Recognition: unknown
ControlFoley: Unified and Controllable Video-to-Audio Generation with Cross-Modal Conflict Handling
Pith reviewed 2026-05-10 09:17 UTC · model grok-4.3
The pith
ControlFoley unifies video, text, and reference audio control for video-to-audio generation by resolving cross-modal conflicts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ControlFoley establishes a unified multimodal framework for video-to-audio generation that supports precise control via video content, text descriptions, and reference audio clips. The framework incorporates a joint visual encoding that combines CLIP features with a spatio-temporal audio-visual encoder to enhance alignment and textual influence. Temporal-timbre decoupling isolates discriminative timbre features from temporal cues in reference audio, while a modality-robust training scheme using unified multimodal representation alignment (REPA) and random modality dropout ensures the model remains effective across varying input combinations and conflicts.
What carries the argument
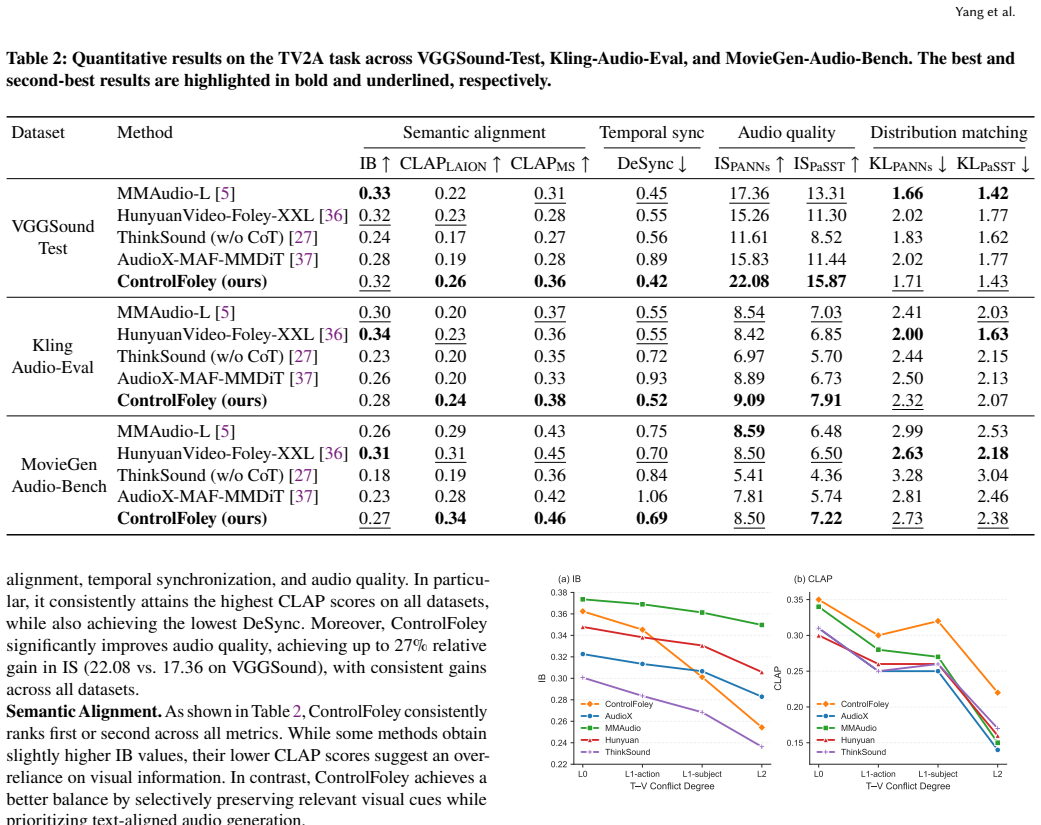
Joint visual encoding paradigm paired with temporal-timbre decoupling, which merges CLIP and spatio-temporal encoders for visual-text alignment and strips timing information from reference audio while retaining timbre features.
If this is right
- Text prompts can direct audio output even when they directly contradict visual content.
- Reference audio supplies stylistic traits without leaking unwanted temporal patterns into the result.
- The model maintains competitive synchronization and quality against industrial video-to-audio systems.
- The VGGSound-TVC benchmark provides a repeatable way to quantify controllability under graded visual-text conflicts.
- Random modality dropout during training allows the system to operate when one or more input types are absent or conflicting.
