Recognition: unknown
Spurious Predictability in Financial Machine Learning
Pith reviewed 2026-05-10 08:54 UTC · model grok-4.3
The pith
Adaptive specification search generates statistically significant financial backtests even under martingale nulls with no true predictability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
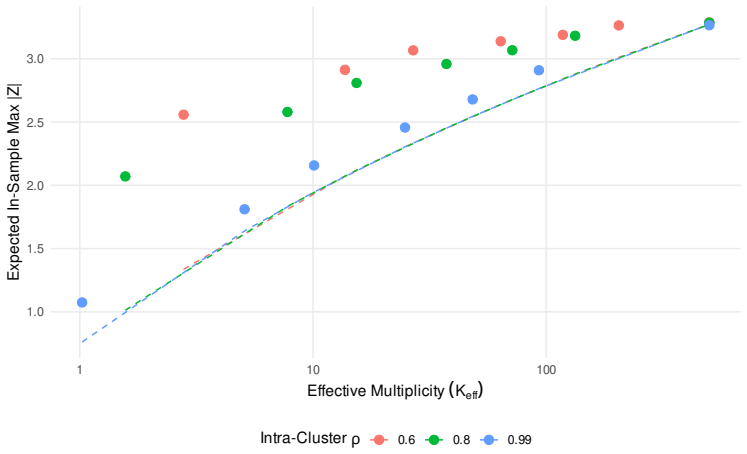
Adaptive specification search generates statistically significant backtests even under martingale-difference nulls. The paper introduces a falsification audit that tests complete predictive workflows against synthetic reference classes, including zero-predictability environments and microstructure placebos. Workflows generating significant walk-forward evidence in these environments are falsified. For passing workflows, selection-induced performance inflation is quantified using an absolute magnitude gap linking optimized in-sample evidence to disjoint walk-forward realizations, adjusted for effective multiplicity.
What carries the argument
The falsification audit that subjects full predictive workflows to synthetic zero-predictability martingale environments and microstructure placebos to detect spurious results created by adaptive search.
If this is right
- Workflows that generate significant results in the synthetic null environments are rejected as spurious.
- For workflows that pass, the absolute magnitude gap provides a direct measure of selection-induced performance inflation.
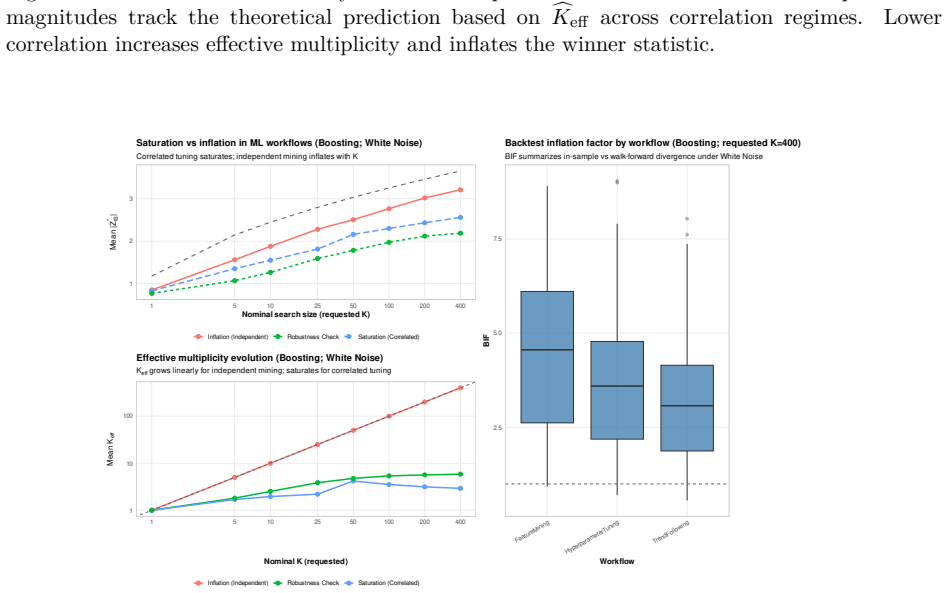
- Simulations confirm that the audit detects genuine predictive structure when it is present and scales correctly under correlated model searches.
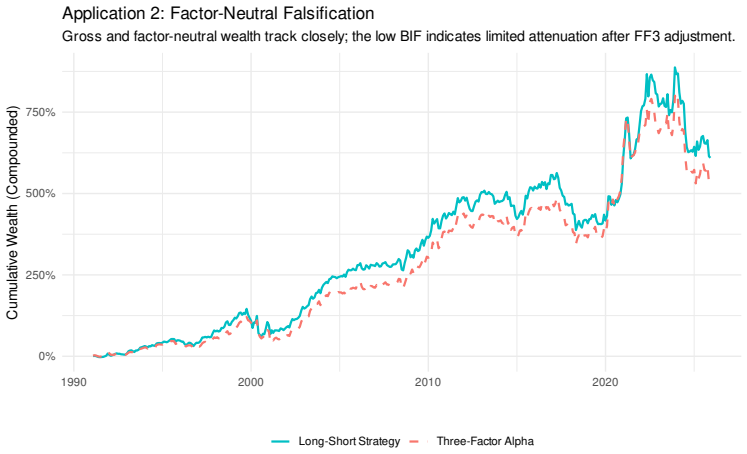
- Empirical case studies show that many published financial ML findings fail the audit and represent artifacts.
Where Pith is reading between the lines
- The audit could be adapted to other domains that rely on high-dimensional adaptive modeling, such as medical outcome prediction or demand forecasting.
