Recognition: unknown
InfoChess: A Game of Adversarial Inference and a Laboratory for Quantifiable Information Control
Pith reviewed 2026-05-10 11:59 UTC · model grok-4.3
The pith
InfoChess is a game where the only way to score is by accurately guessing the opponent's hidden king position through controlled visibility.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose InfoChess, a symmetric adversarial game that elevates competitive information acquisition to the primary objective. There is no piece capture, removing material incentives that would otherwise confound the role of information. Instead, pieces are used to alter visibility. Players are scored on their probabilistic inference of the opponent's king location over the duration of the game. To explore the space of strategies for playing InfoChess, we introduce a hierarchy of heuristic agents defined by increasing levels of opponent modeling, and train a reinforcement learning agent that outperforms these baselines. Leveraging the discrete structure of the game, we analyze gameplay via a
What carries the argument
The action-induced observation channel, which determines how each move changes the visible board and thereby updates each player's belief distribution over the opponent's king location.
Load-bearing premise
The game mechanics of using pieces solely to alter visibility, combined with the inference-based scoring, successfully isolate information control as the dominant strategic element without introducing unaccounted confounding factors from board geometry or movement rules.
What would settle it
Running many games and checking whether agents that ignore king inference and instead optimize for other visible patterns still achieve high scores would show if the scoring truly isolates information control.
Figures


read the original abstract
We propose InfoChess, a symmetric adversarial game that elevates competitive information acquisition to the primary objective. There is no piece capture, removing material incentives that would otherwise confound the role of information. Instead, pieces are used to alter visibility. Players are scored on their probabilistic inference of the opponent's king location over the duration of the game. To explore the space of strategies for playing InfoChess, we introduce a hierarchy of heuristic agents defined by increasing levels of opponent modeling, and train a reinforcement learning agent that outperforms these baselines. Leveraging the discrete structure of the game, we analyze gameplay through natural information-theoretic characterizations that include belief entropy, oracle cross entropy, and predictive log score under the action-induced observation channel. These measures disentangle epistemic uncertainty, calibration mismatch, and uncertainty induced by adversarial movement. The design of InfoChess renders it a testbed for studying multi-agent inference under partial observability. We release code for the environment and agents, and a public interface to encourage further study.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes InfoChess, a symmetric adversarial game that prioritizes competitive information acquisition by eliminating piece capture and using pieces exclusively to modify visibility on a discrete board. Players receive scores based on the accuracy of their probabilistic inferences about the opponent's king location throughout the game. A hierarchy of heuristic agents with progressively deeper opponent modeling is defined, an RL agent is trained and shown to outperform these baselines, and information-theoretic metrics (belief entropy, oracle cross-entropy, and predictive log score under the action-induced observation channel) are introduced to disentangle epistemic uncertainty, calibration mismatch, and uncertainty arising from adversarial movement. The game is presented as a testbed for multi-agent inference under partial observability, with code and a public interface released.
Significance. If the isolation of information control holds and the metrics prove robust, InfoChess supplies a clean, quantifiable laboratory for studying adversarial inference and information theory in partially observable multi-agent systems. The explicit release of the environment, agents, and interface is a strength that supports reproducibility and community follow-up work. The RL outperformance result, if statistically solid, illustrates that learned strategies can exploit the information-centric objective beyond hand-crafted heuristics.
major comments (1)
- [Section 2 (Game Design)] Section 2 (Game Design): The central claim that InfoChess 'elevates competitive information acquisition to the primary objective' with 'no piece capture, removing material incentives' and pieces used 'solely to alter visibility' requires that board geometry and movement rules introduce no independent positional or visibility biases. The manuscript provides no ablation, symmetry analysis, or control experiment (e.g., fixed vs. randomized starting configurations or comparison across board sizes) to demonstrate separability of geometric effects from inference strategy. This is load-bearing for both the reported RL outperformance and the assertion that the three metrics cleanly disentangle the listed uncertainty sources.
minor comments (3)
- [Abstract and Section 4] The abstract and Section 4 (Analysis) would benefit from explicit equations or pseudocode for the three information-theoretic measures to make the disentanglement claim immediately verifiable.
- [Section 3 (Agents and Training)] The description of the RL training procedure (hyperparameters, observation space, reward shaping) is referenced but lacks sufficient detail for exact reproduction even with the released code.