Where Pith is reading between the lines
- The temporal-timbre split could transfer to other audio synthesis tasks that need style control independent of rhythm.
- Creators could use live text adjustments to refine generated soundtracks in post-production pipelines.
- Adding motion or depth maps to the joint visual encoder might increase precision in dynamic scenes.
- Similar conflict-handling benchmarks could be built for image-to-video or text-to-music generation.
Load-bearing premise
That combining CLIP with spatio-temporal visual encoding, separating timbre from temporal cues in reference audio, and training with REPA alignment plus modality dropout will resolve cross-modal conflicts without harming synchronization or audio quality.
What would settle it
A controlled test on VGGSound-TVC where video shows one action but text specifies a clearly conflicting sound source; measure whether generated audio follows the text prompt more than the video while keeping synchronization metrics and perceptual quality scores at or above baseline levels.
Figures









read the original abstract
Recent advances in video-to-audio (V2A) generation enable high-quality audio synthesis from visual content, yet achieving robust and fine-grained controllability remains challenging. Existing methods suffer from weak textual controllability under visual-text conflict and imprecise stylistic control due to entangled temporal and timbre information in reference audio. Moreover, the lack of standardized benchmarks limits systematic evaluation. We propose ControlFoley, a unified multimodal V2A framework that enables precise control over video, text, and reference audio. We introduce a joint visual encoding paradigm that integrates CLIP with a spatio-temporal audio-visual encoder to improve alignment and textual controllability. We further propose temporal-timbre decoupling to suppress redundant temporal cues while preserving discriminative timbre features. In addition, we design a modality-robust training scheme with unified multimodal representation alignment (REPA) and random modality dropout. We also present VGGSound-TVC, a benchmark for evaluating textual controllability under varying degrees of visual-text conflict. Extensive experiments demonstrate state-of-the-art performance across multiple V2A tasks, including text-guided, text-controlled, and audio-controlled generation. ControlFoley achieves superior controllability under cross-modal conflict while maintaining strong synchronization and audio quality, and shows competitive or better performance compared to an industrial V2A system. Code, models, datasets, and demos are available at: https://yjx-research.github.io/ControlFoley/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ControlFoley, a unified multimodal video-to-audio (V2A) generation framework. It introduces a joint visual encoding paradigm integrating CLIP with a spatio-temporal audio-visual encoder, temporal-timbre decoupling to handle reference audio by suppressing redundant temporal cues while preserving timbre, and a modality-robust training scheme using unified multimodal representation alignment (REPA) and random modality dropout. The authors also present the VGGSound-TVC benchmark for evaluating textual controllability under varying degrees of visual-text conflict. The central claims are state-of-the-art performance across text-guided, text-controlled, and audio-controlled V2A tasks, superior controllability under cross-modal conflict, maintained strong synchronization and audio quality, and competitive or better results versus an industrial V2A system.
Significance. If the empirical claims hold after addressing the noted concerns, this would represent a meaningful advance in controllable multimodal generation by providing a unified framework that explicitly handles cross-modal conflicts and by releasing a new benchmark (VGGSound-TVC) that could standardize evaluation of textual controllability. The open release of code, models, datasets, and demos supports reproducibility and follow-on work in the multimedia field.
major comments (2)
- [3.2] §3.2 (temporal-timbre decoupling): The method is described as suppressing redundant temporal cues from reference audio while preserving timbre. However, reference audio timing frequently carries synchronization signals that overlap with video events; the manuscript provides no ablation results on AV alignment or synchronization metrics (e.g., those reported in §4) comparing the decoupled versus non-decoupled reference audio. This directly bears on the central claim that strong synchronization is maintained while achieving superior controllability.
- [4] §4 (experimental evaluation on VGGSound-TVC): The benchmark is introduced to measure textual controllability under visual-text conflict, yet the paper does not specify how conflict degrees are quantified or controlled during dataset construction, nor does it report the precise controllability metrics (e.g., text-audio similarity scores or human ratings) and their statistical significance. Without these details, the evidence for 'superior controllability under cross-modal conflict' remains difficult to assess and is load-bearing for the SOTA claim.
minor comments (3)
- The abstract and §1 would benefit from a concise table summarizing the key quantitative results (FID, CLAP, synchronization scores, etc.) against all baselines to allow immediate comparison.
