Recognition: unknown
Beyond Single-Model Optimization: Preserving Plasticity in Continual Reinforcement Learning
Pith reviewed 2026-05-10 10:57 UTC · model grok-4.3
The pith
Maintaining archives of diverse policies in a shared latent space preserves plasticity in continual reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
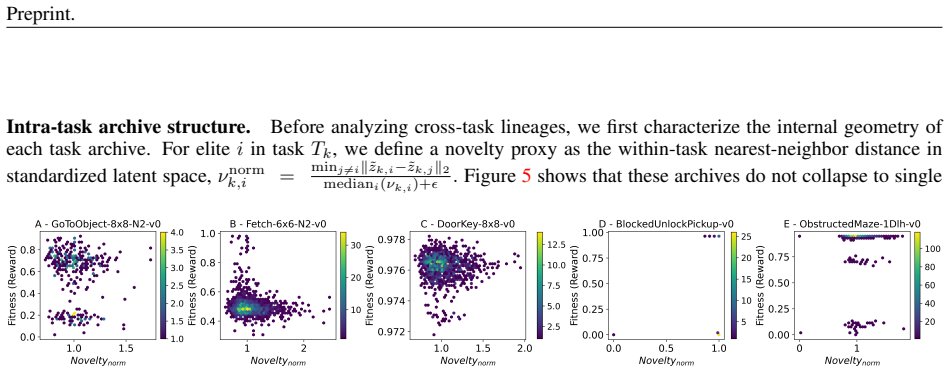
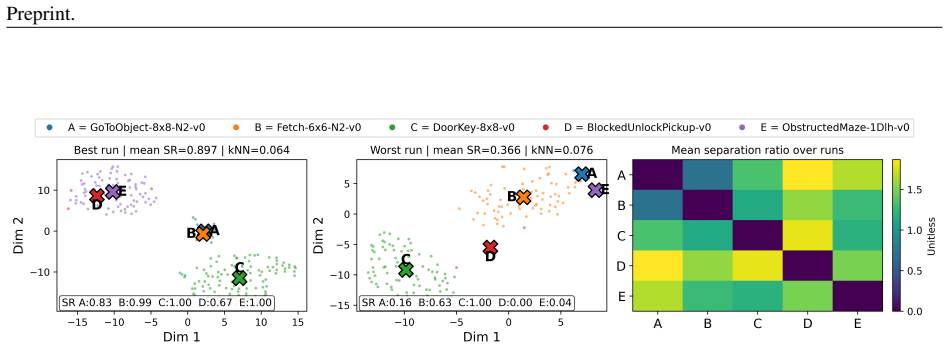
The paper claims that source-optimal policies are often not transfer-optimal even inside a local competent neighborhood, and that effective reuse therefore requires retaining and selecting among multiple nearby alternatives rather than collapsing to one representative; TeLAPA achieves this by placing behaviorally diverse policies into per-task archives connected by a shared latent space that keeps them reusable under non-stationary drift.
What carries the argument
TeLAPA (Transfer-Enabled Latent-Aligned Policy Archives), which builds per-task archives of behaviorally diverse policies kept aligned and comparable inside one shared latent space.
If this is right
- Agents learn more tasks successfully across a long sequence of changing environments.
- Competence on revisited tasks is recovered faster once interference from new learning has occurred.
- Overall performance across the entire task sequence remains higher than with single-model methods.
- Selecting from multiple competent nearby policies proves more effective for transfer than using any single source-optimal policy.
- Single-model preservation cannot fully solve loss of plasticity because it collapses alternatives that remain useful.
Where Pith is reading between the lines
- The same neighborhood principle could be tested in domains with stronger or more abrupt task shifts to see whether the latent alignment still maintains reuse value.
- Storing and searching multiple policies per task introduces a storage and selection cost that future implementations would need to manage efficiently.
- The finding that local competence does not guarantee transfer optimality suggests similar archive structures might help in other non-stationary learning settings beyond reinforcement learning.
Load-bearing premise
Organizing policies into behaviorally diverse neighborhoods via a shared latent space will reliably preserve plasticity and transfer better than single-model preservation.
