Recognition: 2 theorem links
· Lean TheoremCornfigurator: Automated Planning for Any-to-Any Multimodal Model Serving
Pith reviewed 2026-05-16 22:17 UTC · model grok-4.3
The pith
Cornfigurator automatically finds deployment plans for any-to-any multimodal models that match or exceed expert plans by up to 6.32 times in goodput.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
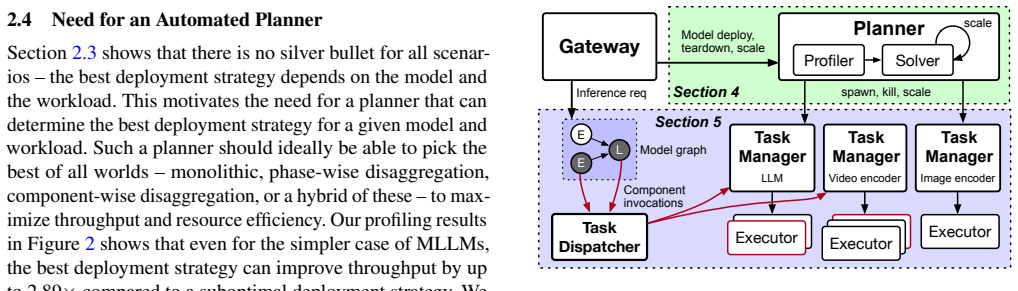
Cornfigurator is the first deployment planner for generic any-to-any model inference serving. The goal is to maximize overall goodput, defined as the throughput of requests meeting their latency targets. It does so by exploring the full spectrum of deployment strategies from colocation to disaggregation and mixing different strategies, using coarse-to-fine statistical evaluation based on model and workload characteristics to navigate the large space of candidate plans.
What carries the argument
Coarse-to-fine statistical evaluation that scores the space of colocation, disaggregation, and hybrid deployment strategies to maximize goodput.
If this is right
- Serving any-to-any models no longer requires manual expert tuning to reach high goodput.
- Plans can combine colocation and disaggregation rather than committing to a single extreme.
- Goodput improvements of 1.12x to 6.32x are achievable compared with current systems.
- The planner can handle the full combinatorial space of deployment options without exhaustive search.
Where Pith is reading between the lines
- The same statistical navigation method could be applied to serving other heterogeneous model families.
- Production systems might adopt periodic re-planning to adapt to shifting workloads or hardware availability.
- Resource cost per successful request could drop if goodput gains translate directly to fewer provisioned accelerators.
- The planner's output could serve as a starting point for online adaptation algorithms that adjust placements at runtime.
Load-bearing premise
The coarse-to-fine statistical evaluation accurately predicts real-world goodput for the full range of deployment strategies without requiring exhaustive execution or encountering unmodeled interference effects.
What would settle it
Run exhaustive real executions of every candidate deployment plan on a small any-to-any model and compare the measured goodput values against the goodput values predicted by Cornfigurator's statistical evaluation.
Figures









read the original abstract
Any-to-Any models are an emerging class of multimodal models that accept combinations of text and multimodal data as input and generate them as output, introducing heterogeneous computation paths and component scaling characteristics. There are existing mechanisms for deploying Any-to-Any models--or special cases of them--for inference serving, but they either require manual effort and expertise to tune, or do not generalize to generic Any-to-Any models. We present Cornfigurator, the first deployment planner for generic Any-to-Any model inference serving. The goal of Cornfigurator is to maximize the overall goodput of serving the model, defined as the throughput of requests meeting their latency targets. To do so, based on model and workload characteristics, Cornfigurator explores the full spectrum of deployment strategies, from colocation to disaggregation and mixing different strategies. Cornfigurator performs coarse-to-fine statistical evaluation to efficiently navigate the large space of candidate plans. Plans generated by Cornfigurator either match or deliver 1.12$\times$-6.32$\times$ higher goodput compared to existing systems and expert-tuned deployment plans.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Cornfigurator, the first automated deployment planner for generic Any-to-Any multimodal models. It explores the space of colocation, disaggregation, and hybrid deployment strategies for heterogeneous text/multimodal compute paths, using a coarse-to-fine statistical evaluation procedure to maximize goodput (defined as throughput of requests meeting latency targets). The central claim is that the generated plans match or exceed existing systems and expert-tuned plans by factors of 1.12×–6.32×.