- [3.3] Notation in the REPA loss equation (likely Eq. (X) in §3.3) could be clarified by explicitly defining the modality-specific encoders before the alignment term.
- Figure captions for the VGGSound-TVC examples should indicate the specific conflict level (low/medium/high) for each illustrated sample.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below, outlining the revisions we will make to improve clarity and strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [3.2] §3.2 (temporal-timbre decoupling): The method is described as suppressing redundant temporal cues from reference audio while preserving timbre. However, reference audio timing frequently carries synchronization signals that overlap with video events; the manuscript provides no ablation results on AV alignment or synchronization metrics (e.g., those reported in §4) comparing the decoupled versus non-decoupled reference audio. This directly bears on the central claim that strong synchronization is maintained while achieving superior controllability.
Authors: We acknowledge that an explicit ablation isolating the impact of temporal-timbre decoupling on synchronization metrics would provide stronger evidence. The current results demonstrate overall strong synchronization alongside improved controllability, but we agree this does not fully isolate the decoupling component. In the revised manuscript, we will add ablation experiments reporting AV alignment and synchronization metrics (e.g., those used in §4) for both the decoupled and non-decoupled reference audio variants. This will directly address whether synchronization is preserved under decoupling. revision: yes
-
Referee: [4] §4 (experimental evaluation on VGGSound-TVC): The benchmark is introduced to measure textual controllability under visual-text conflict, yet the paper does not specify how conflict degrees are quantified or controlled during dataset construction, nor does it report the precise controllability metrics (e.g., text-audio similarity scores or human ratings) and their statistical significance. Without these details, the evidence for 'superior controllability under cross-modal conflict' remains difficult to assess and is load-bearing for the SOTA claim.
Authors: We agree that greater detail on VGGSound-TVC construction and evaluation is required to substantiate the controllability claims. In the revised version, we will expand the description of how conflict degrees are quantified (e.g., via semantic similarity thresholds between visual and textual modalities) and controlled during dataset construction. We will also report the precise controllability metrics, including text-audio similarity scores and human ratings, together with statistical significance tests to support the reported superiority under cross-modal conflict. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper's central claims rest on proposed architectural innovations (joint visual encoding, temporal-timbre decoupling, REPA with random dropout) and empirical results on VGGSound-TVC benchmark, without any equations, predictions, or uniqueness theorems that reduce by construction to fitted inputs or self-referential definitions. No load-bearing self-citations or ansatzes smuggled via prior work are present in the derivation; the evaluation is independent and externally falsifiable via reported metrics.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption CLIP provides effective visual features that improve audio-visual alignment when combined with spatio-temporal encoding
- domain assumption Temporal and timbre information in reference audio can be meaningfully decoupled to improve stylistic control
Reference graph
Works this paper leans on
-
[1]
Glass, and Hilde Kuehne
Edson Araujo, Andrew Rouditchenko, Yuan Gong, Saurabhchand Bhati, Samuel Thomas, Brian Kingsbury, Leonid Karlinsky, Rogerio Feris, James R. Glass, and Hilde Kuehne. 2025. CAV-MAE Sync: Improving Contrastive Audio-Visual Mask Autoencoders via Fine-Grained Alignment . In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE Compute...
