Recognition: unknown
Momentum Further Constrains Sharpness at the Edge of Stochastic Stability
Pith reviewed 2026-05-10 13:09 UTC · model grok-4.3
The pith
SGD with momentum stabilizes batch sharpness at two different plateaus depending on batch size near the stochastic stability edge.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SGD with momentum exhibits an Edge of Stochastic Stability regime in which batch sharpness, the expected directional mini-batch curvature, converges to one of two batch-size-dependent plateaus. At small batch sizes it reaches the lower plateau 2(1-β)/η, which reflects momentum amplification of stochastic fluctuations and favors flatter solutions than vanilla SGD. At large batch sizes it reaches the higher plateau 2(1+β)/η, where momentum recovers its classical stabilizing effect and favors sharper solutions consistent with deterministic gradient flow. These two limits align with linear stability thresholds and cannot be captured by any single momentum-adjusted threshold.
What carries the argument
Batch sharpness, defined as expected directional mini-batch curvature, and its convergence to the two momentum-dependent plateaus 2(1-β)/η and 2(1+β)/η at the instability boundary.
If this is right
- Momentum favors flatter regions than vanilla SGD when batch size is small because it amplifies stochastic fluctuations.
- Momentum favors sharper regions consistent with full-batch dynamics when batch size is large.
- Hyperparameter tuning for momentum must treat small-batch and large-batch regimes separately rather than using one stability threshold.
- The observed sharpness plateaus match the predictions of linear stability analysis applied to the momentum update.
- The coupling of momentum and batch size directly shapes which solutions the optimizer selects.
Where Pith is reading between the lines
- The split regimes may explain why practitioners often pair momentum with small batches to improve generalization.
- The same two-regime structure could appear in other momentum-based methods such as Nesterov or Adam and would be testable by measuring batch sharpness across batch sizes.
- Adjusting the momentum coefficient as a function of batch size might allow explicit control over the sharpness of the final solution.
- Large-batch training with momentum may require different learning-rate scaling rules than small-batch training because the effective stability threshold changes.
