Recognition: unknown
A Mechanistic Analysis of Sim-and-Real Co-Training in Generative Robot Policies
Pith reviewed 2026-05-10 12:25 UTC · model grok-4.3
The pith
Structured representation alignment between simulation and real data primarily drives success in co-training generative robot policies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
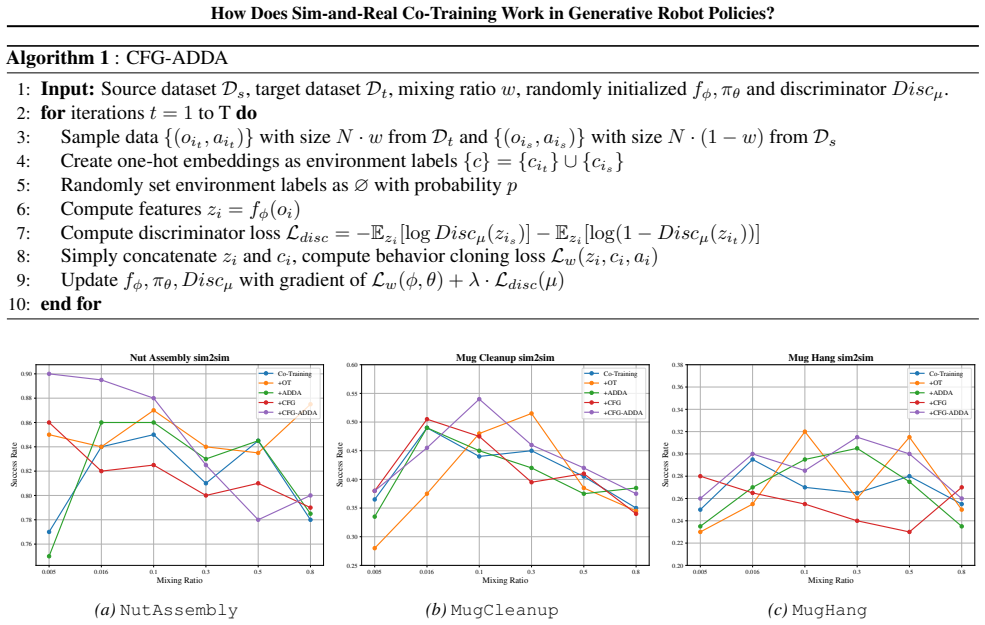
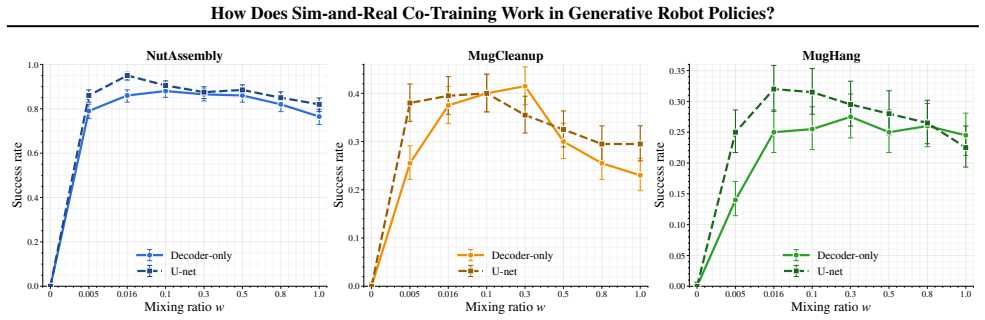
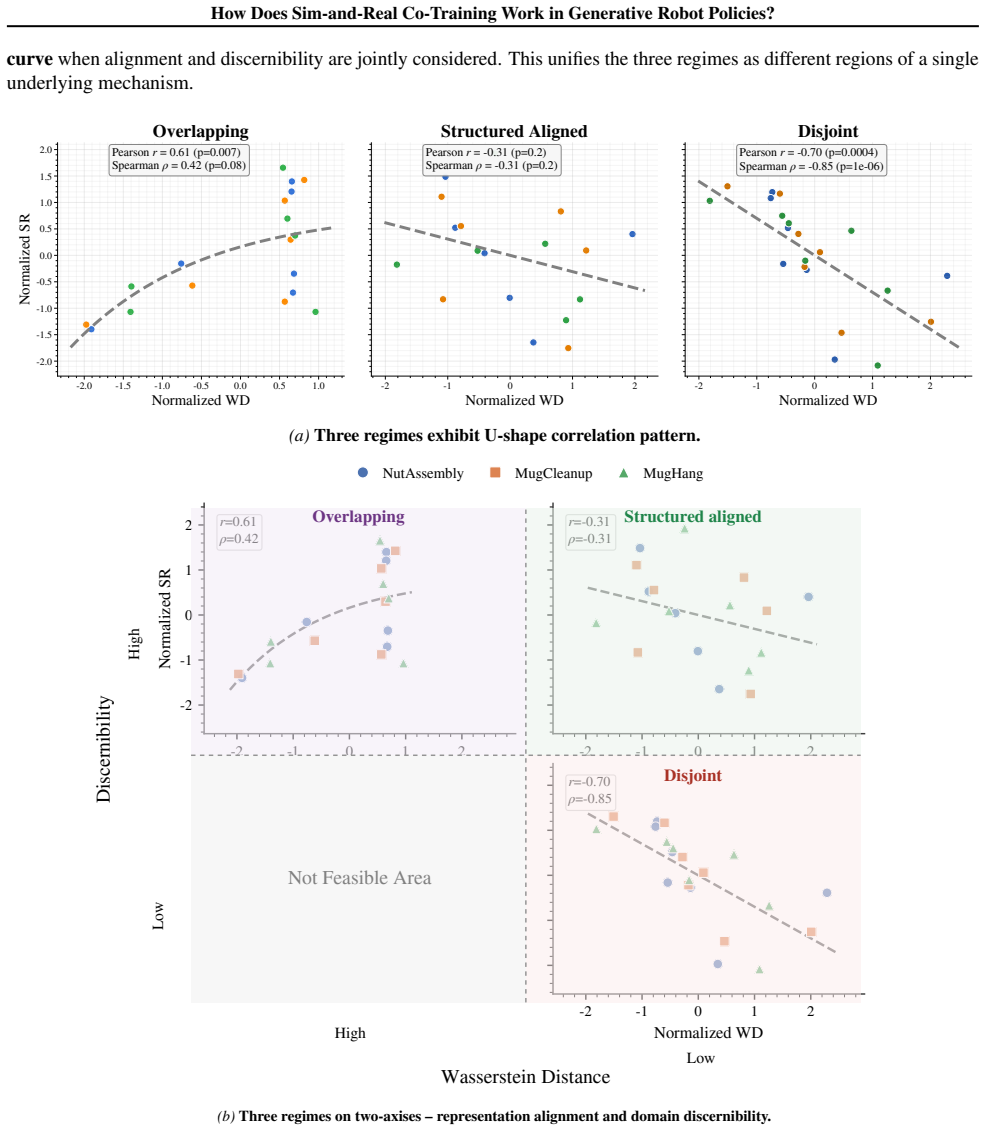
The authors establish that sim-and-real co-training performance is governed by two intrinsic effects. Structured representation alignment, reflecting the balance between cross-domain representation alignment and domain discernibility, plays the primary role in downstream performance. The importance reweighting effect, which arises from domain-dependent modulation of action weighting, operates at a secondary level. These effects are validated with theoretical analysis, a controlled toy model, and extensive sim-and-sim and sim-and-real robot manipulation experiments. The framework offers a unified interpretation of recent co-training techniques and motivates a simple method that consistently改善
What carries the argument
Structured representation alignment, the balance between cross-domain representation alignment and domain discernibility, which primarily determines downstream policy performance in co-training.
If this is right
- Recent co-training techniques can be reinterpreted as operating through the primary alignment effect and the secondary reweighting effect.
- Prioritizing balanced cross-domain alignment over pure domain mixing leads to stronger policy performance.
- Modulating the secondary importance reweighting effect provides additional but smaller gains.
- A simple adjustment method derived from the analysis improves results over prior co-training approaches in manipulation tasks.
Where Pith is reading between the lines
- The same alignment balance may guide co-training when using cross-embodiment data instead of simulation.
