Recognition: unknown
Seeing the imagined: a latent functional alignment in visual imagery decoding from fMRI data
Pith reviewed 2026-05-10 11:41 UTC · model grok-4.3
The pith
Latent functional alignment improves reconstruction of imagined scenes from fMRI by mapping imagery signals into a perception decoder's conditioning space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
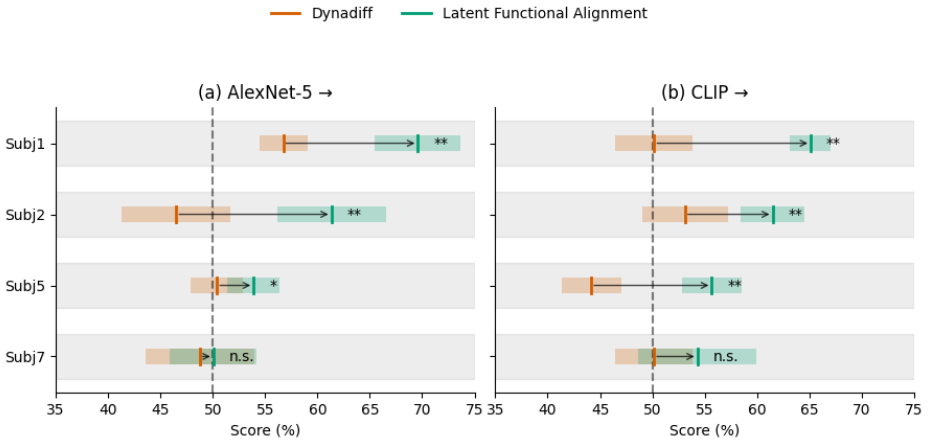
Latent functional alignment maps imagery-evoked fMRI activity into the conditioning space of a frozen pretrained perception decoder (DynaDiff) and augments training with retrieval of semantically related perception trials; this yields consistent gains in high-level semantic reconstruction metrics on the Imagery-NSD benchmark relative to the frozen baseline and a voxel-space ridge baseline, and supports above-chance decoding from multiple cortical regions.
What carries the argument
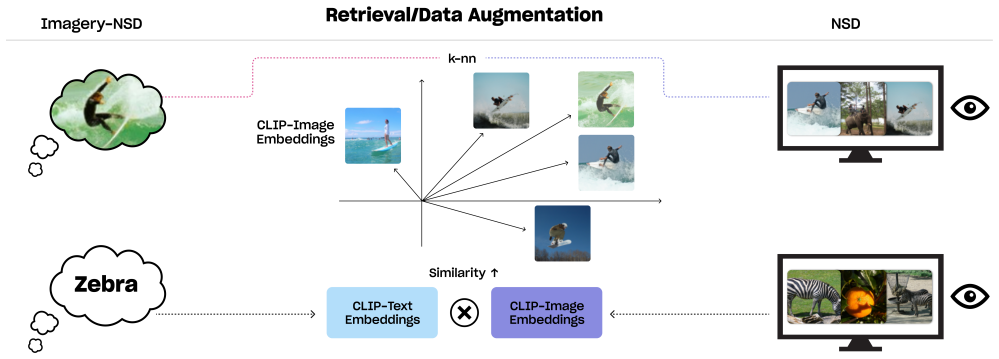
Latent functional alignment: a linear or learned mapping that places imagery fMRI vectors into the pretrained decoder's conditioning space so that semantic structure learned from perception can be reused.
If this is right
- High-level semantic fidelity of reconstructed imagery rises compared with no alignment or voxel-space ridge alignment.
- Above-chance decoding becomes feasible from several cortical regions that otherwise remain below threshold.
- Limited matched imagery-perception pairs can be supplemented by retrieving semantically close perception trials without retraining the core decoder.
- Semantic structure acquired from perception transfers to stabilize performance under the distribution shift of mental imagery.
Where Pith is reading between the lines
- The same alignment strategy could be tested on other sensory modalities where large perception datasets already exist but imagery data are scarce.
- If the mapping generalizes across subjects with minimal new calibration, brain-computer interfaces might reconstruct imagined content without collecting extensive subject-specific imagery data.
- Shared latent structure between perception and imagery suggests that future decoders could be trained primarily on perception and then lightly adapted rather than built from scratch for each mental state.