Load-bearing premise
Finite simulations of training reach the same asymptotic sharpness plateaus that linear stability analysis predicts near the instability boundary.
What would settle it
A long training run at several batch sizes in which measured batch sharpness fails to approach either 2(1-β)/η or 2(1+β)/η as training time increases.
Figures

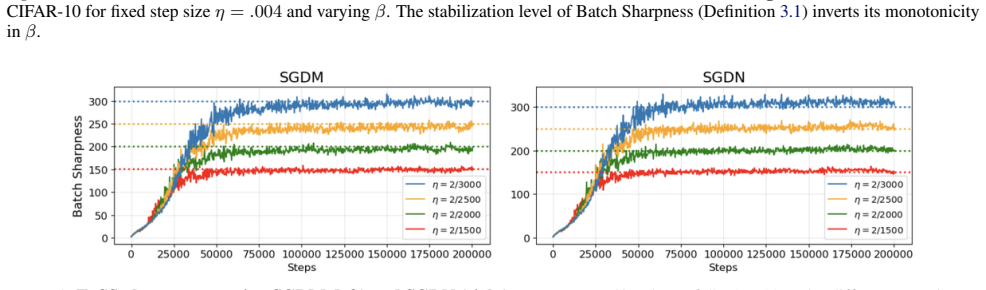

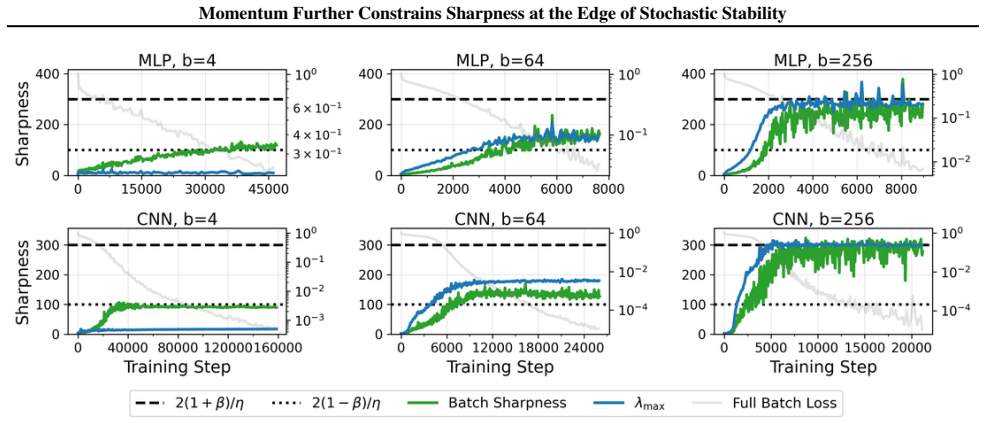








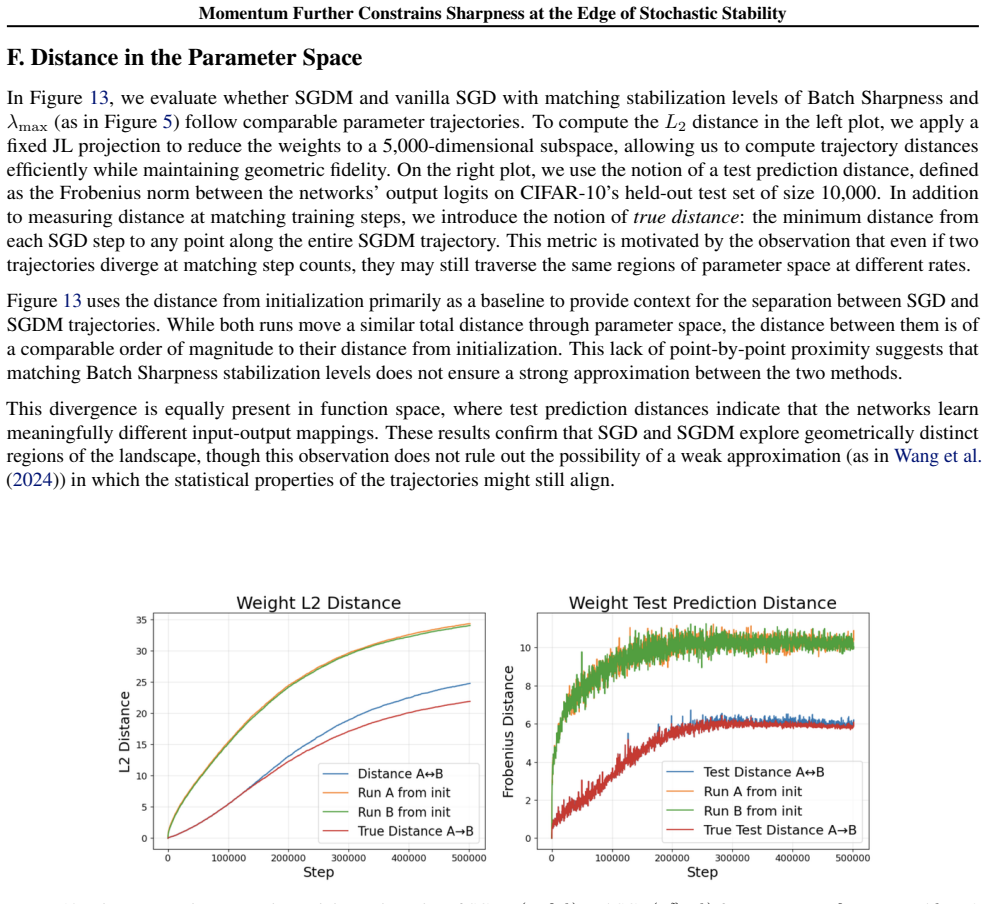






read the original abstract
Recent work suggests that (stochastic) gradient descent self-organizes near an instability boundary, shaping both optimization and the solutions found. Momentum and mini-batch gradients are widely used in practical deep learning optimization, but it remains unclear whether they operate in a comparable regime of instability. We demonstrate that SGD with momentum exhibits an Edge of Stochastic Stability (EoSS)-like regime with batch-size-dependent behavior that cannot be explained by a single momentum-adjusted stability threshold. Batch Sharpness (the expected directional mini-batch curvature) stabilizes in two distinct regimes: at small batch sizes it converges to a lower plateau $2(1-\beta)/\eta$, reflecting amplification of stochastic fluctuations by momentum and favoring flatter regions than vanilla SGD; at large batch sizes it converges to a higher plateau $2(1+\beta)/\eta$, where momentum recovers its classical stabilizing effect and favors sharper regions consistent with full-batch dynamics. We further show that this aligns with linear stability thresholds and discuss the implications for hyperparameter tuning and coupling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that SGD with momentum exhibits an Edge of Stochastic Stability (EoSS)-like regime in which batch sharpness (expected directional mini-batch curvature) converges to two distinct, batch-size-dependent plateaus: a lower value of 2(1-β)/η at small batch sizes (reflecting momentum-amplified stochastic fluctuations) and a higher value of 2(1+β)/η at large batch sizes (recovering classical momentum stabilization). This regime separation cannot be captured by any single momentum-adjusted stability threshold and is shown to align with linear stability analysis, with implications for hyperparameter tuning and optimization dynamics.
