Recognition: unknown
The Synthetic Media Shift: Tracking the Rise, Virality, and Detectability of AI-Generated Multimodal Misinformation
Pith reviewed 2026-05-10 12:27 UTC · model grok-4.3
The pith
AI-generated misinformation on X spreads more virally through passive engagement and becomes harder to detect over time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
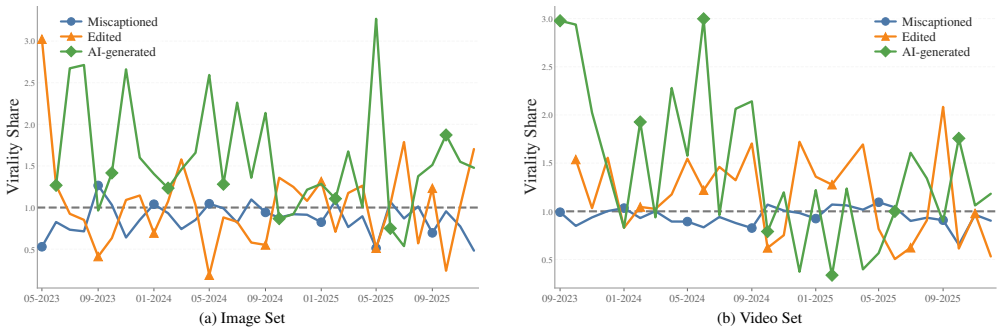
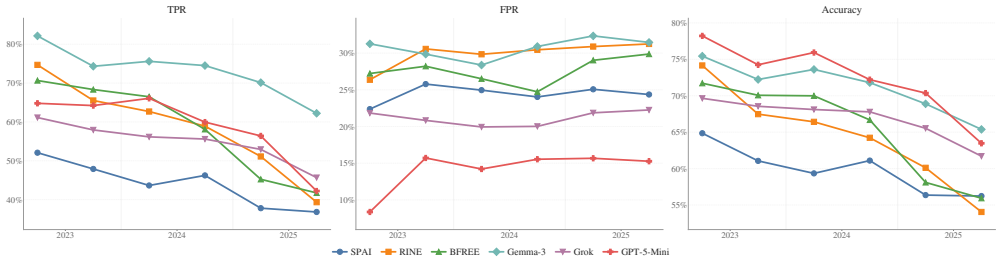
The central claim is that AI-generated visual misinformation in the CONVEX dataset exhibits disproportionate virality powered by passive engagement, faster consensus formation once reported, and a measurable decline in detectability by both dedicated classifiers and general vision-language models as generative capabilities advance.
What carries the argument
The CONVEX dataset of multimodal X posts with Community Notes labels and engagement metrics, used to measure virality ratios, reporting-to-consensus intervals, and temporal detector performance across AI-generated versus non-AI visual misinformation.
If this is right
- AI-generated content achieves higher overall engagement than miscaptioned or edited equivalents.
- Its spread depends more on passive actions such as likes and reposts than on active discourse.
- Community consensus forms more rapidly for AI content once it receives an initial note.
- Detection accuracy for both specialized models and vision-language models declines steadily across successive time windows.
- Continuous monitoring and periodic retraining of detectors are required to maintain effectiveness.
Where Pith is reading between the lines
- Platforms could prioritize signals of passive engagement for earlier throttling of synthetic posts.
- Community Notes may become a more reliable backstop as automated detectors degrade.
- New benchmark datasets will be needed at regular intervals to track and counter advancing generators.
- Widespread use of synthetic media could shift moderation emphasis toward contextual labeling over binary removal.
Load-bearing premise
Posts in the CONVEX dataset are correctly labeled as AI-generated rather than miscaptioned or edited, and Community Notes labels accurately reflect true misinformation without selection bias.
What would settle it
Re-testing the CONVEX images with detectors trained after the study's cutoff date and finding no drop in accuracy, or tracking a new wave of posts after a major generative-model release and observing no increase in relative virality, would refute the core trends.
