Recognition: unknown
From Procedural Skills to Strategy Genes: Towards Experience-Driven Test-Time Evolution
Pith reviewed 2026-05-10 10:50 UTC · model grok-4.3
The pith
A compact Gene representation for reusable experience outperforms documentation-heavy Skill packages in guiding AI code solvers and enabling iterative evolution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Representation itself is a first-order factor. A compact Gene representation yields the strongest overall average, remains competitive under substantial structural perturbations, and outperforms matched-budget Skill fragments, while reattaching documentation-oriented material usually weakens rather than improves it. Gene is also a better carrier for iterative experience accumulation: attached failure history is more effective in Gene than in Skill or freeform text, editable structure matters beyond content alone, and failure information is most useful when distilled into compact warnings rather than naively appended. On CritPt, gene-evolved systems improve over their paired base models from
What carries the argument
The Gene, a compact editable structure that functions simultaneously as test-time control signal and substrate for iterative accumulation of experience.
If this is right
- Gene-evolved systems reach higher success rates on code-solving tasks than their base models.
- Failure history improves performance more when carried by Gene than by Skill packages or raw text.
- Distilling failures into compact warnings outperforms simply appending full failure traces.
- Adding documentation material to a compact Gene usually reduces rather than increases effectiveness.
Where Pith is reading between the lines
- The same representation choice may matter for experience reuse in non-code domains such as planning or tool use.
- Agents could maintain and evolve populations of Genes across repeated interactions rather than accumulating procedural fragments.
- Benchmarks that vary only representation format while holding total token budget fixed would isolate the effect more cleanly.
Load-bearing premise
That the 45 scientific code-solving scenarios and the chosen definitions of Gene versus Skill fragments are representative of broader experience-reuse needs, and that observed differences arise primarily from representation format.
What would settle it
A replication on a substantially larger or more diverse set of tasks in which Skill formats consistently produce higher success rates than Gene formats would falsify the central claim.
Figures




read the original abstract
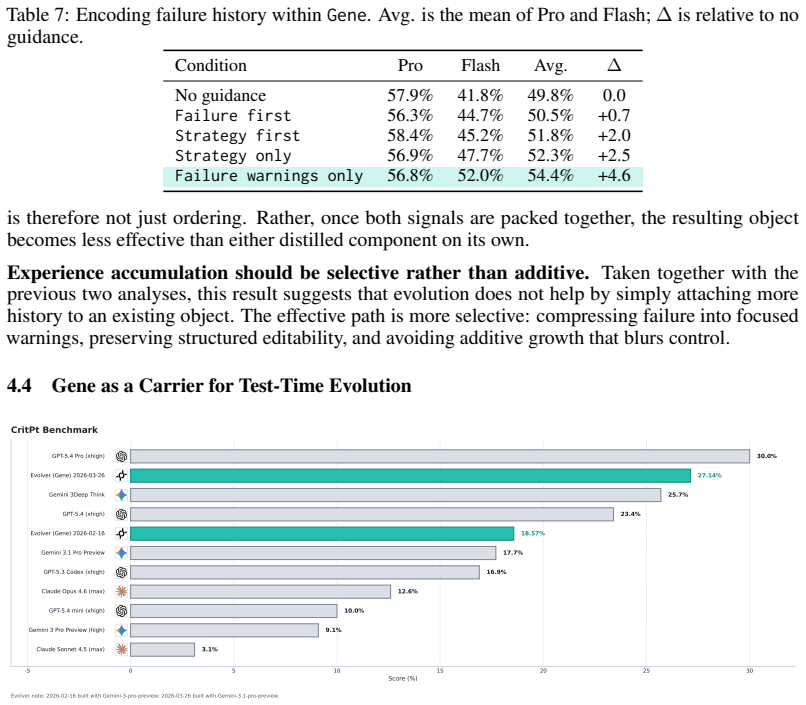
This beta technical report asks how reusable experience should be represented so that it can function as effective test-time control and as a substrate for iterative evolution. We study this question in 4.590 controlled trials across 45 scientific code-solving scenarios. We find that documentation-oriented Skill packages provide unstable control: their useful signal is sparse, and expanding a compact experience object into a fuller documentation package often fails to help and can degrade the overall average. We further show that representation itself is a first-order factor. A compact Gene representation yields the strongest overall average, remains competitive under substantial structural perturbations, and outperforms matched-budget Skill fragments, while reattaching documentation-oriented material usually weakens rather than improves it. Beyond one-shot control, we show that Gene is also a better carrier for iterative experience accumulation: attached failure history is more effective in Gene than in Skill or freeform text, editable structure matters beyond content alone, and failure information is most useful when distilled into compact warnings rather than naively appended. On CritPt, gene-evolved systems improve over their paired base models from 9.1% to 18.57% and from 17.7% to 27.14%. These results suggest that the core problem in experience reuse is not how to supply more experience, but how to encode experience as a compact, control-oriented, evolution-ready object.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports results from 4,590 controlled trials across 45 scientific code-solving scenarios. It claims that documentation-oriented Skill packages yield unstable control, while a compact Strategy Gene representation delivers the strongest overall average performance, remains competitive under structural perturbations, outperforms matched-budget Skill fragments, and serves as a superior carrier for iterative experience accumulation (e.g., failure history is more effective when distilled into compact warnings). Reattaching documentation-oriented material typically weakens results. Concrete gains are reported on CritPt, where gene-evolved systems improve paired base models from 9.1% to 18.57% and from 17.7% to 27.14%. The work concludes that the core issue in experience reuse is encoding as compact, control-oriented, evolution-ready objects rather than supplying more experience.
