Recognition: 2 theorem links
· Lean TheoremOn-Line Policy Iteration with Trajectory-Driven Policy Generation
Pith reviewed 2026-05-12 03:06 UTC · model grok-4.3
The pith
An on-line policy iteration method produces policies with monotonically decreasing costs for a fixed initial state under a consistency condition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under a natural consistency condition on the policy generation process, the sequence of costs of the generated policies is monotonically improving for the given initial state. The method generates each new policy from the trajectory of the previous one, allowing application to repetitive tasks where the same initial state is used multiple times.
What carries the argument
Trajectory-driven policy generation in the on-line policy iteration loop, where the trajectory produced by one policy trains the next policy.
If this is right
- The policy costs decrease monotonically for the initial state with each iteration under the consistency condition.
- The method runs fast enough for on-line use in repetitive tasks.
- It supports training of neural network-based policies while preserving the monotonic improvement.
- The approach applies to both single and multiple decision makers.
- A stochastic counterpart is outlined briefly.
Where Pith is reading between the lines
- The focus on a single initial state suggests the method could be paired with state-space partitioning techniques to handle broader problems.
- Trajectory data as the sole training source implies potential for reduced sample complexity compared to full off-policy learning.
- The brief stochastic discussion leaves open whether similar consistency-based guarantees extend directly to noisy dynamics.
Load-bearing premise
A natural consistency condition must hold for the way each new policy is generated from the previous trajectory.
What would settle it
Demonstrating a sequence of policies where the cost for the initial state increases at some point, even though the consistency condition is satisfied, would falsify the monotonic improvement result.
Figures









read the original abstract
We consider deterministic finite-horizon optimal control problems with a fixed initial state. We introduce an on-line policy iteration method, which, starting from a given policy, however obtained, generates a sequence of cost-improving policies and corresponding trajectories. Each policy produces a trajectory, which is used in turn to generate data for training the next policy. The method is motivated by problems that are repeatedly solved starting from the same initial state, including discrete optimization and path planning for repetitive tasks. For such problems, the method is fast enough to be used on-line. Under a natural consistency condition, we show that the sequence of costs of the generated policies is monotonically improving for the given initial state (but not necessarily for other states). We illustrate our results with computational studies from combinatorial optimization and 3-dimensional path planning for drones {and a robot arm} in the presence of obstacles. We also discuss briefly a stochastic counterpart of our algorithm. Our proposed framework combines elements of rollout and policy iteration with flexible trajectory-based policy representations, and applies to problems involving a single as well as multiple decision makers. It also provides a principled way to train neural network-based policies using trajectory data, while preserving monotonic cost improvement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces an on-line policy iteration algorithm for deterministic finite-horizon optimal control problems with a fixed initial state. Starting from an arbitrary initial policy, each iteration generates a trajectory that is used to train the next policy via a trajectory-driven update. Under a consistency condition on this update, the sequence of policies is shown to produce monotonically decreasing costs for the given initial state (though not necessarily for other states). The method is positioned for repetitive tasks and is illustrated with computational examples from combinatorial optimization and 3D path planning for drones and a robot arm; a stochastic variant is briefly outlined.
Significance. If the central conditional result holds, the work supplies a practical, online mechanism for policy improvement that merges rollout-style trajectory generation with policy iteration while accommodating flexible representations such as neural networks. The monotonicity guarantee, even when restricted to the initial state, is useful for repetitive control and planning tasks. The computational studies provide concrete evidence of applicability to discrete optimization and obstacle-avoidance problems.
major comments (1)
- [§3, Theorem 1] §3, Theorem 1: The monotonicity claim is conditional on the consistency condition; the manuscript should explicitly verify (or prove by construction) that the trajectory-driven training procedure used in the neural-network examples satisfies this condition, as this step is load-bearing for the guarantee.
minor comments (3)
- [Abstract] Abstract: the phrase 'drones {and a robot arm}' contains a LaTeX artifact and should be rendered as 'drones and a robot arm'.
- [§5] §5 (computational studies): the description of the policy training procedure (loss function, number of epochs, initialization) is too brief to allow reproduction; add a short table or paragraph with these details.