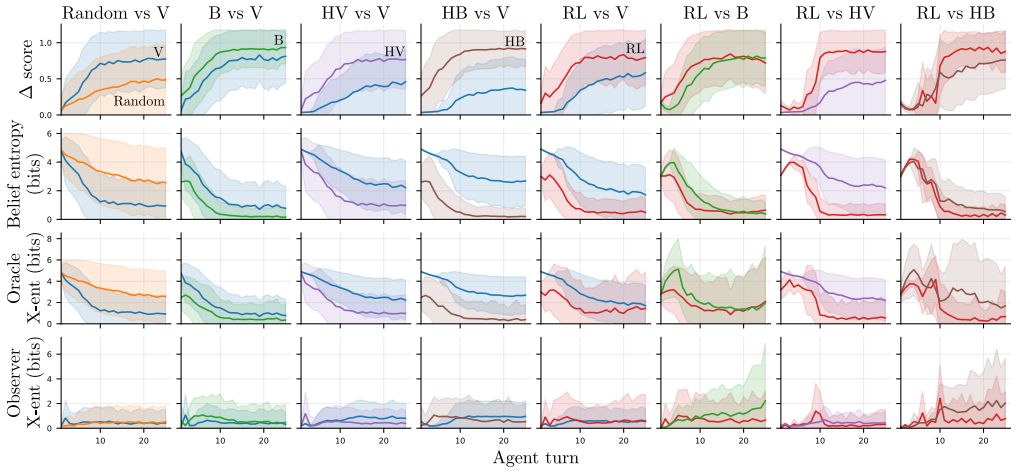
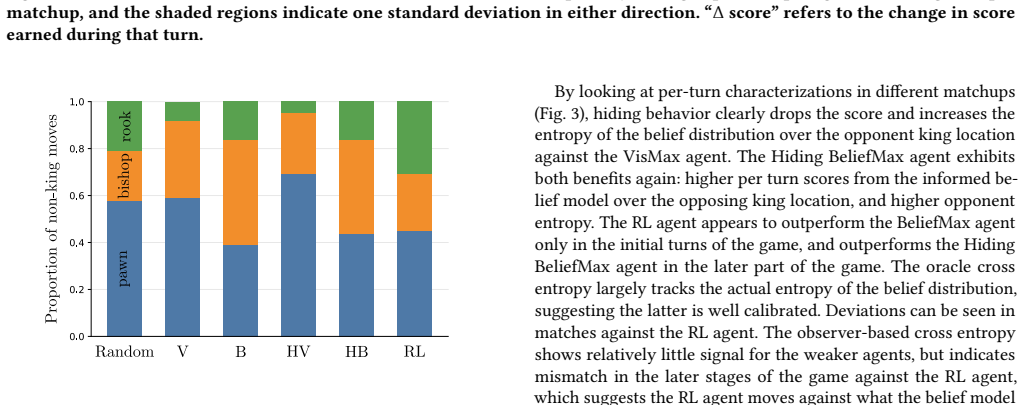
- [Figures in Section 4] Figure captions and axis labels in the gameplay analysis plots should explicitly state the number of episodes or trials averaged and any error bars used.
Simulated Author's Rebuttal
We thank the referee for the careful review and for highlighting the importance of validating that geometric factors do not confound the information-control objective in InfoChess. We address the single major comment below and commit to strengthening the manuscript accordingly.
read point-by-point responses
-
Referee: Section 2 (Game Design): The central claim that InfoChess 'elevates competitive information acquisition to the primary objective' with 'no piece capture, removing material incentives' and pieces used 'solely to alter visibility' requires that board geometry and movement rules introduce no independent positional or visibility biases. The manuscript provides no ablation, symmetry analysis, or control experiment (e.g., fixed vs. randomized starting configurations or comparison across board sizes) to demonstrate separability of geometric effects from inference strategy. This is load-bearing for both the reported RL outperformance and the assertion that the three metrics cleanly disentangle the listed uncertainty sources.