What would settle it
An experiment in the same MiniGrid continual-learning setting where TeLAPA shows no gains in task success rate, recovery speed after interference, or final retention compared with strong single-policy baselines would falsify the central result.
Figures






read the original abstract
Continual reinforcement learning must balance retention with adaptation, yet many methods still rely on \emph{single-model preservation}, committing to one evolving policy as the main reusable solution across tasks. Even when a previously successful policy is retained, it may no longer provide a reliable starting point for rapid adaptation after interference, reflecting a form of \emph{loss of plasticity} that single-policy preservation cannot address. Inspired by quality-diversity methods, we introduce \textsc{TeLAPA} (Transfer-Enabled Latent-Aligned Policy Archives), a continual RL framework that organizes behaviorally diverse policy neighborhoods into per-task archives and maintains a shared latent space so that archived policies remain comparable and reusable under non-stationary drift. This perspective shifts continual RL from retaining isolated solutions to maintaining \emph{skill-aligned neighborhoods} with competent and behaviorally related policies that support future relearning. In our MiniGrid CL setting, \textsc{TeLAPA} learns more tasks successfully, recovers competence faster on revisited tasks after interference, and retains higher performance across a sequence of tasks. Our analyses show that source-optimal policies are often not transfer-optimal, even within a local competent neighborhood, and that effective reuse depends on retaining and selecting among multiple nearby alternatives rather than collapsing them to one representative. Together, these results reframe continual RL around reusable and competent policy neighborhoods, providing a route beyond single-model preservation toward more plastic lifelong agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TeLAPA (Transfer-Enabled Latent-Aligned Policy Archives), a continual RL framework that maintains per-task archives of behaviorally diverse policies aligned in a shared latent space. This shifts from single-model preservation to retaining skill-aligned neighborhoods to better address loss of plasticity and enable reuse under task interference. In MiniGrid continual learning experiments, TeLAPA is reported to solve more tasks, recover faster after interference, and retain higher performance; analyses indicate that source-optimal policies are often not transfer-optimal within neighborhoods.
Significance. If the core mechanism proves robust, the work offers a promising reframing of continual RL around reusable policy neighborhoods rather than isolated solutions, potentially improving plasticity in lifelong agents. The MiniGrid results provide initial support for the value of latent alignment and multi-policy selection over single-policy baselines, but the narrow domain limits broader impact assessment.
major comments (3)
- [§4] §4 (Experiments): All quantitative results and claims of superior task learning, recovery speed, and retention are demonstrated exclusively on MiniGrid, a low-dimensional discrete domain. The central claim that shared latent spaces produce stable, reusable behaviorally diverse neighborhoods under non-stationary drift lacks validation in higher-variance settings such as continuous-control MuJoCo or Atari sequences, where the skeptic concern about latent alignment failure directly undermines the transfer mechanism.
- [§4.2, §5] §4.2 and §5 (Analyses): The assertion that source-optimal policies are not transfer-optimal and that effective reuse requires multiple nearby alternatives rests on MiniGrid-specific metrics without reported error bars, statistical tests, or ablation controls on latent space dimensionality and archive size. This makes it impossible to assess whether the neighborhood advantage is robust or an artifact of the low-dimensional setting.
- [§3] §3 (Method): The description of how the shared latent space maintains comparability of archived policies after task drift is high-level; no concrete mechanism, loss terms, or stability guarantees are provided to ensure that behavioral diversity remains aligned and selectable when policy parameters evolve under interference, which is load-bearing for the 'beyond single-model' claim.
minor comments (2)
- [Abstract] Abstract: Quantitative details, error bars, and baseline comparisons are absent, reducing the ability to evaluate the strength of the reported gains in task success, recovery, and retention.
- [§3] Notation: The distinction between 'source-optimal' and 'transfer-optimal' policies is introduced in the analyses but would benefit from an explicit definition or equation early in the method section to avoid ambiguity.
