Recognition: unknown
Route to Rome Attack: Directing LLM Routers to Expensive Models via Adversarial Suffix Optimization
Pith reviewed 2026-05-10 10:54 UTC · model grok-4.3
The pith
Adversarial suffixes optimized on an ensemble surrogate can force black-box LLM routers to select expensive models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
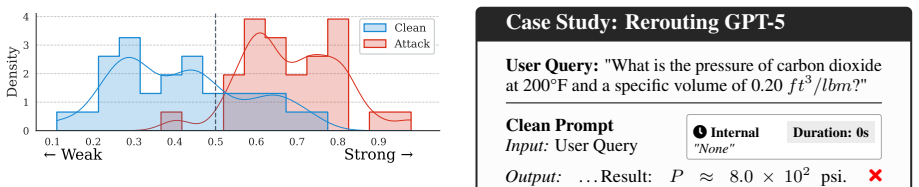
R²A constructs a hybrid ensemble surrogate router from multiple open-source models to replicate the behavior of an inaccessible black-box router, then adapts a suffix optimization algorithm to produce adversarial strings that increase the probability the black-box router dispatches queries to expensive high-capability models.
What carries the argument
The hybrid ensemble surrogate router, built from open-source models, that approximates the black-box router's routing decisions so that suffix optimization can be performed without direct access to the target.
Load-bearing premise
A collection of open-source models can be combined into an ensemble that closely enough reproduces the routing choices of the unknown commercial or black-box router.
What would settle it
Running the generated suffixes on a production router whose decision boundary differs substantially from all models in the surrogate ensemble and observing no measurable rise in expensive-model routing rate.
Figures





read the original abstract
Cost-aware routing dynamically dispatches user queries to models of varying capability to balance performance and inference cost. However, the routing strategy introduces a new security concern that adversaries may manipulate the router to consistently select expensive high-capability models. Existing routing attacks depend on either white-box access or heuristic prompts, rendering them ineffective in real-world black-box scenarios. In this work, we propose R$^2$A, which aims to mislead black-box LLM routers to expensive models via adversarial suffix optimization. Specifically, R$^2$A deploys a hybrid ensemble surrogate router to mimic the black-box router. A suffix optimization algorithm is further adapted for the ensemble-based surrogate. Extensive experiments on multiple open-source and commercial routing systems demonstrate that {R$^2$A} significantly increases the routing rate to expensive models on queries of different distributions. Code and examples: https://github.com/thcxiker/R2A-Attack.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes R²A, an attack on cost-aware LLM routers that constructs a hybrid ensemble surrogate from open-source models, optimizes adversarial suffixes against this surrogate, and claims the resulting suffixes transfer to black-box commercial routers, significantly increasing the rate at which queries are routed to expensive high-capability models across varied query distributions.
Significance. If the transfer results are robustly demonstrated, the work would establish a practical black-box attack vector on production LLM routing systems, highlighting a previously under-explored security risk in cost-optimization infrastructure. The hybrid-surrogate approach is a standard adversarial-ML technique applied here to a new target, but its value depends on verifiable transfer.
major comments (3)
- [Experiments / Method (surrogate construction and transfer evaluation)] The central claim of successful black-box transfer rests on the unverified assumption that the hybrid ensemble surrogate sufficiently approximates the unknown commercial routers. No quantitative surrogate-fidelity metric (e.g., per-router agreement rate on routing decisions over a held-out query set) is reported, nor is there an ablation isolating transfer success from coincidental prompt effects. This directly undermines the ability to attribute observed routing-rate increases to the optimized suffixes rather than query distribution alone.
- [Experiments section] The abstract and results claim 'significantly increases the routing rate' on multiple systems, yet the manuscript provides no baselines, statistical details (confidence intervals, p-values, number of trials), or failure-case analysis. Without these, it is impossible to determine effect size or reproducibility of the reported increases.
- [Method (suffix optimization algorithm)] The suffix-optimization procedure is adapted for the ensemble surrogate, but the paper does not specify how the ensemble loss is aggregated (e.g., majority vote, averaged logits, or routing-probability product) or whether the optimization is performed jointly or sequentially across surrogate members. This detail is load-bearing for reproducibility of the attack.
minor comments (2)
- [Abstract / Introduction] The notation R$^2$A is introduced without an explicit expansion or acronym definition in the abstract or introduction.
