Recognition: unknown
R3D: Revisiting 3D Policy Learning
Pith reviewed 2026-05-10 10:54 UTC · model grok-4.3
The pith
Coupling a transformer 3D encoder with a diffusion decoder stabilizes large-scale 3D policy learning
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
3D policy learning promises superior generalization and cross-embodiment transfer, but progress has been hindered by training instabilities and severe overfitting, precluding the adoption of powerful 3D perception models. In this work, we systematically diagnose these failures, identifying the omission of 3D data augmentation and the adverse effects of Batch Normalization as primary causes. We propose a new architecture coupling a scalable transformer-based 3D encoder with a diffusion decoder, engineered specifically for stability at scale and designed to leverage large-scale pre-training. Our approach significantly outperforms state-of-the-art 3D baselines on challenging manipulation benchm
What carries the argument
Scalable transformer-based 3D encoder coupled with a diffusion decoder engineered for stability at scale and to leverage large-scale pre-training
If this is right
- significantly outperforms state-of-the-art 3D baselines on challenging manipulation benchmarks
- establishes a new and robust foundation for scalable 3D imitation learning
- promises superior generalization and cross-embodiment transfer
- allows adoption of powerful 3D perception models
Where Pith is reading between the lines
- The specific diagnosis of augmentation and normalization issues could guide fixes in other 3D vision-based learning systems.
- Emphasis on pre-training suggests value in building larger 3D datasets tailored to policy tasks.
- If the causes are correctly identified, incremental changes to prior methods might narrow much of the performance gap without a full redesign.
Load-bearing premise
The omission of 3D data augmentation and the adverse effects of batch normalization are the primary causes of instability and overfitting, and the proposed transformer-diffusion architecture resolves these issues at scale without new failure modes.
What would settle it
Training existing 3D policy baselines with added 3D data augmentation and without batch normalization, then comparing their performance to the new architecture on the same manipulation benchmarks.
Figures

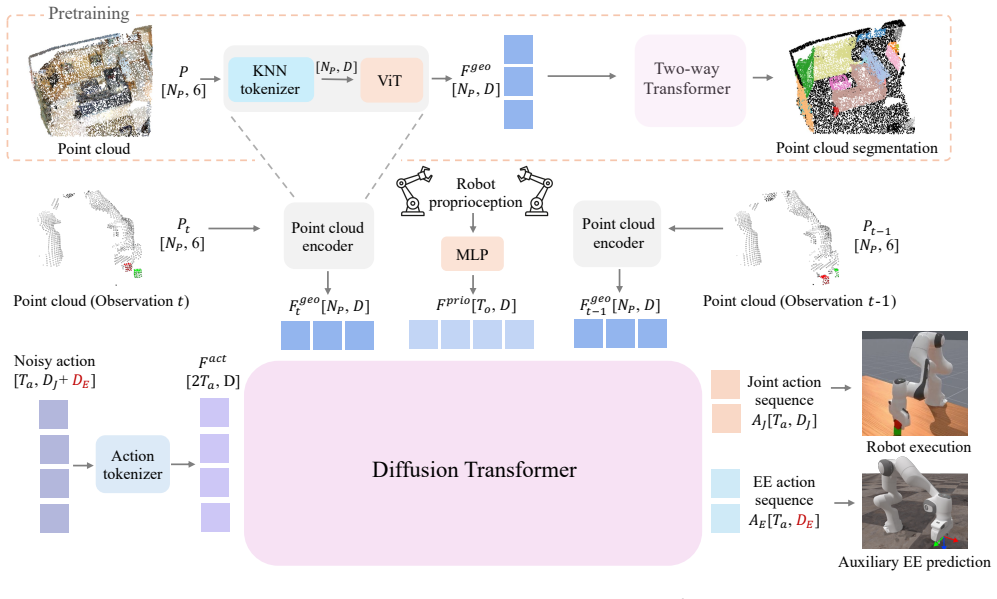
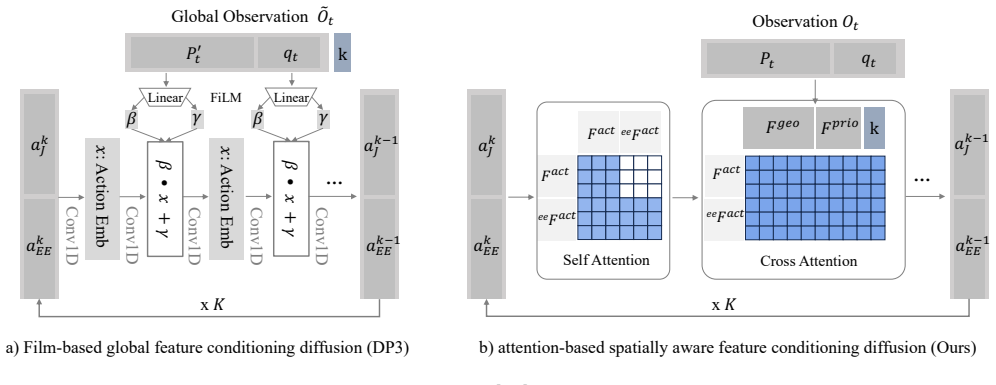



read the original abstract
3D policy learning promises superior generalization and cross-embodiment transfer, but progress has been hindered by training instabilities and severe overfitting, precluding the adoption of powerful 3D perception models. In this work, we systematically diagnose these failures, identifying the omission of 3D data augmentation and the adverse effects of Batch Normalization as primary causes. We propose a new architecture coupling a scalable transformer-based 3D encoder with a diffusion decoder, engineered specifically for stability at scale and designed to leverage large-scale pre-training. Our approach significantly outperforms state-of-the-art 3D baselines on challenging manipulation benchmarks, establishing a new and robust foundation for scalable 3D imitation learning. Project Page: https://r3d-policy.github.io/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper diagnoses instabilities and severe overfitting in 3D policy learning as stemming primarily from the omission of 3D data augmentation and the use of Batch Normalization. It introduces the R3D architecture, which pairs a scalable transformer-based 3D encoder with a diffusion-based decoder, designed for training stability at scale and compatibility with large-scale pre-training. The central empirical claim is that this approach significantly outperforms prior 3D baselines on challenging manipulation benchmarks, providing a robust foundation for scalable 3D imitation learning.
