Recognition: unknown
Scepsy: Serving Agentic Workflows Using Aggregate LLM Pipelines
Pith reviewed 2026-05-10 09:50 UTC · model grok-4.3
The pith
Scepsy allocates GPUs to multi-LLM agentic workflows by modeling stable per-model execution time shares instead of unpredictable end-to-end paths.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By constructing an Aggregate LLM Pipeline from profiled execution-time shares, Scepsy can explore and select GPU allocations (fractional shares, tensor parallelism degrees, and replica counts) that achieve target throughput at low latency for arbitrary agentic workflows, then place those allocations on the cluster with a topology-aware heuristic.
What carries the argument
The Aggregate LLM Pipeline: a lightweight predictor assembled from stable per-LLM execution-time shares that estimates workflow latency and throughput for any combination of fractional GPU shares, tensor parallelism, and replica counts.
If this is right
- Allocations found via the predictor satisfy throughput targets while cutting end-to-end latency without requiring knowledge of exact workflow branches.
- Hierarchical placement of the chosen allocation reduces GPU fragmentation and respects network topology on real clusters.
- A single profiling pass per LLM suffices for repeated executions of the same workflow structure.
- The search over fractional shares and parallelism degrees can be performed quickly because the predictor is lightweight.
Where Pith is reading between the lines
- The same stability-of-shares idea could be applied to other composite systems whose stages have data-dependent durations but fixed relative costs.
- If the stability assumption weakens for some workflows, online re-profiling of shares could be added as a lightweight extension.
- The approach suggests a general principle for scheduling unpredictable multi-model pipelines: optimize on aggregate component costs rather than full-path simulation.
Load-bearing premise
The share of total execution time consumed by each LLM inside the workflow remains stable from one run to the next even when overall workflow duration varies.
What would settle it
Execute the same agentic workflow repeatedly with varied inputs and check whether the measured time proportion for any single LLM deviates substantially across runs.
Figures






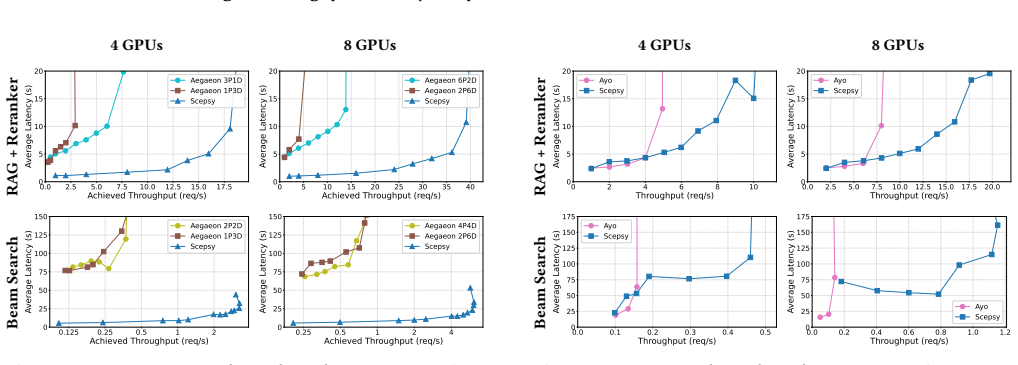


read the original abstract
Agentic workflows carry out complex tasks by orchestrating multiple large language models (LLMs) and tools. Serving such workflows at a target throughput with low latency is challenging because they can be defined using arbitrary agentic frameworks and exhibit unpredictable execution times: execution may branch, fan-out, or recur in data-dependent ways. Since LLMs in workflows often outnumber available GPUs, their execution also leads to GPU oversubscription. We describe Scepsy, a new agentic serving system that efficiently schedules arbitrary multi-LLM agentic workflows onto a GPU cluster. Scepsy exploits the insight that, while agentic workflows have unpredictable end-to-end latencies, the shares of each LLM's total execution times are comparatively stable across executions. Scepsy decides on GPU allocations based on these aggregate shares: first, it profiles the LLMs under different parallelism degrees. It then uses these statistics to construct an Aggregate LLM Pipeline, which is a lightweight latency/throughput predictor for allocations. To find a GPU allocation that minimizes latency while achieving a target throughput, Scepsy uses the Aggregate LLM Pipeline to explore a search space over fractional GPU shares, tensor parallelism degrees, and replica counts. It uses a hierarchical heuristic to place the best allocation onto the GPU cluster, minimizing fragmentation, while respecting network topology constraints. Our evaluation on realistic agentic workflows shows that Scepsy achieves up to 2.4x higher throughput and 27x lower latency compared to systems that optimize LLMs independently or rely on user-specified allocations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Scepsy, a serving system for arbitrary agentic workflows that orchestrate multiple LLMs and tools on GPU clusters. It observes that while end-to-end latencies are unpredictable due to data-dependent branching, fan-out, and recursion, the proportional shares of each LLM's execution time remain comparatively stable. Scepsy profiles LLMs under varying parallelism, builds an Aggregate LLM Pipeline as a lightweight latency/throughput predictor, searches over fractional GPU allocations, tensor parallelism degrees, and replica counts to meet target throughput at minimal latency, and applies a hierarchical heuristic for topology-aware placement. Evaluation on realistic workflows reports up to 2.4× higher throughput and 27× lower latency versus independent LLM optimization or user-specified allocations.