Simulated Author's Rebuttal
We thank the referee for their insightful comments on our manuscript. We have carefully considered each major point and provide detailed responses below, along with indications of how we plan to revise the paper.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): All quantitative results and claims of superior task learning, recovery speed, and retention are demonstrated exclusively on MiniGrid, a low-dimensional discrete domain. The central claim that shared latent spaces produce stable, reusable behaviorally diverse neighborhoods under non-stationary drift lacks validation in higher-variance settings such as continuous-control MuJoCo or Atari sequences, where the skeptic concern about latent alignment failure directly undermines the transfer mechanism.
Authors: We acknowledge the limitation that all empirical results are confined to the MiniGrid environment. MiniGrid was selected as it provides a controlled setting to study continual learning with clear task boundaries and measurable interference effects, allowing us to focus on the plasticity preservation mechanism without the confounding factors of high-dimensional observations or continuous actions. The proposed framework is intended to be general, but we agree that additional validation in domains like MuJoCo or Atari would be valuable to address concerns about latent alignment under greater variance. In the revised version, we will add a dedicated limitations subsection discussing the challenges of scaling the latent alignment to these domains and suggest directions for future empirical work. We cannot perform new large-scale experiments in this revision cycle. revision: partial
-
Referee: [§4.2, §5] §4.2 and §5 (Analyses): The assertion that source-optimal policies are not transfer-optimal and that effective reuse requires multiple nearby alternatives rests on MiniGrid-specific metrics without reported error bars, statistical tests, or ablation controls on latent space dimensionality and archive size. This makes it impossible to assess whether the neighborhood advantage is robust or an artifact of the low-dimensional setting.
Authors: We appreciate this feedback on the rigor of our analyses. In the revised manuscript, we will include error bars (standard deviation across multiple seeds) for all quantitative results in §4.2 and §5. We will also conduct and report statistical tests to compare TeLAPA against baselines. Furthermore, we will add ablation studies varying the latent space dimensionality and archive size to demonstrate the robustness of the multi-policy neighborhood approach. These changes will strengthen the evidence that the observed advantages are not artifacts of the specific setting. revision: yes
-
Referee: [§3] §3 (Method): The description of how the shared latent space maintains comparability of archived policies after task drift is high-level; no concrete mechanism, loss terms, or stability guarantees are provided to ensure that behavioral diversity remains aligned and selectable when policy parameters evolve under interference, which is load-bearing for the 'beyond single-model' claim.
Authors: We will revise §3 to provide a more detailed description of the latent alignment process. This will include the specific loss functions employed to project policies into the shared latent space, the criteria for maintaining behavioral diversity within archives, and any mechanisms or regularizations used to promote stability under policy updates and task drift. We will also discuss the selection strategy for retrieving policies from the archive during adaptation. If appropriate, we will include an algorithmic outline to clarify the overall procedure. revision: yes
- Validation of the approach in higher-variance domains such as MuJoCo or Atari, which would require substantial new experiments not feasible in the current revision.
Circularity Check
No circularity: framework and results are empirically grounded without self-referential reductions.
full rationale
The paper presents TeLAPA as an empirically evaluated framework for continual RL that organizes policies into latent-aligned archives, drawing inspiration from quality-diversity methods. No equations, fitted parameters, or derivations are described that reduce the central claims (e.g., faster recovery via neighborhood selection) to inputs by construction. Analyses of source-optimal vs. transfer-optimal policies and MiniGrid results provide independent empirical content. Self-citations, if present for inspiration, are not load-bearing for the core argument, which rests on experimental comparisons rather than tautological definitions or imported uniqueness theorems.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Policies that are behaviorally similar remain comparable and reusable when projected into a shared latent space even after non-stationary task drift.