Figures




read the original abstract
As generative AI advances, the distinction between authentic and synthetic media is increasingly blurred, challenging the integrity of online information. In this study, we present CONVEX, a large-scale dataset of multimodal misinformation involving miscaptioned, edited, and AI-generated visual content, comprising over 150K multimodal posts with associated notes and engagement metrics from X's Community Notes. We analyze how multimodal misinformation evolves in terms of virality, engagement, and consensus dynamics, with a focus on synthetic media. Our results show that while AI-generated content achieves disproportionate virality, its spread is driven primarily by passive engagement rather than active discourse. Despite slower initial reporting, AI-generated content reaches community consensus more quickly once flagged. Moreover, our evaluation of specialized detectors and vision-language models reveals a consistent decline in performance over time in distinguishing synthetic from authentic images as generative models evolve. These findings highlight the need for continuous monitoring and adaptive strategies in the rapidly evolving digital information environment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CONVEX, a large-scale dataset of over 150K multimodal posts from X's Community Notes, categorized as miscaptioned, edited, or AI-generated. It analyzes the evolution of multimodal misinformation focusing on synthetic media, reporting that AI-generated content has disproportionate virality driven by passive engagement, reaches community consensus more quickly once flagged despite slower initial reporting, and that detector performance declines over time as generative models evolve.
Significance. If the dataset classifications hold and the analyses are statistically sound, this study offers important insights into the virality and detectability of AI-generated misinformation. The large dataset and temporal analysis of detector performance could inform policy and technical strategies for combating synthetic media. The emphasis on passive engagement drivers is a notable contribution to understanding spread mechanisms.
major comments (3)
- [§3 (CONVEX Dataset)] §3 (CONVEX Dataset): The classification of content as AI-generated versus miscaptioned or edited is central to all headline results on virality, engagement, and detector decline. The description ties labels to Community Notes without detailing verification steps for generative artifacts, statistical controls, or handling of potential label noise. This risks conflating categories and confounding the reported trends.
- [§4 (Virality and Engagement Analysis)] §4 (Virality and Engagement Analysis): The claim that AI-generated content's spread is driven primarily by passive engagement lacks explicit definitions of passive vs. active engagement metrics and does not report error bars or significance tests for the disproportionate virality finding.
- [§5 (Detector Evaluation)] §5 (Detector Evaluation): The reported consistent decline in performance of specialized detectors and vision-language models over time is load-bearing for the conclusion on evolving generative models. However, without details on the specific time periods, exact models, sample sizes per period, or controls for dataset shifts, it is unclear if the decline is due to model evolution or other factors like label drift.
minor comments (2)
- [Abstract] The abstract could include key quantitative results, such as the exact virality ratios or performance drop percentages, to better summarize the findings.
- [Figures] Ensure all figures have clear legends and axis labels, particularly those showing temporal trends in detector performance.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which highlights important areas for clarification and strengthening in our manuscript. We address each major comment below and will make the indicated revisions to improve transparency and rigor.
read point-by-point responses
-
Referee: [§3 (CONVEX Dataset)] The classification of content as AI-generated versus miscaptioned or edited is central to all headline results on virality, engagement, and detector decline. The description ties labels to Community Notes without detailing verification steps for generative artifacts, statistical controls, or handling of potential label noise. This risks conflating categories and confounding the reported trends.
Authors: We agree that the current description in §3 lacks sufficient detail on the labeling process and potential noise. In the revised manuscript, we will expand this section to explicitly describe: how Community Notes are used to assign categories; our verification steps, including manual review of a sample of AI-generated posts for generative artifacts (e.g., lighting inconsistencies, unnatural features); any statistical filters or controls applied; and steps taken to mitigate label noise. These additions will provide greater transparency and support the validity of the categorizations underlying our analyses. revision: yes
-
Referee: [§4 (Virality and Engagement Analysis)] The claim that AI-generated content's spread is driven primarily by passive engagement lacks explicit definitions of passive vs. active engagement metrics and does not report error bars or significance tests for the disproportionate virality finding.
Authors: We acknowledge the need for explicit definitions and statistical support. We will revise §4 to define passive engagement (e.g., views and likes without comments or reposts) versus active engagement (e.g., replies, quote tweets, and shares) based on the X metrics available in the dataset. We will also add error bars to all figures showing virality and engagement metrics and report results from statistical tests (e.g., Mann-Whitney U tests) comparing categories to substantiate the disproportionate virality claim and its drivers. revision: yes
-
Referee: [§5 (Detector Evaluation)] The reported consistent decline in performance of specialized detectors and vision-language models over time is load-bearing for the conclusion on evolving generative models. However, without details on the specific time periods, exact models, sample sizes per period, or controls for dataset shifts, it is unclear if the decline is due to model evolution or other factors like label drift.