Significance. If the evaluation holds, the work fills a practical gap by automating optimization for an emerging class of multimodal models whose heterogeneous scaling characteristics make manual tuning impractical. It could improve resource efficiency in inference serving without requiring domain expertise for each new model.
major comments (2)
- [Evaluation (abstract and §5)] The abstract and evaluation sections state performance gains from the planner but provide no details on the statistical evaluation method, workload traces, or controls for confounding factors. This leaves the central 1.12×–6.32× goodput claim only moderately supported, as the coarse-to-fine model must be shown to accurately predict real-world goodput for mixed strategies.
- [§4 (coarse-to-fine procedure) and evaluation] The skeptic concern is load-bearing: the headline gains rest on the assumption that the coarse-to-fine statistical model captures non-linear contention between heterogeneous compute paths in mixed colocation/disaggregation plans. No explicit validation against measured goodput for such mixed strategies is described, risking divergence from actual performance.
minor comments (2)
- [Introduction] Define 'goodput' explicitly in the introduction with its precise formula before using it in claims.
- [Abstract and results] The range 1.12×–6.32× should be accompanied by a table or text specifying the exact baseline systems, models, and workloads for each reported factor.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to improve clarity and strengthen the evaluation evidence.
read point-by-point responses
-
Referee: [Evaluation (abstract and §5)] The abstract and evaluation sections state performance gains from the planner but provide no details on the statistical evaluation method, workload traces, or controls for confounding factors. This leaves the central 1.12×–6.32× goodput claim only moderately supported, as the coarse-to-fine model must be shown to accurately predict real-world goodput for mixed strategies.
Authors: We agree that the abstract is too concise on methodology. Section 4 fully specifies the coarse-to-fine statistical procedure (including the contention model for heterogeneous paths), while §5.1 describes the workload traces (both synthetic and production-derived multimodal serving traces) and controls (repeated runs on fixed hardware, standardized latency targets, and isolation of deployment variables). To make this support explicit, we will add a one-sentence overview of the evaluation method to the abstract and expand the opening of §5 with a summary of the validation approach and confounding-factor controls. revision: yes
-
Referee: [§4 (coarse-to-fine procedure) and evaluation] The skeptic concern is load-bearing: the headline gains rest on the assumption that the coarse-to-fine statistical model captures non-linear contention between heterogeneous compute paths in mixed colocation/disaggregation plans. No explicit validation against measured goodput for such mixed strategies is described, risking divergence from actual performance.
Authors: This is a fair concern. While §5 reports end-to-end measured goodput for the final plans (including those that mix colocation and disaggregation) and shows they outperform baselines, we did not include a dedicated direct comparison of the statistical model's predictions versus measured goodput specifically on mixed-strategy configurations. We will add this validation in the revision: a new subsection in §5 with additional experiments that run a representative set of mixed plans, plot predicted versus observed goodput, and quantify prediction error to confirm the model captures the relevant non-linear contention effects. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper presents Cornfigurator as a search-based planner that enumerates colocation/disaggregation/hybrid strategies for Any-to-Any models and uses coarse-to-fine statistical evaluation to rank them by predicted goodput. Reported gains (1.12×–6.32×) are obtained by comparing the planner’s outputs against external baselines and expert-tuned plans; no equations, fitted parameters, or self-citations reduce these measured goodput values to quantities defined by the planner’s own inputs or prior self-referential results. The central claim therefore rests on external empirical comparison rather than internal self-definition or renaming.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
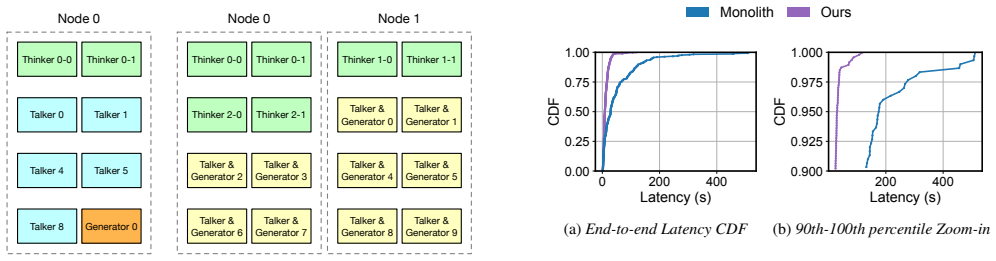
The planner formulates the disaggregation–colocation problem as an instance of the multicommodity network design problem... cell abstraction... power-of-two-sized GPU allocation
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
coarse-to-fine statistical evaluation to efficiently navigate the large space of candidate plans
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 4 Pith papers
-
Scepsy: Serving Agentic Workflows Using Aggregate LLM Pipelines
Scepsy schedules arbitrary multi-LLM agentic workflows on GPU clusters by constructing Aggregate LLM Pipelines from stable per-LLM execution time shares, then searching fractional GPU allocations, tensor parallelism, ...