Significance. If the empirical plateaus and their alignment with linear thresholds hold, the work supplies explicit, testable formulas that refine the EoSS picture for momentum and mini-batching, clarifying why momentum favors flatter regions under small-batch stochasticity while recovering sharper solutions under large-batch or full-batch conditions. The parameter-free expressions in terms of β and η constitute a concrete prediction that could guide practical tuning and connect optimization dynamics to generalization.
major comments (2)
- [Abstract] Abstract and the linear-stability derivation: the central claim that linear stability thresholds directly dictate the observed nonlinear batch-sharpness plateaus is load-bearing, yet the manuscript provides no explicit argument or perturbation analysis showing that higher-order curvature terms or transient nonlinear effects do not shift the effective thresholds away from 2(1-β)/η and 2(1+β)/η.
- [Empirical section] Simulation results (finite-time convergence): the reported stabilization to the two plateaus rests on the assumption that finite-length runs accurately reflect infinite-time asymptotic behavior near the instability boundary; without reported training horizons relative to the stability time scale, convergence diagnostics, or error bars on the sharpness estimator, transient effects could produce apparent regime separation.
minor comments (2)
- [Abstract] The symbols β (momentum) and η (learning rate) are used in the plateau formulas without an early, self-contained definition; a brief reminder in the abstract or introduction would improve readability.
- [Abstract] The phrase 'batch-size-dependent behavior' is repeated; a single consolidated statement of the two regimes would reduce redundancy.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. Below we provide point-by-point responses to the major comments, indicating where revisions will be made to address the concerns.
read point-by-point responses
-
Referee: [Abstract] Abstract and the linear-stability derivation: the central claim that linear stability thresholds directly dictate the observed nonlinear batch-sharpness plateaus is load-bearing, yet the manuscript provides no explicit argument or perturbation analysis showing that higher-order curvature terms or transient nonlinear effects do not shift the effective thresholds away from 2(1-β)/η and 2(1+β)/η.
Authors: While the linear stability analysis provides the thresholds that match our empirical observations, we acknowledge the absence of an explicit perturbation argument in the manuscript. In the revision, we will add a paragraph in the theory section arguing that, consistent with the EoSS framework, the system self-organizes such that nonlinear effects are suppressed near the boundary, preserving the linear thresholds as the effective plateaus. This is supported by the close agreement in our simulations. We will also cite related literature on linear approximations in stochastic optimization. revision: partial
-
Referee: [Empirical section] Simulation results (finite-time convergence): the reported stabilization to the two plateaus rests on the assumption that finite-length runs accurately reflect infinite-time asymptotic behavior near the instability boundary; without reported training horizons relative to the stability time scale, convergence diagnostics, or error bars on the sharpness estimator, transient effects could produce apparent regime separation.
Authors: We agree that additional details on convergence would strengthen the empirical claims. The manuscript reports results after 10^5 training steps, which exceeds the characteristic time scales derived from the linear analysis (approximately 1/|log(stability factor)|). In the revised version, we will include plots showing the evolution of batch sharpness over time to demonstrate convergence, report standard errors from 5 independent runs, and add a discussion comparing the simulation length to the stability time scale. revision: yes
Circularity Check
No significant circularity; stability thresholds derived independently from linear analysis
full rationale
The paper performs linear stability analysis on the momentum SGD update rule to obtain the two batch-size-dependent thresholds 2(1-β)/η and 2(1+β)/η. These are presented as the analytically expected plateaus to which batch sharpness converges. Simulations are then used to verify that observed sharpness approaches these values, which is a non-circular empirical check rather than a re-statement of fitted inputs or self-definitions. No load-bearing self-citations, ansatz smuggling, or renaming of known results are required for the central claim. The derivation chain remains self-contained against the linear dynamics of the optimizer.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Linear stability analysis of the momentum-augmented gradient update governs the long-term behavior of batch sharpness near the instability boundary.