Authors: We will substantially expand §5 to include the requested details: specific time periods (e.g., quarterly or yearly bins), exact models and versions evaluated, sample sizes per period, and controls for dataset shifts (e.g., matching on content themes and engagement levels). We will also add discussion of potential label drift and how our labeling approach addresses it. These revisions will clarify that the performance decline is attributable to generative model evolution rather than confounding factors. revision: yes
Circularity Check
No circularity: purely observational analysis of external platform data
full rationale
The paper constructs the CONVEX dataset from X Community Notes posts and performs empirical measurements of virality, engagement patterns, consensus timing, and detector performance decline. No equations, derivations, fitted parameters, or self-referential definitions appear in the provided text. All headline claims rest on direct counts and comparisons against the collected external data rather than any reduction to inputs by construction, self-citation chains, or ansatz smuggling. This is a standard observational study whose central results are falsifiable against the raw platform data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Community Notes provide accurate and unbiased labels for multimodal misinformation
Reference graph
Works this paper leans on
-
[1]
Mul- timodal automated fact-checking: A survey
Mubashara Akhtar, Michael Schlichtkrull, Zhijiang Guo, Oana Cocarascu, Elena Simperl, and Andreas Vlachos. Mul- timodal automated fact-checking: A survey. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 5430–5448, 2023. 1, 2
2023
-
[2]
Factuality challenges in the era of large lan- guage models and opportunities for fact-checking.Nature Machine Intelligence, 6(8):852–863, 2024
Isabelle Augenstein, Timothy Baldwin, Meeyoung Cha, Tanmoy Chakraborty, Giovanni Luca Ciampaglia, David Corney, Renee DiResta, Emilio Ferrara, Scott Hale, Alon Halevy, et al. Factuality challenges in the era of large lan- guage models and opportunities for fact-checking.Nature Machine Intelligence, 6(8):852–863, 2024. 1, 2
2024
-
[3]
Isabelle Augenstein, Michiel Bakker, Tanmoy Chakraborty, David Corney, Emilio Ferrara, Iryna Gurevych, Scott Hale, Eduard Hovy, Heng Ji, Irene Larraz, et al. Community mod- eration and the new epistemology of fact checking on social media.arXiv preprint arXiv:2505.20067, 2025. 1, 2
-
[4]
The disinformation order: Disruptive communication and the decline of demo- cratic institutions.European journal of communication, 33 (2):122–139, 2018
W Lance Bennett and Steven Livingston. The disinformation order: Disruptive communication and the decline of demo- cratic institutions.European journal of communication, 33 (2):122–139, 2018. 1
2018
-
[5]
Verifying multimedia use at mediaeval 2015
Christina Boididou, Katerina Andreadou, Symeon Pa- padopoulos, Duc Tien Dang Nguyen, Giulia Boato, Michael Riegler, Yiannis Kompatsiaris, et al. Verifying multimedia use at mediaeval 2015. InMediaEval 2015. CEUR-WS,
2015
-
[6]
Verifying information with multime- dia content on twitter: a comparative study of automated approaches.Multimedia tools and applications, 77:15545– 15571, 2018
Christina Boididou, Stuart E Middleton, Zhiwei Jin, Symeon Papadopoulos, Duc-Tien Dang-Nguyen, Giulia Boato, and Yiannis Kompatsiaris. Verifying information with multime- dia content on twitter: a comparative study of automated approaches.Multimedia tools and applications, 77:15545– 15571, 2018. 2
2018
-
[7]
Nadav Borenstein, Greta Warren, Desmond Elliott, and Is- abelle Augenstein. Can community notes replace profes- sional fact-checkers? InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 535–552, 2025. 1, 2
2025
-
[8]
Did the roll-out of community notes reduce en- gagement with misinformation on x/twitter?Proceedings of the ACM on human-computer interaction, 8(CSCW2):1–52,