- Direct measurement of representation alignment could become a diagnostic tool for choosing surrogate datasets in robotics.
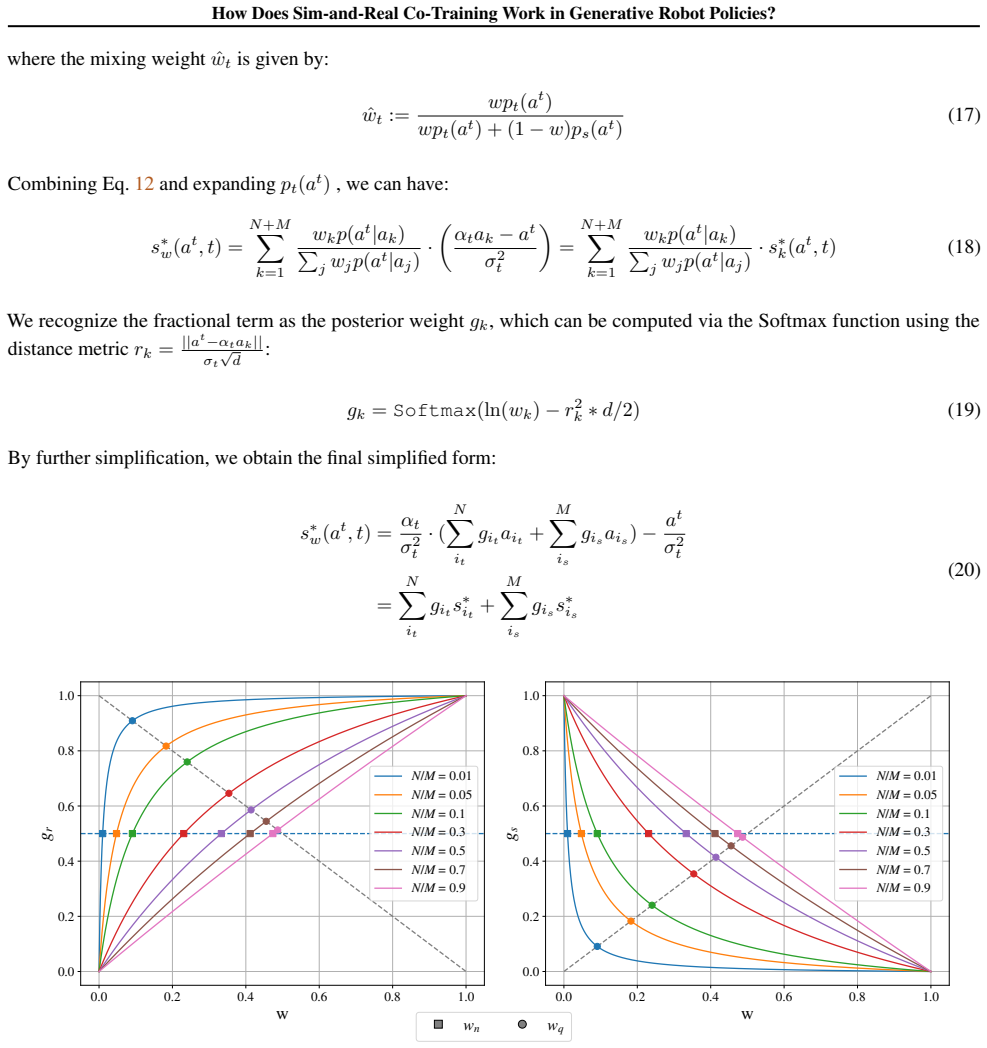
- The framework suggests testing whether the primary effect scales to higher-dimensional control tasks beyond the studied manipulations.
Load-bearing premise
The controlled toy model and the chosen sim-and-sim and sim-and-real manipulation experiments isolate the two effects without confounding influences from policy architecture or task specifics.
What would settle it
An experiment in the toy model where structured representation alignment is deliberately disrupted while keeping importance reweighting fixed, yet co-training performance does not decline as predicted, would falsify the primary role of alignment.