Significance. If the reported performance gains and ablation evidence hold under scrutiny, the work would address a key barrier to adopting expressive 3D perception models in imitation learning, potentially enabling better generalization and cross-embodiment transfer. The explicit focus on stability fixes (augmentation and normalization) plus an architecture suited to pre-training represents a constructive engineering contribution in a domain where empirical progress has been limited by training difficulties.
minor comments (3)
- The abstract and high-level description would be strengthened by including at least one or two key quantitative results (e.g., success rates or relative improvement percentages) alongside the qualitative claim of outperformance.
- Clarify the precise experimental protocol for the 3D data augmentation (types, magnitudes, and application schedule) and the exact modifications to Batch Normalization, as these are presented as the primary fixes.
- Ensure that all baseline comparisons control for training compute, data scale, and hyperparameter tuning effort to support the attribution of gains to the proposed architecture and fixes.
Simulated Author's Rebuttal
We thank the referee for their positive summary, significance assessment, and recommendation for minor revision. The referee accurately captures the core diagnosis of instabilities in 3D policy learning and the proposed R3D architecture. As the report contains no specific major comments to address, we have no point-by-point rebuttals at this stage.
Circularity Check
No significant circularity; empirical architecture proposal
full rationale
The paper is an empirical contribution that diagnoses training instabilities in 3D policy learning via omission of data augmentation and batch-norm effects, then proposes a transformer-based 3D encoder plus diffusion decoder for stability at scale. All central claims reduce to benchmark outperformance on manipulation tasks rather than any mathematical derivation, prediction, or first-principles result. No equations appear that could reduce a claimed output to a fitted input or self-referential definition by construction. Self-citations, if present, are not load-bearing for the architecture choice or performance claims. The work is therefore self-contained as an engineering and experimental advance.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Transformer and diffusion models can be stably trained on 3D point-cloud inputs when batch normalization is removed and 3D-specific augmentations are added.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2111.08897 (2021)
Baruch, G., Chen, Z., Dehghan, A., Dimry, T., Feigin, Y., Fu, P., Gebauer, T., Joffe, B., Kurz, D., Schwartz, A., et al.: Arkitscenes: A diverse real-world dataset for 3d indoor scene understanding using mobile rgb-d data. arXiv preprint arXiv:2111.08897 (2021) 7, 19
-
[2]
Bhat, V., Lan, Y.H., Krishnamurthy, P., Karri, R., Khorrami, F.: 3d cavla: Leveraging depth and 3d context to generalize vision language action models for unseen tasks. arXiv preprint arXiv:2505.05800 (2025) 3
-
[3]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Black, K., Brown, N., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., Groom, L., Hausman, K., Ichter, B., et al.: pi0: A vision-language-action flow model for general robot control. arXiv preprint arXiv:2410.24164 (2024) 1, 2, 12, 13, 21
