Recognition: unknown
EmbodiedClaw: Conversational Workflow Execution for Embodied AI Development
Pith reviewed 2026-05-10 13:31 UTC · model grok-4.3
The pith
A conversational agent automates the full workflow of embodied AI research from user goals alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
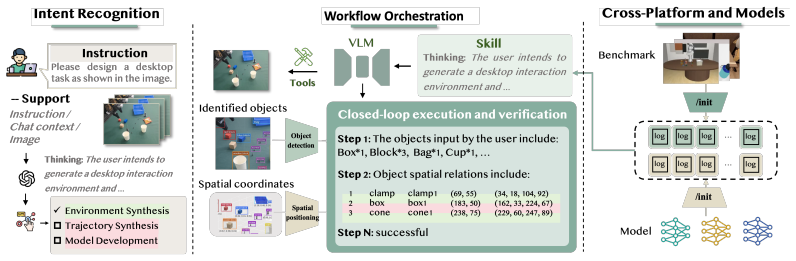
EmbodiedClaw is a conversational agent that turns high-level user instructions into planned sequences of embodied-AI development skills, covering environment creation and revision, benchmark transformation, trajectory synthesis, model evaluation, and asset expansion. When evaluated on end-to-end tasks, targeted capability tests, researcher studies, and component ablations, the agent lowers manual engineering time while raising executability, consistency, and reproducibility of the resulting pipelines.
What carries the argument
EmbodiedClaw, the conversational agent that maps user dialogue directly into executable workflow skills for environment, data, training, and evaluation steps.
If this is right
- Environment revision and benchmark changes can be performed by stating the desired change rather than editing code by hand.
- Trajectory collection and model evaluation become reproducible across different researchers because the steps are generated from the same dialogue record.
- The overall development loop for multi-model, multi-scene projects shortens because each stage is executed by the same automated pipeline.
- Human studies show researchers complete the same workflow with measurably less time spent on implementation details.
Where Pith is reading between the lines
- The same conversational-execution pattern could be reused for non-embodied AI pipelines that also involve repetitive data and evaluation steps.
- Standardized skill libraries built this way might allow different research groups to share and compose workflows without exchanging custom scripts.
- If planning errors decrease with more examples, the system could eventually handle novel combinations of environments and models with little extra training.
Load-bearing premise
The conversational agent can interpret high-level goals and constraints accurately enough to plan and run complex embodied workflows without needing frequent human fixes.
What would settle it
A head-to-head trial on a multi-step task such as benchmark transformation in which the number of human interventions or final error rate is higher with EmbodiedClaw than with standard manual scripting.
Figures






read the original abstract
Embodied AI research is increasingly moving beyond single-task, single-environment policy learning toward multi-task, multi-scene, and multi-model settings. This shift substantially increases the engineering overhead and development time required for stages such as evaluation environment construction, trajectory collection, model training, and evaluation. To address this challenge, we propose a new paradigm for embodied AI development in which users express goals and constraints through conversation, and the system automatically plans and executes the development workflow. We instantiate this paradigm with EmbodiedClaw, a conversational agent that turns high-frequency, high-cost embodied research activities, including environment creation and revision, benchmark transformation, trajectory synthesis, model evaluation, and asset expansion, into executable skills. Experiments on end-to-end workflow tasks, capability-specific evaluations, human researcher studies, and ablations show that EmbodiedClaw reduces manual engineering effort while improving executability, consistency, and reproducibility. These results suggest a shift from manual toolchains to conversationally executable workflows for embodied AI development.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes EmbodiedClaw, a conversational agent that allows users to express high-level goals and constraints for embodied AI development tasks (environment creation/revision, benchmark transformation, trajectory synthesis, model evaluation, asset expansion) and automatically plans and executes the corresponding workflows. It reports results from end-to-end workflow tasks, capability-specific evaluations, human researcher studies, and ablations, claiming that the system reduces manual engineering effort while improving executability, consistency, and reproducibility compared to traditional manual toolchains.