2025
-
[2]
Honglie Chen, Weidi Xie, Triantafyllos Afouras, Arsha Nagrani, Andrea Vedaldi, and Andrew Zisserman. 2021. Localizing visual sounds the hard way. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition. 16867–16876
2021
-
[3]
Honglie Chen, Weidi Xie, Andrea Vedaldi, and Andrew Zisserman. 2020. VGG- Sound: A Large-Scale Audio-Visual Dataset. InIEEE Int. Conf. Acoust. Speech Signal Process. (ICASSP). 721–725
2020
-
[4]
Video-GuidedFoleySoundGeneration with Multimodal Controls
Ziyang Chen, Prem Seetharaman, Bryan Russell, Oriol Nieto, David Bourgin, AndrewOwens,andJustinSalamon.2025. Video-GuidedFoleySoundGeneration with Multimodal Controls. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 18770–18781
2025
-
[5]
HoKeiCheng,MasatoIshii,AkioHayakawa,TakashiShibuya,AlexanderSchwing, and Yuki Mitsufuji. 2025. MMAudio: Taming Multimodal Joint Training for High-Quality Video-to-Audio Synthesis. InIEEE Conf. Comput. Vis. Pattern Recog. (CVPR). 28901–28911
2025
-
[6]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multi- modality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
JadeCopet,FelixKreuk,ItaiGat,TalRemez,DavidKant,GabrielSynnaeve,Yossi Adi, and Alexandre Défossez. 2023. Simple and Controllable Music Generation. InThirty-seventh Conference on Neural Information Processing Systems
2023
-
[8]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xi- aohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. 2021. An Image is Worth 16x16 Words: Trans- formers for Image Recognition at Scale. InInternational Conference on Learning Representations
2021
-
[9]
Konstantinos Drossos, Samuel Lipping, and Tuomas Virtanen. 2020. Clotho: An audio captioning dataset. InICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 736–740
2020
-
[10]
Yuexi Du, Ziyang Chen, Justin Salamon, Bryan Russell, and Andrew Owens
-
[11]
In2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Conditional Generation of Audio from Video via Foley Analogies. In2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2426–2436
-
[12]
Benjamin Elizalde, Soham Deshmukh, Mahmoud Al Ismail, and Huaming Wang
-
[13]
InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
Clap learning audio concepts from natural language supervision. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5
2023
-
[14]
Patrick Esser, Sumith Kulal, A. Blattmann, Rahim Entezari, Jonas Muller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, Kyle Lacey, Alex Goodwin, Yannik Marek, and Robin Rombach. 2024. Scaling Rectified Flow Transformers for High-Resolution Image Synthesis. InInternational Conference on Machi...
2024
-
[15]
HugoFloresGarcía,OriolNieto,JustinSalamon,BryanPardo,andPremSeethara- man. 2025. Sketch2sound: Controllable audio generation via time-varying signals and sonic imitations. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5
2025
-
[16]
Mariana-Iuliana Georgescu, Eduardo Fonseca, Radu Tudor Ionescu, Mario Lucic, Cordelia Schmid, and Anurag Arnab. 2023. Audiovisual Masked Autoencoders . In2023 IEEE/CVF International Conference on Computer Vision (ICCV). 16098–16108
2023
-
[17]
Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, and Ishan Misra. 2023. Imagebind: One embedding space to bind them all. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 15180–15190
2023
-
[18]
Liu, David Harwath, Leonid Karlinsky, Hilde Kuehne, and James Glass
Yuan Gong, Andrew Rouditchenko, Alexander H. Liu, David Harwath, Leonid Karlinsky, Hilde Kuehne, and James Glass. 2023. Contrastive Audio-Visual Masked Autoencoder. arXiv:2210.07839
-
[19]
Xinyue Guo, Xiaoran Yang, Lipan Zhang, Jianxuan Yang, Zhao Wang, and Jian Luan. 2026. AV-Edit: Multimodal Generative Sound Effect Editing via Audio- Visual Semantic Joint Control.Proceedings of the AAAI Conference on Artificial Intelligence40, 26 (Mar. 2026), 21504–21512
2026
-
[20]
Moayed Haji-Ali, Willi Menapace, Aliaksandr Siarohin, Guha Balakrishnan, and Vicente Ordonez. 2026. Taming Data and Transformers for Audio Generation. International Journal of Computer Vision134 (2026)
2026
-
[21]
Emiel Hoogeboom, Jonathan Heek, and Tim Salimans. 2023. Simple diffusion: end-to-end diffusion for high resolution images. InInternational Conference on Machine Learning
2023
-
[22]
Chia-Yu Hung, Navonil Majumder, Zhifeng Kong, Ambuj Mehrish, Amir Ali Bagherzadeh, Chuan Li, Rafael Valle, Bryan Catanzaro, and Soujanya Poria. 2025. TangoFlux: Super Fast and Faithful Text to Audio Generation with Flow Matching and Clap-Ranked Preference Optimization. arXiv:2412.21037
-
[23]
InICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
