Recognition: unknown
Geometrically Consistent Multi-View Scene Generation from Freehand Sketches
Pith reviewed 2026-05-10 13:20 UTC · model grok-4.3
The pith
A single freehand sketch generates geometrically consistent multi-view scenes in one denoising step.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Our framework synthesizes all views in a single denoising process without requiring reference images, iterative refinement, or per-scene optimization. It addresses absent training data, geometric reasoning from distorted input, and cross-view consistency with a curated dataset of ~9k sketch-to-multiview samples, Parallel Camera-Aware Attention Adapters (CA3) that inject geometric inductive biases into the video transformer, and a Sparse Correspondence Supervision Loss (CSL) derived from Structure-from-Motion reconstructions. The approach significantly outperforms state-of-the-art two-stage baselines.
What carries the argument
Parallel Camera-Aware Attention Adapters (CA3) that inject geometric inductive biases into the video transformer, together with Sparse Correspondence Supervision Loss (CSL) derived from Structure-from-Motion reconstructions.
If this is right
- The method improves realism by over 60% in FID compared with two-stage baselines.
- Geometric consistency rises by 23% in the Corr-Acc metric.
- Inference runs up to 3.7 times faster by avoiding iterative refinement and per-scene optimization.
- All views are produced simultaneously without reference images or extra stages.
Where Pith is reading between the lines
- The single-pass design could be tested for extending to time-consistent video generation from sketch sequences.
- Similar camera-aware adapters might transfer to other low-information inputs such as rough diagrams in architecture or product design.
- If the consistency generalizes, the technique could lower the barrier for casual users to create 3D scene assets without multi-view capture.
Load-bearing premise
The automated generation and filtering pipeline for the ~9k sketch-to-multiview dataset produces data that faithfully represents real freehand sketches and their geometric distortions.
What would settle it
Evaluating the model on an independent collection of real human freehand sketches and measuring whether the generated views achieve the reported Corr-Acc gains or permit accurate SfM reconstructions would settle the geometric-consistency claim.
Figures








read the original abstract
We tackle a new problem: generating geometrically consistent multi-view scenes from a single freehand sketch. Freehand sketches are the most geometrically impoverished input one could offer a multi-view generator. They convey scene intent through abstract strokes while introducing spatial distortions that actively conflict with any consistent 3D interpretation. No prior method attempts this; existing multi-view approaches require photographs or text, while sketch-to-3D methods need multiple views or costly per-scene optimisation. We address three compounding challenges; absent training data, the need for geometric reasoning from distorted 2D input, and cross-view consistency, through three mutually reinforcing contributions: (i) a curated dataset of $\sim$9k sketch-to-multiview samples, constructed via an automated generation and filtering pipeline; (ii) Parallel Camera-Aware Attention Adapters (CA3) that inject geometric inductive biases into the video transformer; and (iii) a Sparse Correspondence Supervision Loss (CSL) derived from Structure-from-Motion reconstructions. Our framework synthesizes all views in a single denoising process without requiring reference images, iterative refinement, or per-scene optimization. Our approach significantly outperforms state-of-the-art two-stage baselines, improving realism (FID) by over 60% and geometric consistency (Corr-Acc) by 23%, while providing up to a 3.7$\times$ inference speedup.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a method for synthesizing geometrically consistent multi-view scenes from a single freehand sketch. Key contributions include a new dataset of ~9k sketch-to-multiview pairs generated via an automated pipeline, Parallel Camera-Aware Attention Adapters (CA3) to inject geometric biases into a video transformer, and a Sparse Correspondence Supervision Loss (CSL) based on SfM reconstructions. The framework performs all views in a single denoising process and claims substantial improvements over two-stage baselines: >60% better FID, 23% better Corr-Acc, and up to 3.7× faster inference.