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
Agarwala, A. and Pennington, J. High dimensional analysis reveals conservative sharpening and a stochastic edge of stability. arXiv preprint arXiv:2404.19261, 2024
-
[3]
Understanding the unstable convergence of gradient descent
Ahn, K., Zhang, J., and Sra, S. Understanding the unstable convergence of gradient descent. In Proceedings of the 39th International Conference on Machine Learning , June 2022. URL https://proceedings.mlr.press/v162/ahn22a.html
2022
-
[4]
Andreyev, A. and Beneventano, P. Edge of Stochastic Stability : Revisiting the Edge of Stability for SGD . December 2024. doi:10.48550/arXiv.2412.20553. URL http://arxiv.org/abs/2412.20553. arXiv:2412.20553
-
[5]
and Bruna, J
Chen, L. and Bruna, J. Beyond the edge of stability via two-step gradient updates. In Krause, A., Brunskill, E., Cho, K., Engelhardt, B., Sabato, S., and Scarlett, J. (eds.), Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pp.\ 4330--4391. PMLR, 23--29 Jul 2023. URL https://proc...
2023
-
[6]
arXiv preprint arXiv:2103.00065 , year=
Cohen, J. M., Kaur, S., Li, Y., Kolter, J. Z., and Talwalkar, A. Gradient Descent on Neural Networks Typically Occurs at the Edge of Stability . arXiv:2103.00065 [cs, stat], June 2021. URL http://arxiv.org/abs/2103.00065. arXiv:2103.00065
-
[7]
Cohen, J. M., Ghorbani, B., Krishnan, S., Agarwal, N., Medapati, S., Badura, M., Suo, D., Cardoze, D., Nado, Z., Dahl, G. E., and Gilmer, J. Adaptive Gradient Methods at the Edge of Stability , July 2022. URL http://arxiv.org/abs/2207.14484. arXiv:2207.14484 [cs]
-
[8]
M., Damian, A., Talwalkar, A., Kolter, Z., and Lee, J
Cohen, J. M., Damian, A., Talwalkar, A., Kolter, Z., and Lee, J. D. Understanding Optimization in Deep Learning with Central Flows , October 2024. URL http://arxiv.org/abs/2410.24206. arXiv:2410.24206
-
[9]
and Orabona, F
Cutkosky, A. and Orabona, F. Momentum-based variance reduction in non-convex SGD . In Advances in Neural Information Processing Systems (NeurIPS), 2019
2019
- [10]
-
[11]
When and why momentum accelerates SGD : An empirical study, 2023
Fu, J., Wang, B., Zhang, H., Zhang, Z., Chen, W., and Zheng, N. When and why momentum accelerates SGD : An empirical study, 2023. URL https://arxiv.org/abs/2306.09000
-
[12]
arXiv preprint arXiv:2302.00849 , year=
Ghosh, A., Lyu, H., Zhang, X., and Wang, R. Implicit regularization in heavy-ball momentum accelerated stochastic gradient descent. In International Conference on Learning Representations (ICLR), 2023. URL https://arxiv.org/abs/2302.00849
-
[13]
Understanding the role of momentum in stochastic gradient methods
Gitman, I., Lang, H., Zhang, P., and Xiao, L. Understanding the role of momentum in stochastic gradient methods. In Advances in Neural Information Processing Systems (NeurIPS), 2019. URL https://arxiv.org/abs/1910.13962
-
[14]
Granziol, D., Zohren, S., and Roberts, S. Learning rates as a function of batch size: A random matrix theory approach to neural network training, 2021. URL https://arxiv.org/abs/2006.09092
-
[15]
Deep Residual Learning for Image Recognition
He, K., Zhang, X., Ren, S., and Sun, J. Deep Residual Learning for Image Recognition . arXiv:1512.03385 [cs], December 2015. URL http://arxiv.org/abs/1512.03385. arXiv:1512.03385
work page internal anchor Pith review arXiv 2015
-
[16]
On the Relation Between the Sharpest Directions of DNN Loss and the SGD Step Length , Year =
Jastrz e bski, S., Kenton, Z., Ballas, N., Fischer, A., Bengio, Y., and Storkey, A. On the Relation Between the Sharpest Directions of DNN Loss and the SGD Step Length , December 2019. URL http://arxiv.org/abs/1807.05031. arXiv:1807.05031 [stat]
-
[17]
Jastrz e bski, S., Szymczak, M., Fort, S., Arpit, D., Tabor, J., Cho, K., and Geras, K. The Break - Even Point on Optimization Trajectories of Deep Neural Networks . arXiv:2002.09572 [cs, stat], February 2020. URL http://arxiv.org/abs/2002.09572. arXiv:2002.09572