Significance. If the experimental claims hold with proper quantification, the work could meaningfully lower the engineering barrier for multi-task, multi-environment embodied AI research by shifting from manual scripting to conversational workflow execution. This addresses a genuine practical bottleneck in the field and, if validated, would represent a useful systems contribution for accelerating development cycles.
major comments (2)
- [Experiments] Experiments section (end-to-end workflow tasks and human studies): The central claim that EmbodiedClaw reduces manual engineering effort and improves executability requires evidence that the agent can handle error-prone steps (environment revision, benchmark transformation, trajectory synthesis) with minimal human correction. The reported results do not quantify intervention frequency, failure recovery rates, or effort reduction against an explicit manual baseline, so the asserted improvements in executability and reduced overhead do not yet follow from the presented data.
- [Human studies and ablations] Human researcher studies and ablations: These evaluations are described as showing positive outcomes, but without reported metrics (e.g., task completion time, number of corrections per workflow, inter-rater reliability, or ablation-specific deltas with error bars), it is impossible to assess whether the conversational interface delivers reliable autonomy or merely shifts effort to prompt engineering.
minor comments (1)
- [Abstract] Abstract: The summary of experimental outcomes asserts improvements without any high-level metrics, baselines, or sample sizes; adding one sentence summarizing key quantitative findings would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the potential significance of EmbodiedClaw in addressing engineering bottlenecks in embodied AI research. We address each major comment below and have revised the manuscript to incorporate the requested quantifications and metrics.
read point-by-point responses
-
Referee: [Experiments] Experiments section (end-to-end workflow tasks and human studies): The central claim that EmbodiedClaw reduces manual engineering effort and improves executability requires evidence that the agent can handle error-prone steps (environment revision, benchmark transformation, trajectory synthesis) with minimal human correction. The reported results do not quantify intervention frequency, failure recovery rates, or effort reduction against an explicit manual baseline, so the asserted improvements in executability and reduced overhead do not yet follow from the presented data.
Authors: We agree that explicit quantification of intervention frequency, failure recovery, and effort reduction against a manual baseline would strengthen the central claims. In the revised manuscript, we have expanded the end-to-end workflow tasks subsection to report the average number of human interventions per task for error-prone steps, autonomous failure recovery rates, and a direct comparison of total researcher effort (in hours) using EmbodiedClaw versus a traditional manual toolchain on identical tasks performed by the same participants. These additions provide the missing evidence that the system handles such steps with minimal correction and reduces overhead. revision: yes
-
Referee: [Human studies and ablations] Human researcher studies and ablations: These evaluations are described as showing positive outcomes, but without reported metrics (e.g., task completion time, number of corrections per workflow, inter-rater reliability, or ablation-specific deltas with error bars), it is impossible to assess whether the conversational interface delivers reliable autonomy or merely shifts effort to prompt engineering.
Authors: We acknowledge that the original presentation lacked the specific metrics needed for rigorous assessment. We have revised the Human Researcher Studies and Ablations sections to include average task completion times, number of corrections per workflow, inter-rater reliability coefficients for the qualitative evaluations, and ablation results reported as mean deltas with standard error bars. The updated metrics demonstrate reliable autonomy from the conversational interface, with performance gains not attributable solely to prompt engineering. revision: yes
Circularity Check
No circularity; empirical claims rest on direct experiments without self-referential definitions or fitted predictions
full rationale
The paper introduces EmbodiedClaw as an instantiation of a conversational workflow paradigm for embodied AI tasks and evaluates it via end-to-end experiments, capability-specific tests, human studies, and ablations. No mathematical derivation chain, equations, or parameters exist in the provided text. Claims of reduced engineering effort and improved executability are presented as outcomes of the implemented system and measured results rather than reductions by construction to inputs or self-citations. This is a systems paper whose central assertions are externally falsifiable through the described experiments and do not rely on self-definitional loops or imported uniqueness theorems.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Conversational interfaces can effectively capture high-level research goals and constraints and translate them into executable embodied AI workflows.
