Recognition: unknown
MIND: AI Co-Scientist for Material Research
Pith reviewed 2026-05-10 12:38 UTC · model grok-4.3
The pith
A multi-agent LLM pipeline refines materials hypotheses, runs virtual experiments, and debates their validity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
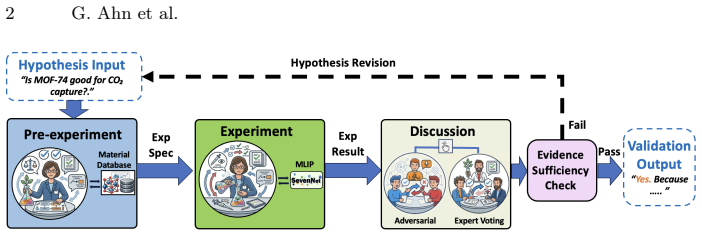
The central claim is that large language models organized as cooperating agents, combined with machine learning models of interatomic forces, can carry out the full sequence of hypothesis refinement, in-silico testing, and validation through structured debate, thereby automating a key part of the materials research workflow without constant human direction.
What carries the argument
The multi-agent pipeline that sequences hypothesis refinement, experimentation via interatomic potential models, and debate-based validation.
If this is right
- Researchers can test many more hypotheses per unit time by replacing physical trials with fast simulations.
- New types of experimental verification can be added as separate modules without redesigning the whole system.
- A web interface lets users start and review automated validation runs directly.
- The same structure supports repeated cycles of refinement until a hypothesis either passes or is rejected.
Where Pith is reading between the lines
- The method could be applied to other simulation-rich fields such as chemistry or battery design where similar atomic models exist.
- Systematic comparison of the framework's accepted hypotheses against later lab results would quantify how often it produces usable leads.
- If the debate stage reliably filters weak ideas, the overall workflow might reduce the fraction of ideas that reach expensive physical testing.
- Extending the simulation component to include temperature or defect effects would test how far the current verification step can be pushed.
Load-bearing premise
Large language models can generate and judge scientifically accurate hypotheses in materials research, and the chosen computer models of atomic interactions give results close enough to reality to stand in for physical tests.
What would settle it
Run the system on a set of hypotheses whose outcomes are already known from laboratory measurements and check whether the automated validations match the measured material properties or produce clear contradictions.
Figures

read the original abstract
Large language models (LLMs) have enabled agentic AI systems for scientific discovery, but most approaches remain limited to textbased reasoning without automated experimental verification. We propose MIND, an LLM-driven framework for automated hypothesis validation in materials research. MIND organizes the scientific discovery process into hypothesis refinement, experimentation, and debate-based validation within a multi-agent pipeline. For experimental verification, the system integrates Machine Learning Interatomic Potentials, particularly SevenNet-Omni, enabling scalable in-silico experiments. We also provide a web-based user interface for automated hypothesis testing. The modular design allows additional experimental modules to be integrated, making the framework adaptable to broader scientific workflows. The code is available at: https://github.com/IMMS-Ewha/MIND, and a demonstration video at: https://youtu.be/lqiFe1OQzN4.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MIND, an LLM-driven multi-agent framework for automated hypothesis validation in materials research. It organizes the discovery process into hypothesis refinement, experimentation using Machine Learning Interatomic Potentials (particularly SevenNet-Omni for scalable in-silico experiments), and debate-based validation. The system includes a modular design for adding experimental modules and provides a web-based UI, with code released on GitHub.
Significance. If the described components function as intended, the framework could advance automated scientific workflows in materials science by combining LLM reasoning with computational verification tools. The open-sourcing of the code and UI is a clear strength that supports reproducibility and extension by the community. However, the absence of any empirical evaluation means the significance remains prospective rather than established.
major comments (2)
- [Abstract] Abstract: The claim that MIND 'enables automated hypothesis validation' rests on the multi-agent pipeline and SevenNet-Omni integration, yet the manuscript supplies no success rates, ablation studies, ground-truth benchmarks, or comparisons to DFT/experiment baselines to substantiate this.
