Recognition: unknown
SCENIC: Stream Computation-Enhanced SmartNIC
Pith reviewed 2026-05-10 09:43 UTC · model grok-4.3
The pith
SCENIC turns the SmartNIC datapath into a first-class stream computation substrate to match commercial 200G performance while adding programmability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
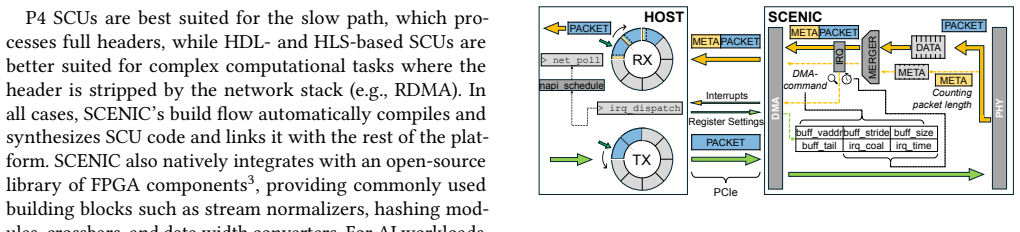
SCENIC implements a 200G network datapath over offloaded TCP/IP and RDMA stacks together with a fallback path for arbitrary traffic; on top of this logic it places Stream Compute Units for data processing and embedded ARM cores for flexible control-path manipulation, all while exposing native Linux network and RDMA verb interfaces so that the programmable elements remain transparent to unmodified applications.
What carries the argument
Stream Compute Units (SCUs) placed directly on the network datapath, paired with embedded ARM cores and shared hardware/software abstractions that allow tight co-design of infrastructure and applications.
Load-bearing premise
Adding Stream Compute Units and ARM cores to the high-speed datapath can deliver useful programmability and control without creating latency or bandwidth penalties that would keep the device from matching commercial SmartNIC performance.
What would settle it
A direct benchmark comparison in which SCENIC's measured latency or sustained bandwidth on standard RDMA or TCP workloads falls measurably below a commercial 200G SmartNIC, or in which the described use cases (offloaded collectives or network-to-GPU partitioning) cannot run at line rate.
Figures







read the original abstract
Although modern, AI-centric datacenters heavily rely on SmartNICs, existing devices impose a hard trade-off. Commercial SmartNICs provide high bandwidth and easy software integration, but offer limited support for customization and data processing offload. In contrast, research SmartNICs often suffer from low bandwidth, limited functionality, and poor software compatibility -- to the point that many are not actual NICs in a technical sense. This gap can be closed by treating the NIC datapath as a first-class stream computation substrate with shared hardware/software abstractions for a tight co-design of infrastructure and applications. To demonstrate this, we introduce SCENIC, an open-source datacenter SmartNIC. SCENIC implements a 200G network datapath over offloaded TCP/IP and RDMA stacks, as well as a fallback path for processing arbitrary network traffic. On top of the network logic, SCENIC combines on-datapath Stream Compute Units (SCUs) for data processing and embedded ARM cores for flexible control path manipulation with direct access to GPUs and SSDs. SCENIC is fully integrated with the OS, exposing native Linux network and RDMA verb interfaces, making the programmable datapath transparent to existing applications while enabling control of, e.g., user-defined offloads and programmable congestion control. SCENIC's performance matches commercial platforms, and we show its versatility through several use cases such as offloaded collective communication and network-to-GPU hash-based data partitioning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SCENIC, an open-source datacenter SmartNIC that implements a 200G network datapath over offloaded TCP/IP and RDMA stacks together with a fallback path for arbitrary traffic. It augments the datapath with on-datapath Stream Compute Units (SCUs) for data processing and embedded ARM cores for control, while providing direct GPU/SSD access and full integration with the Linux OS and RDMA verb interfaces. The central claims are that this design achieves performance parity with commercial platforms and enables versatile use cases such as offloaded collective communication and network-to-GPU hash-based data partitioning without sacrificing bandwidth or latency.
Significance. If the zero-overhead integration of SCUs and ARM cores is demonstrated, the work would meaningfully close the gap between high-bandwidth commercial SmartNICs and customizable research platforms by delivering a fully OS-compatible, programmable datapath. The open-source prototype, native Linux/RDMA compatibility, and multiple concrete use cases are positive attributes that could support broader adoption and further co-design research.
major comments (2)
- [Abstract] Abstract: The claim that 'SCENIC's performance matches commercial platforms' is load-bearing for the contribution yet is presented without any quantitative throughput, latency, or bandwidth measurements, error bars, baseline comparisons (e.g., to BlueField-class devices), or ablation data isolating the impact of the added SCUs and ARM cores versus pure bypass paths.