Significance. If the stability assumption and predictor accuracy hold under diverse inputs, Scepsy offers a practical approach to GPU oversubscription in multi-LLM serving, potentially improving efficiency for emerging agentic applications. The aggregate profiling and search-based allocation strategy is a concrete engineering contribution that could influence resource management in production LLM clusters, though its impact hinges on validation beyond the current evaluation scope.
major comments (3)
- [Abstract, §3] Abstract and §3: The load-bearing claim that 'the shares of each LLM's total execution times are comparatively stable across executions' lacks any quantitative bound on variance, description of input diversity in the profiled workflows, or ablation showing how prediction error in the Aggregate LLM Pipeline grows with share fluctuation. Without these, the 2.4× throughput and 27× latency gains rest on an untested extrapolation.
- [§5] §5: Workload definitions, baseline implementations (e.g., how 'systems that optimize LLMs independently' are realized), measurement methodology, statistical significance testing, and stability quantification are not detailed, preventing verification of the central performance claims from the text alone.
- [§4] §4: No ablation or sensitivity analysis is presented on how the hierarchical heuristic's placement decisions degrade when the Aggregate LLM Pipeline's predictions deviate from measured end-to-end behavior under branching or recursion.
minor comments (2)
- [§3.2] Clarify the exact construction of the Aggregate LLM Pipeline (e.g., how profiled statistics are aggregated into the predictor) with pseudocode or a small example.
- [§3.1] Add a table or figure summarizing the profiled LLMs, their parallelism degrees, and measured share variances across runs.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and will incorporate revisions to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3: The load-bearing claim that 'the shares of each LLM's total execution times are comparatively stable across executions' lacks any quantitative bound on variance, description of input diversity in the profiled workflows, or ablation showing how prediction error in the Aggregate LLM Pipeline grows with share fluctuation. Without these, the 2.4× throughput and 27× latency gains rest on an untested extrapolation.
Authors: We agree that the stability claim would be strengthened by explicit quantitative bounds and an ablation on prediction error. The manuscript profiles LLMs across multiple realistic workflows with varied inputs, but we will add variance statistics (e.g., coefficient of variation per LLM share) and a new figure showing how Aggregate LLM Pipeline error scales with share fluctuation. This will directly support the reported gains. revision: yes
-
Referee: [§5] §5: Workload definitions, baseline implementations (e.g., how 'systems that optimize LLMs independently' are realized), measurement methodology, statistical significance testing, and stability quantification are not detailed, preventing verification of the central performance claims from the text alone.
Authors: We acknowledge that §5 requires expansion for reproducibility. We will add precise workload definitions (including input distributions and agentic frameworks used), detailed descriptions of baseline implementations, full measurement methodology, and statistical significance results (e.g., t-tests or confidence intervals). Stability quantification will be integrated with the variance data from the first comment. revision: yes
-
Referee: [§4] §4: No ablation or sensitivity analysis is presented on how the hierarchical heuristic's placement decisions degrade when the Aggregate LLM Pipeline's predictions deviate from measured end-to-end behavior under branching or recursion.