- [MIND multi-agent pipeline] Framework description: The assumption that LLM agents can reliably generate, refine, and debate materials hypotheses to a scientifically useful level is load-bearing for the central claim but is presented without any concrete examples, error analysis, or tests of the debate module.
minor comments (2)
- The manuscript would benefit from a workflow diagram or pseudocode for the agent interactions to improve clarity of the pipeline.
- Consider expanding the related work section to explicitly compare MIND against other LLM-agent systems for scientific discovery (e.g., those using different validation strategies).
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript describing the MIND framework. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that MIND 'enables automated hypothesis validation' rests on the multi-agent pipeline and SevenNet-Omni integration, yet the manuscript supplies no success rates, ablation studies, ground-truth benchmarks, or comparisons to DFT/experiment baselines to substantiate this.
Authors: We acknowledge that the current manuscript does not include quantitative success rates, ablation studies, ground-truth benchmarks, or direct comparisons to DFT or experimental baselines. The central claim concerns the design of a modular, LLM-driven pipeline that integrates hypothesis refinement, ML interatomic potential-based experimentation (via SevenNet-Omni), and debate-based validation, with the open-source code and UI provided to enable such validation by users. As a framework paper, the contribution focuses on the architecture and reproducibility rather than a benchmarked performance study. To address this, we will revise the abstract for precision and add a new section with concrete illustrative examples of end-to-end hypothesis validation runs using the released implementation, including qualitative outcomes and basic performance indicators from the system. revision: yes
-
Referee: [MIND multi-agent pipeline] Framework description: The assumption that LLM agents can reliably generate, refine, and debate materials hypotheses to a scientifically useful level is load-bearing for the central claim but is presented without any concrete examples, error analysis, or tests of the debate module.
Authors: We agree that the manuscript would benefit from concrete examples and analysis of the multi-agent components, especially the debate module. The current description outlines the pipeline structure and agent roles, but does not include sample interaction traces or error cases. In the revision, we will incorporate specific examples of hypothesis generation, refinement, and debate sessions drawn from the open-source code, along with a brief discussion of observed failure modes and mitigation strategies within the modular design. revision: yes
Circularity Check
No circularity: system proposal without derivations or self-referential predictions
full rationale
The manuscript describes MIND as an LLM-based multi-agent framework for hypothesis refinement, experimentation via SevenNet-Omni MLIPs, and debate validation, plus a web UI. No equations, parameter fits, uniqueness theorems, or predictions appear in the abstract or architecture description. The central claims concern the proposed modular design and its intended use for materials research rather than any derived result that reduces to its own inputs by construction. The value is asserted to rest on future empirical application, not internal consistency of a derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can be orchestrated in a multi-agent pipeline to perform reliable hypothesis refinement and debate-based validation for materials science
invented entities (1)
-
MIND multi-agent pipeline
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Towards Agentic AI for Science: Hypothesis Generation, Comprehension, Quantification, and Validation (2025)
Bazgir, A., Zhang, Y., et al.: Agentichypothesis: A survey on hypothesis genera- tion using llm systems. Towards Agentic AI for Science: Hypothesis Generation, Comprehension, Quantification, and Validation (2025)
2025
-
[2]
Gottweis, J., Weng, W.H., Daryin, A., Tu, T., Palepu, A., Sirkovic, P., Myaskovsky, A., Weissenberger, F., Rong, K., Tanno, R., et al.: Towards an ai co-scientist. arXiv preprint arXiv:2502.18864 (2025)
work page internal anchor Pith review arXiv 2025
-
[3]
Nature Communications (2026)
Kim, J., You, J., Park, Y., Lim, Y., Kang, Y., Kim, J., Jeon, H., Ju, S., Hong, D., Lee, S.Y., et al.: Optimizing cross-domain transfer for universal machine learning interatomic potentials. Nature Communications (2026)
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.