T. Moutakanni, H. Vo, M. Szafraniec, V . Khalidov, P . Fernandez, D. Haziza, F. Massa, A. El-Noubyet al., “Dinov2: Learning robust visual features without supervision,” Transactions on Machine Learning Research (TMLR), 2024
2024
-
[54]
Point-nerf: Point-based neural radiance fields,
Q. Xu, Z. Xu, J. Philip, S. Bi, Z. Shu, K. Sunkavalli, and U. Neu- mann, “Point-nerf: Point-based neural radiance fields,” inPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 5438–5448
2022
-
[55]
3dgstream: On-the-fly training of 3d gaussians for efficient streaming of photo-realistic free-viewpoint videos,
J. Sun, H. Jiao, G. Li, Z. Zhang, L. Zhao, and W. Xing, “3dgstream: On-the-fly training of 3d gaussians for efficient streaming of photo-realistic free-viewpoint videos,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion (CVPR), June 2024, pp. 20 675–20 685
2024
-
[56]
URL https://doi.org/10.1145/3528223
T. M ¨uller, A. Evans, C. Schied, and A. Keller, “Instant neural graphics primitives with a multiresolution hash encoding,”ACM Trans. Graph., vol. 41, no. 4, pp. 102:1–102:15, Jul. 2022. [Online]. Available: https://doi.org/10.1145/3528223.3530127
-
[57]
Large scale multi-view stereopsis evaluation,
R. Jensen, A. Dahl, G. Vogiatzis, E. Tola, and H. Aanæs, “Large scale multi-view stereopsis evaluation,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2014, pp. 406– 413
2014
-
[58]
A multi-view stereo benchmark with high-resolution images and multi-camera videos,
T. Schops, J. L. Schonberger, S. Galliani, T. Sattler, K. Schindler, M. Pollefeys, and A. Geiger, “A multi-view stereo benchmark with high-resolution images and multi-camera videos,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 3260–3269
2017
-
[59]
Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision,
L. Ling, Y. Sheng, Z. Tu, W. Zhao, C. Xin, K. Wan, L. Yu, Q. Guo, Z. Yu, Y. Luet al., “Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 22 160–22 169
2024
-
[60]
Stereo magnification: Learning view synthesis using multiplane images,
T. Zhou, R. Tucker, J. Flynn, G. Fyffe, and N. Snavely, “Stereo magnification: Learning view synthesis using multiplane images,” ACM Transactions on Graphics (TOG), vol. 37, no. 4, pp. 65:1–65:12, 2018
2018
-
[61]
K-planes: Explicit radiance fields in space, time, and appearance,
S. Fridovich-Keil, G. Meanti, F. R. Warburg, B. Recht, and A. Kanazawa, “K-planes: Explicit radiance fields in space, time, and appearance,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 12 479– 12 488
2023
-
[62]
4d gaussian splatting for real-time dynamic scene rendering,
G. Wu, T. Yi, J. Fang, L. Xie, X. Zhang, W. Wei, W. Liu, Q. Tian, and X. Wang, “4d gaussian splatting for real-time dynamic scene rendering,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 20 310–20 320
2024
-
[63]
Spacetime gaussian feature splatting for real-time dynamic view synthesis,
Z. Li, Z. Chen, Z. Li, and Y. Xu, “Spacetime gaussian feature splatting for real-time dynamic view synthesis,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2024, pp. 8508–8520
2024
-
[64]
Streaming radiance fields for 3d video synthesis,
L. Li, Z. Shen, Z. Wang, L. Shen, and P . Tan, “Streaming radiance fields for 3d video synthesis,”Advances in Neural Information Processing Systems, vol. 35, pp. 13 485–13 498, 2022
2022
-
[65]
Instant gaussian stream: Fast and generalizable stream- ing of dynamic scene reconstruction via gaussian splatting,
J. Yan, R. Peng, Z. Wang, L. Tang, J. Yang, J. Liang, J. Wu, and R. Wang, “Instant gaussian stream: Fast and generalizable stream- ing of dynamic scene reconstruction via gaussian splatting,” in Proceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 16 520–16 531
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.