Figures













read the original abstract
Co-training, which combines limited in-domain real-world data with abundant surrogate data such as simulation or cross-embodiment robot data, is widely used for training generative robot policies. Despite its empirical success, the mechanisms that determine when and why co-training is effective remain poorly understood. We investigate the mechanism of sim-and-real co-training through theoretical analysis and empirical study, and identify two intrinsic effects governing performance. The first, \textbf{``structured representation alignment"}, reflects a balance between cross-domain representation alignment and domain discernibility, and plays a primary role in downstream performance. The second, the \textbf{``importance reweighting effect"}, arises from domain-dependent modulation of action weighting and operates at a secondary level. We validate these effects with controlled experiments on a toy model and extensive sim-and-sim and sim-and-real robot manipulation experiments. Our analysis offers a unified interpretation of recent co-training techniques and motivates a simple method that consistently improves upon prior approaches. More broadly, our aim is to examine the inner workings of co-training and to facilitate research in this direction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that sim-and-real co-training performance in generative robot policies is governed by two intrinsic effects: structured representation alignment (a balance between cross-domain alignment and domain discernibility) as the primary driver of downstream performance, and importance reweighting (domain-dependent action weighting) as secondary. It supports this via theoretical analysis, controlled toy-model experiments, and sim-and-sim plus sim-and-real robot manipulation tasks, providing a unified interpretation of prior techniques and motivating a simple improvement method.
Significance. If the mechanistic claims hold, the work offers a principled framework for understanding and improving co-training, which is widely used but poorly understood in robot learning. The dual theoretical-empirical approach and the concrete improvement method are practical strengths that could reduce reliance on ad-hoc tuning.
major comments (2)
- [§4] §4 (toy model): The claim that structured representation alignment is primary requires explicit isolation from importance reweighting. The experiments must show that alignment metrics explain substantially more performance variance than reweighting (e.g., via ablation or regression); without this, the primary/secondary distinction risks being confounded by generative sampling dynamics.
- [§5] §5 (sim-and-real manipulation experiments): Attribution of effects to policy performance would be strengthened by a variance decomposition or controlled ablation that holds reweighting fixed while modulating alignment (or vice versa). Current setups may entangle representation learning with action distribution changes, weakening causal claims about the two effects.
minor comments (2)
- [§3] Clarify notation for 'domain discernibility' and 'structured representation alignment' early in the theoretical section to distinguish them from standard contrastive or mutual-information metrics.
- [Figure 3] Figure captions for the toy-model results should explicitly state the controlled variables and any post-hoc data exclusion rules.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for highlighting opportunities to strengthen the isolation of effects in our analysis. We address each major comment below and describe the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (toy model): The claim that structured representation alignment is primary requires explicit isolation from importance reweighting. The experiments must show that alignment metrics explain substantially more performance variance than reweighting (e.g., via ablation or regression); without this, the primary/secondary distinction risks being confounded by generative sampling dynamics.
Authors: In the toy-model experiments of §4, we constructed the generative process such that the latent representation parameters (controlling cross-domain alignment and domain discernibility) are varied independently while the action distributions are held identical across domains. This design eliminates domain-dependent action reweighting by construction, allowing performance differences to be attributed to structured representation alignment. To make the primary/secondary distinction more rigorous, we will add in the revision (i) a set of ablations that explicitly fix reweighting and modulate alignment, and (ii) a regression analysis reporting the fraction of performance variance explained by alignment metrics versus reweighting terms. revision: yes
-
Referee: [§5] §5 (sim-and-real manipulation experiments): Attribution of effects to policy performance would be strengthened by a variance decomposition or controlled ablation that holds reweighting fixed while modulating alignment (or vice versa). Current setups may entangle representation learning with action distribution changes, weakening causal claims about the two effects.
