Recognition: unknown
Towards Personalizing Secure Programming Education with LLM-Injected Vulnerabilities
Pith reviewed 2026-05-10 12:58 UTC · model grok-4.3
The pith
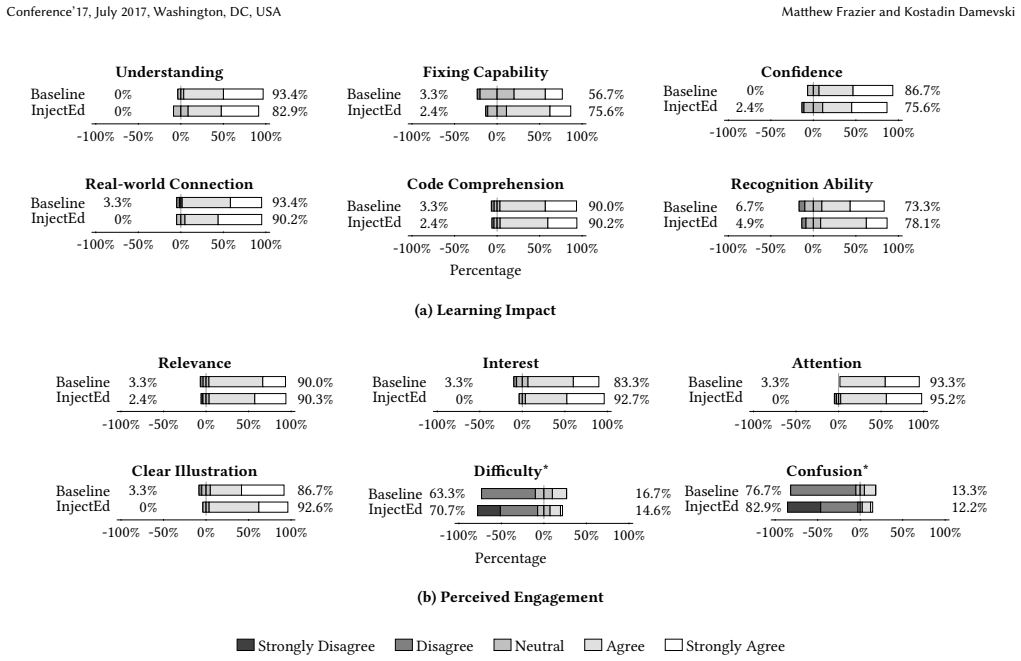
Using large language models to inject security vulnerabilities into students' own code produces examples that students rate as more relevant and engaging than standard textbook materials.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is the development and deployment of an agentic framework where LLM agents inject Common Weakness Enumerations into student code, evaluate the results, and generate learning materials. In classroom use, this led to students reporting greater relevance, clarity, and engagement with the personalized samples compared to baseline generic materials.
What carries the argument
Agentic AI framework using autonomous LLM-based agents with tools for orchestrating vulnerability injection, evaluation, ranking, and outcome generation.
Load-bearing premise
That the vulnerabilities added by the language model behave like genuine flaws students would encounter, without any unnatural features affecting learning or perception.
What would settle it
Running a study where one group uses the LLM-personalized code examples and another uses generic ones, then testing both groups on their ability to spot and fix security problems in new code to see if the personalized group performs better.
Figures

read the original abstract
According to constructivist theory, students learn software security more effectively when examples are grounded in their own code. Generic examples often fail to connect with students' prior work, limiting engagement and understanding. Advances in LLMs are now making it possible to automatically generate personalized examples by embedding security vulnerabilities directly into student-authored code. This paper introduces a method that uses LLMs to inject instances of specific Common Weakness Enumerations (CWEs) into students' own assignment code, creating individualized instructional materials. We present an agentic AI framework, using autonomous LLM-based agents equipped with task-specific tools to orchestrate injection, evaluation, ranking, and learning outcome generation. We report the experience of deploying this system in two undergraduate computer science courses (N=71), where students reviewed code samples containing LLM-injected vulnerabilities and completed a post-project survey. We compared responses with a baseline using a widely adopted set of generic security instructional materials. Students qualitatively reported finding CWE injections into their own code more relevant, clearer, and more engaging than the textbook-style examples. However, our quantitative findings revealed limited statistically significant differences, suggesting that while students valued the personalization, further studies and refinement of the approach are needed to establish stronger empirical support.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces an agentic LLM-based framework to automatically inject specific Common Weakness Enumerations (CWEs) into student-authored code, generating personalized security vulnerability examples grounded in constructivist learning theory. The system was deployed in two undergraduate computer science courses (N=71 students total), where participants reviewed the LLM-injected samples and completed post-project surveys comparing them to a baseline of generic textbook-style security materials. Qualitative survey responses indicated that students found the personalized injections more relevant, clearer, and engaging than generic examples, while quantitative analysis revealed only limited statistically significant differences, leading the authors to recommend further studies and refinements.