work page internal anchor Pith review arXiv 2024
-
[4]
UniVLA: Learning to Act Anywhere with Task-centric Latent Actions
Bu, Q., Yang, Y., Cai, J., Gao, S., Ren, G., Yao, M., Luo, P., Li, H.: Univla: Learning to act anywhere with task-centric latent actions. arXiv preprint arXiv:2505.06111 (2025) 1, 2
work page internal anchor Pith review arXiv 2025
-
[5]
Chen, S., Liu, J., Qian, S., Jiang, H., Li, L., Zhang, R., Liu, Z., Gu, C., Hou, C., Wang, P., et al.: Ac-dit: Adaptive coordination diffusion transformer for mobile manipulation. arXiv preprint arXiv:2507.01961 (2025) 3
-
[6]
Chen, T., Chen, Z., Chen, B., Cai, Z., Liu, Y., Li, Z., Liang, Q., Lin, X., Ge, Y., Gu, Z., et al.: Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation. arXiv preprint arXiv:2506.18088 (2025) 3, 4, 8, 9, 10, 21
work page internal anchor Pith review arXiv 2025
-
[7]
The International Journal of Robotics Research44(10-11), 1684–1704 (2025) 1, 2, 5, 6, 10, 12, 13, 17, 21
Chi, C., Xu, Z., Feng, S., Cousineau, E., Du, Y., Burchfiel, B., Tedrake, R., Song, S.: Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research44(10-11), 1684–1704 (2025) 1, 2, 5, 6, 10, 12, 13, 17, 21
2025
-
[8]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Dai, A., Chang, A.X., Savva, M., Halber, M., Funkhouser, T., Nießner, M.: Scannet: Richly- annotated 3d reconstructions of indoor scenes. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 5828–5839 (2017) 7, 19
2017
-
[9]
scalable deep reinforcement learning for vision-based robotic manipulation
Dmitry, K., Alex, I., Peter, P., Julian, I., Alexander, H., Eric, J., Deirdre, Q., Ethan, H., Mri- nal, K., Vincent, V., et al.: Qt-opt. scalable deep reinforcement learning for vision-based robotic manipulation. arXiv preprint (2018) 4
2018
-
[10]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A.: An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020) 4, 6
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[11]
arXiv preprint arXiv:2503.03081 (2025) 20
Fang, H., Wang, C., Wang, Y., Chen, J., Xia, S., Lv, J., He, Z., Yi, X., Guo, Y., Zhan, X., et al.: Airexo-2: Scaling up generalizable robotic imitation learning with low-cost exoskeletons. arXiv preprint arXiv:2503.03081 (2025) 20
-
[12]
Act3d: Infinite resolution action detection transformer for robotic manipulation
Gervet, T., Xian, Z., Gkanatsios, N., Fragkiadaki, K.: Act3d: 3d feature field transformers for multi-task robotic manipulation. arXiv preprint arXiv:2306.17817 (2023) 3
-
[13]
arXiv preprint arXiv:2508.11002 (2025) 3
Gkanatsios, N., Xu, J., Bronars, M., Mousavian, A., Ke, T.W., Fragkiadaki, K.: 3d flowmatch actor: Unified 3d policy for single-and dual-arm manipulation. arXiv preprint arXiv:2508.11002 (2025) 3
-
[14]
In: Conference on Robot Learning
Goyal, A., Xu, J., Guo, Y., Blukis, V., Chao, Y.W., Fox, D.: Rvt: Robotic view transformer for 3d object manipulation. In: Conference on Robot Learning. pp. 694–710. PMLR (2023) 3
2023
-
[15]
Gu, J., Xiang, F., Li, X., Ling, Z., Liu, X., Mu, T., Tang, Y., Tao, S., Wei, X., Yao, Y., et al.: Man- iskill2: A unified benchmark for generalizable manipulation skills. arXiv preprint arXiv:2302.04659 (2023) 9, 10, 22
-
[16]
International Conference on Intelligent Robots and Systems (IROS) (2024) 18
Hong, Z., Zheng, K., Chen, L.: Fully automatic hand-eye calibration with pretrained image models. International Conference on Intelligent Robots and Systems (IROS) (2024) 18
2024
-