invented entities (1)
-
EmbodiedClaw
no independent evidence
Reference graph
Works this paper leans on
-
[2]
Aligning cyber space with physical world: A comprehensive survey on embodied AI,
Minghua Liu et al. Aligning cyber space with physical world: A comprehensive survey on embodied AI. arXiv preprint arXiv:2407.06886, 2023
-
[3]
Multi-agent embodied ai: Advances and future directions.arXiv preprint arXiv:2505.05108,
Zhaocan Feng et al. Multi-agent embodied AI: Advances and future directions.arXiv preprint arXiv:2505.05108, 2025
-
[4]
arXiv preprint arXiv:2508.13073 (2025)
Rui Shao, Wei Li, Lingsen Zhang, Renshan Zhang, Zhiyang Liu, Ran Chen, and Liqiang Nie. Large vlm- based vision-language-action models for robotic manipulation: A survey.arXiv preprint arXiv:2508.13073, 2025
-
[5]
Embodied intelligence: A synergy of morphology, action, perception and learning.ACM Computing Surveys, 57(7):1–36, 2025
Huaping Liu, Di Guo, and Angelo Cangelosi. Embodied intelligence: A synergy of morphology, action, perception and learning.ACM Computing Surveys, 57(7):1–36, 2025
2025
-
[6]
Machine learning meets advanced robotic manipulation.Information Fusion, 105:102221, 2024
Saeid Nahavandi, Roohallah Alizadehsani, Darius Nahavandi, Chee Peng Lim, Kevin Kelly, and Fernando Bello. Machine learning meets advanced robotic manipulation.Information Fusion, 105:102221, 2024
2024
-
[7]
Foundation models defining a new era in vision: a survey and outlook.IEEE Transactions on Pattern Analysis and Machine Intelligence, 47(4): 2245–2264, 2025
Muhammad Awais, Muzammal Naseer, Salman Khan, Rao Muhammad Anwer, Hisham Cholakkal, Mubarak Shah, Ming-Hsuan Yang, and Fahad Shahbaz Khan. Foundation models defining a new era in vision: a survey and outlook.IEEE Transactions on Pattern Analysis and Machine Intelligence, 47(4): 2245–2264, 2025
2025
-
[8]
Fuyu Ma et al. Orchestrating embodied systems through the embodied context protocol: Motivation, progress, and directions.Research, 2025. doi: 10.34133/research.1047
-
[9]
Robotwin: Dual-arm robot benchmark with generative digital twins
Yao Mu, Tianxing Chen, Zanxin Chen, Shijia Peng, Zhiqian Lan, Zeyu Gao, Zhixuan Liang, Qiaojun Yu, Yude Zou, Mingkun Xu, et al. Robotwin: Dual-arm robot benchmark with generative digital twins. In Proceedings of the computer vision and pattern recognition conference, pages 27649–27660, 2025
2025
-
[10]
Pu Hua, Minghuan Liu, Annabella Macaluso, Yunfeng Lin, Weinan Zhang, Huazhe Xu, and Lirui Wang. Gensim2: Scaling robot data generation with multi-modal and reasoning llms.arXiv preprint arXiv:2410.03645, 2024
-
[11]
Yufei Wang, Zhou Xian, Feng Chen, Tsun-Hsuan Wang, Yian Wang, Katerina Fragkiadaki, Zackory Erickson, David Held, and Chuang Gan. RoboGen: Towards unleashing infinite data for automated robot learning via generative simulation.arXiv preprint arXiv:2311.01455, 2023
-
[12]
AI2-THOR: An Interactive 3D Environment for Visual AI
Eric Kolve, Roozbeh Mottaghi, Winson Han, Eli VanderBilt, Luca Weihs, Alvaro Herrasti, Daniel Gordon, Yuke Zhu, Abhinav Gupta, and Ali Farhadi. AI2-THOR: An interactive 3D environment for visual AI. arXiv preprint arXiv:1712.05474, 2017
work page internal anchor Pith review arXiv 2017
-
[13]
Habitat: A platform for embodied AI research
Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, Devi Parikh, and Dhruv Batra. Habitat: A platform for embodied AI research. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 9339–9347, 2019
2019
-
[14]
Habitat 2.0: Training home assistants to rearrange their habitat
Andrew Szot, Alexander Clegg, Eric Undersander, Erik Wijmans, Yili Zhao, John Turner, Noah Maestre, Mustafa Mukadam, Devendra Singh Chaplot, Oleksandr Maksymets, Aaron Gokaslan, Vladimír V ondruš, Sameer Dharur, Franziska Meier, Wojciech Galuba, Angel X Chang, Zsolt Kira, Vladlen Koltun, Jitendra Malik, Manolis Savva, and Dhruv Batra. Habitat 2.0: Trainin...