- [Use cases] Use-case demonstrations: The offloaded collective communication and hash-based GPU partitioning examples are described at a high level but lack performance numbers, comparisons against non-programmable baselines, or stress-test results on the programmable paths and fallback route under realistic 200G workloads, leaving the 'no-penalty' assumption unverified.
minor comments (1)
- [Abstract] Abstract: The acronym 'SCU' is introduced without a short definition or pointer to the stream-computation literature that motivates the hardware abstraction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of SCENIC's potential impact. We address each major comment below with point-by-point responses and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'SCENIC's performance matches commercial platforms' is load-bearing for the contribution yet is presented without any quantitative throughput, latency, or bandwidth measurements, error bars, baseline comparisons (e.g., to BlueField-class devices), or ablation data isolating the impact of the added SCUs and ARM cores versus pure bypass paths.
Authors: We agree that the abstract would be strengthened by including a concise summary of the key quantitative results that appear in the evaluation section. The manuscript already contains throughput and latency measurements at 200 Gbps, direct comparisons to BlueField-class devices, error bars from repeated runs, and ablations isolating SCU/ARM overhead on the bypass path. We will revise the abstract to incorporate these supporting metrics and comparisons so the performance claim is substantiated at the abstract level as well. revision: yes
-
Referee: [Use cases] Use-case demonstrations: The offloaded collective communication and hash-based GPU partitioning examples are described at a high level but lack performance numbers, comparisons against non-programmable baselines, or stress-test results on the programmable paths and fallback route under realistic 200G workloads, leaving the 'no-penalty' assumption unverified.
Authors: The quantitative results for both use cases, including comparisons to non-programmable baselines and stress tests under full 200 Gbps load on programmable and fallback paths, are presented in the evaluation section. We acknowledge that the use-case descriptions themselves remain somewhat high-level and do not sufficiently cross-reference or restate these numbers. We will revise the use-case subsections to explicitly include the relevant performance figures, baseline comparisons, and workload results, thereby directly verifying the no-penalty claim in context. revision: yes
Circularity Check
No circularity detected in SCENIC implementation claims
full rationale
The paper presents an implemented hardware/software prototype for a 200G SmartNIC with on-datapath SCUs and ARM cores, offloaded TCP/IP/RDMA stacks, and OS integration. Central claims of matching commercial performance and versatility in use cases rest on the physical prototype, fallback paths, and demonstrated applications rather than any equations, fitted parameters, or derivations that reduce to their own inputs by construction. No self-definitional steps, uniqueness theorems, or ansatz smuggling via self-citation appear in the provided text; the design is described as a co-design substrate without load-bearing self-referential logic.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing hardware primitives for 200G networking and RDMA offload are sufficient to support the described performance and integration.
Reference graph
Works this paper leans on
-
[1]
Andersen, Peter Bailis, Magdalena Balazinska, Philip A
Daniel Abadi, Anastasia Ailamaki, David G. Andersen, Peter Bailis, Magdalena Balazinska, Philip A. Bernstein, Peter Boncz, Surajit Chaud- huri, Alvin Cheung, AnHai Doan, Luna Dong, Michael J. Franklin, Juliana Freire, Alon Y. Halevy, Joseph M. Hellerstein, Stratos Idreos, Donald Kossmann, Tim Kraska, Sailesh Krishnamurthy, Volker Markl, Sergey Melnik, Tov...