VladimirIashin,WeidiXie,EsaRahtu,andAndrewZisserman.2024.Synchformer: Efficient Synchronization From Sparse Cues. InICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 5325–5329
2024
-
[24]
Yujin Jeong, Yunji Kim, Sanghyuk Chun, and Jiyoung Lee. 2025. Read, watch and scream! sound generation from text and video. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 17590–17598
2025
-
[25]
Chris Dongjoo Kim, Byeongchang Kim, Hyunmin Lee, and Gunhee Kim. 2019. Audiocaps: Generating captions for audios in the wild. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 119–132
2019
-
[26]
Qiuqiang Kong, Yin Cao, Turab Iqbal, Yuxuan Wang, Wenwu Wang, and Mark D Plumbley. 2020. Panns: Large-scale pretrained audio neural networks for audio pattern recognition.IEEE/ACM Transactions on Audio, Speech, and Language Processing28 (2020), 2880–2894
2020
-
[27]
Khaled Koutini, Jan Schlüter, Hamid Eghbal-Zadeh, and Gerhard Widmer
- [28]
-
[29]
FCConDubber: Fine and Coarse-Grained Prosody Alignment for Expressive Video Dubbing via Contrastive Audio-Motion Pretraining
QiulinLi,ZhichaoWu,HanweiLi,XinDong,andQunYang.2025. FCConDubber: Fine and Coarse-Grained Prosody Alignment for Expressive Video Dubbing via Contrastive Audio-Motion Pretraining. InIEEE Int. Conf. Acoust. Speech Signal Process. (ICASSP). 1–5
2025
- [30]
-
[31]
Plumbley
Haohe Liu, Yi Yuan, Xubo Liu, Xinhao Mei, Qiuqiang Kong, Qiao Tian, Yuping Wang, Wenwu Wang, Yuxuan Wang, and Mark D. Plumbley. 2024. AudioLDM 2: LearningHolisticAudioGenerationWithSelf-SupervisedPretraining.IEEE/ACM Transactions on Audio, Speech, and Language Processing32 (2024), 2871–2883
2024
-
[32]
Jing Liu, Sihan Chen, Xingjian He, Longteng Guo, Xinxin Zhu, Weining Wang, and Jinhui Tang. 2025. VALOR: Vision-Audio-Language Omni-Perception Pretraining Model and Dataset.IEEE Transactions on Pattern Analysis and Machine Intelligence47, 2 (2025), 708–724
2025
-
[33]
Xiulong Liu, Kun Su, and Eli Shlizerman. 2024. Tell what you hear from what you see-video to audio generation through text.Advances in Neural Information Processing Systems37 (2024), 101337–101366
2024
-
[34]
Simian Luo, Chuanhao Yan, Chenxu Hu, and Hang Zhao. 2023. Diff-foley: Synchronized video-to-audio synthesis with latent diffusion models.Advances in Neural Information Processing Systems36 (2023), 48855–48876
2023
-
[35]
Xinhao Mei, Chutong Meng, Haohe Liu, Qiuqiang Kong, Tom Ko, Chengqi Zhao, Mark D Plumbley, Yuexian Zou, and Wenwu Wang. 2024. Wavcaps: A chatgpt- assisted weakly-labelled audio captioning dataset for audio-language multimodal research.IEEE/ACM Transactions on Audio, Speech, and Language Processing 32 (2024), 3339–3354
2024
-
[36]
Visuallyindicatedsounds.InProceedings of the IEEE conference on computer vision and pattern recognition
Andrew Owens, Phillip Isola, Josh McDermott, Antonio Torralba, Edward H Adelson,andWilliamTFreeman.2016. Visuallyindicatedsounds.InProceedings of the IEEE conference on computer vision and pattern recognition. 2405–2413
2016
-
[37]
Adam Polyak, Amit Zohar, Andrew Brown, Andros Tjandra, Animesh Sinha, Ann Lee, Apoorv Vyas, and Bowen Shi et al. 2024. MovieGen: A Cast of Media Foundation Models.arXiv preprint arXiv:2410.13720(2024)
work page internal anchor Pith review arXiv 2024
-
[38]
Learningtransferablevisualmodelsfromnaturallanguagesupervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, etal.2021. Learningtransferablevisualmodelsfromnaturallanguagesupervision. InInternational conference on machine learning. PmLR, 8748–8763
2021
- [39]
-
[40]
Zeyue Tian, Zhaoyang Liu, Yizhu Jin, Ruibin Yuan, Xu Tan, Qifeng Chen, Wei Xue, and Yike Guo. 2026. AudioX: A Unified Framework for Anything-to-Audio Generation. arXiv:2503.10522
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[41]
Ioannis Tsiamas, Santiago Pascual, Chunghsin Yeh, and Joan Serrà. 2025. Sequen- tial Contrastive Audio-Visual Learning. InIEEE Int. Conf. Acoust. Speech Signal Process. (ICASSP). 1–5
2025
-
[42]
Ilpo Viertola, Vladimir Iashin, and Esa Rahtu. 2025. Temporally aligned audio for video with autoregression. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5
2025
-
[43]
Li Wan, Quan Wang, Alan Papir, and Ignacio Lopez Moreno. 2018. Generalized end-to-end loss for speaker verification. In2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 4879–4883
2018
-
[44]
Jun Wang, Xijuan Zeng, Chunyu Qiang, Ruilong Chen, Shiyao Wang, Le Wang, Wangjing Zhou, Pengfei Cai, Jiahui Zhao, Nan Li, Zihan Li, Yuzhe Liang, Xiaopeng Wang, Haorui Zheng, Ming Wen, Kang Yin, Yiran Wang, Nan Li, Feng Deng, Liang Dong, Chen Zhang, Di Zhang, and Kun Gai. 2025. Kling-Foley: Multimodal Diffusion Transformer for High-Quality Video-to-Audio G...