2021
-
[15]
SAPIEN: A simulated part-based interactive environment
Fanbo Xiang, Yuzhe Qin, Kaichun Mo, Yikuan Xia, Hao Zhu, Fangchen Liu, Minghua Liu, Hanxiao Jiang, Yifu Yuan, He Wang, Li Yi, Angel X Chang, Leonidas J Guibas, and Hao Su. SAPIEN: A simulated part-based interactive environment. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11097–11107, 2020
2020
-
[16]
Isaac gym: High performance GPU-based physics simulation for robot learning
Viktor Makoviychuk, Leszek Wawrzyniak, Yunrong Guo, Michelle Lu, Kier Storey, Miles Macklin, David Hoeller, Nikita Rudin, Arthur Allshire, Ankur Handa, and Gavriel State. Isaac gym: High performance GPU-based physics simulation for robot learning. InAdvances in Neural Information Processing Systems (NeurIPS), Datasets & Benchmarks Track, 2021
2021
-
[17]
robosuite: A Modular Simulation Framework and Benchmark for Robot Learning
Yuke Zhu, Josiah Wong, Ajay Mandlekar, and Roberto Martín-Martín. robosuite: A modular simulation framework and benchmark for robot learning.arXiv preprint arXiv:2009.12293, 2020. 11
work page internal anchor Pith review arXiv 2009
-
[18]
Stone Tao, Fanbo Xiang, Arth Shukla, Yuzhe Qin, Xander Hinrichsen, Xiaodi Yuan, Chen Bao, Xinsong Lin, Yulin Liu, Tse-kai Chan, et al. ManiSkill3: GPU parallelized robotics simulation and rendering for generalizable embodied AI.arXiv preprint arXiv:2410.00425, 2024
-
[19]
ProcTHOR: Large-scale embodied AI using procedural generation
Matt Deitke, Eli VanderBilt, Alvaro Herrasti, Luca Weihs, Kiana Ehsani, Jordi Salvador, Winson Han, Eric Kolve, Aniruddha Kembhavi, and Roozbeh Mottaghi. ProcTHOR: Large-scale embodied AI using procedural generation. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[20]
Holodeck: Language guided generation of 3D embodied AI environments
Yue Yang, Fan-Yun Sun, Luca Weihs, Eli VanderBilt, Alvaro Herrasti, Winson Han, Jiajun Wu, Nick Haber, Ranjay Krishna, Lingjie Liu, Chris Callison-Burch, Mark Yatskar, Aniruddha Kembhavi, and Christopher Clark. Holodeck: Language guided generation of 3D embodied AI environments. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog...