Authors: The hierarchical heuristic incorporates topology awareness to limit sensitivity to moderate errors, but we agree an explicit ablation is needed. We will add a sensitivity analysis in the revised §4, injecting controlled prediction deviations (based on observed variances) and reporting impact on placement quality, fragmentation, and end-to-end latency/throughput. revision: yes
Circularity Check
No significant circularity; empirical profiling and search are self-contained
full rationale
The paper's core chain is profiling LLM execution shares under varying parallelism, constructing an Aggregate LLM Pipeline predictor from those measured shares, and using the predictor inside a search over fractional GPU allocations, tensor parallelism, and replicas. No equations, fitted parameters, or self-citations appear in the abstract or described method that would make any output equivalent to its inputs by construction. The stability of per-LLM shares is presented as an empirical observation used to justify the predictor, not as a definitional premise that tautologically produces the claimed throughput or latency gains. Performance numbers are obtained from direct evaluation against independent baselines, not from internal consistency of the predictor itself. This is a standard empirical systems paper whose claims rest on external measurement rather than on any self-referential derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Shares of each LLM's total execution times remain comparatively stable across different workflow executions
invented entities (1)
-
Aggregate LLM Pipeline
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Efficient Serving for Dynamic Agent Workflows with Prediction-based KV-Cache Management
PBKV predicts agent invocations in dynamic LLM workflows to manage KV-cache reuse, delivering up to 1.85x speedup over LRU and 1.26x over KVFlow.
Reference graph
Works this paper leans on
-
[1]
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav Gulavani, Alexey Tumanov, and Ramachandran Ram- jee. 2024. Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). USENIX Association, Santa Clara, CA, 117–134.https://www.usenix...
2024
-
[2]
Anthropic. 2023. Claude.https://www.anthropic.com/claude. Ac- cessed: 2026-03-08
2023
- [3]
-
[4]
Canonical. 2026. MicroK8s.https://canonical.com/microk8s. accessed 2026-03-22
2026
-
[5]
Lingjiao Chen, Matei Zaharia, and James Zou. 2024. FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance.Transactions on Machine Learning Research(2024).https: //openreview.net/forum?id=cSimKw5p6RFeatured Certification
2024
- [6]
-
[7]
János Csirik, Johannes Bartholomeus Gerardus Frenk, Martine Labbé, and Shuzhong Zhang. 1990. On the multidimensional vector bin packing.Acta Cybernetica9, 4 (1990), 361–369
1990
-
[8]
Jiangfei Duan, Runyu Lu, Haojie Duanmu, Xiuhong Li, Xingcheng Zhang, Dahua Lin, Ion Stoica, and Hao Zhang. 2024. MuxServe: Flexible Spatial-Temporal Multiplexing for Multiple LLM Serving. InProceed- ings of the 41st International Conference on Machine Learning (Pro- ceedings of Machine Learning Research, Vol. 235), Ruslan Salakhut- dinov, Zico Kolter, Kat...
2024
-
[9]
Yao Fu, Leyang Xue, Yeqi Huang, Andrei-Octavian Brabete, Dmitrii Ustiugov, Yuvraj Patel, and Luo Mai. 2024. ServerlessLLM: Low- Latency Serverless Inference for Large Language Models. In18th USENIX Symposium on Operating Systems Design and Implementa- tion (OSDI 24). USENIX Association, Santa Clara, CA, 135–153.https: //www.usenix.org/conference/osdi24/pr...
2024
-
[10]
Google. 2023. Gemini.https://gemini.google.com. Accessed: 2026-03- 08
2023
-
[11]
Alibaba Group. 2025. Aegaeon Artifact.https://zenodo.org/records/ 16673199. Accessed: 2026-03-20
2025
-
[12]
Mingcong Han, Hanze Zhang, Rong Chen, and Haibo Chen. 2022. Microsecond-scale Preemption for Concurrent GPU-accelerated DNN Inferences. In16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22). USENIX Association, Carlsbad, CA, 539– 558.https://www.usenix.org/conference/osdi22/presentation/han
2022
-
[13]
Connor Holmes, Masahiro Tanaka, Michael Wyatt, Ammar Ahmad Awan, Jeff Rasley, Samyam Rajbhandari, Reza Yazdani Aminabadi, Heyang Qin, Arash Bakhtiari, Lev Kurilenko, and Yuxiong He. 2024. DeepSpeed-FastGen: High-throughput Text Generation for LLMs via MII and DeepSpeed-Inference. arXiv:2401.08671 [cs.PF]https://arxiv. org/abs/2401.08671
- [14]
-
[15]
Hugging Face. 2024. Scaling Test-Time Compute.https://huggingface. co/spaces/HuggingFaceH4/blogpost-scaling-test-time-compute. Ac- cessed: 2026-03-20
2024
-
[16]
Hugging Face. 2024. Search and Learn.https://github.com/ huggingface/search-and-learn. Accessed: 2026-03-20
2024
-
[17]
Kamath, Ramya Prabhu, Jayashree Mohan, Simon Peter, Ramachandran Ramjee, and Ashish Panwar
Aditya K. Kamath, Ramya Prabhu, Jayashree Mohan, Simon Peter, Ramachandran Ramjee, and Ashish Panwar. 2025.POD-Attention: Unlocking Full Prefill-Decode Overlap for Faster LLM Inference. As- sociation for Computing Machinery, New York, NY, USA, 897–912. https://doi.org/10.1145/3676641.3715996
-
[18]
Kubernetes. 2014. Kubernetes.https://kubernetes.io/. Accessed: 2026-03-08
2014
-
[19]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Sto- ica. 2023. Efficient Memory Management for Large Language Model Serving with PagedAttention. InProceedings of the 29th Symposium on Operating Systems Principles(Koblenz, Germany)(SOSP ’23). As- sociation for Computing Machinery, New Yor...