Authors: We acknowledge that the sim-and-real tasks involve some coupling between representation learning and action distributions. Our sim-and-sim experiments already provide a more separable setting in which the two effects can be modulated independently. For the sim-and-real results, we will introduce additional controlled ablations in the revised manuscript: we will hold action reweighting fixed by employing domain-invariant action sampling and vary alignment through targeted regularization on the representation space. We will also report a variance decomposition that quantifies the relative contribution of each effect to downstream success rate. revision: yes
Circularity Check
No significant circularity; analysis derives effects from theory then validates independently on held-out experiments
full rationale
The paper's chain begins with theoretical identification of two effects (structured representation alignment as primary, importance reweighting as secondary) from mechanistic analysis of co-training, followed by validation on a controlled toy model plus separate sim-and-sim and sim-and-real manipulation tasks. No quoted equations or claims show a 'prediction' or derived quantity reducing by construction to the same fitted inputs or data used to define the effects. Self-citations, if present, are not load-bearing for the central claims, and experiments are described as isolating the effects via controlled variation. The derivation remains self-contained against external benchmarks rather than tautological.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Barreiros, J., Beaulieu, A., Bhat, A., Cory, R., Cousineau, E., Dai, H., Fang, C.-H., Hashimoto, K., Irshad, M. Z., Itkina, M., et al. A careful examination of large behav- ior models for multitask dexterous manipulation. arXiv preprint arXiv:2507.05331,
-
[2]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Bjorck, J., Casta˜neda, F., Cherniadev, N., Da, X., Ding, R., Fan, L., Fang, Y ., Fox, D., Hu, F., Huang, S., et al. Gr00t n1: An open foundation model for generalist humanoid robots. arXiv preprint arXiv:2503.14734,
work page internal anchor Pith review arXiv
-
[3]
arXiv preprint arXiv:2511.15704 (2025)
Cai, X., Qiu, R.-Z., Chen, G., Wei, L., Liu, I., Huang, T., Cheng, X., and Wang, X. In-n-on: Scaling egocentric manipulation with in-the-wild and on-task data. arXiv preprint arXiv:2511.15704,
-
[4]
Generalizable domain adaptation for sim-and- real policy co-training
Cheng, S., Ma, L., Chen, Z., Mandlekar, A., Garrett, C., and Xu, D. Generalizable domain adaptation for sim-and- real policy co-training. arXiv preprint arXiv:2509.18631,
- [5]
-
[6]
P., and Salimans, T
Gao, R., Hoogeboom, E., Heek, J., De Bortoli, V ., Murphy, K. P., and Salimans, T. Diffusion models and gaussian flow matching: Two sides of the same coin. InThe Fourth Blogpost Track at ICLR 2025,
2025
-
[7]
S., Sartoretti, G., and Schwager, M
He, C., Liu, X., Camps, G. S., Sartoretti, G., and Schwager, M. Demystifying diffusion policies: Action memoriza- tion and simple lookup table alternatives. arXiv preprint arXiv:2505.05787,
-
[8]
Classifier-Free Diffusion Guidance
Ho, J. and Salimans, T. Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598,
work page internal anchor Pith review arXiv
-
[9]
Po- laRiS: Scalable real-to-sim evaluations for generalist robot policies, 2025
Jain, A., Zhang, M., Arora, K., Chen, W., Torne, M., Irshad, M. Z., Zakharov, S., Wang, Y ., Levine, S., Finn, C., et al. Polaris: Scalable real-to-sim evaluations for generalist robot policies. arXiv preprint arXiv:2512.16881,
-
[10]
J., and Zhu, Y
Jiang, Z., Xie, Y ., Lin, K., Xu, Z., Wan, W., Mandlekar, A., Fan, L. J., and Zhu, Y . Dexmimicgen: Automated data generation for bimanual dexterous manipulation via im- itation learning. In 2025 IEEE International Conference on Robotics and Automation (ICRA), pp. 16923–16930. IEEE,
2025
-
[11]
Kareer, S., Patel, D., Punamiya, R., Mathur, P., Cheng, S., Wang, C., Hoffman, J., and Xu, D. Egomimic: Scaling imitation learning via egocentric video. In 2025 IEEE International Conference on Robotics and Automation (ICRA), pp. 13226–13233. IEEE, 2025a. 11 How Does Sim-and-Real Co-Training Work in Generative Robot Policies? Kareer, S., Pertsch, K., Darp...
-
[12]
Lepert, M., Fang, J., and Bohg, J. Masquerade: Learning from in-the-wild human videos using data-editing. arXiv preprint arXiv:2508.09976, 2025a. Lepert, M., Fang, J., and Bohg, J. Phantom: Training robots without robots using only human videos. arXiv preprint arXiv:2503.00779, 2025b. Li, S., Gao, Y ., Sadigh, D., and Song, S. Unified video action model. ...