Significance. If the central assumptions hold, particularly regarding the dataset's representation of real freehand distortions, this paper would make a notable contribution to the field of sketch-based multi-view generation by enabling efficient, consistent synthesis without iterative optimization or reference images. The emphasis on handling geometric distortions through inductive biases and supervision is valuable for practical applications in design and visualization.
major comments (2)
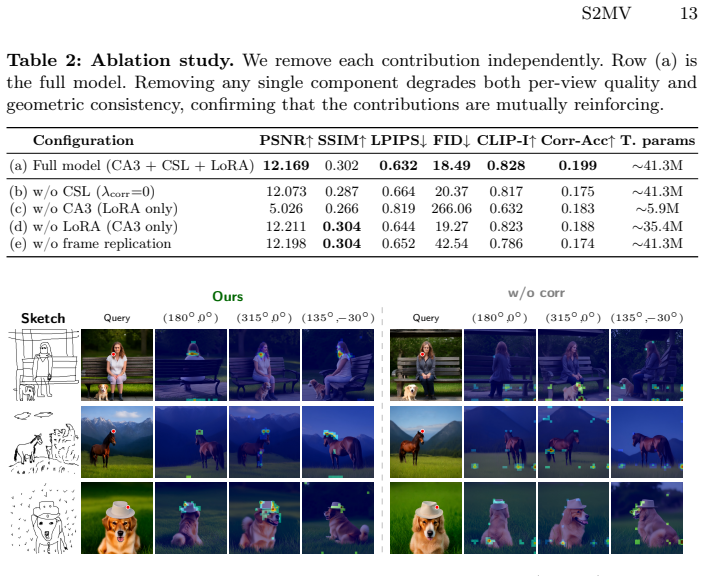
- The construction of the ~9k dataset via automated generation and filtering is load-bearing for the claims of handling 'geometrically impoverished' freehand sketches. The manuscript should include quantitative or qualitative analysis demonstrating that the pipeline's outputs exhibit the irregular distortions and conflicting perspective cues characteristic of actual human freehand drawings, rather than more consistent geometry from 3D model renders. Without this, the reported gains in geometric consistency (Corr-Acc) may not translate to real-world freehand inputs.
- The quantitative results reported in the abstract lack supporting details such as error bars, standard deviations, or ablation studies on the individual contributions of the CA3 adapters and CSL loss. Additionally, there is no discussion of potential biases in the automated dataset pipeline or verification that the training data matches the distribution of real freehand sketches, which is critical for validating the single-denoising process's effectiveness.
minor comments (1)
- The abstract could more explicitly name the state-of-the-art two-stage baselines being compared against to provide better context for the performance claims.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and will incorporate revisions to strengthen the presentation of our dataset validation and experimental analysis.
read point-by-point responses
-
Referee: The construction of the ~9k dataset via automated generation and filtering is load-bearing for the claims of handling 'geometrically impoverished' freehand sketches. The manuscript should include quantitative or qualitative analysis demonstrating that the pipeline's outputs exhibit the irregular distortions and conflicting perspective cues characteristic of actual human freehand drawings, rather than more consistent geometry from 3D model renders. Without this, the reported gains in geometric consistency (Corr-Acc) may not translate to real-world freehand inputs.
Authors: We agree that explicit validation of the distortion characteristics is important for supporting our claims. Our automated pipeline applies randomized stroke simplification, perspective jitter, and edge perturbation steps derived from 3D renders to emulate freehand variability; however, the current manuscript does not include a dedicated comparison. In the revision we will add a new subsection with both qualitative side-by-side examples (our generated sketches versus real freehand drawings from public sources) and quantitative metrics such as average stroke curvature variance and multi-view perspective inconsistency scores. This will directly demonstrate the presence of conflicting geometric cues. revision: yes
-
Referee: The quantitative results reported in the abstract lack supporting details such as error bars, standard deviations, or ablation studies on the individual contributions of the CA3 adapters and CSL loss. Additionally, there is no discussion of potential biases in the automated dataset pipeline or verification that the training data matches the distribution of real freehand sketches, which is critical for validating the single-denoising process's effectiveness.