-
[2]
Advanced Micro Devices, Inc. 2024. AMD Pensando Software-in-Silicon Development Kit (SSDK). https://www.amd.com/content/dam/amd/ en/documents/pensando-technical-docs/product-briefs/pensando- ssdk-product-brief.pdf
2024
-
[3]
Papailiopoulos
Saurabh Agarwal, Hongyi Wang, Shivaram Venkataraman, and Dim- itris S. Papailiopoulos. 2022. On the Utility of Gradient Compression in Distributed Training Systems. (2022). https://proceedings.mlsys.or g/paper_files/paper/2022/hash/773862fcc2e29f650d68960ba5bd1101- Abstract.html
2022
-
[4]
Olasupo Ajayi and Ryan Grant. 2025. A Chronological Analysis of the Evolution of SmartNICs. CoRR abs/2512.04054 (2025). arXiv:2512.04054 doi:10.48550/ARXIV.2512.04054
-
[5]
Mohammad Al-Fares, Alexander Loukissas, and Amin Vahdat. 2008. A scalable, commodity data center network architecture. InProceedings of the ACM SIGCOMM 2008 Conference on Data Communication (Seattle, WA, USA) (SIGCOMM ’08). Association for Computing Machinery, New York, NY, USA, 63–74. doi: 10.1145/1402958.1402967
-
[6]
Amazon Web Services. 2022. The Components of the Nitro System (The Security Design of the A WS Nitro System Whitepaper). Technical Report. Amazon Web Services. https://docs.aws.amazon.com/whitepapers/la test/security-design-of-aws-nitro-system/the-components-of-the- nitro-system.html Accessed: 2026-04-15
2022
-
[7]
AMD. 2025. DMA/Bridge Subsystem for PCI Express Product Guide (PG195). https://docs.amd.com/r/en-US/pg195-pcie-dma
2025
-
[8]
AMD. 2025. Versal Adaptive SoC 600G Channelized Multirate Ethernet Subsystem (DCMAC) LogiCORE IP Product Guide (PG369). https: //docs.amd.com/r/en-US/pg369-dcmac/Introduction
2025
-
[9]
AMD. 2025. Versal Adaptive SoC CPM DMA and Bridge Mode for PCI Express v3.4. https://docs.amd.com/r/en-US/pg347-cpm-dma- bridge?tocId=oTd_ZrdYcOWw7fqmc3hb9g
2025
-
[10]
AMD. 2025. Vitis Networking P4. https://docs.amd.com/r/en- US/ug1308-vitis-p4-user-guide
2025
-
[11]
AMD Pensando. 2022. AMD Pensando Elba DPU (DSC-200) Product Overview. https://www.amd.com/en/products/data-processing- units/pensando.html
2022
-
[12]
AMD/Xilinx. 2021. OpenNIC: An Open-Source NIC Shell for Alveo FPGAs. GitHub. https://github.com/Xilinx/open-nic
2021
-
[13]
Kyle Aubrey and Farshad Ghodsian. 2026. Inside NVIDIA Groq 3 LPX: The Low-Latency Inference Accelerator for the NVIDIA Vera Rubin Platform. NVIDIA Technical Blog. https://developer.nvidia.com/blo g/inside-nvidia-groq-3-lpx-the-low-latency-inference-accelerator- for-the-nvidia-vera-rubin-platform/ Accessed: 2026-03-28
2026
-
[14]
John Bachan, Kaiming Ouyang, Misbah Mubarak, Thomas Gillis, Bruce Chang, Devendar Bureddy, Giuseppe Congiu, Keith Caton, Kyle Aubrey, and Xiaofan Li. 2025. Enabling Fast Inference and Resilient Training with NCCL 2.27. https://developer.nvidia.com/blog/enabling- fast-inference-and-resilient-training-with-nccl-2-27/
2025
-
[15]
Wei Bai, Shanim Sainul Abdeen, Ankit Agrawal, Krishan Kumar Attre, Paramvir Bahl, Ameya Bhagat, Gowri Bhaskara, Tanya Brokhman, Lei Cao, Ahmad Cheema, Rebecca Chow, Jeff Cohen, Mahmoud Elhaddad, Vivek Ette, Igal Figlin, Daniel Firestone, Mathew George, Ilya German, Lakhmeet Ghai, Eric Green, Albert G. Greenberg, Manish Gupta, Randy Haagens, Matthew Hendel...
2023
-
[16]
Tommaso Bonato, Abdul Kabbani, Ahmad Ghalayini, Anup Agarwal, Daniele De Sensi, Rong Pan, Costin Raiciu, Mark Handley, Mihai Brodschi, Timo Schneider, Nils Blach, Daniel Santos Ferreira Alves, and Torsten Hoefler. 2026. SMaRTT: Sender-based Marked Rapidly- adapting Trimmed & Timed Transport. (2026). arXiv:2404.01630 [cs.NI] https://arxiv.org/abs/2404.01630
-
[17]
Broadcom. 2019. Broadcom Stingray PS225 Dual-Port 25GbE PCIe Ethernet SmartNIC Data Sheet. https://www.broadcom.com/compa ny/news/product-releases/53106
2019
-
[18]
Marco Spaziani Brunella, Giacomo Belocchi, Marco Bonola, Salva- tore Pontarelli, Giuseppe Siracusano, Giuseppe Bianchi, Aniello Cam- marano, Alessandro Palumbo, Luca Petrucci, and Roberto Bifulco. 2020. hXDP: Efficient Software Packet Processing on FPGA NICs. In 14th USENIX Symposium on Operating Systems Design and Implementation, 12 OSDI 2020, Virtual Ev...