Yuwei Chuai, Haoye Tian, Nicolas Pr ¨ollochs, and Gabriele Lenzini. Did the roll-out of community notes reduce en- gagement with misinformation on x/twitter?Proceedings of the ACM on human-computer interaction, 8(CSCW2):1–52,
-
[9]
Supernotes: Driving consensus in crowd-sourced fact-checking
Soham De, Michiel A Bakker, Jay Baxter, and Martin Saveski. Supernotes: Driving consensus in crowd-sourced fact-checking. InProceedings of the ACM on Web Confer- ence 2025, pages 3751–3761, 2025. 2
2025
-
[10]
A survey of defenses against ai-generated visual media: Detection, disruption, and authentication.ACM Computing Surveys, 58(5):1–35, 2025
Jingyi Deng, Chenhao Lin, Zhengyu Zhao, Shuai Liu, Zhe Peng, Qian Wang, and Chao Shen. A survey of defenses against ai-generated visual media: Detection, disruption, and authentication.ACM Computing Surveys, 58(5):1–35, 2025. 1
2025
-
[11]
Infodemics and health misinformation: a systematic review of reviews.Bulletin of the World Health Organiza- tion, 100(9):544, 2022
Israel Junior Borges Do Nascimento, Ana Beatriz Pizarro, Jussara M Almeida, Natasha Azzopardi-Muscat, Mar- cos Andr´e Gonc ¸alves, Maria Bj¨orklund, and David Novillo- Ortiz. Infodemics and health misinformation: a systematic review of reviews.Bulletin of the World Health Organiza- tion, 100(9):544, 2022. 1
2022
-
[12]
AMMeBa: A large-scale survey and dataset of media-based misinformation in-the-wild,
Nicholas Dufour, Arkanath Pathak, Pouya Samangouei, Nikki Hariri, Shashi Deshetti, Andrew Dudfield, Christo- pher Guess, Pablo Hern´andez Escayola, Bobby Tran, Mevan Babakar, et al. Ammeba: A large-scale survey and dataset of media-based misinformation in-the-wild.arXiv preprint arXiv:2405.11697, 1(8), 2024. 1, 2
-
[13]
Multimodal disinformation about otherness on the in- ternet
Jos ´e Gamir-R´ıos, Raquel Tarullo, Miguel Ib´a˜nez-Cuquerella, et al. Multimodal disinformation about otherness on the in- ternet. the spread of racist, xenophobic and islamophobic fake news in 2020.An `alisi, pages 49–64, 2021. 1
2020
-
[14]
A bias-free training paradigm for more general ai-generated image de- tection
Fabrizio Guillaro, Giada Zingarini, Ben Usman, Avneesh Sud, Davide Cozzolino, and Luisa Verdoliva. A bias-free training paradigm for more general ai-generated image de- tection. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18685–18694, 2025. 2
2025
-
[15]
A survey on automated fact-checking.Transactions of the association for computational linguistics, 10:178–206, 2022
Zhijiang Guo, Michael Schlichtkrull, and Andreas Vlachos. A survey on automated fact-checking.Transactions of the association for computational linguistics, 10:178–206, 2022. 1
2022
-
[16]
A picture paints a thousand lies? the effects and mechanisms of multimodal disinformation and rebuttals disseminated via social media.Political com- munication, 37(2):281–301, 2020
Michael Hameleers, Thomas E Powell, Toni GLA Van Der Meer, and Lieke Bos. A picture paints a thousand lies? the effects and mechanisms of multimodal disinformation and rebuttals disseminated via social media.Political com- munication, 37(2):281–301, 2020. 2
2020
-
[17]
Can chatgpt detect deepfakes? a study of using mul- timodal large language models for media forensics
Shan Jia, Reilin Lyu, Kangran Zhao, Yize Chen, Zhiyuan Yan, Yan Ju, Chuanbo Hu, Xin Li, Baoyuan Wu, and Siwei Lyu. Can chatgpt detect deepfakes? a study of using mul- timodal large language models for media forensics. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4324–4333, 2024. 3
2024
-
[18]
Novel visual and statistical image features for mi- croblogs news verification.IEEE transactions on multime- dia, 19(3):598–608, 2016
Zhiwei Jin, Juan Cao, Yongdong Zhang, Jianshe Zhou, and Qi Tian. Novel visual and statistical image features for mi- croblogs news verification.IEEE transactions on multime- dia, 19(3):598–608, 2016. 2
2016
-
[19]