- [Experiments] The GitHub link is provided but the manuscript does not state whether the released code includes the exact surrogate configurations, optimization hyperparameters, and evaluation scripts used for the commercial-router experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on surrogate fidelity, statistical rigor, and methodological clarity. We address each major comment below and will revise the manuscript accordingly to improve verifiability and reproducibility.
read point-by-point responses
-
Referee: [Experiments / Method (surrogate construction and transfer evaluation)] The central claim of successful black-box transfer rests on the unverified assumption that the hybrid ensemble surrogate sufficiently approximates the unknown commercial routers. No quantitative surrogate-fidelity metric (e.g., per-router agreement rate on routing decisions over a held-out query set) is reported, nor is there an ablation isolating transfer success from coincidental prompt effects. This directly undermines the ability to attribute observed routing-rate increases to the optimized suffixes rather than query distribution alone.
Authors: We agree that a quantitative surrogate-fidelity metric and ablation would strengthen attribution of the transfer results. In the revised manuscript, we will add per-router agreement rates computed on a held-out query set for each commercial router, along with an ablation study comparing routing rates under original queries, random suffixes, and our optimized suffixes. This will help isolate the contribution of the adversarial suffixes. revision: yes
-
Referee: [Experiments section] The abstract and results claim 'significantly increases the routing rate' on multiple systems, yet the manuscript provides no baselines, statistical details (confidence intervals, p-values, number of trials), or failure-case analysis. Without these, it is impossible to determine effect size or reproducibility of the reported increases.
Authors: We acknowledge that additional statistical details and baselines are necessary for assessing effect size and reproducibility. We will incorporate baseline comparisons (original queries and heuristic prompts), results aggregated over multiple independent trials (with explicit trial counts), 95% confidence intervals, p-values from appropriate statistical tests, and a dedicated failure-case analysis in the revised experiments section. revision: yes
-
Referee: [Method (suffix optimization algorithm)] The suffix-optimization procedure is adapted for the ensemble surrogate, but the paper does not specify how the ensemble loss is aggregated (e.g., majority vote, averaged logits, or routing-probability product) or whether the optimization is performed jointly or sequentially across surrogate members. This detail is load-bearing for reproducibility of the attack.
Authors: We appreciate the call for explicit details on the ensemble procedure. The loss is aggregated by averaging the routing probabilities across surrogate models, and optimization is performed jointly via gradients through the full ensemble. We will expand the Method section with a precise description of the aggregation, joint optimization steps, and pseudocode to ensure full reproducibility. revision: yes
Circularity Check
No circularity: empirical attack construction with independent surrogate and experimental validation
full rationale
The paper describes an empirical attack method (R²A) that builds a hybrid ensemble surrogate from open-source models and optimizes adversarial suffixes against it before testing transfer to black-box routers. No equations, derivations, fitted parameters, or first-principles claims are present that reduce to the inputs by construction. The central result is measured via direct experiments on routing rates across query distributions and router types; the surrogate is constructed independently rather than defined in terms of the target outcome. Self-citations, if any, are not load-bearing for any derivation. This is a standard empirical security paper whose validity rests on experimental evidence rather than tautological reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Hybrid ensemble surrogate router can sufficiently mimic the black-box router for adversarial optimization transfer
Forward citations
Cited by 1 Pith paper
-
Misrouter: Exploiting Routing Mechanisms for Input-Only Attacks on Mixture-of-Experts LLMs
Misrouter enables input-only attacks on MoE LLMs by optimizing queries on open-source surrogates to route toward weakly aligned experts and transferring them to public APIs.
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Pranjal Aggarwal, Aman Madaan, Ankit Anand, Srividya Pranavi Potharaju, Swaroop Mishra, Pei Zhou, Aditya Gupta, Dheeraj Rajagopal, Karthik Kappaganthu, Yiming Yang, Shyam Upadhyay, Manaal Faruqui, and Mausam. 2025. https://arxiv.org/abs/2310.12963 Automix: Automatically mixing language models . Preprint, arXiv:2310.12963
-
[4]
Ge Bai, Jie Liu, Xingyuan Bu, Yancheng He, Jiaheng Liu, Zhanhui Zhou, Zhuoran Lin, Wenbo Su, Tiezheng Ge, Bo Zheng, and Wanli Ouyang. 2024. https://doi.org/10.18653/v1/2024.acl-long.401 MT -bench-101: A fine-grained benchmark for evaluating large language models in multi-turn dialogues . In Proceedings of the 62nd Annual Meeting of the Association for Com...
-
[5]
Xiaofan Bai, Pingyi Hu, Xiaojing Ma, Linchen Yu, Dongmei Zhang, Qi Zhang, and Bin Benjamin Zhu. 2025. https://doi.org/10.18653/v1/2025.findings-acl.546 ESF : Efficient sensitive fingerprinting for black-box tamper detection of large language models . In Findings of the Association for Computational Linguistics: ACL 2025, pages 10477--10494, Vienna, Austri...