-
[13]
Video generators are robot policies.arXiv preprint arXiv:2508.00795, 2025
Liang, J., Tokmakov, P., Liu, R., Sudhakar, S., Shah, P., Ambrus, R., and V ondrick, C. Video generators are robot policies. arXiv preprint arXiv:2508.00795,
-
[14]
Lin, F., Arora, K., Mercat, J., Nishimura, H., Shah, P., Xu, C., Zhang, M., Zolotas, M., Angeles, M., Pfannenstiehl, O., et al. A systematic study of data modalities and strategies for co-training large behavior models for robot manipulation. arXiv preprint arXiv:2602.01067,
-
[15]
Constraint-preserving data gen- eration for visuomotor policy learning
Lin, K., Ragunath, V ., McAlinden, A., Prasad, A., Wu, J., Zhu, Y ., and Bohg, J. Constraint-preserving data gen- eration for visuomotor policy learning. arXiv preprint arXiv:2508.03944,
-
[16]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Liu, X., Gong, C., and Liu, Q. Flow straight and fast: Learning to generate and transfer data with rectified flow. arXiv preprint arXiv:2209.03003,
work page internal anchor Pith review arXiv
-
[17]
Being-h0: Vision-language-action pretraining from large-scale human videos, 2025
Luo, H., Feng, Y ., Zhang, W., Zheng, S., Wang, Y ., Yuan, H., Liu, J., Xu, C., Jin, Q., and Lu, Z. Being-h0: vision-language-action pretraining from large-scale hu- man videos. arXiv preprint arXiv:2507.15597,
-
[18]
Y ., Nasiriany, S., Xie, Y ., Fang, Y ., Huang, W., Wang, Z., Xu, Z., Chernyadev, N., et al
Maddukuri, A., Jiang, Z., Chen, L. Y ., Nasiriany, S., Xie, Y ., Fang, Y ., Huang, W., Wang, Z., Xu, Z., Chernyadev, N., et al. Sim-and-real co-training: A simple recipe for vision-based robotic manipulation. arXiv preprint arXiv:2503.24361,
-
[19]
Mimicgen: A data generation system for scalable robot learning using human demonstrations, 2023
Mandlekar, A., Nasiriany, S., Wen, B., Akinola, I., Narang, Y ., Fan, L., Zhu, Y ., and Fox, D. Mimicgen: A data gen- eration system for scalable robot learning using human demonstrations. arXiv preprint arXiv:2310.17596,
-
[20]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
McInnes, L., Healy, J., and Melville, J. Umap: Uniform manifold approximation and projection for dimension reduction. arXiv preprint arXiv:1802.03426,
work page internal anchor Pith review arXiv
-
[21]
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Mittal, M., Roth, P., Tigue, J., Richard, A., Zhang, O., Du, P., Serrano-Mu˜noz, A., Yao, X., Zurbr¨ugg, R., Rudin, N., et al. Isaac lab: A gpu-accelerated simulation frame- work for multi-modal robot learning. arXiv preprint arXiv:2511.04831,
work page internal anchor Pith review arXiv
-
[22]
RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots
Nasiriany, S., Maddukuri, A., Zhang, L., Parikh, A., Lo, A., Joshi, A., Mandlekar, A., and Zhu, Y . Robocasa: Large- scale simulation of everyday tasks for generalist robots. arXiv preprint arXiv:2406.02523,
work page internal anchor Pith review arXiv
-
[23]
6892–6903
In 2024 IEEE International Conference on Robotics and Automation (ICRA), pp. 6892–6903. IEEE,
2024
-
[24]
Much ado about noising: Dispelling the myths of generative robotic control,
Pan, C., Anantharaman, G., Huang, N.-C., Jin, C., Pfrom- mer, D., Yuan, C., Permenter, F., Qu, G., Boffi, N., Shi, G., et al. Much ado about noising: Dispelling the myths of generative robotic control. arXiv preprint arXiv:2512.01809,
-