Significance. If the results prove robust, the work provides large-scale empirical evidence that representation format is a first-order factor in test-time experience reuse for LLM-based code solvers. It shifts emphasis from volume of experience to structured, editable, compact encodings that support both immediate control and iterative evolution. The scale of the evaluation (4,590 trials) and the concrete percentage gains on held-out scenarios are notable strengths that could inform agent design in software engineering and related domains.
major comments (1)
- [Abstract / Experimental Setup] The central claim that performance gains arise from the Gene representation (rather than incidental prompt differences) is load-bearing, yet the abstract only states that Gene 'outperforms matched-budget Skill fragments' without detailing how total prompt length, token allocation, structural framing, delimiters, ordering, and auxiliary instructions are held identical across conditions. If Skill fragments are rendered as fuller documentation-style text while Gene remains compact, the reported lifts (e.g., CritPt from 9.1% to 18.57%) could be artifacts of prompt engineering. Explicit confirmation or ablation of these controls is required in the methods section.
minor comments (1)
- [Abstract] The figure '4.590' in the abstract is a typographical error and should read '4,590' for readability.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The concern about prompt equivalence controls is well-taken and directly relevant to the load-bearing claim. We address it below and will strengthen the manuscript with additional documentation.
read point-by-point responses
-
Referee: [Abstract / Experimental Setup] The central claim that performance gains arise from the Gene representation (rather than incidental prompt differences) is load-bearing, yet the abstract only states that Gene 'outperforms matched-budget Skill fragments' without detailing how total prompt length, token allocation, structural framing, delimiters, ordering, and auxiliary instructions are held identical across conditions. If Skill fragments are rendered as fuller documentation-style text while Gene remains compact, the reported lifts (e.g., CritPt from 9.1% to 18.57%) could be artifacts of prompt engineering. Explicit confirmation or ablation of these controls is required in the methods section.
Authors: We agree that the abstract is concise and that the methods section should provide explicit confirmation. In the full manuscript the matched-budget condition is implemented by selecting or truncating Skill fragments so that their token count (measured with the same tokenizer) lies within 5% of the Gene length for each scenario; the base prompt template, system instructions, query framing, delimiters, and output constraints are identical across all conditions, with the experience block inserted at the same position. We will add a dedicated subsection in Methods titled 'Prompt Equivalence and Token Budget Controls' that reports the per-scenario token budgets, the fragment-selection procedure, and a new ablation in which we deliberately mismatch lengths to isolate the effect of representation format. This revision will make the controls fully transparent and rule out prompt-engineering artifacts. revision: yes
Circularity Check
No circularity: purely empirical comparison of representations via measured outcomes
full rationale
The paper conducts 4,590 controlled trials on 45 held-out scientific code-solving scenarios and directly measures performance differences between Gene and Skill representations (e.g., CritPt lifts from 9.1% to 18.57%). No equations, derivations, fitted parameters, or self-citations are invoked to reduce any claimed result to its own inputs by construction. All reported gains are external measurements on independent test cases rather than tautological re-expressions of fitted quantities or prior self-referential theorems.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 45 code-solving scenarios are representative of the broader class of tasks where experience reuse matters.