- [18]
-
[19]
Muon: An optimizer for hidden layers in neural networks, dec 2024
Jordan, K. Muon: An optimizer for hidden layers in neural networks, dec 2024. URL https://kellerjordan.github.io/posts/muon/. Blog post
2024
- [20]
-
[21]
Krizhevsky, A., Sutskever, I., and Hinton, G. E. ImageNet Classification with Deep Convolutional Neural Networks . In Advances in Neural Information Processing Systems , volume 25. Curran Associates, Inc., 2012. URL https://papers.nips.cc/paper/2012/hash/c399862d3b9d6b76c8436e924a68c45b-Abstract.html
2012
-
[22]
and Jang, C
Lee, S. and Jang, C. A new characterization of the edge of stability based on a sharpness measure aware of batch gradient distribution. In International Conference on Learning Representations, 2023. URL https://api.semanticscholar.org/CorpusID:259298833
2023
-
[23]
Dynamics of stochastic gradient algorithms, 2015
Li, Q., Tai, C., and E, W. Dynamics of stochastic gradient algorithms, 2015. URL https://arxiv.org/abs/1511.06251
-
[24]
Stochastic modified equations and adaptive stochastic gradient algorithms
Li, Q., Tai, C., and E, W. Stochastic modified equations and adaptive stochastic gradient algorithms. In Proceedings of the 34th International Conference on Machine Learning (ICML), 2017. URL https://arxiv.org/abs/1612.06277
-
[25]
Stochastic modified equations I : Mathematical foundations
Li, Q., Tai, C., and E, W. Stochastic modified equations I : Mathematical foundations. Journal of Machine Learning Research, 2019. URL https://www.jmlr.org/papers/v20/17-526.html
2019
-
[26]
A diffusion approximation theory of momentum SGD in nonconvex optimization, 2018
Liu, T., Chen, Z., Zhou, E., and Zhao, T. A diffusion approximation theory of momentum SGD in nonconvex optimization, 2018. URL https://arxiv.org/abs/1802.05155
-
[27]
An improved analysis of stochastic gradient descent with momentum
Liu, Y., Gao, Y., and Yin, W. An improved analysis of stochastic gradient descent with momentum. In Advances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[28]
Effects of momentum in implicit bias of gradient flow for diagonal linear networks
Lyu, B. Effects of momentum in implicit bias of gradient flow for diagonal linear networks. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2025. URL https://ojs.aaai.org/index.php/AAAI/article/view/34118
2025
-
[29]
and Ying, L
Ma, C. and Ying, L. On linear stability of SGD and input-smoothness of neural networks. In Beygelzimer, A., Dauphin, Y., Liang, P., and Vaughan, J. W. (eds.), Advances in Neural Information Processing Systems, 2021. URL https://openreview.net/forum?id=yAvCV6NwWQ
2021
-
[30]
Ma, J. and Yarats, D. Quasi-hyperbolic momentum and adam for deep learning, 2018. URL https://arxiv.org/abs/1810.06801
-
[31]
D., and Blei, D
Mandt, S., Hoffman, M. D., and Blei, D. M. Stochastic gradient descent as approximate Bayesian inference. Journal of Machine Learning Research, 18 0 (134): 0 1--35, 2017. URL https://www.jmlr.org/papers/v18/16-511.html
2017
-
[32]
Masters, D. and Luschi, C. Revisiting Small Batch Training for Deep Neural Networks , April 2018. URL http://arxiv.org/abs/1804.07612. arXiv:1804.07612
-
[33]
Asynchrony begets momentum, with an application to deep learning, 2016
Mitliagkas, I., Zhang, C., Hadjis, S., and R \'e , C. Asynchrony begets momentum, with an application to deep learning, 2016. URL https://arxiv.org/abs/1605.09774
-
[34]
Mulayoff, R. and Michaeli, T. Exact mean square linear stability analysis for sgd, 2024. URL https://arxiv.org/abs/2306.07850
-
[35]
On an approach to the construction of optimal methods of minimization of smooth convex functions
Nesterov, Y. On an approach to the construction of optimal methods of minimization of smooth convex functions. Ekonomika i Mateaticheskie Metody, 24 0 (3): 0 509--517, 1988
1988
-
[36]