Load-bearing premise
Brain representations of imagined and perceived scenes share enough semantic structure that a modest amount of paired data suffices to learn a useful mapping between them.
What would settle it
If held-out imagery trials decoded with the aligned model show semantic similarity scores no higher than the frozen baseline or drop to chance level in the same regions across subjects, the central claim is falsified.
Figures










read the original abstract
Recent progress in visual brain decoding from fMRI has been enabled by large-scale datasets such as the Natural Scenes Dataset (NSD) and powerful diffusion-based generative models. While current pipelines are primarily optimized for perception, their performance under mental-imagery remains less well understood. In this work, we study how a state-of-the-art (SOTA) perception decoder (DynaDiff) can be adapted to reconstruct imagined content from the Imagery-NSD benchmark. We propose a latent functional alignment approach that maps imagery-evoked activity into the pretrained model's conditioning space, while keeping the remaining components frozen. To mitigate the limited amount of matched imagery-perception supervision, we further introduce a retrieval-based augmentation strategy that selects semantically related NSD perception trials. Across four subjects, latent functional alignment consistently improves high-level semantic reconstruction metrics relative to the frozen pretrained baseline and a voxel-space ridge alignment baseline, and enables above-chance decoding from multiple cortical regions. These results suggest that semantic structure learned from perception can be leveraged to stabilize and improve visual imagery decoding under out-of-distribution conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a latent functional alignment method to adapt the pretrained DynaDiff perception decoder for visual imagery reconstruction from fMRI data on the Imagery-NSD benchmark. Imagery-evoked activity is mapped into the model's conditioning space with most components kept frozen; a retrieval-based augmentation strategy selects semantically related NSD perception trials to address limited matched supervision. Across four subjects, the approach is reported to yield consistent gains in high-level semantic reconstruction metrics over a frozen pretrained baseline and a voxel-space ridge alignment baseline, while enabling above-chance decoding from multiple cortical regions.
Significance. If the reported gains are robust, the work provides evidence that semantic structure learned from large-scale perception data can transfer to stabilize imagery decoding under out-of-distribution conditions. This has implications for understanding shared neural representations between perception and imagery and offers a practical, efficient adaptation strategy that avoids full retraining. The emphasis on frozen components and retrieval augmentation supports reproducibility and data efficiency in brain-decoding pipelines.
major comments (2)
- Abstract: the central claim of 'consistent improvements in high-level semantic reconstruction metrics' and 'above-chance decoding' is asserted without any quantitative values, confidence intervals, statistical tests, or effect sizes. This absence is load-bearing because the magnitude and reliability of the gains cannot be assessed from the provided text, undermining evaluation of whether latent alignment outperforms the baselines in a meaningful way.
- Methods (latent functional alignment and retrieval augmentation): with only four subjects and limited matched imagery-perception pairs, the alignment mapping risks overfitting to subject-specific noise, scanner effects, or retrieval-induced biases rather than genuine semantic overlap. The manuscript should provide ablation results, cross-subject validation, or controls showing that performance gains derive from shared high-level representations rather than spurious correlations.
minor comments (2)
- Abstract: spell out 'SOTA' as 'state-of-the-art' on first use.
- Results: specify the exact definition of 'above-chance' (including chance level and statistical procedure) for each cortical region and decoder variant.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We address each major comment point by point below, indicating where revisions will be made to strengthen the presentation and analysis.
read point-by-point responses
-
Referee: Abstract: the central claim of 'consistent improvements in high-level semantic reconstruction metrics' and 'above-chance decoding' is asserted without any quantitative values, confidence intervals, statistical tests, or effect sizes. This absence is load-bearing because the magnitude and reliability of the gains cannot be assessed from the provided text, undermining evaluation of whether latent alignment outperforms the baselines in a meaningful way.
Authors: We agree that the abstract would be strengthened by including quantitative support for the claims. In the revised manuscript, we will add specific values such as average improvements in high-level semantic metrics (e.g., CLIP-based similarity scores), along with statistical test results (p-values), confidence intervals, and effect sizes computed across the four subjects. These details are already present in the results section and will be summarized concisely in the abstract to allow direct assessment of the gains relative to baselines. revision: yes
-
Referee: Methods (latent functional alignment and retrieval augmentation): with only four subjects and limited matched imagery-perception pairs, the alignment mapping risks overfitting to subject-specific noise, scanner effects, or retrieval-induced biases rather than genuine semantic overlap. The manuscript should provide ablation results, cross-subject validation, or controls showing that performance gains derive from shared high-level representations rather than spurious correlations.