Authors: We acknowledge that the reported metrics would benefit from statistical detail and component-wise analysis. The revised manuscript will include error bars and standard deviations computed over multiple random seeds for all FID and Corr-Acc numbers. We will also expand the experiments with dedicated ablations that isolate the contribution of the Parallel Camera-Aware Attention Adapters and the Sparse Correspondence Supervision Loss. In addition, we will insert a discussion of potential pipeline biases (e.g., residual 3D consistency) together with a distributional comparison (feature histograms and Fréchet distance) between our generated sketches and real freehand sketch collections to confirm that the training distribution adequately covers the target domain. revision: yes
Circularity Check
No circularity; derivation relies on external dataset construction and SfM supervision
full rationale
The paper's central claims rest on a newly introduced ~9k sketch-to-multiview dataset built via an automated external pipeline and a Sparse Correspondence Supervision Loss explicitly derived from independent Structure-from-Motion reconstructions. The CA3 adapters and single-pass denoising architecture are presented as novel inductive biases injected into a video transformer, without any reduction to self-definitions, fitted parameters renamed as predictions, or load-bearing self-citations. Performance metrics (FID, Corr-Acc) are benchmarked against separate two-stage baselines rather than tautologically following from the inputs. No ansatzes, uniqueness theorems, or renamings of known results are invoked in a self-referential manner.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The automated generation and filtering pipeline produces a dataset of ~9k sketch-to-multiview samples that is representative of real freehand sketches.
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Bahmani, S., Skorokhodov, I., Qian, G., Siarohin, A., Menapace, W., Tagliasacchi, A., Lindell, D.B., Tulyakov, S.: Ac3d: Analyzing and improving 3d camera con- trol in video diffusion transformers. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 22875–22889 (2025)
2025
-
[2]
Bai, Y., Fang, S., Yu, C., Wang, F., Huang, Q.: Geovideo: Introducing geometric regularization into video generation model. arXiv preprint arXiv:2512.03453 (2025)
-
[3]
In: International Conference on Learning Representations (2026)
Bourouis, A., Bessmeltsev, M., Gryaditskaya, Y.: Sketchingreality: From freehand scene sketches to photorealistic images. In: International Conference on Learning Representations (2026)
2026
-
[4]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Bourouis, A., Fan, J.E., Gryaditskaya, Y.: Open vocabulary semantic scene sketch understanding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4176–4186 (2024)
2024
-
[5]
openvocabulary scene sketch semantic understanding
Bourouis,A.,Fan,J.E.,Gryaditskaya,Y.:Datausedinthepaper"openvocabulary scene sketch semantic understanding"(fscoco-seg) (2024)
2024
-
[6]
SAM 3: Segment Anything with Concepts
Carion, N., Gustafson, L., Hu, Y.T., Debnath, S., Hu, R., Suris, D., Ryali, C., Alwala,K.V.,Khedr,H.,Huang,A.,etal.:Sam3:Segmentanythingwithconcepts. arXiv preprint arXiv:2511.16719 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
arXiv preprint arXiv:2401.14257 (2024)
Chen, M., Yuan, W., Wang, Y., Sheng, Z., He, Y., Dong, Z., Bo, L., Guo, Y.: Sketch2nerf: multi-view sketch-guided text-to-3d generation. arXiv preprint arXiv:2401.14257 (2024)
-
[8]
V3d: Video diffusion models are effective 3d generators
Chen, Z., Wang, Y., Wang, F., Wang, Z., Liu, H.: V3d: Video diffusion models are effective 3d generators. arXiv preprint arXiv:2403.06738 (2024)
-
[9]
In: European conference on computer vision
Chowdhury, P.N., Sain, A., Bhunia, A.K., Xiang, T., Gryaditskaya, Y., Song, Y.Z.: Fs-coco:Towardsunderstandingoffreehandsketchesofcommonobjectsincontext. In: European conference on computer vision. pp. 253–270. Springer (2022)
2022
-
[10]
Hugging Face model card (2025),https: //huggingface.co/dx8152/Qwen-Edit-2509-Multiple-angles, accessed: 2026- 01-28