Multimodal fusion with recurrent neural networks for rumor detection on microblogs
Zhiwei Jin, Juan Cao, Han Guo, Yongdong Zhang, and Jiebo Luo. Multimodal fusion with recurrent neural networks for rumor detection on microblogs. InProceedings of the 25th ACM international conference on Multimedia, pages 795– 816, 2017. 2
2017
-
[20]
Who checks the checkers? exploring source credibility in twitter’s community notes.Journal of Computational Social Science, 9(1):24, 2026
Uku Kangur, Roshni Chakraborty, and Rajesh Sharma. Who checks the checkers? exploring source credibility in twitter’s community notes.Journal of Computational Social Science, 9(1):24, 2026. 2
2026
-
[21]
Evolution of detection performance throughout the online lifespan of synthetic images
Dimitrios Karageogiou, Quentin Bammey, Valentin Por- cellini, Bertrand Goupil, Denis Teyssou, and Symeon Pa- padopoulos. Evolution of detection performance throughout the online lifespan of synthetic images. InEuropean Con- ference on Computer Vision, pages 400–417. Springer, 2024. 2
2024
-
[22]
Any-resolution ai- generated image detection by spectral learning
Dimitrios Karageorgiou, Symeon Papadopoulos, Ioannis Kompatsiaris, and Efstratios Gavves. Any-resolution ai- generated image detection by spectral learning. InProceed- ings of the Computer Vision and Pattern Recognition Con- ference, pages 18706–18717, 2025. 2
2025
-
[23]
Leveraging rep- resentations from intermediate encoder-blocks for synthetic image detection
Christos Koutlis and Symeon Papadopoulos. Leveraging rep- resentations from intermediate encoder-blocks for synthetic image detection. InEuropean Conference on computer vi- sion, pages 394–411. Springer, 2024. 2
2024
-
[24]
Crowdsourced fact-checking or biased com- mentary? analyzing political bias in twitter’s community notes
Simon Fox Kuuse, Uku Kangur, Roshni Chakraborty, and Rajesh Sharma. Crowdsourced fact-checking or biased com- mentary? analyzing political bias in twitter’s community notes. InCompanion Proceedings of the ACM on Web Con- ference 2025, pages 2661–2669, 2025. 2
2025
-
[25]
Scaling human judgment in community notes with llms.arXiv preprint arXiv:2506.24118, 2025
Haiwen Li, Soham De, Manon Revel, Andreas Haupt, Brad Miller, Keith Coleman, Jay Baxter, Martin Saveski, and Michiel A Bakker. Scaling human judgment in community notes with llms.arXiv preprint arXiv:2506.24118, 2025. 2
-
[26]
Detecting multimedia generated by large ai models: A survey.arXiv preprint arXiv:2402.00045, 2024
Li Lin, Neeraj Gupta, Yue Zhang, Hainan Ren, Chun-Hao Liu, Feng Ding, Xin Wang, Xin Li, Luisa Verdoliva, and Shu Hu. Detecting multimedia generated by large ai models: A survey.arXiv preprint arXiv:2402.00045, 2024. 2
-
[27]
Newsclip- pings: Automatic generation of out-of-context multimodal media
Grace Luo, Trevor Darrell, and Anna Rohrbach. Newsclip- pings: Automatic generation of out-of-context multimodal media. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 6801–6817,
2021
-
[28]
Methods and trends in detecting ai-generated images: A comprehensive review
Arpan Mahara and Naphtali Rishe. Methods and trends in detecting ai-generated images: A comprehensive review. Computer Science Review, 60:100908, 2026. 2
2026
-
[29]
Crowds can effectively identify misinfor- mation at scale.Perspectives on Psychological Science, 19 (2):477–488, 2024
Cameron Martel, Jennifer Allen, Gordon Pennycook, and David G Rand. Crowds can effectively identify misinfor- mation at scale.Perspectives on Psychological Science, 19 (2):477–488, 2024. 2
2024
-
[30]
The creation and detection of deepfakes: A survey.ACM computing surveys (CSUR), 54(1):1–41, 2021
Yisroel Mirsky and Wenke Lee. The creation and detection of deepfakes: A survey.ACM computing surveys (CSUR), 54(1):1–41, 2021. 2
2021
-
[31]
Saeedeh Mohammadi, Narges Chinichian, Hannah Doyal, Kristina Skutilova, Hao Cui, Michele d’Errico, Siobhan Grayson, and Taha Yasseri. From birdwatch to community notes, from twitter to x: four years of community-based con- tent moderation.arXiv preprint arXiv:2510.09585, 2025. 2