[17]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Hou, C., Ze, Y., Fu, Y., Gao, Z., Hu, S., Yu, Y., Zhang, S., Xu, H.: 4d visual pre-training for robot learning. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 8451–8461 (October 2025) 3
2025
-
[18]
Jia, Y., Liu, J., Chen, S., Gu, C., Wang, Z., Luo, L., Lee, L., Wang, P., Wang, Z., Zhang, R., et al.: Lift3d foundation policy: Lifting 2d large-scale pretrained models for robust 3d robotic manipulation. arXiv preprint arXiv:2411.18623 (2024) 3 14
-
[19]
3d diffuser actor: Policy diffusion with 3d scene representations, 2024
Ke, T.W., Gkanatsios, N., Fragkiadaki, K.: 3d diffuser actor: Policy diffusion with 3d scene repre- sentations. arXiv preprint arXiv:2402.10885 (2024) 1, 3
-
[20]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Kim, M.J., Finn, C., Liang, P.: Fine-tuning vision-language-action models: Optimizing speed and success. arXiv preprint arXiv:2502.19645 (2025) 2
work page internal anchor Pith review arXiv 2025
-
[21]
OpenVLA: An Open-Source Vision-Language-Action Model
Kim, M.J., Pertsch, K., Karamcheti, S., Xiao, T., Balakrishna, A., Nair, S., Rafailov, R., Foster, E., Lam, G., Sanketi, P., et al.: Openvla: An open-source vision-language-action model. arXiv preprint arXiv:2406.09246 (2024) 1, 2
work page internal anchor Pith review arXiv 2024
-
[22]
arXiv preprint arXiv:2503.07511 (2025)
Li, C., Wen, J., Peng, Y., Peng, Y., Feng, F., Zhu, Y.: Pointvla: Injecting the 3d world into vision- language-action models. arXiv preprint arXiv:2503.07511 (2025) 3
-
[23]
Li, F., Song, W., Zhao, H., Wang, J., Ding, P., Wang, D., Zeng, L., Li, H.: Spatial forcing: Implicit spatial representation alignment for vision-language-action model. arXiv preprint arXiv:2510.12276 (2025) 3, 10, 21
-
[24]
Bridgevla: Input-output alignment for efficient 3d manipulation learning with vision-language models
Li, P., Chen, Y., Wu, H., Ma, X., Wu, X., Huang, Y., Wang, L., Kong, T., Tan, T.: Bridgevla: Input-output alignment for efficient 3d manipulation learning with vision-language models. arXiv preprint arXiv:2506.07961 (2025) 3
-
[25]
Vision-language foundation models as effective robot imitators.arXiv preprint arXiv:2311.01378, 2023
Li, X., Liu, M., Zhang, H., Yu, C., Xu, J., Wu, H., Cheang, C., Jing, Y., Zhang, W., Liu, H., et al.: Vision-language foundation models as effective robot imitators. arXiv preprint arXiv:2311.01378 (2023) 2
-
[26]
arXiv preprint arXiv:2509.02530 (2025) 12, 18
Liu, M., Zhu, Z., Han, X., Hu, P., Lin, H., Li, X., Chen, J., Xu, J., Yang, Y., Lin, Y., et al.: Manipulation as in simulation: Enabling accurate geometry perception in robots. arXiv preprint arXiv:2509.02530 (2025) 12, 18
-
[27]
RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
Liu, S., Wu, L., Li, B., Tan, H., Chen, H., Wang, Z., Xu, K., Su, H., Zhu, J.: Rdt-1b: a diffusion foundation model for bimanual manipulation. arXiv preprint arXiv:2410.07864 (2024) 2, 10, 21
work page internal anchor Pith review arXiv 2024
-
[28]
Ni, Z., He, Y., Qian, L., Mao, J., Fu, F., Sui, W., Su, H., Peng, J., Wang, Z., He, B.: Vo-dp: Semantic-geometric adaptive diffusion policy for vision-only robotic manipulation. arXiv preprint arXiv:2510.15530 (2025) 3
-
[29]
In: 2024 IEEE International Conference on Robotics and Automation (ICRA)
O’Neill, A., Rehman, A., Maddukuri, A., Gupta, A., Padalkar, A., Lee, A., Pooley, A., Gupta, A., Mandlekar, A., Jain, A., et al.: Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In: 2024 IEEE International Conference on Robotics and Automation (ICRA). pp. 6892–6903. IEEE (2024) 1, 2
2024
-
[30]