Significance. If the injected vulnerabilities can be validated as realistic without systematic artifacts, the approach offers a promising way to improve engagement in secure programming education by connecting examples directly to students' own code. The real-world deployment across two courses and direct comparison to an established baseline constitute a practical strength, providing initial evidence of student preference for personalization. However, the current evidence rests primarily on self-reported perceptions rather than objective measures of learning gains, which tempers the immediate impact on the field.
major comments (2)
- [Abstract and Evaluation] The central qualitative claim (students found CWE injections into their own code more relevant, clearer, and engaging) is load-bearing for the paper's contribution, yet the manuscript provides no description of post-injection validation steps such as expert review for realism, checks for compilability, or comparison of injected flaws to naturally occurring CWEs in student code. Without this, the reported preferences could reflect novelty or artificial clarity rather than authentic educational value, directly undermining the constructivist grounding asserted in the abstract.
- [Abstract] The abstract states that learning outcomes were assessed via post-project opinion surveys and that quantitative differences were limited, but provides no details on how outcomes were operationalized (e.g., exact survey items, response scales, statistical tests, or effect sizes). This absence weakens the ability to interpret the 'limited statistically significant differences' finding and the call for further studies.
minor comments (2)
- [Method] The description of the agentic framework (orchestrating injection, evaluation, ranking, and learning outcome generation) would benefit from a high-level diagram or pseudocode to clarify the tool-using agent interactions and decision points.
- [Evaluation] The baseline comparison to 'a widely adopted set of generic security instructional materials' should specify the exact source or textbook to allow readers to assess equivalence.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which highlights important areas for strengthening the description of our evaluation. We agree that greater transparency on validation procedures and survey operationalization will improve the manuscript and address the concerns about interpreting the qualitative and quantitative results. We respond to each major comment below and commit to revisions that incorporate these points without overstating our current evidence.
read point-by-point responses
-
Referee: [Abstract and Evaluation] The central qualitative claim (students found CWE injections into their own code more relevant, clearer, and engaging) is load-bearing for the paper's contribution, yet the manuscript provides no description of post-injection validation steps such as expert review for realism, checks for compilability, or comparison of injected flaws to naturally occurring CWEs in student code. Without this, the reported preferences could reflect novelty or artificial clarity rather than authentic educational value, directly undermining the constructivist grounding asserted in the abstract.
Authors: We acknowledge that the manuscript does not currently include a dedicated description of post-injection validation. The agentic framework incorporates automated evaluation steps for compilability and basic syntactic validity via the LLM agents' tool use, but we did not perform external expert review by security specialists or a systematic comparison of injected CWEs against naturally occurring vulnerabilities in the student code. This is a genuine limitation that could influence how the qualitative preferences are interpreted. We will revise the Evaluation section to add an explicit subsection on validation procedures, detailing the automated checks performed, noting the absence of expert review and natural-CWE benchmarking as limitations, and discussing implications for the constructivist claims. This will provide readers with a clearer basis for assessing the educational value of the injections. revision: yes
-
Referee: [Abstract] The abstract states that learning outcomes were assessed via post-project opinion surveys and that quantitative differences were limited, but provides no details on how outcomes were operationalized (e.g., exact survey items, response scales, statistical tests, or effect sizes). This absence weakens the ability to interpret the 'limited statistically significant differences' finding and the call for further studies.