-
GENSERVE: Efficient Co-Serving of Heterogeneous Diffusion Model Workloads
GENSERVE improves SLO attainment by up to 44% for co-serving heterogeneous T2I and T2V diffusion workloads via step-level preemption, elastic parallelism, and joint scheduling.
-
Cornserve: A Distributed Serving System for Any-to-Any Multimodal Models
Cornserve introduces a task abstraction and record-and-replay runtime for Any-to-Any multimodal models, achieving up to 3.81x higher throughput and 5.79x lower tail latency through component disaggregation and direct ...
-
Position: LLM Serving Needs Mathematical Optimization and Algorithmic Foundations, Not Just Heuristics
LLM serving requires mathematical optimization and algorithms with provable guarantees rather than generic heuristics that fail unpredictably on LLM workloads.
Reference graph
Works this paper leans on
-
[1]
KServe.https://github.com/kserve/kserve
-
[2]
llm-d: High Performance Distributed Inference on Ku- bernetes.https://github.com/llm-d/llm-d
-
[3]
https://www.nvidia.com/ en-gb/data-center/dgx-systems/
NVIDIA DGX Systems. https://www.nvidia.com/ en-gb/data-center/dgx-systems/
-
[4]
https://www.nvidia.com/ en-us/data-center/gb200-nvl72/
NVIDIA GB200 NVL72. https://www.nvidia.com/ en-us/data-center/gb200-nvl72/
-
[5]
NVIDIA NIM.https://docs.nvidia.com/nim/
- [6]
-
[7]
Approximate caching for efficiently serving text-to-image diffusion models
Shubham Agarwal, Subrata Mitra, Sarthak Chakraborty, Srikrishna Karanam, Koyel Mukherjee, and Shiv Ku- mar Saini. Approximate caching for efficiently serving text-to-image diffusion models. InProceedings of the 21st USENIX Symposium on Networked Systems Design and Implementation, NSDI’24, USA, 2024. USENIX Association
work page 2024
-
[8]
Taming throughput- latency tradeoff in LLM inference with Sarathi-Serve
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav Gulavani, Alexey Tu- manov, and Ramachandran Ramjee. Taming throughput- latency tradeoff in LLM inference with Sarathi-Serve. InOSDI, 2024
work page 2024
-
[9]
Springer International Publishing, Cham, 2021
Alper Atamtürk and Oktay Günlük.Multicommodity Multifacility Network Design, pages 141–166. Springer International Publishing, Cham, 2021
work page 2021
-
[10]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wen- bin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-VL technical report....
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Gonzalez, Matei Za- haria, and Ion Stoica
Shiyi Cao, Shu Liu, Tyler Griggs, Peter Schafhalter, Xi- aoxuan Liu, Ying Sheng, Joseph E. Gonzalez, Matei Za- haria, and Ion Stoica. Moe-lightning: High-throughput moe inference on memory-constrained gpus. InASP- LOS, 2025
work page 2025
-
[12]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, and Chong Ruan. Janus-pro: Unified multimodal understanding and gen- eration with data and model scaling.arXiv preprint arXiv:2501.17811, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Ma, Ruofan Wu, Jiachen Liu, Oh Jun Kweon, Yuxuan Xia, Zhiyu Wu, and Mosharaf Chowdhury