- [Throughout] Notation: the symbols for policy, trajectory, and cost are introduced inconsistently across sections; adopt a single, uniform notation from the outset.
Simulated Author's Rebuttal
We thank the referee for the careful reading of our manuscript and the positive recommendation for minor revision. We address the single major comment below and will incorporate the requested clarification in the revised version.
read point-by-point responses
-
Referee: [§3, Theorem 1] §3, Theorem 1: The monotonicity claim is conditional on the consistency condition; the manuscript should explicitly verify (or prove by construction) that the trajectory-driven training procedure used in the neural-network examples satisfies this condition, as this step is load-bearing for the guarantee.
Authors: We agree that the consistency condition is central to the applicability of Theorem 1 and that an explicit verification for the neural-network examples strengthens the presentation. In the revised manuscript we will add a short subsection (or paragraph within Section 4) that proves by construction that the trajectory-driven training procedure satisfies the condition. Specifically, the neural network is trained via supervised regression on the state-action pairs collected along the trajectory generated by the previous policy, with the loss function defined so that the new policy exactly reproduces the actions taken on those states; this directly enforces the required consistency (i.e., the new policy agrees with the data-generating policy on the visited trajectory). The same argument applies verbatim to both the combinatorial-optimization and the 3-D path-planning examples, and we will state it explicitly for each. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents a conditional result: under an explicitly stated natural consistency condition on the trajectory-driven policy generation process, the costs of successive policies improve monotonically for the fixed initial state. This condition is treated as an assumption rather than derived internally or defined in terms of the claimed improvement, and the proof adapts standard dynamic programming arguments to the online setting. No steps reduce by construction to fitted parameters, self-referential definitions, or load-bearing self-citations; the framework remains self-contained once the consistency condition is granted as the weakest assumption.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Natural consistency condition
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
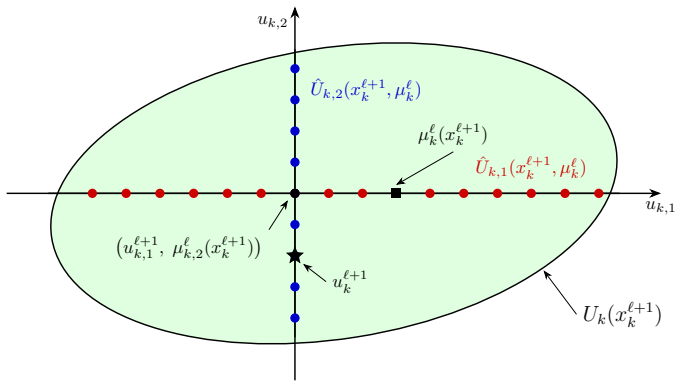
Jπ(x0) = gN(xN) + ∑ gk(xk, μk(xk)) … Under a natural consistency condition, we show that the sequence of costs … is monotonically improving for the given initial state
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the generator is consistent if … μk(xk) = uk … ensures that the improvement of the computed trajectory … is inherited by the generated policy
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
On-line policy iteration for infinite horizon dy- namic programming.arXiv preprint arXiv:2106.00746,
[Ber21b] Dimitri Bertsekas. On-line policy iteration for infinite horizon dy- namic programming.arXiv preprint arXiv:2106.00746,
-
[2]
Adaptive Network Security Policies via Belief Aggregation and Rollout
[HLA+25] Kim Hammar, Yuchao Li, Tansu Alpcan, Emil C. Lupu, and Dimitri Bertsekas. Adaptive network security policies via belief aggregation and rollout.arXiv preprint arXiv:2507.15163,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Johansson, Jonas M˚ artensson, and Dimitri P
[LJMB21] Yuchao Li, Karl H. Johansson, Jonas M˚ artensson, and Dimitri P. Bertsekas. Data-driven rollout for deterministic optimal control. In 2021 60th IEEE Conference on Decision and Control (CDC), pages 2169–2176. IEEE,
work page 2021
-
[4]
31 [MLWB24] Pratyusha Musunuru, Yuchao Li, Jamison Weber, and Dim- itri Bertsekas. An approximate dynamic programming frame- work for occlusion-robust multi-object tracking.arXiv preprint arXiv:2405.15137,
-
[5]
Proximal Policy Optimization Algorithms
[SWD+17] John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.