dx8152: Qwen-Edit-2509-Multiple-angles. Hugging Face model card (2025),https: //huggingface.co/dx8152/Qwen-Edit-2509-Multiple-angles, accessed: 2026- 01-28
2025
-
[11]
Eitz, M., Hays, J., Alexa, M.: How do humans sketch objects? ACM Transactions on graphics (TOG)31(4), 1–10 (2012)
2012
-
[12]
Cat3d: Create any- thing in 3d with multi-view diffusion models,
Gao, R., Holynski, A., Henzler, P., Brussee, A., Martin-Brualla, R., Srinivasan, P., Barron, J.T., Poole, B.: Cat3d: Create anything in 3d with multi-view diffusion models. arXiv preprint arXiv:2405.10314 (2024)
-
[13]
He, H., Xu, Y., Guo, Y., Wetzstein, G., Dai, B., Li, H., Yang, C.: Cameractrl: En- ablingcameracontrolfortext-to-videogeneration.arXivpreprintarXiv:2404.02101 (2024)
work page internal anchor Pith review arXiv 2024
-
[14]
Advances in neural information processing systems30(2017)
Heusel,M.,Ramsauer,H.,Unterthiner,T.,Nessler,B.,Hochreiter,S.:Ganstrained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems30(2017)
2017
-
[15]
ICLR1(2), 3 (2022)
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. ICLR1(2), 3 (2022)
2022
-
[16]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang, Z., Wen, H., Dong, J., Wang, Y., Li, Y., Chen, X., Cao, Y.P., Liang, D., Qiao, Y., Dai, B., et al.: Epidiff: Enhancing multi-view synthesis via localized epipolar-constrained diffusion. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9784–9794 (2024)
2024
-
[17]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Kant, Y., Siarohin, A., Wu, Z., Vasilkovsky, M., Qian, G., Ren, J., Guler, R.A., Ghanem, B., Tulyakov, S., Gilitschenski, I.: Spad: Spatially aware multi-view dif- fusers. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 10026–10038 (2024) 16 Bourouis et al
2024
-
[18]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Kim, S., Li, K., Deng, X., Shi, Y., Cho, M., Wang, P.: Enhancing 3d fidelity of text-to-3d using cross-view correspondences. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 10649–10658 (2024)
2024
-
[19]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Koley, S., Bhunia, A.K., Sekhri, D., Sain, A., Chowdhury, P.N., Xiang, T., Song, Y.Z.: It’s all about your sketch: Democratising sketch control in diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7204–7214 (2024)
2024
-
[20]
International journal of computer vision123(1), 32–73 (2017)
Krishna, R., Zhu, Y., Groth, O., Johnson, J., Hata, K., Kravitz, J., Chen, S., Kalantidis, Y., Li, L.J., Shamma, D.A., et al.: Visual genome: Connecting language and vision using crowdsourced dense image annotations. International journal of computer vision123(1), 32–73 (2017)
2017
-
[21]
arXiv preprint arXiv:2512.03045 (2025)
Kwon, M., Choi, J., Park, J., Jeon, S., Jang, J., Seo, J., Kwak, M., Kim, J.H., Kim, S.: Cameo: Correspondence-attention alignment for multi-view diffusion models. arXiv preprint arXiv:2512.03045 (2025)
-
[22]
Labs, B.F.: FLUX.2: Frontier Visual Intelligence.https://bfl.ai/blog/flux-2 (2025)
2025
-
[23]
In: European Conference on Computer Vision
Leroy, V., Cabon, Y., Revaud, J.: Grounding image matching in 3d with mast3r. In: European Conference on Computer Vision. pp. 71–91. Springer (2024)
2024
-
[24]
arXiv preprint arXiv:2602.08068 (2026)
Li, C., Yang, Y., Shao, J., Zhou, H., Schwarz, K., Liao, Y.: Rerope: Repurposing rope for relative camera control. arXiv preprint arXiv:2602.08068 (2026)
-
[25]
Advances in Neural Information Processing Systems37, 55975–56000 (2024)
Li, P., Liu, Y., Long, X., Zhang, F., Lin, C., Li, M., Qi, X., Zhang, S., Xue, W., Luo, W., et al.: Era3d: High-resolution multiview diffusion using efficient row-wise attention. Advances in Neural Information Processing Systems37, 55975–56000 (2024)
2024
-
[26]
Cameras as relative positional encoding.arXiv preprint arXiv:2507.10496,
Li, R., Yi, B., Liu, J., Gao, H., Ma, Y., Kanazawa, A.: Cameras as relative posi- tional encoding. arXiv preprint arXiv:2507.10496 (2025)
-
[27]
Flow Matching for Generative Modeling
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[28]