Jae-Won Chung, Jeff J. Ma, Ruofan Wu, Jiachen Liu, Oh Jun Kweon, Yuxuan Xia, Zhiyu Wu, and Mosharaf Chowdhury. The ML.ENERGY benchmark: Toward automated inference energy measurement and optimiza- tion.NeurIPS, 2025
work page 2025
-
[14]
Zach Evans, CJ Carr, Josiah Taylor, Scott H. Hawley, and Jordi Pons. Fast timing-conditioned latent audio dif- fusion. InProceedings of the 41st International Confer- ence on Machine Learning, ICML’24. JMLR.org, 2024
work page 2024
-
[15]
Jiarui Fang, Jinzhe Pan, Xibo Sun, Aoyu Li, and Jiannan Wang. xDiT: an inference engine for diffusion trans- formers (DiTs) with massive parallelism.arXiv preprint arXiv:2411.01738, 2024
-
[16]
Heyang Huang, Cunchen Hu, Jiaqi Zhu, Ziyuan Gao, Liangliang Xu, Yizhou Shan, Yungang Bao, Sun Ninghui, Tianwei Zhang, and Sa Wang. Ddit: Dynamic resource allocation for diffusion transformer model serv- ing.arXiv preprint arXiv:2506.13497, 2025
-
[17]
Prodiff: Progressive fast dif- fusion model for high-quality text-to-speech
Rongjie Huang, Zhou Zhao, Huadai Liu, Jinglin Liu, Chenye Cui, and Yi Ren. Prodiff: Progressive fast dif- fusion model for high-quality text-to-speech. InPro- ceedings of the 30th ACM International Conference on Multimedia, MM ’22, page 2595–2605, New York, NY , USA, 2022. Association for Computing Machinery
work page 2022
-
[18]
Le, Yonghui Wu, and Zhifeng Chen
Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Mia Xu Chen, Dehao Chen, HyoukJoong Lee, Jiquan Ngiam, Quoc V . Le, Yonghui Wu, and Zhifeng Chen. GPipe: Efficient training of giant neural networks using pipeline parallelism. InNeurIPS, 2019
work page 2019
-
[19]
Oobleck: Resilient distributed training of large models using pipeline templates
Insu Jang, Zhenning Yang, Zhen Zhang, Xin Jin, and Mosharaf Chowdhury. Oobleck: Resilient distributed training of large models using pipeline templates. In SOSP, 2023
work page 2023
-
[20]
NEO: Saving GPU memory crisis with CPU offloading for online LLM inference
Xuanlin Jiang, Yang Zhou, Shiyi Cao, Ion Stoica, and Minlan Yu. NEO: Saving GPU memory crisis with CPU offloading for online LLM inference. InEighth Conference on Machine Learning and Systems, 2025
work page 2025
-
[21]
Hans Kellerer, Ulrich Pferschy, and David Pisinger. Knapsack Problems. Springer Berlin Heidelberg, 2004
work page 2004
-
[22]
Efficient memory manage- ment for large language model serving with PagedAt- tention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory manage- ment for large language model serving with PagedAt- tention. InSOSP, 2023
work page 2023
-
[23]
Yejin Lee, Anna Sun, Basil Hosmer, Bilge Acun, Can Balioglu, Changhan Wang, Charles David Hernandez, 13 Christian Puhrsch, Daniel Haziza, Driss Guessous, Fran- cisco Massa, Jacob Kahn, Jeffrey Wan, Jeremy Reizen- stein, Jiaqi Zhai, Joe Isaacson, Joel Schlosser, Juan Pino, Kaushik Ram Sadagopan, Leonid Shamis, Linjian Ma, Min-Jae Hwang, Mingda Chen, Mostaf...