invented entities (1)
-
Transfer-Enabled Latent-Aligned Policy Archives (TeLAPA)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
The effect of task ordering in continual learning.arXiv preprint arXiv:2205.13323,
Samuel J Bell and Neil D Lawrence. The effect of task ordering in continual learning.arXiv preprint arXiv:2205.13323,
-
[2]
Exploration by random network distillation.arXiv preprint arXiv:1810.12894, 2018
Yuri Burda, Harrison Edwards, Amos Storkey, and Oleg Klimov. Exploration by random network distillation.arXiv preprint arXiv:1810.12894,
-
[3]
New insights on reducing abrupt representation change in online continual learning,
Lucas Caccia, Rahaf Aljundi, Nader Asadi, Tinne Tuytelaars, Joelle Pineau, and Eugene Belilovsky. New insights on reducing abrupt representation change in online continual learning.arXiv preprint arXiv:2104.05025,
-
[4]
Felix Chalumeau, Raphael Boige, Bryan Lim, Valentin Mac ´e, Maxime Allard, Arthur Flajolet, Antoine Cully, and Thomas Pierrot. Neuroevolution is a competitive alternative to reinforcement learning for skill discovery.arXiv preprint arXiv:2210.03516,
-
[5]
Efficient Lifelong Learning with A-GEM
Arslan Chaudhry, Marc’Aurelio Ranzato, Marcus Rohrbach, and Mohamed Elhoseiny. Efficient lifelong learning with a-gem.arXiv preprint arXiv:1812.00420,
-
[6]
Adaptive rational activations to boost deep reinforcement learning.arXiv preprint arXiv:2102.09407,
Quentin Delfosse, Patrick Schramowski, Martin Mundt, Alejandro Molina, and Kristian Kersting. Adaptive rational activations to boost deep reinforcement learning.arXiv preprint arXiv:2102.09407,
-
[7]
Shibhansh Dohare, Richard S Sutton, and A Rupam Mahmood. Continual backprop: Stochastic gradient descent with persistent randomness.arXiv preprint arXiv:2108.06325,
-
[8]
Benjamin Eysenbach, Abhishek Gupta, Julian Ibarz, and Sergey Levine. Diversity is all you need: Learning skills without a reward function.arXiv preprint arXiv:1802.06070,
-
[9]
Lapo Frati, Neil Traft, Jeff Clune, and Nick Cheney. Reset it and forget it: Relearning last-layer weights improves continual and transfer learning.arXiv preprint arXiv:2310.07996,
-
[10]
Association for Computing Machinery. ISBN 9781450367486. doi: 10.1145/3319619.3321897. 11 Preprint. Timur Garipov, Pavel Izmailov, Dmitrii Podoprikhin, Dmitry P Vetrov, and Andrew G Wilson. Loss surfaces, mode connectivity, and fast ensembling of dnns.Advances in neural information processing systems, 31,
-
[11]
Building a subspace of policies for scal- able continual learning.arXiv:2211.10445, 2022
Jean-Baptiste Gaya, Thang Doan, Lucas Caccia, Laure Soulier, Ludovic Denoyer, and Roberta Raileanu. Building a subspace of policies for scalable continual learning.arXiv preprint arXiv:2211.10445,
-
[12]
Hendawy, H
A. Hendawy, H. Metternich, J. Peters, G. Tiboni, and C. D’Eramo. It is all connected: Multi-task reinforcement learning via mode connectivity. InEighteenth European Workshop on Reinforcement Learning (EWRL 2025),
2025
-
[13]
Plasticity Loss in Deep Reinforcement Learning: A Survey
Timo Klein, Lukas Miklautz, Kevin Sidak, Claudia Plant, and Sebastian Tschiatschek. Plasticity loss in deep rein- forcement learning: A survey.arXiv preprint arXiv:2411.04832,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Implicit under-parameterization inhibits data-efficient deep reinforcement learning
Aviral Kumar, Rishabh Agarwal, Dibya Ghosh, and Sergey Levine. Implicit under-parameterization inhibits data- efficient deep reinforcement learning.arXiv preprint arXiv:2010.14498,
-
[15]
Maintaining plasticity in continual learning via regenerative regularization, 2024
Saurabh Kumar, Henrik Marklund, and Benjamin Van Roy. Maintaining plasticity in continual learning via regenera- tive regularization.arXiv preprint arXiv:2308.11958,
-
[16]
Joel Lehman and Kenneth O. Stanley. Abandoning objectives: Evolution through the search for novelty alone.Evol. Comput., 19(2):189–223, June 2011a. ISSN 1063-6560. doi: 10.1162/EVCO a 00025. Joel Lehman and Kenneth O. Stanley. Abandoning objectives: Evolution through the search for novelty alone.Evol. Comput., 19(2):189–223, June 2011b. ISSN 1063-6560. do...