- [45]
-
[46]
Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, and Shlomo Dubnov. 2023. Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5
2023
-
[47]
Yazhou Xing, Yingqing He, Zeyue Tian, Xintao Wang, and Qifeng Chen. 2024. Seeing and hearing: Open-domain visual-audio generation with diffusion latent aligners. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 7151–7161
2024
-
[48]
Visual - Text Conflic
Yiming Zhang, Yicheng Gu, Yanhong Zeng, Zhening Xing, Yuancheng Wang, Zhizheng Wu, Bin Liu, and Kai Chen. 2026. FoleyCrafter: Bring Silent Videos to LifewithLifelikeandSynchronizedSounds.Int.J.Comput.Vision134,1(2026). ControlFoley: Unified and Controllable Video-to-Audio Generation with Cross-Modal Conflict Handling Appendix A VGGSound-TVC Construction P...
2026
-
[49]
dog barking
noun + verb - ing ( e . g . , " dog barking " , " people whispering ")
-
[50]
chopping wood
gerund phrase ( e . g . , " chopping wood " , " driving buses ")
-
[51]
wind noise
noun phrase ( e . g . , " wind noise " , " ambulance siren ") - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - You will be given : - A video clip ( visual input ) - Its raw label : label _ L 0_ raw ( Note : label _ L 0_ raw may contain multiple comma - separated synonyms ) - - - - - - - - - - - - - - - - ...
-
[52]
female speech , woman speaking
label _ L 0 ( Clean Ground Truth ) - If label _ L 0_ raw contains multiple comma - separated labels , SELECT exactly ONE label that best matches the visual content of the video . - If label _ L 0_ raw contains only one label , copy it directly without modification . - Do NOT introduce new semantics or change the event type . - Keep the label concise and i...
-
[53]
dog barking
label _ L 1_ subject ( Weak Conflict : Subject Change ) - Change WHO produces the sound . - Preserve the TEMPORAL STRUCTURE and overall acoustic pattern . - The new subject must plausibly produce a similar type of sound . - IMPORTANT : When the subject changes , the ACTION WORD must be updated to a natural verb for the new subject . Examples : - " dog bar...
-
[54]
people clapping
label _ L 1_ action ( Weak Conflict : Action Change ) - Keep the SAME subject . - Change the action , but STRICTLY preserve the temporal pattern . Temporal consistency rules : - Continuous stays continuous - Rhythmic stays rhythmic - Transient stays transient Examples : - " people clapping " -> " slapping table " - " dog barking " -> " dog coughing " - " ...
-
[55]
dog barking
label _ L 2 ( Moderate Conflict : Semantic Mismatch , Physical Match ) - Change to a DIFFERENT semantic class . - The sound must remain acoustically and temporally compatible with the video's motion and rhythm . - Visual meaning may conflict , but sound structure must match . - Think like a Foley artist . Examples : - " dog barking " -> " knocking on door...
-
[56]
All labels look like valid VGGSound labels
-
[57]
Temporal structure is preserved across all rewritten labels
-
[58]
No extra text
Output JSON ONLY . No extra text
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.