Authors: We agree that explicit verification of separability strengthens the central claims. InfoChess is constructed with complete symmetry: identical movement and visibility rules for both players, a uniform square grid, and randomized initial king placements that eliminate fixed positional advantages. Because every agent (heuristic and RL) experiences the identical geometry and observation model, performance differentials arise from differences in inference and opponent modeling rather than from board layout. The three metrics are defined relative to the action-induced observation channel, which directly encodes how each move alters visibility; belief entropy captures epistemic uncertainty in the current belief, oracle cross-entropy measures calibration to ground truth, and the predictive log score isolates the residual uncertainty attributable to adversarial movement. Nevertheless, the current manuscript does not contain the requested ablations. In the revision we will add: (i) a symmetry check demonstrating statistically equivalent results when player roles are exchanged, (ii) performance comparisons across board sizes (e.g., 6×6 and 8×8), and (iii) controlled experiments contrasting fixed versus randomized starting configurations. These additions will quantify any residual geometric contribution and confirm that the reported RL gains and metric interpretations remain valid. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper's central contribution is the definition of InfoChess as a new symmetric game with explicit mechanics (no capture, visibility alteration via pieces, scoring via probabilistic king inference). Heuristic agents are constructed by increasing opponent-modeling levels, an RL agent is trained to outperform them, and information-theoretic measures (belief entropy, oracle cross-entropy, predictive log score) are applied directly to the game's observation channel. None of these steps reduce by the paper's own equations or definitions to fitted parameters renamed as predictions, self-referential loops, or load-bearing self-citations. The analysis is a direct, non-circular application of standard information theory to the newly defined discrete state space, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Chess-like discrete board and movement rules provide a suitable structure for partial observability
- domain assumption Reinforcement learning can successfully train agents to optimize inference scores in this environment
invented entities (1)
-
InfoChess game
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Bowen Baker, Ingmar Kanitscheider, Todor Markov, Yi Wu, Glenn Powell, Bob McGrew, and Igor Mordatch. 2020. Emergent tool use from multi-agent autocur- ricula. InInternational conference on learning representations
2020
-
[2]
Nolan Bard, Jakob N Foerster, Sarath Chandar, Neil Burch, Marc Lanctot, H Francis Song, Emilio Parisotto, Vincent Dumoulin, Subhodeep Moitra, Edward Hughes, et al. 2020. The hanabi challenge: A new frontier for ai research.Artificial Intelligence280 (2020), 103216
2020
-
[3]
Christopher Berner, Greg Brockman, Brooke Chan, Vicki Cheung, Przemysław Dębiak, Christy Dennison, David Farhi, Quirin Fischer, Shariq Hashme, Chris Hesse, et al. 2019. Dota 2 with large scale deep reinforcement learning.arXiv preprint arXiv:1912.06680(2019)
work page internal anchor Pith review arXiv 2019
-
[4]
Noam Brown and Tuomas Sandholm. 2018. Superhuman AI for heads-up no-limit poker: Libratus beats top professionals.Science359, 6374 (2018), 418–424
2018
-
[5]
Noam Brown and Tuomas Sandholm. 2019. Superhuman AI for multiplayer poker.Science365, 6456 (2019), 885–890
2019
- [6]
-
[7]
1999.Elements of information theory
Thomas M Cover and Joy A Thomas. 1999.Elements of information theory. John Wiley & Sons
1999
-
[8]
Elizabeth Gilmour, Noah Plotkin, and Leslie N Smith. 2021. An approach to partial observability in games: Learning to both act and observe. In2021 IEEE Conference on Games (CoG). IEEE, 01–05
2021
-
[9]
Tilmann Gneiting and Adrian E Raftery. 2007. Strictly proper scoring rules, prediction, and estimation.Journal of the American statistical Association102, 477 (2007), 359–378
2007
- [10]
-
[11]
Leslie Pack Kaelbling, Michael L Littman, and Anthony R Cassandra. 1998. Plan- ning and acting in partially observable stochastic domains.Artificial intelligence 101, 1-2 (1998), 99–134
1998
-
[12]
Julien Perolat, Bart De Vylder, Daniel Hennes, Eugene Tarassov, Florian Strub, Vincent de Boer, Paul Muller, Jerome T Connor, Neil Burch, Thomas Anthony, et al
-
[13]
Mastering the game of Stratego with model-free multiagent reinforcement learning.Science378, 6623 (2022), 990–996
2022
-
[14]
2000.Popular chess variants
David Brine Pritchard. 2000.Popular chess variants. Batsford
2000
-
[15]
Freddie Bickford Smith, Andreas Kirsch, Sebastian Farquhar, Yarin Gal, Adam Foster, and Tom Rainforth. 2023. Prediction-oriented bayesian active learning. In International conference on artificial intelligence and statistics. PMLR, 7331–7348
2023
-
[16]
Oriol Vinyals, Igor Babuschkin, Wojciech M Czarnecki, Michaël Mathieu, An- drew Dudzik, Junyoung Chung, David H Choi, Richard Powell, Timo Ewalds, Petko Georgiev, et al. 2019. Grandmaster level in StarCraft II using multi-agent reinforcement learning.nature575, 7782 (2019), 350–354
2019
-
[17]
Ronald J Williams. 1992. Simple statistical gradient-following algorithms for connectionist reinforcement learning.Machine learning8, 3 (1992), 229–256
1992
- [18]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.