invented entities (1)
-
Strategy Gene
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A survey on large language model based autonomous agents.Frontiers Comput
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, and Jirong Wen. A survey on large language model based autonomous agents.Frontiers Comput. Sci., 18(6):186345, 2024
2024
-
[2]
A survey on the memory mechanism of large language model-based agents
Zeyu Zhang, Quanyu Dai, Xiaohe Bo, Chen Ma, Rui Li, Xu Chen, Jieming Zhu, Zhenhua Dong, and Ji-Rong Wen. A survey on the memory mechanism of large language model-based agents. ACM Trans. Inf. Syst., 43(6):155:1–155:47, 2025
2025
-
[3]
V oyager: An open-ended embodied agent with large language models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models. Trans. Mach. Learn. Res., 2024, 2024
2024
-
[4]
Reflexion: language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: language agents with verbal reinforcement learning. InNeurIPS, 2023
2023
-
[5]
Expel: LLM agents are experiential learners
Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. Expel: LLM agents are experiential learners. InAAAI, pages 19632–19642. AAAI Press, 2024
2024
-
[6]
Skill-Pro: Learning Reusable Skills from Experience via Non-Parametric PPO for LLM Agents
Qirui Mi, Zhijian Ma, Mengyue Yang, Haoxuan Li, Yisen Wang, Haifeng Zhang, and Jun Wang. Procmem: Learning reusable procedural memory from experience via non-parametric PPO for LLM agents.CoRR, abs/2602.01869, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
MemSkill: Learning and Evolving Memory Skills for Self-Evolving Agents
Haozhen Zhang, Quanyu Long, Jianzhu Bao, Tao Feng, Weizhi Zhang, Haodong Yue, and Wenya Wang. Memskill: Learning and evolving memory skills for self-evolving agents.CoRR, abs/2602.02474, 2026
work page internal anchor Pith review arXiv 2026
-
[8]
Memento-skills: Let agents design agents
Huichi Zhou, Siyuan Guo, Anjie Liu, Zhongwei Yu, Ziqin Gong, Bowen Zhao, Zhixun Chen, Menglong Zhang, Yihang Chen, Jinsong Li, et al. Memento-skills: Let agents design agents. arXiv preprint arXiv:2603.18743, 2026
-
[9]
Zexin Lin, Jiachen Yu, Haoyang Zhang, Yuzhao Li, Zhonghang Li, Yujiu Yang, Junjie Wang, and Xiaoqiang Ji. Cowork-x: Experience-optimized co-evolution for multi-agent collaboration system.CoRR, abs/2602.05004, 2026
-
[10]
Self-refine: Iterative refinement with self-feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. Self-refine: Iterative refinement with self-feedback. InNeurIPS, 2023
2023
-
[11]
CRITIC: large language models can self-correct with tool-interactive critiquing
Zhibin Gou, Zhihong Shao, Yeyun Gong, Yelong Shen, Yujiu Yang, Nan Duan, and Weizhu Chen. CRITIC: large language models can self-correct with tool-interactive critiquing. InICLR. OpenReview.net, 2024
2024
-
[12]
Teaching large language models to self-debug
Xinyun Chen, Maxwell Lin, Nathanael Schärli, and Denny Zhou. Teaching large language models to self-debug. InICLR. OpenReview.net, 2024. 14
2024
-
[13]
Memp: Exploring Agent Procedural Memory