[25]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence. π0.5: a vision-language-action model with open-world generalization. arXiv preprint arXiv:2504.16054,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Selective underfitting in diffusion models.arXiv preprint arXiv:2510.01378,
Song, K., Kim, J., Chen, S., Du, Y ., Kakade, S., and Sitz- mann, V . Selective underfitting in diffusion models.arXiv preprint arXiv:2510.01378,
-
[27]
Wei, A., Agarwal, A., Chen, B., Bosworth, R., Pfaff, N., and Tedrake, R. Empirical analysis of sim-and-real cotraining of diffusion policies for planar pushing from pixels.arXiv preprint arXiv:2503.22634,
-
[28]
Dexumi: Using human hand as the universal manipulation interface for dexterous manipulation, 2025
Xu, M., Zhang, H., Hou, Y ., Xu, Z., Fan, L., Veloso, M., and Song, S. Dexumi: Using human hand as the universal manipulation interface for dexterous manipulation. arXiv preprint arXiv:2505.21864,
-
[29]
Pushing the lim- its of cross-embodiment learning for manipulation and navigation
Yang, J., Glossop, C., Bhorkar, A., Shah, D., Vuong, Q., Finn, C., Sadigh, D., and Levine, S. Pushing the lim- its of cross-embodiment learning for manipulation and navigation. arXiv preprint arXiv:2402.19432,
-
[30]
Latent Action Pretraining from Videos
Ye, S., Jang, J., Jeon, B., Joo, S., Yang, J., Peng, B., Mandlekar, A., Tan, R., Chao, Y .-W., Lin, B. Y ., et al. Latent action pretraining from videos. arXiv preprint arXiv:2410.11758,
-
[31]
Real2render2real: Scaling robot data without dynamics simulation or robot hardware,
Yu, J., Fu, L., Huang, H., El-Refai, K., Ambrus, R. A., Cheng, R., Irshad, M. Z., and Goldberg, K. Real2render2real: Scaling robot data without dynam- ics simulation or robot hardware. arXiv preprint arXiv:2505.09601,
-
[32]
Yuan, C., Zhou, R., Liu, M., Hu, Y ., Wang, S., Yi, L., Wen, C., Zhang, S., and Gao, Y . Motiontrans: Human vr data enable motion-level learning for robotic manipulation policies. arXiv preprint arXiv:2509.17759,
-
[33]
Zakka, K., Tabanpour, B., Liao, Q., Haiderbhai, M., Holt, S., Luo, J. Y ., Allshire, A., Frey, E., Sreenath, K., Kahrs, L. A., et al. Mujoco playground. arXiv preprint arXiv:2502.08844,
-
[34]
Zawalski, M., Chen, W., Pertsch, K., Mees, O., Finn, C., and Levine, S. Robotic control via embodied chain-of-thought reasoning. arXiv preprint arXiv:2407.08693,
-
[35]
Zhou, G., Pan, H., LeCun, Y ., and Pinto, L. Dino-wm: World models on pre-trained visual features enable zero- shot planning. arXiv preprint arXiv:2411.04983,
-
[36]
Unified World Models: Coupling Video and Action Diffusion for Pretraining on Large Robotic Datasets
Zhu, C., Yu, R., Feng, S., Burchfiel, B., Shah, P., and Gupta, A. Unified world models: Coupling video and action diffusion for pretraining on large robotic datasets. arXiv preprint arXiv:2504.02792,
work page internal anchor Pith review arXiv
-
[37]
robosuite: A Modular Simulation Framework and Benchmark for Robot Learning
Zhu, Y ., Wong, J., Mandlekar, A., Mart´ın-Mart´ın, R., Joshi, A., Nasiriany, S., and Zhu, Y . robosuite: A modular simulation framework and benchmark for robot learning. arXiv preprint arXiv:2009.12293,
work page internal anchor Pith review arXiv 2009
-
[38]
Simulation Pre-training+Real Fine-tine
13 How Does Sim-and-Real Co-Training Work in Generative Robot Policies? Contents 1 Introduction 2 2 Theoretical Analysis of Co-Training 2 2.1 Structured Representation Alignment . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3 2.2 Importance Reweighting Effect . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ....