-
[24]
Audiolcm: Efficient and high-quality text-to-audio gen- eration with minimal inference steps
Huadai Liu, Rongjie Huang, Yang Liu, Hengyuan Cao, Jialei Wang, Xize Cheng, Siqi Zheng, and Zhou Zhao. Audiolcm: Efficient and high-quality text-to-audio gen- eration with minimal inference steps. InProceedings of the 32nd ACM International Conference on Multimedia, MM ’24, page 7008–7017, New York, NY , USA, 2024. Association for Computing Machinery
work page 2024
-
[25]
The llama 4 herd: The begin- ning of a new era of natively multimodal ai innovation
AI Meta. The llama 4 herd: The begin- ning of a new era of natively multimodal ai innovation. https://ai.meta.com/blog/ llama-4-multimodal-intelligence/, 2025
work page 2025
-
[26]
The power of two choices in randomized load balancing.IEEE Trans
Michael Mitzenmacher. The power of two choices in randomized load balancing.IEEE Trans. Parallel Dis- trib. Syst., 12(10), 2001
work page 2001
-
[27]
Efficient large-scale language model training on GPU clusters using Megatron-LM
Deepak Narayanan, Mohammad Shoeybi, Jared Casper, Patrick LeGresley, Mostofa Patwary, Vijay Korthikanti, Dmitri Vainbrand, Prethvi Kashinkunti, Julie Bernauer, Bryan Catanzaro, Amar Phanishayee, and Matei Zaharia. Efficient large-scale language model training on GPU clusters using Megatron-LM. InSC, 2021
work page 2021
-
[28]
Splitwise: Efficient generative llm inference using phase splitting
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. Splitwise: Efficient generative llm inference using phase splitting. InISCA, 2024
work page 2024
-
[29]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InICCV, 2023
work page 2023
-
[30]
Ruoyu Qin, Zheming Li, Weiran He, Jialei Cui, Feng Ren, Mingxing Zhang, Yongwei Wu, Weimin Zheng, and Xinran Xu. Mooncake: Trading more storage for less computation – a KVCache-centric architecture for serving LLM chatbot. InUSENIX FAST, 2025
work page 2025
-
[31]
ModServe: Scalable and resource-efficient large multimodal model serving
Haoran Qiu, Anish Biswas, Zihan Zhao, Jayashree Mo- han, Alind Khare, Esha Choukse, Íñigo Goiri, Zeyu Zhang, Haiying Shen, Chetan Bansal, Ramachandran Ramjee, and Rodrigo Fonseca. ModServe: Scalable and resource-efficient large multimodal model serving. arXiv preprint arXiv:2502.00937, 2025
-
[32]
Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He. Deepspeed: System optimizations enable training deep learning models with over 100 billion pa- rameters. InProceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 3505–3506, 2020
work page 2020
-
[33]
Flexgen: high-throughput generative inference of large language models with a single gpu
Ying Sheng, Lianmin Zheng, Binhang Yuan, Zhuohan Li, Max Ryabinin, Beidi Chen, Percy Liang, Christopher Ré, Ion Stoica, and Ce Zhang. Flexgen: high-throughput generative inference of large language models with a single gpu. InICML, 2023
work page 2023
-
[34]
Efficiently serving large multimodal models using EPD disaggregation
Gursimran Singh, Xinglu Wang, Yifan Hu, Timothy Tin Long Yu, Linzi Xing, Wei Jiang, Zhefeng Wang, Bai Xiaolong, Yi Li, Ying Xiong, Yong Zhang, and Zhenan Fan. Efficiently serving large multimodal models using EPD disaggregation. InICML, 2025
work page 2025
-
[35]
Powerinfer: Fast large language model serving with a consumer-grade gpu
Yixin Song, Zeyu Mi, Haotong Xie, and Haibo Chen. Powerinfer: Fast large language model serving with a consumer-grade gpu. InProceedings of the ACM SIGOPS 30th Symposium on Operating Systems Prin- ciples, SOSP ’24, page 590–606, New York, NY , USA,
-
[36]
Association for Computing Machinery
-
[37]
Llumnix: Dynamic scheduling for large language model serving
Biao Sun, Ziming Huang, Hanyu Zhao, Wencong Xiao, Xinyi Zhang, Yong Li, and Wei Lin. Llumnix: Dynamic scheduling for large language model serving. InOSDI, 2024
work page 2024
-
[38]
vLLM team. Disaggregated prefilling. https: //docs.vllm.ai/en/v0.12.0/features/disagg_ prefill/, 2025
work page 2025
-
[39]
WLB-LLM: Workload-balanced 4d parallelism for large language model training
Zheng Wang, Anna Cai, Xinfeng Xie, Zaifeng Pan, Yue Guan, Weiwei Chu, Jie Wang, Shikai Li, Jianyu Huang, Chris Cai, , Yuchen Hao, and Yufei Ding. WLB-LLM: Workload-balanced 4d parallelism for large language model training. InOSDI, 2025
work page 2025
-
[40]