2020
-
[19]
https://www.usenix.org/conference/osdi20/presentation/brunella
-
[20]
Xuzheng Chen, Jie Zhang, Ting Fu, Yifan Shen, Shu Ma, Kun Qian, Lingjun Zhu, Chao Shi, Yin Zhang, Ming Liu, and Zeke Wang. 2024. Demystifying Datapath Accelerator Enhanced Off-path SmartNIC. In 32nd IEEE International Conference on Network Protocols, ICNP 2024, Charleroi, Belgium, October 28-31, 2024 . IEEE, 1–12. doi: 10.1109/ICNP 61940.2024.10858560
-
[21]
Alibaba Cloud Community. 2022. A Detailed Explanation about Al- ibaba Cloud CIPU. https://www.alibabacloud.com/blog/a-detailed- explanation-about-alibaba-cloud-cipu_599183
2022
-
[22]
Dan Daly, Jakub Kicinski, and Willem de Bruijn. 2023. OCP NIC Core Features Specification, Version 1.0. Technical Specification. Open Compute Project (OCP). https://www.opencompute.org/document s/ocp-server-nic-core-features-specification-ocp-spec-format-1-1- pdf Accessed: 2026-03-23
2023
-
[23]
Jonas Dann and Gustavo Alonso. 2026. Should I Hide My Duck in the Lake? CoRR abs/2602.18775 (2026). doi:10.48550/ARXIV.2602.18775
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.18775 2026
-
[24]
Jonas Dann, Royden Wagner, Daniel Ritter, Christian Faerber, and Holger Fröning. 2022. PipeJSON: Parsing JSON at Line Speed on FPGAs. In International Conference on Management of Data, DaMoN 2022, Philadelphia, PA, USA, 13 June 2022 , Spyros Blanas and Norman May (Eds.). ACM, 3:1–3:7. doi:10.1145/3533737.3535094
-
[25]
Tristan Döring, Henning Stubbe, and Kilian Holzinger. 2021. Smart- NICs: Current Trends in Research and Industry . Technical Report NET- 2021-05-1. Chair of Network Architectures and Services, Department of Informatics, Technical University of Munich. https://www.net.in.t um.de/fileadmin/TUM/NET/NET-2021-05-1/NET-2021-05-1_05.pdf
2021
-
[26]
Kfoury, Jose Gomez, and Jorge Crichigno
Sergio Elizalde, Ali AlSabeh, Ali Mazloum, Samia Choueiri, Elie F. Kfoury, Jose Gomez, and Jorge Crichigno. 2025. A survey on security applications with SmartNICs: Taxonomy, implementations, challenges, and future trends. J. Netw. Comput. Appl. 242 (2025), 104257. doi:10.1 016/J.JNCA.2025.104257
-
[27]
Caulfield, Eric S
Daniel Firestone, Andrew Putnam, Sambrama Mundkur, Derek Chiou, Alireza Dabagh, Mike Andrewartha, Hari Angepat, Vivek Bhanu, Adrian M. Caulfield, Eric S. Chung, Harish Kumar Chandrappa, Somesh Chaturmohta, Matt Humphrey, Jack Lavier, Norman Lam, Fengfen Liu, Kalin Ovtcharov, Jitu Padhye, Gautham Popuri, Shachar Raindel, Tejas Sapre, Mark Shaw, Gabriel Sil...
-
[28]
In 15th USENIX Symposium on Networked Systems Design and Im- plementation, NSDI 2018, Renton, W A, USA, April 9-11, 2018 , Sujata Banerjee and Srinivasan Seshan (Eds.)
Azure Accelerated Networking: SmartNICs in the Public Cloud. In 15th USENIX Symposium on Networked Systems Design and Im- plementation, NSDI 2018, Renton, W A, USA, April 9-11, 2018 , Sujata Banerjee and Srinivasan Seshan (Eds.). USENIX Association, 51–66. https://www.usenix.org/conference/nsdi18/presentation/firestone
2018
-
[29]
Snoeren, George Porter, and George Papen
Alex Forencich, Alex C. Snoeren, George Porter, and George Papen
-
[30]
Corundum: An Open-Source 100-Gbps Nic. In 28th IEEE Annual International Symposium on Field-Programmable Custom Computing Machines, FCCM 2020, Fayetteville, AR, USA, May 3-6, 2020. IEEE, 38–46. doi:10.1109/FCCM48280.2020.00015
-
[31]
fpgasystems. [n. d.]. GitHub - fpgasystems/fpga-network-stack: Scal- able Network Stack for FPGAs (TCP/IP, RoCEv2). https://github.com /fpgasystems/fpga-network-stack
-
[32]
Adithya Gangidi, Rui Miao, Shengbao Zheng, Sai Jayesh Bondu, Guilherme Goes, Hany Morsy, Rohit Puri, Mohammad Riftadi, Ashmitha Jeevaraj Shetty, Jingyi Yang, Shuqiang Zhang, Mikel Jimenez Fernandez, Shashidhar Gandham, and Hongyi Zeng. 2024. RDMA over Ethernet for Distributed Training at Meta Scale. In Proceedings of the ACM SIGCOMM 2024 Conference, ACM S...