-
[6]
Lingjiao Chen, Matei Zaharia, and James Zou. 2024 a . Frugalgpt: How to use large language models while reducing cost and improving performance. Transactions on Machine Learning Research
2024
-
[7]
Shuhao Chen, Weisen Jiang, Baijiong Lin, James Kwok, and Yu Zhang. 2024 b . Routerdc: Query-based router by dual contrastive learning for assembling large language models. Advances in Neural Information Processing Systems, 37:66305--66328
2024
-
[8]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
Enyan Dai and Suhang Wang. 2022. Learning fair graph neural networks with limited and private sensitive attribute information. IEEE Transactions on Knowledge and Data Engineering, 35(7):7103--7117
2022
-
[10]
Dujian Ding, Ankur Mallick, Chi Wang, Robert Sim, Subhabrata Mukherjee, Victor R \" u hle, Laks V. S. Lakshmanan, and Ahmed Hassan Awadallah. 2024. https://openreview.net/forum?id=02f3mUtqnM Hybrid LLM: cost-efficient and quality-aware query routing . In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11...
2024
-
[11]
Yinpeng Dong, Fangzhou Liao, Tianyu Pang, Hang Su, Jun Zhu, Xiaolin Hu, and Jianguo Li. 2018. Boosting adversarial attacks with momentum. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
2018
-
[12]
Tao Feng, Yanzhen Shen, and Jiaxuan You. 2024. Graphrouter: A graph-based router for llm selections. In The Thirteenth International Conference on Learning Representations
2024
- [13]
-
[14]
arXiv preprint arXiv:2502.14855 , year=
Evan Frick, Connor Chen, Joseph Tennyson, Tianle Li, Wei-Lin Chiang, Anastasios N. Angelopoulos, and Ion Stoica. 2025. https://arxiv.org/abs/2502.14855 Prompt-to-leaderboard . Preprint, arXiv:2502.14855
-
[15]
Zirui Guo, Lianghao Xia, Yanhua Yu, Tu Ao, and Chao Huang. 2025. L ight RAG : Simple and fast retrieval-augmented generation. In Findings of the Association for Computational Linguistics: EMNLP 2025
2025
-
[16]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021. Measuring massive multitask language understanding. Proceedings of the International Conference on Learning Representations (ICLR)
2021
-
[17]
Edward J Hu, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. 2022. Lora: Low-rank adaptation of large language models. In International Conference on Learning Representations (ICLR)
2022
-
[18]
Qitian Jason Hu, Jacob Bieker, Xiuyu Li, Nan Jiang, Benjamin Keigwin, Gaurav Ranganath, Kurt Keutzer, and Shriyash Kaustubh Upadhyay. 2024. https://openreview.net/forum?id=IVXmV8Uxwh Routerbench: A benchmark for multi- LLM routing system . In Agentic Markets Workshop at ICML 2024
2024
-
[19]
Choquette-Choo, Daphne Ippolito, Matthew Jagielski, Katherine Lee, Ken Liu, Ion Stoica, Florian Tram \`e r, and Chiyuan Zhang
Yangsibo Huang, Milad Nasr, Anastasios Nikolas Angelopoulos, Nicholas Carlini, Wei-Lin Chiang, Christopher A. Choquette-Choo, Daphne Ippolito, Matthew Jagielski, Katherine Lee, Ken Liu, Ion Stoica, Florian Tram \`e r, and Chiyuan Zhang. 2025 a . https://openreview.net/forum?id=zf9zwCRKyP Exploring and mitigating adversarial manipulation of voting-based le...
2025
-
[20]
Zhongzhan Huang, Guoming Ling, Yupei Lin, Yandong Chen, Shanshan Zhong, Hefeng Wu, and Liang Lin. 2025 b . https://doi.org/10.18653/v1/2025.findings-emnlp.208 R outer E val: A comprehensive benchmark for routing LLM s to explore model-level scaling up in LLM s . In Findings of the Association for Computational Linguistics: EMNLP 2025, pages 3860--3887, Su...