-
[17]
Optimal task order for continual learning of multiple tasks.arXiv preprint arXiv:2502.03350,
Ziyan Li and Naoki Hiratani. Optimal task order for continual learning of multiple tasks.arXiv preprint arXiv:2502.03350,
-
[18]
Activation Function Design Sustains Plasticity in Continual Learning
Lute Lillo and Nick Cheney. Activation function design sustains plasticity in continual learning.arXiv preprint arXiv:2509.22562,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Understanding and preventing capacity loss in reinforce- ment learning, 2022
Clare Lyle, Mark Rowland, and Will Dabney. Understanding and preventing capacity loss in reinforcement learning. arXiv preprint arXiv:2204.09560,
-
[20]
Disentangling the causes of plasticity loss in neural networks,
Clare Lyle, Zeyu Zheng, Khimya Khetarpal, Hado van Hasselt, Razvan Pascanu, James Martens, and Will Dabney. Disentangling the causes of plasticity loss in neural networks.arXiv preprint arXiv:2402.18762,
-
[21]
Illuminating search spaces by mapping elites
Jean-Baptiste Mouret and Jeff Clune. Illuminating search spaces by mapping elites.arXiv preprint arXiv:1504.04909,
-
[22]
Quality diversity for multi-task optimization
Jean-Baptiste Mouret and Glenn Maguire. Quality diversity for multi-task optimization. InProceedings of the 2020 Genetic and Evolutionary Computation Conference, pp. 121–129,
2020
-
[23]
Association for Computing Machinery. ISBN 9781450383509. doi: 10.1145/3449639.3459304. Jørgen Nordmoen, Frank Veenstra, Kai Olav Ellefsen, and Kyrre Glette. Map-elites enables powerful stepping stones and diversity for modular robotics.Frontiers in Robotics and AI, 8:639173,
-
[24]
Roberta Raileanu and Tim Rockt¨aschel. Ride: Rewarding impact-driven exploration for procedurally-generated envi- ronments.arXiv preprint arXiv:2002.12292,
-
[25]
icarl: Incremental classifier and representation learning
Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H Lampert. icarl: Incremental classifier and representation learning. InProceedings of the IEEE conference on Computer Vision and Pattern Recognition, pp. 2001–2010,
2001
-
[26]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Tiago F Tavares, Fabio Ayres, and Paris Smaragdis. Measuring similarity between embedding spaces using induced neighborhood graphs.arXiv preprint arXiv:2411.08687,
-
[28]
Grown: Grow only when necessary for continual learning.arXiv preprint arXiv:2110.00908,
Li Yang, Sen Lin, Junshan Zhang, and Deliang Fan. Grown: Grow only when necessary for continual learning.arXiv preprint arXiv:2110.00908,
-
[29]
Lifelong Learning with Dynamically Expandable Networks
Jaehong Yoon, Eunho Yang, Jeongtae Lee, and Sung Ju Hwang. Lifelong learning with dynamically expandable networks.arXiv preprint arXiv:1708.01547,
-
[30]
Bebold: Exploration beyond the boundary of explored regions.arXiv preprint arXiv:2012.08621,
Tianjun Zhang, Huazhe Xu, Xiaolong Wang, Yi Wu, Kurt Keutzer, Joseph E Gonzalez, and Yuandong Tian. Bebold: Exploration beyond the boundary of explored regions.arXiv preprint arXiv:2012.08621,
-
[31]
retained knowledge
+b 4 ∈R d.(19) Thus, the full episode encoder is ze =ϕ(E),(20) whereϕdenotes the current shared trajectory embedder. E.4 POLICY-LEVEL LATENT SUMMARIES A policy is evaluated over a collection of episodes E(π) ={E (1), . . . , E(M) }.(21) The encoder is applied to every episode: z(m) e =ϕ(E (m)), m= 1, . . . , M.(22) The policy-level mean descriptor is zmea...
2020
-
[32]
We use the same hyperparameter configuration for all methods as in the main paper results. This sequence tests whether TeLAPA requires gradual prerequisite accumulation, or whether it can still retain and exploit useful policies when tasks arrive in a less curriculum-like order. Results.Task order still matters, but TeLAPA’s advantage does not disappear u...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.