-
[33]
Anqi Guo, Yuchen Hao, Xiteng Yao, Shining Yang, Jianyu Huang, Tony (Tong) Geng, and Martin Herbordt. 2025. SmartNIC-GPU- CPU Heterogeneous System for Large Machine Learning Model with Software-Hardware Codesign. In Proceedings of the 39th ACM Interna- tional Conference on Supercomputing (ICS ’25). Association for Com- puting Machinery, New York, NY, USA, ...
-
[34]
Zhenhao He, Dario Korolija, and Gustavo Alonso. 2021. EasyNet: 100 Gbps Network for HLS. In 31st International Conference on Field- Programmable Logic and Applications, FPL 2021, Dresden, Germany, August 30 - Sept. 3, 2021 . IEEE, 197–203. doi: 10.1109/FPL53798.2021.00 040
-
[35]
Zhenhao He, Dario Korolija, Yu Zhu, Benjamin Ramhorst, Tristan Laan, Lucian Petrica, Michaela Blott, and Gustavo Alonso. 2024. ACCL+: an FPGA-Based Collective Engine for Distributed Applications. In 18th USENIX Symposium on Operating Systems Design and Implementation, OSDI 2024, Santa Clara, CA, USA, July 10-12, 2024 , Ada Gavrilovska and Douglas B. Terry...
2024
- [36]
-
[37]
Torsten Hoefler, Duncan Roweth, Keith D. Underwood, Robert Alver- son, Mark Griswold, Vahid Tabatabaee, Mohan Kalkunte, Suren- dra Anubolu, Siyuan Shen, Moray McLaren, Abdul Kabbani, and Steve Scott. 2023. Data Center Ethernet and Remote Direct Mem- ory Access: Issues at Hyperscale. Computer 56, 7 (2023), 67–77. doi:10.1109/MC.2023.3261184
-
[38]
Underwood, Cedell Alexander, Bob Alverson, Paul Bottorff, Adrian M
Torsten Hoefler, Karen Schramm, Eric Spada, Keith D. Underwood, Cedell Alexander, Bob Alverson, Paul Bottorff, Adrian M. Caulfield, Mark Handley, Cathy Huang, Costin Raiciu, Abdul Kabbani, Eugene Opsasnick, Rong Pan, Adee Ran, and Rip Sohan. 2025. Ultra Ethernet’s Design Principles and Architectural Innovations. arXiv:2508.08906 doi:10.48550/ARXIV.2508.08906
-
[39]
Hongjing Huang, Jie Zhang, Xuzheng Chen, Ziyu Song, Jiajun Qin, and Zeke Wang. 2025. SwCC: Software-Programmable and Per-Packet Con- gestion Control in RDMA Engine. In Proceedings of the 2025 USENIX Annual Technical Conference, USENIX ATC 2025, Boston, MA, USA, July 7-9, 2025, Deniz Altinbüken and Ryan Stutsman (Eds.). USENIX Asso- ciation, 1243–1260. htt...
2025
-
[40]
IEEE. 2010. IEEE Standard for Information technology–Local and met- ropolitan area networks–Specific requirements–Part 3: CSMA/CD Access Method and Physical Layer Specifications Amendment 4: Media Access Control Parameters, Physical Layers, and Manage- ment Parameters for 40 Gb/s and 100 Gb/s Operation. 457 pages. doi:10.1109/IEEESTD.2010.5501740
-
[41]
IEEE. 2011. IEEE Standard for Local and metropolitan area networks– Media Access Control (MAC) Bridges and Virtual Bridged Local Area Networks–Amendment 17: Priority-based Flow Control. 40 pages. doi:10.1109/IEEESTD.2011.6032693
-
[42]
IEEE. 2017. IEEE Standard for Ethernet - Amendment 10: Media Access Control Parameters, Physical Layers, and Management Parameters for 200 Gb/s and 400 Gb/s Operation. 416 pages. doi: 10.1109/IEEESTD.20 17.8207825
-
[43]
Intel. 2022. Intel Infrastructure Processing Unit (Intel IPU) E2000. https://www.intel.com/content/www/us/en/products/details/netwo rk-io/ipu.html
2022
-
[44]
Ziheng Jiang, Haibin Lin, Yinmin Zhong, Qi Huang, Yangrui Chen, Zhi Zhang, Yanghua Peng, Xiang Li, Cong Xie, Shibiao Nong, Yulu Jia, Sun He, Hongmin Chen, Zhihao Bai, Qi Hou, Shipeng Yan, Ding Zhou, Yiyao Sheng, Zhuo Jiang, Haohan Xu, Haoran Wei, Zhang Zhang, Pengfei Nie, Leqi Zou, Sida Zhao, Liang Xiang, Zherui Liu, Zhe Li, Xiaoying Jia, Jianxi Ye, Xin J...