In: Proceedings of the IEEE/CVF international conference on computer vision
Peebles, W., Xie, S.: Scalable diffusion models with transformers. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 4195–4205 (2023) 2, 7, 9
2023
-
[31]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Qi, C.R., Su, H., Mo, K., Guibas, L.J.: Pointnet: Deep learning on point sets for 3d classification and segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 652–660 (2017) 4, 6, 9
2017
-
[32]
Advances in neural information processing systems30(2017) 4
Qi, C.R., Yi, L., Su, H., Guibas, L.J.: Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Advances in neural information processing systems30(2017) 4
2017
-
[33]
arXiv preprint arXiv:2509.15733 (2025) 3
Qian, Q., Zhao, G., Zhang, G., Wang, J., Xu, R., Gao, J., Zhao, D.: Gp3: A 3d geometry-aware policy with multi-view images for robotic manipulation. arXiv preprint arXiv:2509.15733 (2025) 3
-
[34]
3d-mvp: 3d multi- view pretraining for robotic manipulation.arXiv preprint arXiv:2406.18158, 2024
Qian, S., Mo, K., Blukis, V., Fouhey, D.F., Fox, D., Goyal, A.: 3d-mvp: 3d multiview pretraining for robotic manipulation. arXiv preprint arXiv:2406.18158 (2024) 3
-
[35]
SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Model
Qu, D., Song, H., Chen, Q., Yao, Y., Ye, X., Ding, Y., Wang, Z., Gu, J., Zhao, B., Wang, D., et al.: Spatialvla: Exploring spatial representations for visual-language-action model. arXiv preprint arXiv:2501.15830 (2025) 3
work page internal anchor Pith review arXiv 2025
-
[36]
In: Conference on Robot Learning
Shridhar, M., Manuelli, L., Fox, D.: Perceiver-actor: A multi-task transformer for robotic manipu- lation. In: Conference on Robot Learning. pp. 785–799. PMLR (2023) 2
2023
-
[37]
Geovla: Em- powering 3d representations in vision-language-action models,
Sun, L., Xie, B., Liu, Y., Shi, H., Wang, T., Cao, J.: Geovla: Empowering 3d representations in vision-language-action models. arXiv preprint arXiv:2508.09071 (2025) 3
-
[38]
Octo: An Open-Source Generalist Robot Policy
Team, O.M., Ghosh, D., Walke, H., Pertsch, K., Black, K., Mees, O., Dasari, S., Hejna, J., Kreiman, T., Xu, C., et al.: Octo: An open-source generalist robot policy. arXiv preprint arXiv:2405.12213 (2024) 2 15
work page internal anchor Pith review arXiv 2024
-
[39]
Vuong, A.D., Vu, M.N., Reid, I.: Improving robotic manipulation with efficient geometry-aware vision encoder. arXiv preprint arXiv:2509.15880 (2025) 10, 21
-
[40]
Partnext: A next-generation dataset for fine-grained and hierarchical 3d part understanding
Wang, P., He, Y., Lv, X., Zhou, Y., Xu, L., Yu, J., Gu, J.: Partnext: A next-generation dataset for fine-grained and hierarchical 3d part understanding. arXiv preprint arXiv:2510.20155 (2025) 7, 19
-
[41]
Unleashing Large-Scale Video Generative Pre-training for Visual Robot Manipulation
Wu, H., Jing, Y., Cheang, C., Chen, G., Xu, J., Li, X., Liu, M., Li, H., Kong, T.: Unleashing large- scale video generative pre-training for visual robot manipulation. arXiv preprint arXiv:2312.13139 (2023) 2
work page internal anchor Pith review arXiv 2023
-
[42]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wu, X., Jiang, L., Wang, P.S., Liu, Z., Liu, X., Qiao, Y., Ouyang, W., He, T., Zhao, H.: Point transformer v3: Simpler faster stronger. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4840–4851 (2024) 1
2024
-
[43]
In: 2024 IEEE International Conference on Robotics and Automation (ICRA)
Xie, A., Lee, L., Xiao, T., Finn, C.: Decomposing the generalization gap in imitation learning for visual robotic manipulation. In: 2024 IEEE International Conference on Robotics and Automation (ICRA). pp. 3153–3160. IEEE (2024) 1