ACM Transactions on Graphics (TOG)43(4), 1–13 (2024)
Liu, F.L., Fu, H., Lai, Y.K., Gao, L.: Sketchdream: Sketch-based text-to-3d gener- ation and editing. ACM Transactions on Graphics (TOG)43(4), 1–13 (2024)
2024
-
[29]
In: Proceedings of the IEEE/CVF inter- national conference on computer vision
Liu, R., Wu, R., Van Hoorick, B., Tokmakov, P., Zakharov, S., Vondrick, C.: Zero- 1-to-3: Zero-shot one image to 3d object. In: Proceedings of the IEEE/CVF inter- national conference on computer vision. pp. 9298–9309 (2023)
2023
-
[30]
In: European conference on computer vision
Liu, S., Zeng, Z., Ren, T., Li, F., Zhang, H., Yang, J., Jiang, Q., Li, C., Yang, J., Su, H., et al.: Grounding dino: Marrying dino with grounded pre-training for open-set object detection. In: European conference on computer vision. pp. 38–55. Springer (2024)
2024
-
[31]
arXiv preprint arXiv:2309.03453 , year=
Liu, Y., Lin, C., Zeng, Z., Long, X., Liu, L., Komura, T., Wang, W.: Syncdreamer: Generating multiview-consistent images from a single-view image. arXiv preprint arXiv:2309.03453 (2023)
-
[32]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Long, X., Guo, Y.C., Lin, C., Liu, Y., Dou, Z., Liu, L., Ma, Y., Zhang, S.H., Habermann, M., Theobalt, C., et al.: Wonder3d: Single image to 3d using cross- domain diffusion. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9970–9980 (2024)
2024
-
[33]
Decoupled Weight Decay Regularization
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[34]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Ma, B., Gao, H., Deng, H., Luo, Z., Huang, T., Tang, L., Wang, X.: You see it, you got it: Learning 3d creation on pose-free videos at scale. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 2016–2029 (2025) S2MV 17
2016
-
[35]
In: Proceedings of the AAAI conference on artificial intelligence
Mou, C., Wang, X., Xie, L., Wu, Y., Zhang, J., Qi, Z., Shan, Y.: T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. In: Proceedings of the AAAI conference on artificial intelligence. vol. 38, pp. 4296–4304 (2024)
2024
-
[36]
arXiv preprint arXiv:2410.01595 (2024)
Navard, P., Monsefi, A.K., Zhou, M., Chao, W.L., Yilmaz, A., Ramnath, R.: Knob- gen: controlling the sophistication of artwork in sketch-based diffusion models. arXiv preprint arXiv:2410.01595 (2024)
-
[37]
Representation Learning with Contrastive Predictive Coding
Oord, A.v.d., Li, Y., Vinyals, O.: Representation learning with contrastive predic- tive coding. arXiv preprint arXiv:1807.03748 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[38]
Accelerating 3d deep learning with pytorch3d.arXiv preprint arXiv:2007.08501, 2020
Ravi,N.,Reizenstein,J.,Novotny,D.,Gordon,T.,Lo,W.Y.,Johnson,J.,Gkioxari, G.: Accelerating 3d deep learning with pytorch3d. arXiv:2007.08501 (2020)
-
[39]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Schonberger, J.L., Frahm, J.M.: Structure-from-motion revisited. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 4104–4113 (2016)
2016
-
[40]
Shi, R., Chen, H., Zhang, Z., Liu, M., Xu, C., Wei, X., Chen, L., Zeng, C., Su, H.: Zero123++: a single image to consistent multi-view diffusion base model. arXiv preprint arXiv:2310.15110 (2023)
-
[41]
arXiv preprint arXiv:2308.16512 , year=
Shi,Y.,Wang,P.,Ye,J.,Long,M.,Li,K.,Yang,X.:Mvdream:Multi-viewdiffusion for 3d generation. arXiv preprint arXiv:2308.16512 (2023)
-
[42]
Advances in Neural Information Processing Systems 36, 1363–1389 (2023)
Tang, L., Jia, M., Wang, Q., Phoo, C.P., Hariharan, B.: Emergent correspon- dence from image diffusion. Advances in Neural Information Processing Systems 36, 1363–1389 (2023)
2023
-
[43]
In: Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers
Tang, M., Vinker, Y., Yan, C., Zhang, L., Agrawala, M.: Instance segmentation of scene sketches using natural image priors. In: Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers. pp. 1–10 (2025)
2025
-
[44]
In: European Conference on Computer Vision
Voleti, V., Yao, C.H., Boss, M., Letts, A., Pankratz, D., Tochilkin, D., Laforte, C., Rombach, R., Jampani, V.: Sv3d: Novel multi-view synthesis and 3d genera- tion from a single image using latent video diffusion. In: European Conference on Computer Vision. pp. 439–457. Springer (2024)