2024
- [45]
-
[46]
Svilen Kanev, Juan Pablo Darago, Kim Hazelwood, Parthasarathy Ran- ganathan, Tipp Moseley, Gu-Yeon Wei, and David Brooks. 2015. Pro- filing a warehouse-scale computer. In Proceedings of the 42nd Annual International Symposium on Computer Architecture (Portland, Oregon) (ISCA ’15). Association for Computing Machinery, New York, NY, USA, 158–169. doi: 10.11...
-
[47]
Kfoury, Samia Choueiri, Ali Mazloum, Ali AlSabeh, Jose Gomez, and Jorge Crichigno
Elie F. Kfoury, Samia Choueiri, Ali Mazloum, Ali AlSabeh, Jose Gomez, and Jorge Crichigno. 2024. A Comprehensive Survey on SmartNICs: Architectures, Development Models, Applications, and Research Di- rections. IEEE Access 12 (2024), 107297–107336. doi:10.1109/ACCESS.2 024.3437203
-
[48]
Dario Korolija, Timothy Roscoe, and Gustavo Alonso. 2020. Do OS abstractions make sense on FPGAs?. In 14th USENIX Symposium on Operating Systems Design and Implementation, OSDI 2020, Virtual Event, November 4-6, 2020. USENIX Association, 991–1010. https://www.us enix.org/conference/osdi20/presentation/roscoe
2020
-
[49]
Sakari Lahti and Timo D. Hämäläinen. 2025. High-Level Synthesis for FPGAs - A Hardware Engineer’s Perspective. IEEE Access 13 (2025), 28574–28593. doi: 10.1109/ACCESS.2025.3540320
-
[50]
Bojie Li, Kun Tan, Layong Larry Luo, Yanqing Peng, Renqian Luo, Ningyi Xu, Yongqiang Xiong, and Peng Cheng. 2016. ClickNP: Highly flexible and High-performance Network Processing with Reconfig- urable Hardware. In Proceedings of the ACM SIGCOMM 2016 Confer- ence, Florianopolis, Brazil, August 22-26, 2016 , Marinho P. Barcellos, Jon Crowcroft, Amin Vahdat,...
-
[51]
Jiayong Li, Jonas Dann, Zhenhao He, Gustavo Alonso, Sai Rahul Cha- lamalasetti, Dejan Milojicic, Lance Evans, Alex Veprinsky, and Runbin Shi. 2026. StreamDedup: Distributed In-line Deduplication for Disag- gregated Storage. ACM Trans. Reconfigurable Technol. Syst. (March 2026). doi: 10.1145/3799896
-
[52]
Junru Li, Youyou Lu, Qing Wang, Jiazhen Lin, Zhe Yang, and Jiwu Shu
-
[53]
In 2022 USENIX Annual Technical Conference (USENIX ATC 22)
AlNiCo: SmartNIC-accelerated Contention-aware Request Sched- uling for Transaction Processing. In 2022 USENIX Annual Technical Conference (USENIX ATC 22). USENIX Association, Carlsbad, CA, 951–
2022
-
[54]
https://www.usenix.org/conference/atc22/presentation/li-junru
-
[55]
Yuliang Li, Rui Miao, Hongqiang Harry Liu, Yan Zhuang, Fei Feng, Lingbo Tang, Zheng Cao, Ming Zhang, Frank Kelly, Mohammad Al- izadeh, and Minlan Yu. 2019. HPCC: high precision congestion control. In Proceedings of the ACM Special Interest Group on Data Communica- tion, SIGCOMM 2019, Beijing, China, August 19-23, 2019 , Jianping Wu and Wendy Hall (Eds.). ...