-
[32]
Multimodal analytics for real-world news using measures of cross-modal entity con- sistency
Eric M ¨uller-Budack, Jonas Theiner, Sebastian Diering, Max- imilian Idahl, and Ralph Ewerth. Multimodal analytics for real-world news using measures of cross-modal entity con- sistency. InProceedings of the 2020 international confer- ence on multimedia retrieval, pages 16–25, 2020. 2
2020
-
[33]
Synthetic mis- informers: Generating and combating multimodal misinfor- mation
Stefanos-Iordanis Papadopoulos, Christos Koutlis, Symeon Papadopoulos, and Panagiotis Petrantonakis. Synthetic mis- informers: Generating and combating multimodal misinfor- mation. InProceedings of the 2nd ACM International Work- shop on Multimedia AI against Disinformation, pages 36–44,
-
[34]
Verite: a ro- bust benchmark for multimodal misinformation detection ac- counting for unimodal bias.International Journal of Multi- media Information Retrieval, 13(1):4, 2024
Stefanos-Iordanis Papadopoulos, Christos Koutlis, Symeon Papadopoulos, and Panagiotis C Petrantonakis. Verite: a ro- bust benchmark for multimodal misinformation detection ac- counting for unimodal bias.International Journal of Multi- media Information Retrieval, 13(1):4, 2024. 2
2024
-
[35]
Olesya Razuvayevskaya, Adel Tayebi, Ulrikke Dybdal Sørensen, Kalina Bontcheva, and Richard Rogers. Timeli- ness, consensus, and composition of the crowd: Community notes on x.arXiv preprint arXiv:2510.12559, 2025. 2
-
[36]
Cove: Context and veracity prediction for out-of-context im- ages
Jonathan Tonglet, Gabriel Thiem, and Iryna Gurevych. Cove: Context and veracity prediction for out-of-context im- ages. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computa- tional Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 2029–2049, 2025. 2
2025
-
[37]
Visual disinforma- tion in a digital age: A literature synthesis and research agenda.New Media & Society, 25(12):3696–3713, 2023
Teresa Weikmann and Sophie Lecheler. Visual disinforma- tion in a digital age: A literature synthesis and research agenda.New Media & Society, 25(12):3696–3713, 2023. 1, 2
2023
-
[38]
Future chal- lenges for online, crowdsourced content moderation: evi- dence from twitter’s community notes.Journal of Online Trust and Safety, 2(1), 2023
Valerie Wirtschafter and Sharanya Majumder. Future chal- lenges for online, crowdsourced content moderation: evi- dence from twitter’s community notes.Journal of Online Trust and Safety, 2(1), 2023. 1, 2
2023
-
[39]
Stefan Wojcik, Sophie Hilgard, Nick Judd, Delia Mocanu, Stephen Ragain, MB Hunzaker, Keith Coleman, and Jay Baxter. Birdwatch: Crowd wisdom and bridging algorithms can inform understanding and reduce the spread of misinfor- mation.arXiv preprint arXiv:2210.15723, 2022. 1, 2
-
[40]
End-to-end multimodal fact-checking and explanation generation: A challenging dataset and mod- els
Barry Menglong Yao, Aditya Shah, Lichao Sun, Jin-Hee Cho, and Lifu Huang. End-to-end multimodal fact-checking and explanation generation: A challenging dataset and mod- els. InProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 2733–2743, 2023. 2
2023
-
[41]
A survey on multimodal large language models.National Science Review, 11(12): nwae403, 2024
Shukang Yin, Chaoyou Fu, Sirui Zhao, Ke Li, Xing Sun, Tong Xu, and Enhong Chen. A survey on multimodal large language models.National Science Review, 11(12): nwae403, 2024. 3
2024
-
[42]
Fact- checking meets fauxtography: Verifying claims about im- ages
Dimitrina Zlatkova, Preslav Nakov, and Ivan Koychev. Fact- checking meets fauxtography: Verifying claims about im- ages. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th Inter- national Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2099–2108, 2019. 2
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.