-
[21]
Dongfu Jiang, Xiang Ren, and Bill Yuchen Lin. 2023. Llm-blender: Ensembling large language models with pairwise comparison and generative fusion. In Proceedings of the 61th Annual Meeting of the Association for Computational Linguistics (ACL 2023)
2023
-
[22]
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361
work page internal anchor Pith review Pith/arXiv arXiv 2020
- [23]
-
[24]
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large language models are zero-shot reasoners. Advances in neural information processing systems (NeurIPS)
2022
-
[25]
Chenao Li, Shuo Yan, and Enyan Dai. 2025 a . https://openreview.net/forum?id=5cgm5dV5hr Unizyme: A unified protein cleavage site predictor enhanced with enzyme active-site knowledge . In Advances in Neural Information Processing Systems (NeurIPS)
2025
-
[26]
Gonzalez, and Ion Stoica
Tianle Li, Wei-Lin Chiang, Evan Frick, Lisa Dunlap, Tianhao Wu, Banghua Zhu, Joseph E. Gonzalez, and Ion Stoica. 2025 b . https://openreview.net/forum?id=KfTf9vFvSn From crowdsourced data to high-quality benchmarks: Arena-hard and benchbuilder pipeline . In Forty-second International Conference on Machine Learning
2025
-
[27]
Minhua Lin, Enyan Dai, Junjie Xu, Jinyuan Jia, Xiang Zhang, and Suhang Wang. 2025 a . Stealing training graphs from graph neural networks. In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 1, pages 777--788
2025
- [28]
-
[29]
Yanpei Liu, Xinyun Chen, Chang Liu, and Dawn Song. 2017. Delving into transferable adversarial examples and black-box attacks. In International Conference on Learning Representations (ICLR)
2017
-
[30]
Keming Lu, Hongyi Yuan, Runji Lin, Junyang Lin, Zheng Yuan, Chang Zhou, and Jingren Zhou. 2024. https://doi.org/10.18653/v1/2024.naacl-long.109 Routing to the expert: Efficient reward-guided ensemble of large language models . In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Langua...
- [31]
-
[32]
Hope McGovern, Rickard Stureborg, Yoshi Suhara, and Dimitris Alikaniotis. 2025. https://aclanthology.org/2025.genaidetect-1.6/ Your large language models are leaving fingerprints . In Proceedings of the 1stWorkshop on GenAI Content Detection (GenAIDetect), pages 85--95, Abu Dhabi, UAE. International Conference on Computational Linguistics
2025
-
[33]
Gonzalez, M Waleed Kadous, and Ion Stoica
Isaac Ong, Amjad Almahairi, Vincent Wu, Wei-Lin Chiang, Tianhao Wu, Joseph E. Gonzalez, M Waleed Kadous, and Ion Stoica. 2025. https://openreview.net/forum?id=8sSqNntaMr Route LLM : Learning to route LLM s from preference data . In The Thirteenth International Conference on Learning Representations
2025
-
[34]
Alexander Robey, Eric Wong, Hamed Hassani, and George J. Pappas. 2025. https://openreview.net/forum?id=laPAh2hRFC Smoothllm: Defending large language models against jailbreaking attacks . Trans. Mach. Learn. Res., 2025
2025
-
[35]
Avital Shafran, Roei Schuster, Tom Ristenpart, and Vitaly Shmatikov. 2025. Rerouting LLM routers. In Conference on Language Modeling (COLM)
2025
-
[36]
Chenxu Wang, Hao Li, Yiqun Zhang, Linyao Chen, Jianhao Chen, Ping Jian, Peng Ye, Qiaosheng Zhang, and Shuyue Hu. 2025. https://arxiv.org/abs/2510.09719 Icl-router: In-context learned model representations for llm routing . In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI). Poster
-
[37]
Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou. 2020. Minilm: deep self-attention distillation for task-agnostic compression of pre-trained transformers. In Proceedings of the 34th International Conference on Neural Information Processing Systems, NIPS '20, Red Hook, NY, USA. Curran Associates Inc
2020
- [38]
- [39]
-
[40]
Yiqun Zhang, Hao Li, Jianhao Chen, Hangfan Zhang, Peng Ye, Lei Bai, and Shuyue Hu. 2025. https://doi.org/10.1145/3772429.3772445 Beyond gpt-5: Making llms cheaper and better via performance-efficiency optimized routing . In Proceedings of the 2025 7th International Conference on Distributed Artificial Intelligence, DAI '25, page 122–129, New York, NY, USA...
-
[41]
Zesen Zhao, Shuowei Jin, and Z. Morley Mao. 2024. https://arxiv.org/abs/2409.15518 Eagle: Efficient training-free router for multi-llm inference . Preprint, arXiv:2409.15518
-
[42]
Richard Zhuang, Tianhao Wu, Zhaojin Wen, Andrew Li, Jiantao Jiao, and Kannan Ramchandran. 2025. https://openreview.net/forum?id=Fs9EabmQrJ Embed LLM : Learning compact representations of large language models . In The Thirteenth International Conference on Learning Representations
2025
-
[43]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter, and Matt Fredrikson. 2023. https://arxiv.org/abs/2307.15043 Universal and transferable adversarial attacks on aligned language models . Preprint, arXiv:2307.15043
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.