Authors: We agree that the abstract is insufficiently specific on methodology. The full manuscript (Section 4.2 and Appendix) describes the post-project survey using 5-point Likert scales for relevance, clarity, and engagement; reports non-parametric tests (Mann-Whitney U) for between-condition comparisons; and includes effect-size calculations. To improve accessibility, we will revise the abstract to briefly note the survey scales, statistical approach, and the limited significant differences observed, while retaining the call for further studies. We will also ensure effect sizes are more prominently reported in the results if not already highlighted. revision: yes
Circularity Check
No circularity: empirical deployment with external baseline
full rationale
The paper describes an agentic LLM framework for injecting CWEs into student code and reports results from a deployment in two courses (N=71) with post-project surveys compared to generic textbook materials. No equations, derivations, fitted parameters, or predictions exist that could reduce to inputs by construction. Claims rest on qualitative student feedback and limited quantitative comparisons against an independent external baseline, with no self-citation chains or self-definitional steps load-bearing on the results. This is a standard empirical study without circular elements in its methodology or evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Constructivist theory holds that students learn software security more effectively when examples are grounded in their own code.
Reference graph
Works this paper leans on
-
[1]
2001.A taxonomy for learning, teaching, and assessing: A revision of Bloom’s taxonomy of educational objectives: complete edition
Lorin W Anderson and David R Krathwohl. 2001.A taxonomy for learning, teaching, and assessing: A revision of Bloom’s taxonomy of educational objectives: complete edition. Addison Wesley Longman, Inc
2001
-
[2]
2022.Teaching for quality learning at university 5e
John Biggs, Catherine Tang, and Gregor Kennedy. 2022.Teaching for quality learning at university 5e. McGraw-hill education (UK)
2022
-
[3]
Matt Bishop. 2011. Teaching security stealthily.IEEE Security & Privacy9, 2 (2011), 69–71
2011
-
[4]
Simon Buckingham Shum and Ruth Deakin Crick. 2012. Learning dispositions and transferable competencies: pedagogy, modelling and learning analytics. In Proceedings of the 2nd international conference on learning analytics and knowledge. 92–101
2012
-
[5]
Diana I Cordova and Mark R Lepper. 1996. Intrinsic motivation and the process of learning: Beneficial effects of contextualization, personalization, and choice. Journal of educational psychology88, 4 (1996), 715
1996
-
[6]
CrewAI Inc. 2025. CrewAI: Framework for orchestrating role-playing, au- tonomous AI agents. by fostering collaborative intelligence, crewai empow- ers agents to work together seamlessly, tackling complex tasks. https: //github.com/crewAIInc/crewAI
2025
- [7]
-
[8]
Wenliang Du. 2011. SEED: hands-on lab exercises for computer security education. IEEE Security & Privacy9, 5 (2011), 70–73
2011
-
[9]
2014.Eight myths of student disengagement: Creating class- rooms of deep learning
Jennifer A Fredricks. 2014.Eight myths of student disengagement: Creating class- rooms of deep learning. Corwin Press
2014
-
[10]
Barr, Zhendong Su, Mark Gabel, and Premkumar Devanbu
Abram Hindle, Earl T. Barr, Zhendong Su, Mark Gabel, and Premkumar Devanbu
-
[11]
In2012 34th International Conference on Software Engineering (ICSE)
On the naturalness of software. In2012 34th International Conference on Software Engineering (ICSE). 837–847. https://doi.org/10.1109/ICSE.2012.6227135
-
[12]
Sirui Hong, Xiawu Zheng, Jonathan Chen, Yuheng Cheng, et al. 2023. Metagpt: Meta programming for multi-agent collaborative framework.arXiv preprint arXiv:2308.003523, 4 (2023), 6
work page internal anchor Pith review arXiv 2023
-
[13]
Shotaro Ishihara, Hiromu Takahashi, and Hono Shirai. 2022. Semantic shift stability: Efficient way to detect performance degradation of word embeddings and pre-trained language models. InProceedings of the 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Lang...