-
[56]
Will Lin, Yizhou Shan, Ryan Kosta, Arvind Krishnamurthy, and Yiying Zhang. 2024. SuperNIC: An FPGA-Based, Cloud-Oriented SmartNIC. In Proceedings of the 2024 ACM/SIGDA International Symposium on Field Programmable Gate Arrays, FPGA 2024, Monterey, CA, USA, March 3-5, 2024, Zhiru Zhang and Andrew Putnam (Eds.). ACM, 130–141. doi:10.1145/3626202.3637564
-
[57]
Linux RDMA. 2024. perftest – RDMA Performance Tests. https: //github.com/linux-rdma/perftest. Accessed: 04/15/2026
2024
-
[58]
Junyi Liu, Aleksandar Dragojević, Shane Fleming, Antonios Katsarakis, Dario Korolija, Igor Zablotchi, Ho-Cheung Ng, Anuj Kalia, and Miguel Castro. 2024. Honeycomb: Ordered Key-Value Store Acceleration on an FPGA-Based SmartNIC. IEEE Trans. Comput. 73, 3 (2024), 857–871. doi:10.1109/TC.2023.3345173
-
[59]
Ming Liu, Tianyi Cui, Henry Schuh, Arvind Krishnamurthy, Simon Peter, and Karan Gupta. 2019. Offloading distributed applications onto smartNICs using iPipe. InProceedings of the ACM Special Interest Group on Data Communication, SIGCOMM 2019, Beijing, China, August 19-23, 2019, Jianping Wu and Wendy Hall (Eds.). ACM, 318–333. doi:10.1145/ 3341302.3342079
-
[60]
Rui Ma, Evangelos Georganas, Alexander Heinecke, Sergey Gribok, Andrew Boutros, and Eriko Nurvitadhi. 2022. FPGA-Based AI Smart NICs for Scalable Distributed AI Training Systems. IEEE Computer Architecture Letters 21, 2 (2022), 49–52. doi: 10.1109/LCA.2022.3189207
-
[61]
MangoBoost. 2025. Mango BoostX ™ Programmable DPUs. https: //cdn.sanity.io/files/hx87iaks/production/ce5454fc6af423cd241b5784 3750527b05d29811.pdf. Accessed on 04/15/2026
2025
-
[62]
YoungGyoun Moon, SeungEon Lee, Muhammad Asim Jamshed, and KyoungSoo Park. 2020. AccelTCP: Accelerating Network Applica- tions with Stateful TCP Offloading. In 17th USENIX Symposium on Networked Systems Design and Implementation, NSDI 2020, Santa Clara, CA, USA, February 25-27, 2020 , Ranjita Bhagwan and George Porter (Eds.). USENIX Association, 77–92. htt...
2020
-
[63]
Javier Moya, Matthias Gabathuler, Mario Ruiz, and Gustavo Alonso
-
[64]
fpgasystems/hacc: ETHZ-HACC. Zenodo. doi: 10.5281/zenodo.8 340448 https://doi.org/10.5281/zenodo.8340448
-
[65]
NVIDIA. [n. d.]. GPUDirect RDMA and GPUDirect Storage — NVIDIA GPU Operator. https://docs.nvidia.com/datacenter/cloud-native/gpu- operator/25.3.1/gpu-operator-rdma.html#gpudirect-rdma-and- gpudirect-storage
-
[66]
NVIDIA. 2023. NVIDIA BlueField-3 DPU Data Sheet. https://www.nv idia.com/content/dam/en-zz/Solutions/Data-Center/documents/dat asheet-nvidia-bluefield-3-dpu.pdf
2023
-
[67]
NVIDIA Corporation. 2024. NVIDIA DOCA SDK. https://developer.nv idia.com/networking/doca Version 2.6.0, Accessed: 2026-03-24
2024
-
[68]
Oracle. 2025. Oracle Unveils Next-Generation Oracle Cloud Infras- tructure Zettascale10 Cluster for AI. Oracle Corporation. https: //www.oracle.com/news/announcement/ai-world-oracle-unveils- next-generation-oci-zettascale10-cluster-for-ai-2025-10-14/ Re- trieved March 25, 2026
2025
-
[69]
Sourav Panda, Yixiao Feng, Sameer G Kulkarni, K. K. Ramakrishnan, Nick Duffield, and Laxmi N. Bhuyan. 2021. SmartWatch: accurate traffic analysis and flow-state tracking for intrusion prevention us- ing SmartNICs. In Proceedings of the 17th International Conference on Emerging Networking EXperiments and Technologies (Virtual Event, Germany) (CoNEXT ’21). ...