-
[20]
LangChain. 2022. LangChain.https://www.langchain.com/. Accessed: 2026-03-08
2022
-
[21]
LangChain. 2024. LangGraph.https://www.langchain.com/langgraph. Accessed: 2026-03-26
2024
-
[22]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval- augmented generation for knowledge-intensive NLP tasks. InPro- ceedings of the 34th International Conference on Neural Information Processing Systems(...
2020
-
[23]
Guohao Li, Hasan Abed Al Kader Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. 2023. CAMEL: Communicative Agents for "Mind" Exploration of Large Language Model Society. In Thirty-seventh Conference on Neural Information Processing Systems
2023
-
[24]
Gonzalez, and Ion Stoica
Zhuohan Li, Lianmin Zheng, Yinmin Zhong, Vincent Liu, Ying Sheng, Xin Jin, Yanping Huang, Zhifeng Chen, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. AlpaServe: Statistical Multiplexing with Model Parallelism for Deep Learning Serving. In17th USENIX Symposium on Operating Systems Design and Implementation (OSDI 23). USENIX As- sociation, Boston, MA...
2023
-
[25]
Chaofan Lin, Zhenhua Han, Chengruidong Zhang, Yuqing Yang, Fan Yang, Chen Chen, and Lili Qiu. 2024. Parrot: Efficient Serving of LLM-based Applications with Semantic Variable. In18th USENIX Sym- posium on Operating Systems Design and Implementation (OSDI 24). USENIX Association, Santa Clara, CA, 929–945.https://www.usenix. org/conference/osdi24/presentati...
2024
-
[26]
Zejia Lin, Hongxin Xu, Guanyi Chen, Zhiguang Chen, Yutong Lu, and Xianwei Zhang. 2026. Bullet: Boosting GPU Utilization for LLM Serving via Dynamic Spatial-Temporal Orchestration. InProceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2(USA)(ASP- LOS ’26). Association for Com...
-
[27]
Jerry Liu. 2022. LlamaIndex.https://github.com/jerryjliu/llama_index
2022
-
[28]
arXiv preprint arXiv:2502.13965 , year =
Michael Luo, Xiaoxiang Shi, Colin Cai, Tianjun Zhang, Justin Wong, Yichuan Wang, Chi Wang, Yanping Huang, Zhifeng Chen, Joseph E. Gonzalez, and Ion Stoica. 2025. Autellix: An Efficient Serving Engine for LLM Agents as General Programs. arXiv:2502.13965 [cs.LG]https: //arxiv.org/abs/2502.13965
-
[29]
Cornfigurator: Automated Planning for Any-to-Any Multimodal Model Serving
Jeff J. Ma, Jae-Won Chung, Jisang Ahn, Yizhuo Liang, Akshay Jajoo, Myungjin Lee, and Mosharaf Chowdhury. 2025. Cornserve: Efficiently Serving Any-to-Any Multimodal Models. arXiv:2512.14098 [cs.LG] https://arxiv.org/abs/2512.14098
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [30]
- [31]
-
[32]
NetX-lab. 2025. Ayo Artifact.https://github.com/NetX-lab/Ayo. Ac- cessed: 2026-03-20. 13
2025
- [33]
-
[34]
NVIDIA. 2022. NVIDIA MPS.https://docs.nvidia.com/deploy/mps/ index.html. Accessed: 2026-03-08
2022
-
[35]
NVIDIA. 2022. Time-Sliced NVIDIA vGPU.https://docs.nvidia.com/ai- enterprise/release-7/latest/infra-software/vgpu/overview.html# nvidia-vgpu-architecture-overview. Accessed: 2026-03-20
2022
-
[36]
NVIDIA. 2026. NVIDIA Kubernetes device plugin: README, With CUDA Time-Slicing.https://github.com/NVIDIA/k8s-device-plugin/ blob/44345e3d/README.md#with-cuda-time-slicing. GitHub reposi- tory documentation, commit 44345e3d, accessed 2026-03-22
2026
-
[37]
2023.NVLink™Fabric High-Speed Interconnect White Paper
NVIDIA Corporation. 2023.NVLink™Fabric High-Speed Interconnect White Paper. Technical Report. NVIDIA Corporation.https://www. nvidia.com/en-gb/data-center/nvlink/White paper; GPU-GPU and switch interconnect
2023
-
[38]
OpenAI. 2022. ChatGPT.https://openai.com/chatgpt. Accessed: 2026-03-08
2022
-
[39]
Ruoyu Qin, Zheming Li, Weiran He, Jialei Cui, Feng Ren, Mingxing Zhang, Yongwei Wu, Weimin Zheng, and Xinran Xu. 2025. Moon- cake: Trading More Storage for Less Computation — A KVCache- centric Architecture for Serving LLM Chatbot. In23rd USENIX Confer- ence on File and Storage Technologies (FAST 25). USENIX Association, Santa Clara, CA, 155–170.https://w...