2025
-
[39]
and automated data generation tools (Mandlekar et al., 2023; Jiang et al., 2025; Lin et al., 2025), high-quality and massive robot trajectories can be obtained easily. Many works have demonstrated the effectiveness of sim-and-real co-training on challenging manipulation tasks with small diffusion policy models (Maddukuri et al., 2025; Wei et al., 2025; Ch...
2023
-
[40]
There are also works (Barreiros et al., 2025; Jain et al.,
and even large Vision-Language-Action(VLA) models (Bjorck et al., 2025; Yu et al., 2025). There are also works (Barreiros et al., 2025; Jain et al.,
2025
-
[41]
Cross-Embodiment Co-Training.A large amount of work (Doshi et al., 2024; Yang et al., 2024; O’Neill et al., 2024; Physical Intelligence, 2025; Yuan et al.,
utilizing relatively large-scale real-world data and a small amount of simulation data for co-training, so that the performance evaluated in simulation can effectively reflect the performance in the real world. Cross-Embodiment Co-Training.A large amount of work (Doshi et al., 2024; Yang et al., 2024; O’Neill et al., 2024; Physical Intelligence, 2025; Yua...
2024
-
[42]
The main domain gaps include the visual appearance and the embodiment-physics gap
has explored using cross-embodiment robot data for co-training, where a single policy is trained with multiple embodiments with a unified architecture and action representation. The main domain gaps include the visual appearance and the embodiment-physics gap. Human data is a special case of them, which can be directly treated as another embodiment. These...
2025
-
[43]
Another line of work (Xu et al., 2025; Lepert et al., 2025b;a) forces input data distribution alignment via image editing
utilize representation alignment regularization, such as optimal transport and adversarial discriminator. Another line of work (Xu et al., 2025; Lepert et al., 2025b;a) forces input data distribution alignment via image editing. Non-Robot Data Co-Training.Internet-scale multimodal data without action labels is another valuable co-training resource. Numero...
2025
-
[44]
explicitly extract action labels but with the problem of accuracy; some works (Ye et al., 2024; Zhou et al.,
2024
-
[45]
explored latent action representations by encoding changes between video frames; other works (Li et al., 2025; Zhu et al., 2025; Liang et al.,
2025
-
[46]
propose to co-train the action- and actionless video data within a unified architecture. A.2. Representation Learning in Domain Adaptation Co-training can also be viewed as semi-supervised or unsupervised domain adaptation. A central theme in domain adaptation is learning representations that enable knowledge transfer across domains while mitigating distr...
2010
-
[47]
These make the softmax weights extremely imbalanced, which is nearly biased towards the nearest training data. 17 How Does Sim-and-Real Co-Training Work in Generative Robot Policies? 0.0 0.2 0.4 0.6 0.8 1.0 x 0.0 0.2 0.4 0.6 0.8 1.0Bhattacharyya coefficient Overlap measurement Real-Sim Real-Real Figure 12.Empirical measurement about training sample overla...
2025
discussion (0)
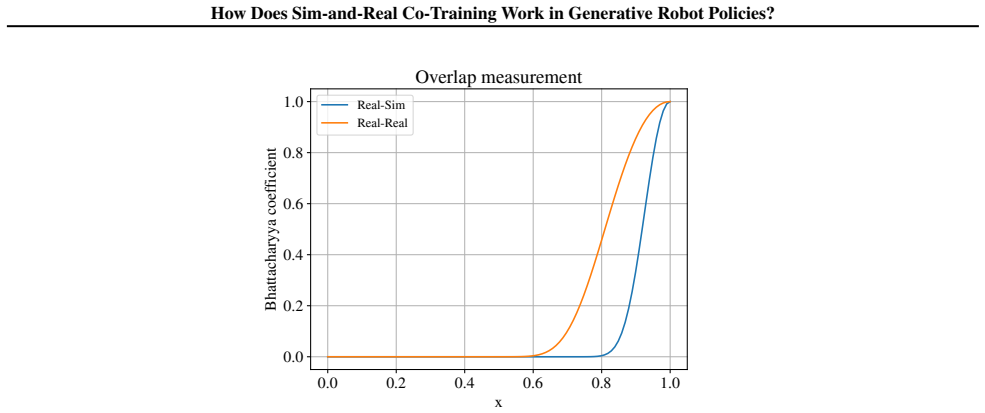
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.