Authors: We acknowledge the valid concern regarding potential overfitting given the small number of subjects and limited matched pairs in Imagery-NSD. Our approach mitigates this through extensive freezing of the pretrained DynaDiff components and by leveraging retrieval from the much larger NSD perception dataset for augmentation. We already report consistent gains across all four subjects and include a voxel-space ridge regression baseline as a control for subject-specific linear effects. To further address the comment, we will add ablation results removing the retrieval augmentation component and report any available cross-subject analyses (e.g., training on three subjects and testing on the held-out subject) in the revision. These additions will help isolate the contribution of shared semantic representations. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper adapts an external pretrained DynaDiff perception model to imagery data via a proposed latent functional alignment step trained on limited matched pairs from the public Imagery-NSD benchmark. No equations or steps reduce the reported improvements to self-fitted parameters by construction, self-citations that bear the central load, or imported uniqueness theorems. The method is compared against frozen baseline and voxel-space ridge baselines on held-out data, with the alignment and retrieval augmentation serving as independent methodological choices rather than tautological redefinitions of inputs. The derivation chain remains self-contained against external benchmarks and does not exhibit any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Imagery-evoked and perception-evoked brain activity share transferable semantic structure
- domain assumption Retrieval of semantically related perception trials can effectively augment limited imagery supervision
Reference graph
Works this paper leans on
-
[1]
A massive 7T fMRI dataset to bridge cognitive neuroscience and artificial intelligence,
E. J. Allen, G. St-Yves, Y . Wu, J. L. Breedlove, J. S. Prince, L. T . Dowdle, M. Nau, B. Caron, F. Pestilli, I. Charest, J. B. Hutchinson, T . Naselaris, and K. Kay, “ A massive 7T fMRI dataset to bridge cognitive neuroscience and artificial intelligence,” Nature Neuroscience, vol. 25, pp. 116–126, Jan. 2022
2022
-
[2]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P . Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervision,” 2021
2021
-
[3]
Dynadiff: Single-stage decoding of images from continuously evolving fmri,
M. Careil, Y . Benchetrit, and J.-R. King, “Dynadiff: Single-stage decoding of images from continuously evolving fmri,” 2025
2025
-
[4]
Comparison of signal to noise in vision and imagery for qualitatively different kinds of stimuli,
T . Roy, J. Breedlove, G. St-Yves, K. Kay, and T . Naselaris, “Comparison of signal to noise in vision and imagery for qualitatively different kinds of stimuli,” Journal of Vision , vol. 23, p. 5961, 08 2023
2023
-
[5]
Nsd-imagery: A benchmark dataset for extending fmri vision decoding methods to mental imagery,
R. Kneeland, P . S. Scotti, G. St-Yves, J. Breedlove, K. Kay, and T . Naselaris, “Nsd-imagery: A benchmark dataset for extending fmri vision decoding methods to mental imagery,” 2025
2025
-
[6]
High-resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P . Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,” 2022
2022
-
[7]
Versatile diffusion: Text, images and variations all in one diffusion model,
X. Xu, Z. Wang, E. Zhang, K. Wang, and H. Shi, “Versatile diffusion: Text, images and variations all in one diffusion model,” 2024
2024
-
[8]
Reconstructing the mind’s eye: fmri-to-image with contrastive learning and diffusion priors,
P . S. Scotti, A. Banerjee, J. Goode, S. Shabalin, A. Nguyen, E. Cohen, A. J. Dempster, N. Verlinde, E. Yundler, D. Weis- berg, K. A. Norman, and T . M. Abraham, “Reconstructing the mind’s eye: fmri-to-image with contrastive learning and diffusion priors,” 2023
2023
-
[9]