2025
-
[40]
RUC-NLPIR. 2024. FlashRAG.https://github.com/RUC-NLPIR/ FlashRAG. Accessed: 2026-03-20
2024
-
[41]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language models can teach themselves to use tools.Advances in neural information processing systems36 (2023), 68539–68551
2023
-
[42]
Amrith Setlur, Chirag Nagpal, Adam Fisch, Xinyang Geng, Jacob Eisen- stein, Rishabh Agarwal, Alekh Agarwal, Jonathan Berant, and Aviral Kumar. 2025. Rewarding Progress: Scaling Automated Process Verifiers for LLM Reasoning. InThe Thirteenth International Conference on Learn- ing Representations.https://openreview.net/forum?id=A6Y7AqlzLW
2025
-
[43]
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. 2024. Scaling llm test-time compute optimally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314(2024)
work page Pith review arXiv 2024
-
[44]
Foteini Strati, Xianzhe Ma, and Ana Klimovic. 2024. Orion: Interference-aware, Fine-grained GPU Sharing for ML Applications. In Proceedings of the Nineteenth European Conference on Computer Systems (Athens, Greece)(EuroSys ’24). Association for Computing Machinery, New York, NY, USA, 1075–1092. doi:10.1145/3627703.3629578
-
[45]
Qidong Su, Wei Zhao, Xin Li, Muralidhar Andoorveedu, Chen- hao Jiang, Zhanda Zhu, Kevin Song, Christina Giannoula, and Gennady Pekhimenko. 2025. Seesaw: High-throughput LLM In- ference via Model Re-sharding. InProceedings of Machine Learn- ing and Systems, M. Zaharia, G. Joshi, and Y. Lin (Eds.), Vol. 7. MLSys.https://proceedings.mlsys.org/paper_files/pap...
2025
-
[46]
2025.Towards End- to-End Optimization of LLM-based Applications with A yo
Xin Tan, Yimin Jiang, Yitao Yang, and Hong Xu. 2025.Towards End- to-End Optimization of LLM-based Applications with A yo. Association for Computing Machinery, New York, NY, USA, 1302–1316.https: //doi.org/10.1145/3676641.3716278
-
[47]
The AIBrix Team, Jiaxin Shan, Varun Gupta, Le Xu, Haiyang Shi, Jingyuan Zhang, Ning Wang, Linhui Xu, Rong Kang, Tongping Liu, Yifei Zhang, Yiqing Zhu, Shuowei Jin, Gangmuk Lim, Binbin Chen, Zuzhi Chen, Xiao Liu, Xin Chen, Kante Yin, Chak-Pong Chung, Chenyu Jiang, Yicheng Lu, Jianjun Chen, Caixue Lin, Wu Xiang, Rui Shi, and Liguang Xie. 2025. AIBrix: Towar...