Runnan Fang, Yuan Liang, Xiaobin Wang, Jialong Wu, Shuofei Qiao, Pengjun Xie, Fei Huang, Huajun Chen, and Ningyu Zhang. Memp: Exploring agent procedural memory.CoRR, abs/2508.06433, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Libin Qiu, Zhirong Gao, Junfu Chen, Yuhang Ye, Weizhi Huang, Xiaobo Xue, Wenkai Qiu, and Shuo Tang. Autorefine: From trajectories to reusable expertise for continual LLM agent refinement.CoRR, abs/2601.22758, 2026
-
[15]
Evo-Memory: Benchmarking LLM Agent Test-time Learning with Self-Evolving Memory
Tianxin Wei, Noveen Sachdeva, Benjamin Coleman, Zhankui He, Yuanchen Bei, Xuying Ning, Mengting Ai, Yunzhe Li, Jingrui He, Ed H. Chi, Chi Wang, Shuo Chen, Fernando Pereira, Wang-Cheng Kang, and Derek Zhiyuan Cheng. Evo-memory: Benchmarking LLM agent test-time learning with self-evolving memory.CoRR, abs/2511.20857, 2025
work page internal anchor Pith review arXiv 2025
-
[16]
Yu Cheng, Jiuan Zhou, Yongkang Hu, Yihang Chen, Huichi Zhou, Mingang Chen, Zhizhong Zhang, Kun Shao, Yuan Xie, and Zhaoxia Yin. TAME: A trustworthy test-time evolution of agent memory with systematic benchmarking.CoRR, abs/2602.03224, 2026
-
[17]
Yongshi Ye, Hui Jiang, Feihu Jiang, Tian Lan, Yichao Du, Biao Fu, Xiaodong Shi, Qianghuai Jia, Longyue Wang, and Weihua Luo. UMEM: unified memory extraction and management framework for generalizable memory.CoRR, abs/2602.10652, 2026
-
[18]
URLhttps://arxiv.org/abs/2512.18746
Guibin Zhang, Haotian Ren, Chong Zhan, Zhenhong Zhou, Junhao Wang, He Zhu, Wangchun- shu Zhou, and Shuicheng Yan. Memevolve: Meta-evolution of agent memory systems.CoRR, abs/2512.18746, 2025
-
[19]
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
Xiangyi Li, Wenbo Chen, Yimin Liu, Shenghan Zheng, Xiaokun Chen, Yifeng He, Yubo Li, Bingran You, Haotian Shen, Jiankai Sun, Shuyi Wang, Qunhong Zeng, Di Wang, Xuandong Zhao, Yuanli Wang, Roey Ben Chaim, Zonglin Di, Yipeng Gao, Junwei He, Yizhuo He, Liqiang Jing, Luyang Kong, Xin Lan, Jiachen Li, Songlin Li, Yijiang Li, Yueqian Lin, Xinyi Liu, Xuanqing Li...
work page internal anchor Pith review arXiv 2026
-
[20]
Agent Skills for Large Language Models: Architecture, Acquisition, Security, and the Path Forward
Renjun Xu and Yang Yan. Agent skills for large language models: Architecture, acquisition, security, and the path forward.CoRR, abs/2602.12430, 2026
work page internal anchor Pith review arXiv 2026
- [21]
-
[22]
Probing the Critical Point (CritPt) of AI Reasoning: a Frontier Physics Research Benchmark
Minhui Zhu, Minyang Tian, Xiaocheng Yang, Tianci Zhou, Penghao Zhu, Eli Chertkov, Shengyan Liu, Yufeng Du, Lifan Yuan, Ziming Ji, Indranil Das, Junyi Cao, Yufeng Du, Jinchen He, Yifan Su, Jiabin Yu, Yikun Jiang, Yujie Zhang, Chang Liu, Ze-Min Huang, Weizhen Jia, Xinan Chen, Peixue Wu, Yunkai Wang, Juntai Zhou, Yong Zhao, Farshid Jafarpour, Jessie Shelton,...
work page internal anchor Pith review arXiv 2025
-
[23]
optimize
AVOID: {pitfall} </strategy-gene> Representative Skill control prompt.For the Skill condition, the same task prompt is paired with a documentation-style full skill package: You are given the following skill package to guide your work. Follow its instructions carefully. <SKILL.md + scripts + ...> Representative evolution-style control prompt.Some retained ...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.