Paquette, C. and Paquette, E. Dynamics of stochastic momentum methods on large-scale quadratic models. In Advances in Neural Information Processing Systems (NeurIPS), 2021. URL https://arxiv.org/abs/2104.03485
-
[37]
Some methods of speeding up the convergence of iteration methods
Polyak, B. Some methods of speeding up the convergence of iteration methods. USSR Computational Mathematics and Mathematical Physics , 4 0 (5): 0 1--17, 1964. ISSN 0041-5553. doi:10.1016/0041-5553(64)90137-5. URL https://www.sciencedirect.com/science/article/pii/0041555364901375
-
[38]
On the generalization of stochastic gradient descent with momentum
Ramezani-Kebrya, A., Antonakopoulos, K., Cevher, V., Khisti, A., and Liang, B. On the generalization of stochastic gradient descent with momentum. Journal of Machine Learning Research, 25 0 (22): 0 1--56, 2024. URL https://jmlr.org/papers/v25/22-0068.html
2024
-
[39]
Shi, B., Du, S., Jordan, M. I., and Su, W. Understanding the acceleration phenomenon via high-resolution differential equations. Mathematical Programming, 2022. doi:10.1007/s10107-021-01681-8. URL https://doi.org/10.1007/s10107-021-01681-8
-
[40]
A differential equation for modeling Nesterov 's accelerated gradient method: Theory and insights
Su, W., Boyd, S., and Cand \`e s, E. A differential equation for modeling Nesterov 's accelerated gradient method: Theory and insights. In Advances in Neural Information Processing Systems (NeurIPS), 2014. URL https://arxiv.org/abs/1503.01243
-
[41]
E., and Hinton, G
Sutskever, I., Martens, J., Dahl, G. E., and Hinton, G. E. On the importance of initialization and momentum in deep learning. In Proceedings of the 30th International Conference on Machine Learning (ICML), volume 28 of Proceedings of Machine Learning Research, pp.\ 1139--1147, 2013. URL https://proceedings.mlr.press/v28/sutskever13.html
2013
-
[42]
Does momentum change the implicit regularization on separable data? In Advances in Neural Information Processing Systems (NeurIPS), 2022
Wang, B., Meng, Q., Zhang, H., Sun, R., Chen, W., Ma, Z.-M., and Liu, T.-Y. Does momentum change the implicit regularization on separable data? In Advances in Neural Information Processing Systems (NeurIPS), 2022. URL https://openreview.net/forum?id=i-8uqlurj1f
2022
-
[43]
The marginal value of momentum for small learning rate SGD
Wang, R., Malladi, S., Wang, T., Lyu, K., and Li, Z. The marginal value of momentum for small learning rate SGD . In International Conference on Learning Representations (ICLR), 2024. URL https://arxiv.org/abs/2307.15196
-
[44]
Wibisono, A., Wilson, A. C., and Jordan, M. I. A variational perspective on accelerated methods in optimization, 2016. URL https://arxiv.org/abs/1603.04245
-
[45]
C., Recht, B., and Jordan, M
Wilson, A. C., Recht, B., and Jordan, M. I. A Lyapunov analysis of accelerated methods in optimization. Journal of Machine Learning Research, 2021
2021
- [46]
-
[47]
Wu, L., Ma, C., and E, W. How SGD Selects the Global Minima in Over -parameterized Learning : A Dynamical Stability Perspective . In Advances in Neural Information Processing Systems , volume 31. Curran Associates, Inc., 2018. URL https://proceedings.neurips.cc/paper_files/paper/2018/hash/6651526b6fb8f29a00507de6a49ce30f-Abstract.html
-
[48]
The alignment property of sgd noise and how it helps select flat minima: A stability analysis, 2022
Wu, L., Wang, M., and Su, W. The alignment property of sgd noise and how it helps select flat minima: A stability analysis, 2022
2022
-
[49]
arXiv preprint arXiv:1802.08770 , year =
Xing, C., Arpit, D., Tsirigotis, C., and Bengio, Y. A Walk with SGD , May 2018. URL http://arxiv.org/abs/1802.08770. arXiv:1802.08770 [cs, stat]
- [50]
-
[51]
Zagoruyko, S. and Komodakis, N. Wide Residual Networks . arXiv:1605.07146 [cs], June 2017. URL http://arxiv.org/abs/1605.07146. arXiv:1605.07146
work page internal anchor Pith review arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.