2024
-
[45]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., et al.: Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Wang, H., Spinelli, M., Wang, Q., Bai, X., Qin, Z., Chen, A.: Instantstyle: Free lunch towards style-preserving in text-to-image generation. arXiv preprint arXiv:2404.02733 (2024)
-
[47]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., Novotny, D.: Vggt: Visual geometry grounded transformer. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 5294–5306 (2025)
2025
-
[48]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wang, S., Leroy, V., Cabon, Y., Chidlovskii, B., Revaud, J.: Dust3r: Geometric 3d vision made easy. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 20697–20709 (2024)
2024
-
[49]
IEEE transactions on image processing 13(4), 600–612 (2004)
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing 13(4), 600–612 (2004)
2004
-
[50]
In: ACM SIGGRAPH 2024 Conference Papers
Wang, Z., Yuan, Z., Wang, X., Li, Y., Chen, T., Xia, M., Luo, P., Shan, Y.: Mo- tionctrl: A unified and flexible motion controller for video generation. In: ACM SIGGRAPH 2024 Conference Papers. pp. 1–11 (2024)
2024
-
[51]
Native and compact structured latents for 3d generation.arXiv preprint arXiv:2512.14692, 2025
Xiang, J., Chen, X., Xu, S., Wang, R., Lv, Z., Deng, Y., Zhu, H., Dong, Y., Zhao, H., Yuan, N.J., et al.: Native and compact structured latents for 3d generation. arXiv preprint arXiv:2512.14692 (2025) 18 Bourouis et al
-
[52]
In: European Conference on Computer Vision
Xing,J.,Xia,M.,Zhang,Y.,Chen,H.,Yu,W.,Liu,H.,Liu,G.,Wang,X.,Shan,Y., Wong, T.T.: Dynamicrafter: Animating open-domain images with video diffusion priors. In: European Conference on Computer Vision. pp. 399–417. Springer (2024)
2024
-
[53]
Xu, D., Nie, W., Liu, C., Liu, S., Kautz, J., Wang, Z., Vahdat, A.: Camco: Camera-controllable 3d-consistent image-to-video generation. arXiv preprint arXiv:2406.02509 (2024)
-
[54]
ViewCrafter: Taming Video Diffusion Models for High-fidelity Novel View Synthesis
Yu, W., Xing, J., Yuan, L., Hu, W., Li, X., Huang, Z., Gao, X., Wong, T.T., Shan, Y., Tian, Y.: Viewcrafter: Taming video diffusion models for high-fidelity novel view synthesis. arXiv preprint arXiv:2409.02048 (2024)
work page internal anchor Pith review arXiv 2024
-
[55]
Unified camera positional encoding for controlled video generation.arXiv preprint arXiv:2512.07237,
Zhang, C., Li, B., Wei, M., Cao, Y.P., Gambardella, C.C., Phung, D., Cai, J.: Unified camera positional encoding for controlled video generation. arXiv preprint arXiv:2512.07237 (2025)
-
[56]
In: Proceedings of the IEEE/CVF international conference on computer vision
Zhang, L., Rao, A., Agrawala, M.: Adding conditional control to text-to-image diffusion models. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 3836–3847 (2023)
2023
-
[57]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 586–595 (2018)
2018
-
[58]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Zhang, S., Xu, H., Guo, S., Xie, Z., Bao, H., Xu, W., Zou, C.: Spatialcrafter: Unleashing the imagination of video diffusion models for scene reconstruction from limited observations. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 27794–27805 (2025)
2025
-
[59]
Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
Zhao, Z., Lai, Z., Lin, Q., Zhao, Y., Liu, H., Yang, S., Feng, Y., Yang, M., Zhang, S., Yang, X., et al.: Hunyuan3d 2.0: Scaling diffusion models for high resolution textured 3d assets generation. arXiv preprint arXiv:2501.12202 (2025)
work page Pith review arXiv 2025
-
[60]
Zhou,J.,Gao,H.,Voleti,V.,Vasishta,A.,Yao,C.H.,Boss,M.,Torr,P.,Rupprecht, C., Jampani, V.: Stable virtual camera: Generative view synthesis with diffusion models. arXiv preprint arXiv:2503.14489 (2025) S2MV 19 Supplementary Material This supplementary document provides additional details that complement the main paper. Sec. A presents additional qualitativ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.