2024
-
[21]
iGibson 2.0: Object-centric simulation for robot learning of everyday household tasks
Chengshu Li, Fei Xia, Roberto Martín-Martín, Michael Lingelbach, Sanjana Srivastava, Bhuvan Bhargava, Kim Leong, Feiran An, Carl Romero, Shyamal Shivkumar, et al. iGibson 2.0: Object-centric simulation for robot learning of everyday household tasks. InConference on Robot Learning (CoRL), 2022
2022
-
[22]
Bear, Dan Gutfreund, David Cox, Antonio Torralba, James J
Chuang Gan, Jeremy Schwartz, Seth Alter, Martin Schrimpf, James Traer, Julian De Freitas, Jonas Kubilius, Abhishek Bhandwaldar, Nick Haber, Megumi Sano, et al. ThreeDWorld: A platform for interactive multi- modal physical simulation.arXiv preprint arXiv:2007.04954, 2020
-
[23]
RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots
Soroush Nasiriany, Abhiram Maddukuri, Lance Zhang, Adeet Parakh, Andrew Lo, Abhishek Joshi, Ajay Mandlekar, and Yuke Zhu. RoboCasa: Large-scale simulation of everyday tasks for generalist robots. arXiv preprint arXiv:2406.02523, 2024
work page internal anchor Pith review arXiv 2024
-
[24]
Imitating task and motion planning with visuomotor transformers
Murtaza Dalal, Ajay Mandlekar, Caelan Garrett, Ankur Handa, Ruslan Salakhutdinov, and Dieter Fox. Imitating task and motion planning with visuomotor transformers.arXiv preprint arXiv:2305.16309, 2023
-
[25]
Mimicgen: A data generation system for scalable robot learning using human demonstrations
Ajay Mandlekar, Soroush Nasiriany, Bowen Wen, Iretiayo Akinola, Yashraj Narang, Linxi Fan, Yuke Zhu, and Dieter Fox. Mimicgen: A data generation system for scalable robot learning using human demonstrations.arXiv preprint arXiv:2310.17596, 2023
-
[26]
Jiayuan Gu, Fanbo Xiang, Xuanlin Li, Zhan Ling, Xiqiang Liu, Tongzhou Mu, Yihe Tang, Stone Tao, Xinyue Wei, Yunchao Yao, et al. Maniskill2: A unified benchmark for generalizable manipulation skills. arXiv preprint arXiv:2302.04659, 2023
-
[27]
Rlbench: The robot learning benchmark & learning environment.IEEE Robotics and Automation Letters, 5(2):3019–3026, 2020
Stephen James, Zicong Ma, David Rovick Arrojo, and Andrew J Davison. Rlbench: The robot learning benchmark & learning environment.IEEE Robotics and Automation Letters, 5(2):3019–3026, 2020
2020
-
[28]
Behavior-1k: A benchmark for embodied ai with 1,000 everyday activities and realistic simulation
Chengshu Li, Ruohan Zhang, Josiah Wong, Cem Gokmen, Sanjana Srivastava, Roberto Martín-Martín, Chen Wang, Gabrael Levine, Michael Lingelbach, Jiankai Sun, et al. Behavior-1k: A benchmark for embodied ai with 1,000 everyday activities and realistic simulation. InConference on Robot Learning, pages 80–93. PMLR, 2023
2023
-
[29]
Claude Code
Anthropic. Claude Code. https://claude.com/product/claude-code, 2026. Accessed: 2026-04- 01
2026
-
[30]
OpenAI Codex
OpenAI. OpenAI Codex. https://openai.com/index/openai-codex/, 2026. Accessed: 2026-04- 01
2026
-
[31]
Gemini CLI.https://geminicli.com/, 2026
Google. Gemini CLI.https://geminicli.com/, 2026. Accessed: 2026-04-01
2026
-
[32]
OpenClaw — personal AI assistant
OpenClaw Community. OpenClaw — personal AI assistant. https://openclaw.ai, 2026. Accessed: 2026-04-01
2026
-
[33]
Language models as zero-shot planners: Extracting actionable knowledge for embodied agents
Wenlong Huang, Pieter Abbeel, Deepak Pathak, and Igor Mordatch. Language models as zero-shot planners: Extracting actionable knowledge for embodied agents. 2022
2022
-
[34]
Code as policies: Language model programs for embodied control
Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, and Andy Zeng. Code as policies: Language model programs for embodied control. 2023
2023
-
[35]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. VOYAGER: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Danny Driess, Fei Xia, Mehdi S. M. Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, et al. PaLM-E: An embodied multimodal language model. 2023. 12