2022
-
[14]
Dave S Kerby. 2014. The simple difference formula: An approach to teaching nonparametric correlation.Comprehensive Psychology3 (2014), 11–IT
2014
-
[15]
Jessica Lam, Elias Fang, Majed Almansoori, Rahul Chatterjee, and Adalbert Ger- ald Soosai Raj. 2022. Identifying Gaps in the Secure Programming Knowledge and Skills of Students. InProceedings of the 53rd ACM Technical Symposium on Computer Science Education V. 1. 703–709
2022
-
[16]
Langfuse GmbH / Finto Technologies Inc. 2025. Langfuse: Open source LLM engi- neering platform: Traces, evals, prompt management, metrics, and playground to debug and improve your LLM application. https://github.com/langfuse/langfuse
2025
-
[17]
Kamil Malinka, Anton Firc, Pavel Loutock`y, Jakub Vostoupal, Andrej Kristofík, and Frantisek Kasl. 2024. Using Real-world Bug Bounty Programs in Secure Coding Course: Experience Report. InProceedings of the 2024 on Innovation and Technology in Computer Science Education V. 1. 227–233
2024
-
[18]
Vincent Nestler, Tony Coulson, and James D Ashley. 2019. The NICE challenge project: providing workforce experience before the workforce.IEEE Security & Privacy17, 2 (2019), 73–78
2019
-
[19]
Yu Nong, Yuzhe Ou, Michael Pradel, Feng Chen, and Haipeng Cai. 2022. Gen- erating realistic vulnerabilities via neural code editing: an empirical study. In Proceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering(Singapore, Singapore) (ESEC/FSE 2022). Association for Computing Mach...
-
[20]
Yu Nong, Yuzhe Ou, Michael Pradel, Feng Chen, and Haipeng Cai. 2023. VULGEN: Realistic Vulnerability Generation Via Pattern Mining and Deep Learning. In 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). 2527–2539. https://doi.org/10.1109/ICSE48619.2023.00211
- [21]
-
[22]
Stacy J Priniski, Cameron A Hecht, and Judith M Harackiewicz. 2018. Making learning personally meaningful: A new framework for relevance research.The Journal of Experimental Education86, 1 (2018), 11–29
2018
-
[23]
Sagar Raina, Siddharth Kaza, and Blair Taylor. 2014. Segmented and interactive modules for teaching secure coding: A pilot study. InE-Learning, E-Education, and Online Training: First International Conference, eLEOT 2014, Bethesda, MD, USA, September 18-20, 2014, Revised Selected Papers 1. Springer, 147–154
2014
-
[24]
Miia Rannikmäe, Jack Holbrook, and Regina Soobard. 1970. Social constructivism- jerome bruner. https://link.springer.com/chapter/10.1007/978-3-030-43620-9_18
-
[25]
Ambareen Siraj, Nigamanth Sridhar, John A Drew Hamilton Jr, Latifur Khan, Siddharth Kaza, Maanak Gupta, and Sudip Mittal. 2021. Is there a Security Mindset and Can it be Taught?. InProceedings of the Eleventh ACM Conference on Data and Application Security and Privacy. 335–336
2021
-
[26]
arXiv preprint arXiv:2402.02172 , year=
Xunzhu Tang, Kisub Kim, Yewei Song, Cedric Lothritz, Bei Li, Saad Ezzini, Haoye Tian, Jacques Klein, and Tegawende F. Bissyande. 2024. CodeAgent: Autonomous Communicative Agents for Code Review. arXiv:2402.02172 [cs.SE] https://arxiv. org/abs/2402.02172
-
[27]
Blair Taylor and Siddharth Kaza. 2016. Security injections@Towson: Integrating secure coding into introductory computer science courses.ACM Transactions on Computing Education (TOCE)16, 4 (2016), 1–20
2016
-
[28]
The MITRE Corporation. 2025. Common Weakness Enumeration: A community- developedlist fo SW & HW weakness that can become vulnerabilities. https: //cwe.mitre.org/ Retrieved on June 1, 2025
2025
- [29]
-
[30]
Shao-Fang Wen and Basel Katt. 2019. Learning Software Security in Context: An Evaluation in Open Source Software Development Environment. InProceedings of the 14th International Conference on A vailability, Reliability and Security(Can- terbury, CA, United Kingdom)(ARES ’19). Association for Computing Machinery, New York, NY, USA, Article 58, 10 pages. ht...
-
[31]
Michael Whitney, Heather Richter Lipford, Bill Chu, and Tyler Thomas. 2018. Embedding secure coding instruction into the ide: Complementing early and intermediate cs courses with eside.Journal of Educational Computing Research 56, 3 (2018), 415–438
2018
-
[32]
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Shaokun Zhang, Erkang Zhu, Beibin Li, Li Jiang, Xiaoyun Zhang, and Chi Wang. 2023. AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation Framework. https: //doi.org/10.48550/arXiv.2308.08155
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.08155 2023
-
[33]
Tolga Yilmaz and Özgür Ulusoy. 2022. Understanding security vulnerabilities in student code: A case study in a non-security course.Journal of Systems and Software185 (2022), 111150
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.