Natural scene reconstruction from fMRI signals using generative latent diffusion,
F. Ozcelik and R. VanRullen, “Natural scene reconstruction from fMRI signals using generative latent diffusion,” Scientific Reports , vol. 13, p. 15666, Sept. 2023
2023
-
[10]
Mindeye2: Shared-subject models enable fmri-to-image with 1 hour of data,
P . S. Scotti, M. Tripathy, C. K. T . Villanueva, R. Kneeland, T . Chen, A. Narang, C. Santhirasegaran, J. Xu, T . Naselaris, K. A. Norman, and T . M. Abraham, “Mindeye2: Shared-subject models enable fmri-to-image with 1 hour of data,” 2024
2024
-
[11]
Auto-encoding variational bayes,
D. P . Kingma and M. Welling, “ Auto-encoding variational bayes,” 2022
2022
-
[12]
Very deep vaes generalize autoregressive models and can outperform them on images,
R. Child, “Very deep vaes generalize autoregressive models and can outperform them on images,” 11 2020
2020
-
[13]
U-net: Convolutional networks for biomedical image segmentation,
O. Ronneberger, P . Fischer, and T . Brox, “U-net: Convolutional networks for biomedical image segmentation,” 2015
2015
-
[14]
Lora: Low-rank adaptation of large language models,
E. J. Hu, Y . Shen, P . Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “Lora: Low-rank adaptation of large language models,” 2021
2021
-
[15]
Microsoft coco: Common objects in context,
T .-Y . Lin, M. Maire, S. Belongie, L. Bourdev, R. Girshick, J. Hays, P . Perona, D. Ramanan, C. L. Zitnick, and P . Dollár, “Microsoft coco: Common objects in context,” 2015
2015
-
[16]
A multi-modal parcellation of human cerebral cortex,
M. F. Glasser, T . S. Coalson, E. C. Robinson, C. D. Hacker, J. Harwell, E. Y acoub, K. Ugurbil, J. Andersson, C. F. Beck- mann, M. Jenkinson, S. M. Smith, and D. C. Van Essen, “ A multi-modal parcellation of human cerebral cortex,” Nature, vol. 536, pp. 171–178, Aug. 2016
2016
-
[17]
Through their eyes: Multi-subject brain decod- ing with simple alignment techniques,
M. Ferrante, T . Boccato, F. Ozcelik, R. VanRullen, and N. Toschi, “Through their eyes: Multi-subject brain decod- ing with simple alignment techniques,” Imaging Neuroscience , vol. 2, pp. imag–2–00170, May 2024. _eprint: https://direct.mit.edu/imag/article-pdf/doi/10.1162/imag_a_00170/2370814/imag_a_00170.pdf
work page doi:10.1162/imag_a_00170/2370814/imag_a_00170.pdf 2024
-
[18]
Inter-individual and inter-site neural code conversion without shared stimuli,
H. Wang, J. Ho, F. Cheng, S. Aoki, Y . Muraki, M. T anaka, J.-Y . Park, and Y . Kamitani, “Inter-individual and inter-site neural code conversion without shared stimuli,” Nature Computational Science , vol. 5, pp. 534–546, 07 2025
2025
-
[19]
Hyperalignment: Modeling shared information encoded in idiosyncratic cortical topographies,
J. Haxby, J. S. Guntupalli, S. Nastase, and M. Feilong, “Hyperalignment: Modeling shared information encoded in idiosyncratic cortical topographies,” eLife Sciences , vol. 9, p. e56601, 06 2020
2020
-
[20]
Deep Neural Networks: A New Framework for Modeling Biological Vision and Brain Information Processing,
N. Kriegeskorte, “Deep Neural Networks: A New Framework for Modeling Biological Vision and Brain Information Processing,” Annual Review of Vision Science , vol. 1, no. Volume 1, 2015, pp. 417–446, 2015. Type: Journal Article
2015
-
[21]
High-level visual representations in the human brain are aligned with large language models,
A. Doerig, T . Kietzmann, E. Allen, Y . Wu, T . Naselaris, K. Kay, and I. Charest, “High-level visual representations in the human brain are aligned with large language models,” Nature Machine Intelligence, vol. 7, pp. 1220–1234, 08 2025
2025
-
[22]
Image quality assessment: From error visibility to structural similarity,
Z. Wang, A. Bovik, H. Sheikh, and E. Simoncelli, “Image quality assessment: From error visibility to structural similarity,” Image Processing, IEEE Transactions on , vol. 13, pp. 600 – 612, 05 2004. 9
2004
-
[23]
Imagenet classification with deep convolutional neural networks,