2023
-
[37]
RT-2: Vision-language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. RT-2: Vision-language-action models transfer web knowledge to robotic control. 2023
2023
-
[38]
Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
Bo Liu et al. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
2023
-
[39]
Evaluating Real-World Robot Manipulation Policies in Simulation
Xuanlin Li et al. Evaluating real-world robot manipulation policies in simulation.arXiv preprint arXiv:2405.05941, 2024
work page internal anchor Pith review arXiv 2024
-
[40]
VirtualHome: Simulating household activities via programs
Xavier Puig, Kevin Ra, Marko Boben, Jiaman Li, Tingwu Wang, Sanja Fidler, and Antonio Torralba. VirtualHome: Simulating household activities via programs. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8494–8502, 2018
2018
-
[41]
Foundation models in robotics: Applications, challenges, and the future.The International Journal of Robotics Research, 44(5):701–739, 2025
Roya Firoozi, Johnathan Tucker, Stephen Tian, Anirudha Majumdar, Jiankai Sun, Weiyu Liu, Yuke Zhu, Shuran Song, Ashish Kapoor, Karol Hausman, et al. Foundation models in robotics: Applications, challenges, and the future.The International Journal of Robotics Research, 44(5):701–739, 2025
2025
-
[42]
Kun Zhang, Peng Yun, Jun Cen, Junhao Cai, Didi Zhu, Hangjie Yuan, Chao Zhao, Tao Feng, Michael Yu Wang, Qifeng Chen, et al. Generative artificial intelligence in robotic manipulation: A survey.arXiv preprint arXiv:2503.03464, 2025
-
[43]
Sage: Scalable agentic 3d scene generation for embodied ai, 2026
Hongchi Xia, Xuan Li, Zhaoshuo Li, Qianli Ma, Jiashu Xu, Ming-Yu Liu, Yin Cui, Tsung-Yi Lin, Wei-Chiu Ma, Shenlong Wang, Shuran Song, and Fangyin Wei. SAGE: Scalable agentic 3D scene generation for embodied AI.arXiv preprint arXiv:2602.10116, 2026
-
[44]
EmbodiedGen: Towards a generative 3D world engine for embodied intelligence, 2025
Xinjie Wang, Liu Liu, Yu Cao, Ruiqi Wu, Wenkang Qin, Dehui Wang, Wei Sui, and Zhizhong Su. EmbodiedGen: Towards a generative 3D world engine for embodied intelligence, 2025
2025
-
[45]
MuJoCo: A physics engine for model-based control
Emanuel Todorov, Tom Erez, and Yuval Tassa. MuJoCo: A physics engine for model-based control. In 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 5026–5033. IEEE, 2012
2012
-
[46]
M 2Diffuser: Diffusion-based trajectory optimization for mobile manipulation in 3D scenes.arXiv preprint, 2024
Zhou Xian et al. M 2Diffuser: Diffusion-based trajectory optimization for mobile manipulation in 3D scenes.arXiv preprint, 2024. Available athttps://m2diffuser.github.io
2024
-
[47]
arXiv preprint arXiv:2505.02836 (2025)
Lu Ling et al. Scenethesis: A language and vision agentic framework for 3D scene generation.arXiv preprint arXiv:2505.02836, 2025
-
[48]
Shifang Zhao et al. Cutclaw: Agentic hours-long video editing via music synchronization.arXiv preprint arXiv:2603.29664, 2026
-
[49]
Autogen: Enabling next-gen llm applications via multi-agent conversations
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Shaoshuai Li, Erkang Zhu, Li Jiang, Xiaohan Zhang, Chi Liu, Ahmed Hassan Awadallah, Jianfeng Wang, et al. Autogen: Enabling next-gen llm applications via multi-agent conversations. InFirst Conference on Language Modeling, 2024
2024
-
[50]
arXiv preprint arXiv:2404.11584 , year=
Tula Masterman, Sandi Besen, Mason Sawtell, and Alex Chao. The landscape of emerging ai agent architectures for reasoning, planning, and tool calling: A survey.arXiv preprint arXiv:2404.11584, 2024
-
[51]
A survey of ai agent protocols.arXiv preprint arXiv:2504.16736,
Yingxuan Yang, Huacan Chai, Yuanyi Song, Siyuan Qi, Muning Wen, Ning Li, Junwei Liao, Haoyi Hu, Jianghao Lin, Gaowei Chang, et al. A survey of ai agent protocols.arXiv preprint arXiv:2504.16736, 2025. 13
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.