-
[48]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. At- tention is all you need.Advances in neural information processing systems30 (2017)
2017
-
[49]
vllm-project. 2025. vLLM Production Stack.https://github.com/vllm- project/production-stack. Accessed: 2026-03-08
2025
-
[50]
Jiali Wang, Yankui Wang, Mingcong Han, and Rong Chen. 2025. Colo- cating ML inference and training with fast GPU memory handover. In Proceedings of the 2025 USENIX Conference on Usenix Annual Technical Conference(Boston, MA, USA)(USENIX ATC ’25). USENIX Association, USA, Article 98, 19 pages
2025
- [51]
-
[52]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompt- ing elicits reasoning in large language models.Advances in neural information processing systems35 (2022), 24824–24837
2022
-
[53]
Bingyang Wu, Shengyu Liu, Yinmin Zhong, Peng Sun, Xuanzhe Liu, and Xin Jin. 2024. LoongServe: Efficiently Serving Long-Context Large Language Models with Elastic Sequence Parallelism. InProceedings of the ACM SIGOPS 30th Symposium on Operating Systems Principles (Austin, TX, USA)(SOSP ’24). Association for Computing Machinery, New York, NY, USA, 640–654. ...
-
[54]
Bingyang Wu, Zili Zhang, Zhihao Bai, Xuanzhe Liu, and Xin Jin. 2023. Transparent GPU Sharing in Container Clouds for Deep Learning Workloads. In20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23). USENIX Association, Boston, MA, 69– 85.https://www.usenix.org/conference/nsdi23/presentation/wu
2023
-
[55]
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, et al. 2024. Autogen: Enabling next-gen LLM applications via multi-agent conver- sations. InFirst conference on language modeling
2024
-
[56]
Yuxing Xiang, Xue Li, Kun Qian, Yufan Yang, Diwen Zhu, Wenyuan Yu, Ennan Zhai, Xuanzhe Liu, Xin Jin, and Jingren Zhou. 2025. Aegaeon: Effective GPU Pooling for Concurrent LLM Serving on the Market. In Proceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles(Lotte Hotel World, Seoul, Republic of Korea)(SOSP ’25). Association for Computi...
-
[57]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations
2022
-
[58]
Minchen Yu, Ao Wang, Dong Chen, Haoxuan Yu, Xiaonan Luo, Zhuo- hao Li, Wei Wang, Ruichuan Chen, Dapeng Nie, Haoran Yang, and Yu Ding. 2025. Torpor: GPU-enabled serverless computing for low- latency, resource-efficient inference. InProceedings of the 2025 USENIX Conference on Usenix Annual Technical Conference(Boston, MA, USA) (USENIX ATC ’25). USENIX Asso...
2025
-
[59]
Shan Yu, Jiarong Xing, Yifan Qiao, Mingyuan Ma, Yangmin Li, Yang Wang, Shuo Yang, Zhiqiang Xie, Shiyi Cao, Ke Bao, Ion Stoica, Harry Xu, and Ying Sheng. 2025. Prism: Unleashing GPU Sharing for Cost- Efficient Multi-LLM Serving. arXiv:2505.04021 [cs.DC]https://arxiv. org/abs/2505.04021
-
[60]
Dingyan Zhang, Haotian Wang, Yang Liu, Xingda Wei, Yizhou Shan, Rong Chen, and Haibo Chen. 2025. BLITZSCALE: fast and live large model autoscaling with O(1) host caching. InProceedings of the 19th USENIX Conference on Operating Systems Design and Implementation (Boston, MA, USA)(OSDI ’25). USENIX Association, USA, Article 16, 19 pages
2025
- [61]
- [62]
-
[63]
Gonzalez, Clark Barrett, and Ying Sheng
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. 2024. SGLang: efficient execution of structured language model programs. InPro- ceedings of the 38th International Conference on Neural Information Processing Systems(Vancouver, BC,...
2024
-
[64]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xu- anzhe Liu, Xin Jin, and Hao Zhang. 2024. DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). USENIX Association, Santa Clara, CA, 193– 210.https://www.usenix.org/co...
2024
-
[65]
Andy Zhou, Kai Yan, Michal Shlapentokh-Rothman, Haohan Wang, and Yu-Xiong Wang. 2024. Language agent tree search unifies rea- soning, acting, and planning in language models. InProceedings of the 41st International Conference on Machine Learning(Vienna, Austria) (ICML’24). JMLR.org, Article 2572, 23 pages
2024
-
[66]
Kan Zhu, Yufei Gao, Yilong Zhao, Liangyu Zhao, Gefei Zuo, Yile Gu, Dedong Xie, Tian Tang, Qinyu Xu, Zihao Ye, Keisuke Kamahori, Chien- Yu Lin, Ziren Wang, Stephanie Wang, Arvind Krishnamurthy, and Baris Kasikci. 2025. NanoFlow: towards optimal large language model serving throughput. InProceedings of the 19th USENIX Conference on Operating Systems Design ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.