G. Hinton, A. Krizhevsky, I. Sutskever, and Y . Rachmad, “Imagenet classification with deep convolutional neural networks,” Advances in Neural Information Processing Systems , pp. 1097–1105, 01 2012
2012
-
[24]
Rethinking the inception architecture for computer vision,
C. Szegedy, V . Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna, “Rethinking the inception architecture for computer vision,” 2015
2015
-
[25]
Efficientnet: Rethinking model scaling for convolutional neural networks,
M. T an and Q. V . Le, “Efficientnet: Rethinking model scaling for convolutional neural networks,” 2020
2020
-
[26]
Unsupervised learning of visual features by contrasting cluster assignments,
M. Caron, I. Misra, J. Mairal, P . Goyal, P . Bojanowski, and A. Joulin, “Unsupervised learning of visual features by contrasting cluster assignments,” 2021
2021
-
[27]
Mental imagery: Functional mechanisms and clinical applica- tions,
J. Pearson, T . Naselaris, E. Holmes, and S. Kosslyn, “Mental imagery: Functional mechanisms and clinical applica- tions,” Trends in Cognitive Sciences , vol. 19, pp. 590–602, 10 2015
2015
-
[28]
Semantic memory as the root of imagination,
A. Abraham and A. Bubić, “Semantic memory as the root of imagination,” Frontiers in Psychology , vol. 6, p. 325, 03 2015
2015
-
[29]
Visual imagery and perception share neural representations in the alpha frequency band,
S. Xie, D. Kaiser, and R. Cichy, “Visual imagery and perception share neural representations in the alpha frequency band,” Current Biology , vol. 30, p. 3062, 08 2020
2020
-
[30]
Uncovering the role of the early visual cortex in visual mental imagery,
N. Dijkstra, “Uncovering the role of the early visual cortex in visual mental imagery,” Vision, vol. 8, p. 29, 05 2024
2024
-
[31]
Vivid visual mental imagery in the absence of the primary visual cortex,
H. Bridge, S. Harrold, E. A. Holmes, M. Stokes, and C. Kennard, “Vivid visual mental imagery in the absence of the primary visual cortex,” Journal of Neurology , vol. 259, pp. 1062–1070, June 2012
2012
-
[32]
Mental imagery: The role of primary visual cortex in aphantasia,
F. Milton, “Mental imagery: The role of primary visual cortex in aphantasia,” Current Biology , vol. 34, no. 21, pp. R1088–R1090, 2024
2024
-
[33]
Vividness of visual imagery depends on the neural overlap with perception in visual areas,
N. Dijkstra, S. Bosch, and M. van Gerven, “Vividness of visual imagery depends on the neural overlap with perception in visual areas,” The Journal of Neuroscience , vol. 37, pp. 3022–16, 01 2017
2017
-
[34]
Brain areas underlying visual mental imagery and visual perception: an fmri study,
G. Ganis, W. Thompson, and S. Kosslyn, “Brain areas underlying visual mental imagery and visual perception: an fmri study,” Brain research. Cognitive brain research , vol. 20, pp. 226–41, 08 2004
2004
-
[35]
Decoding visual experience and mapping semantics through whole-brain analysis using fmri foundation models,
Y . Wang, A. Turnbull, T . Xiang, Y . Xu, S. Zhou, A. Masoud, S. Azizi, F. Lin, and E. Adeli, “Decoding visual experience and mapping semantics through whole-brain analysis using fmri foundation models,” 11 2024
2024
-
[36]
The fusion of mental imagery and sensation in the temporal association cortex,
C. Berger and H. Ehrsson, “The fusion of mental imagery and sensation in the temporal association cortex,” The Journal of Neuroscience : The Official Journal of the Society for Neuroscience , vol. 34, pp. 13684–13692, 10 2014
2014
-
[37]
Cognitive and neural mechanisms of mental imagery supporting creative cognition,
G. Jing, X. Wang, C. Liu, L. Y ang, J. Fan, J. Sun, Y . Kenett, and J. Qiu, “Cognitive and neural mechanisms of mental imagery supporting creative cognition,” Communications Biology , vol. 8, 09 2025. 10 A Statements Ethics Statement The datasets are publicly accessible at: https://natural-scenes-dataset.s3.amazonaws.com/index.html. The present study make...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.