Bingyang Wu, Shengyu Liu, Yinmin Zhong, Peng Sun, Xuanzhe Liu, and Xin Jin. Loongserve: Efficiently serv- ing long-context large language models with elastic se- quence parallelism. InSOSP, 2024
work page 2024
-
[41]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, Yuxiang Chen, Zecheng Tang, Zekai Zhang, Zhengyi Wang, An Yang, Bowen Yu, Chen Cheng, Dayiheng Liu, Deqing Li, Hang Zhang, Hao Meng, Hu Wei, Jingyuan Ni, Kai Chen, Kuan Cao, Liang Peng, Lin Qu, Minggang Wu, Peng Wang, Shuting Yu, Tingkun...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation
Chengyue Wu, Xiaokang Chen, Zhiyu Wu, Yiyang Ma, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, Chong Ruan, et al. Janus: Decoupling visual encoding for unified multimodal understanding and generation.arXiv preprint arXiv:2410.13848, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Modm: Efficient serving for image generation via mixture-of-diffusion models
Yuchen Xia, Divyam Sharma, Yichao Yuan, Souvik Kundu, and Nishil Talati. Modm: Efficient serving for image generation via mixture-of-diffusion models. arXiv preprint arXiv:2503.11972, 2025
-
[44]
ServeGen: Workload Characterization and Generation of Large Language Model Serving in Production
Yuxing Xiang, Xue Li, Kun Qian, Wenyuan Yu, Ennan Zhai, and Xin Jin. ServeGen: Workload characteriza- tion and generation of large language model serving in production.arXiv preprint arXiv:2505.09999, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, and Junyang Lin. Qwen2.5-Omni technical report.arXiv preprint arXiv:2503.20215, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, Yuanjun Lv, Yongqi Wang, Dake Guo, He Wang, Linhan Ma, Pei Zhang, Xinyu Zhang, Hongkun Hao, Zishan Guo, Baosong Yang, Bin Zhang, Ziyang Ma, Xipin Wei, Shuai Bai, Keqin Chen, Xue- jing Liu, Peng Wang, Mingkun Yang, Dayiheng Liu, Xingzhang Ren, B...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Yuanzhong Xu, HyoukJoong Lee, Dehao Chen, Blake Hechtman, Yanping Huang, Rahul Joshi, Maxim Krikun, Dmitry Lepikhin, Andy Ly, Marcello Maggioni, et al. GSPMD: general and scalable parallelization for ML computation graphs.arXiv preprint arXiv:2105.04663, 2021
-
[48]
Orca: A distributed serving system for Transformer-Based generative mod- els
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soo- jeong Kim, and Byung-Gon Chun. Orca: A distributed serving system for Transformer-Based generative mod- els. InOSDI, 2022
work page 2022
-
[49]
BLITZS- CALE: Fast and live large model autoscaling with o(1) host caching
Dingyan Zhang, Haotian Wang, Yang Liu, Xingda Wei, Yizhou Shan, Rong Chen, and Haibo Chen. BLITZS- CALE: Fast and live large model autoscaling with o(1) host caching. InOSDI, 2025
work page 2025
-
[50]
Lianmin Zheng, Zhuohan Li, Hao Zhang, Yonghao Zhuang, Zhifeng Chen, Yanping Huang, Yida Wang, Yuanzhong Xu, Danyang Zhuo, Eric P. Xing, Joseph E. Gonzalez, and Ion Stoica. Alpa: Automating inter- and Intra-Operator parallelism for distributed deep learning. InUSENIX OSDI, 2022
work page 2022
-
[51]
SGLang: Efficient Execution of Structured Language Model Programs
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Bar- rett, and Ying Sheng. Sglang: Efficient execution of structured language model programs.arXiv preprint arXiv:2312.07104, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
Dist- Serve: Disaggregating prefill and decoding for goodput- optimized large language model serving
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, and Hao Zhang. Dist- Serve: Disaggregating prefill and decoding for goodput- optimized large language model serving. InOSDI, 2024
work page 2024
-
[53]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Wei- jie Su, Jie Shao, Zhangwei Gao, Erfei Cui, Xuehui Wang, Yue Cao, Yangzhou Liu, Xingguang Wei, Hongjie Zhang, Haomin Wang, Weiye Xu, Hao Li, Jiahao Wang, Nianchen Deng, Songze Li, Yinan He, Tan Jiang, Jia- peng Luo, Yi Wang, Conghui He, Botian Shi, Xingchen...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
LLM” for Qwen Omni refers to the Thinker component. “Cached
Kan Zhu, Yufei Gao, Yilong Zhao, Liangyu Zhao, Gefei Zuo, Yile Gu, Dedong Xie, Tian Tang, Qinyu Xu, Zihao Ye, Keisuke Kamahori, Chien-Yu Lin, Ziren Wang, Stephanie Wang, Arvind Krishnamurthy, and Baris Kasikci. NanoFlow: Towards optimal large lan- guage model serving throughput. InOSDI, 2025. 15 A Multicommodity Network Design Problem with Network Topolog...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.