2024
-
[44]
arXiv preprint arXiv:2509.01819 (2025) 3, 9, 10, 12, 13, 21
Yan, G., Zhu, J., Deng, Y., Yang, S., Qiu, R.Z., Cheng, X., Memmel, M., Krishna, R., Goyal, A., Wang, X., et al.: Maniflow: A general robot manipulation policy via consistency flow training. arXiv preprint arXiv:2509.01819 (2025) 3, 9, 10, 12, 13, 21
-
[45]
Fp3: A 3d foundation policy for robotic manipulation.arXiv preprint arXiv:2503.08950, 2025
Yang, R., Chen, G., Wen, C., Gao, Y.: Fp3: A 3d foundation policy for robotic manipulation. arXiv preprint arXiv:2503.08950 (2025) 3
-
[46]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Yu, H., Jin, Y., He, Y., Sui, W.: Efficient task-specific conditional diffusion policies: Shortcut model acceleration and so (3) optimization. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 4174–4183 (2025) 2
2025
-
[47]
Yuan, T., Liu, Y., Lu, C., Chen, Z., Jiang, T., Zhao, H.: Depthvla: Enhancing vision-language- action models with depth-aware spatial reasoning. arXiv preprint arXiv:2510.13375 (2025) 3
-
[48]
arXiv e-prints pp
Ze,Y.,Chen,Z.,Wang,W.,Chen,T.,He,X.,Yuan,Y.,Peng,X.B.,Wu,J.:Generalizablehumanoid manipulation with improved 3d diffusion policies. arXiv e-prints pp. arXiv–2410 (2024) 1
2024
-
[49]
3D Diffusion Policy: Generalizable Visuomotor Policy Learning via Simple 3D Representations
Ze, Y., Zhang, G., Zhang, K., Hu, C., Wang, M., Xu, H.: 3d diffusion policy: Generalizable visuo- motor policy learning via simple 3d representations. arXiv preprint arXiv:2403.03954 (2024) 1, 3, 4, 6, 7, 10, 12, 13, 17, 21, 22
work page internal anchor Pith review arXiv 2024
-
[50]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Zhao, T.Z., Kumar, V., Levine, S., Finn, C.: Learning fine-grained bimanual manipulation with low-cost hardware. arXiv preprint arXiv:2304.13705 (2023) 1, 2
work page internal anchor Pith review arXiv 2023
-
[51]
arXiv preprint arXiv:2506.19269 (2025) 3
Zhao,Z.,Fan,K.,Xu,H.Y.,Qiao,N.,Peng,B.,Gao,W.,Li,D.,Shen,H.:Anchordp3:3daffordance guided sparse diffusion policy for robotic manipulation. arXiv preprint arXiv:2506.19269 (2025) 3
-
[52]
3D-VLA: A 3D Vision-Language-Action Generative World Model
Zhen, H., Qiu, X., Chen, P., Yang, J., Yan, X., Du, Y., Hong, Y., Gan, C.: 3d-vla: A 3d vision- language-action generative world model. arXiv preprint arXiv:2403.09631 (2024) 3
work page internal anchor Pith review arXiv 2024
-
[53]
Uni3d: Ex- ploring unified 3d representation at scale,
Zhou, J., Wang, J., Ma, B., Liu, Y.S., Huang, T., Wang, X.: Uni3d: Exploring unified 3d represen- tation at scale. arXiv preprint arXiv:2310.06773 (2023) 1, 4, 6, 9, 20
-
[54]
arXiv preprint arXiv:2406.17741 (2024)
Zhou, Y., Gu, J., Chiang, T.Y., Xiang, F., Su, H.: Point-sam: Promptable 3d segmentation model for point clouds. arXiv preprint arXiv:2406.17741 (2024) 1, 2, 5, 6, 7, 19
-
[55]
Zhu, H., Wang, Y., Huang, D., Ye, W., Ouyang, W., He, T.: Point cloud matters: Rethinking the impactofdifferentobservationspacesonrobotlearning.AdvancesinNeuralInformationProcessing Systems37, 77799–77830 (2024) 10, 22
2024
-
[56]
In: Con- ference on Robot Learning
Zitkovich, B., Yu, T., Xu, S., Xu, P., Xiao, T., Xia, F., Wu, J., Wohlhart, P., Welker, S., Wahid, A., et al.: Rt-2: Vision-language-action models transfer web knowledge to robotic control. In: Con- ference on Robot Learning. pp. 2165–2183. PMLR (2023) 1, 2 16 A More Real-world Experiments To further illustrate the performance of our approach across more ...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.