-
[70]
Charles Papon. 2016. SpinalHDL Documentation. https://spinalhdl.gi thub.io/SpinalDoc-RTD/master/SpinalHDL/Introduction/SpinalHD L.html. Accessed: 2025-04-15
2016
-
[71]
Suchita Pati, Shaizeen Aga, Mahzabeen Islam, Nuwan Jayasena, and Matthew D. Sinclair. 2023. Tale of Two Cs: Computation vs. Commu- nication Scaling for Future Transformers on Future Hardware. In IEEE International Symposium on Workload Characterization, IISWC 2023, Ghent, Belgium, October 1-3, 2023 . IEEE, 140–153. doi: 10.1109/IISWC5 9245.2023.00026
-
[72]
Salvatore Pontarelli, Roberto Bifulco, Marco Bonola, Carmelo Cascone, Marco Spaziani Brunella, Valerio Bruschi, Davide Sanvito, Giuseppe Siracusano, Antonio Capone, Michio Honda, and Felipe Huici. 2019. FlowBlaze: Stateful Packet Processing in Hardware. In 16th USENIX Symposium on Networked Systems Design and Implementation, NSDI 2019, Boston, MA, Februar...
2019
-
[73]
Benjamin Ramhorst, Dario Korolija, Maximilian Jakob Heer, Jonas Dann, Luhao Liu, and Gustavo Alonso. 2025. Coyote v2: Raising the Level of Abstraction for Data Center FPGAs. InProceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles, SOSP 2025, Lotte Hotel World, Seoul, Republic of Korea, October 13-16, 2025 , Youjip 14 Won, Youngjin K...
-
[74]
Mario Ruiz, David Sidler, Gustavo Sutter, Gustavo Alonso, and Sergio López-Buedo. 2019. Limago: An FPGA-Based Open-Source 100 GbE TCP/IP Stack. In 29th International Conference on Field Programmable Logic and Applications, FPL 2019, Barcelona, Spain, September 8-12, 2019, Ioannis Sourdis, Christos-Savvas Bouganis, Carlos Álvarez, Leonel Antonio Toledo Día...
-
[75]
Rob Rydberg, Madison N. Emas, John Demme, Ana Ibarra, Kara Kagi, Brandon Klouchek, Abhijeet Lawande, Todd Massengill, David J. Pow- ers, and Andrew Putnam. 2026. Hyperscale FPGA Engineering Sys- tems at Microsoft. In Proceedings of the 2026 ACM/SIGDA International Symposium on Field Programmable Gate Arrays, FPGA 2026, Seaside, CA, USA, February 22-24, 20...
-
[76]
Leah Shalev, Hani Ayoub, Nafea Bshara, and Erez Sabbag. 2020. A Cloud-Optimized Transport Protocol for Elastic and Scalable HPC. IEEE Micro 40, 6 (2020), 67–73. doi: 10.1109/MM.2020.3016891
-
[77]
Rajath Shashidhara, Tim Stamler, Antoine Kaufmann, and Simon Peter
-
[78]
In 19th USENIX Symposium on Networked Systems Design and Imple- mentation, NSDI 2022, Renton, W A, USA, April 4-6, 2022, Amar Phan- ishayee and Vyas Sekar (Eds.)
FlexTOE: Flexible TCP Offload with Fine-Grained Parallelism. In 19th USENIX Symposium on Networked Systems Design and Imple- mentation, NSDI 2022, Renton, W A, USA, April 4-6, 2022, Amar Phan- ishayee and Vyas Sekar (Eds.). USENIX Association, 87–102. https: //www.usenix.org/conference/nsdi22/presentation/shashidhara
2022
-
[79]
David Sidler, Zeke Wang, Monica Chiosa, Amit Kulkarni, and Gustavo Alonso. 2020. StRoM: smart remote memory. In EuroSys ’20: Fifteenth EuroSys Conference 2020, Heraklion, Greece, April 27-30, 2020 , Angelos Bilas, Kostas Magoutis, Evangelos P. Markatos, Dejan Kostic, and Margo I. Seltzer (Eds.). ACM, 29:1–29:16. doi: 10.1145/3342195.3387519
-
[80]
Arjun Singhvi, Nandita Dukkipati, Prashant Chandra, Hassan M. G. Wassel, Naveen Kr. Sharma, Anthony Rebello, Henry Schuh, Praveen Kumar, Behnam Montazeri, Neelesh Bansod, Sarin Thomas, Inho Cho, Hyojeong Lee Seibert, Baijun Wu, Rui Yang, Yuliang Li, Kai Huang, Qianwen Yin, Abhishek Agarwal, Srinivas Vaduvatha, Wei- huang Wang, Masoud Moshref, Tao Ji, Davi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.