- Standard backtesting protocols in quantitative finance might need to incorporate null-model audits alongside conventional cross-validation.
- Developing additional reference classes that embed realistic non-stationarities or regime shifts could further tighten the falsification test.
Load-bearing premise
The chosen synthetic reference classes capture the full range of spurious effects that adaptive search can produce in real financial data.
What would settle it
A workflow that produces statistically significant walk-forward results inside the synthetic martingale and placebo environments yet also delivers economically valuable predictions on live market data with independent verification would falsify the audit's reliability.
Figures






read the original abstract
Adaptive specification search generates statistically significant backtests even under martingale-difference nulls. We introduce a falsification audit testing complete predictive workflows against synthetic reference classes, including zero-predictability environments and microstructure placebos. Workflows generating significant walk-forward evidence in these environments are falsified. For passing workflows, we quantify selection-induced performance inflation using an absolute magnitude gap linking optimized in-sample evidence to disjoint walk-forward realizations, adjusted for effective multiplicity. Simulations validate extreme-value scaling under correlated searches and demonstrate detection power under genuine structure. Empirical case studies confirm that many apparent findings represent methodological artifacts rather than genuine predictability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that adaptive specification search generates statistically significant backtests even under martingale-difference nulls. It introduces a falsification audit that tests complete predictive workflows against synthetic reference classes (zero-predictability martingale environments and microstructure placebos); workflows producing significant walk-forward evidence in these null environments are falsified. For passing workflows, selection-induced performance inflation is quantified via an absolute magnitude gap that links optimized in-sample evidence to disjoint walk-forward realizations, adjusted for effective multiplicity. Simulations are said to validate extreme-value scaling under correlated searches and to demonstrate detection power under genuine structure; empirical case studies are presented to show that many apparent findings are methodological artifacts rather than genuine predictability.
Significance. If the audit procedure and magnitude-gap measure are shown to be robust and reproducible, the work would provide a practical tool for distinguishing genuine predictability from data-snooping artifacts in financial machine learning, addressing a long-standing concern about the reliability of published backtests in quantitative finance.
major comments (3)
- [Methods / magnitude-gap definition] The manuscript does not supply the explicit equations or algorithmic definition of the absolute magnitude gap (or its multiplicity adjustment), so it is impossible to verify how the measure is computed from in-sample optimized evidence and disjoint walk-forward realizations or whether the adjustment is derived independently of the fitted results.
- [Synthetic benchmark construction] Exact data-exclusion rules, sampling procedures, and parameter settings used to construct the zero-predictability martingale environments and microstructure placebos are not stated, preventing assessment of whether these reference classes adequately span the range of spurious effects that arise under adaptive search in real financial series.
- [Empirical case studies] The empirical case studies do not list the concrete workflows examined, the precise walk-forward protocol, or the numerical threshold applied to declare that a workflow 'passes' the audit; without these details the claim that 'many apparent findings represent methodological artifacts' cannot be evaluated.
minor comments (1)
- [Abstract] The abstract is information-dense; separating the description of the audit procedure from the simulation and empirical results would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which identify important gaps in methodological exposition. We agree that additional explicit definitions, construction details, and protocol specifications are needed for full reproducibility and verifiability. We will incorporate these in a major revision.
read point-by-point responses
-
Referee: The manuscript does not supply the explicit equations or algorithmic definition of the absolute magnitude gap (or its multiplicity adjustment), so it is impossible to verify how the measure is computed from in-sample optimized evidence and disjoint walk-forward realizations or whether the adjustment is derived independently of the fitted results.
Authors: We agree that the explicit equations and algorithmic steps for the absolute magnitude gap were omitted from the main text. In the revised manuscript we will insert a dedicated Methods subsection that states the definition in full: the gap is the difference between the maximum in-sample performance (optimized over the specification search) and the corresponding disjoint walk-forward out-of-sample realization; the multiplicity adjustment is obtained from the expected maximum of the test statistic under the null, using the extreme-value scaling calibrated on the synthetic reference class. The adjustment is computed once from the reference-class simulations and does not depend on any particular fitted model. Pseudocode and the exact formula will be provided. revision: yes
-
Referee: Exact data-exclusion rules, sampling procedures, and parameter settings used to construct the zero-predictability martingale environments and microstructure placebos are not stated, preventing assessment of whether these reference classes adequately span the range of spurious effects that arise under adaptive search in real financial series.
Authors: We acknowledge that the precise construction rules were not stated. The revision will add an appendix section that specifies: (i) data-exclusion rules (non-overlapping windows, removal of periods with volatility exceeding the 95th percentile of the historical distribution); (ii) sampling procedures (block bootstrap of returns with random permutation within blocks to enforce the martingale-difference property while preserving serial dependence and marginal moments); and (iii) parameter settings (5,000 Monte Carlo replications, microstructure noise calibrated to average bid-ask spreads observed in the target asset class). These choices were selected to cover the principal channels of spurious predictability under adaptive search, as already validated by the simulation experiments reported in the paper. revision: yes
-
Referee: The empirical case studies do not list the concrete workflows examined, the precise walk-forward protocol, or the numerical threshold applied to declare that a workflow 'passes' the audit; without these details the claim that 'many apparent findings represent methodological artifacts' cannot be evaluated.
Authors: We agree that the case-study description lacks the required operational details. The revised text will expand the section to enumerate: the concrete workflows (specific ML algorithms, feature sets, and hyper-parameter grids), the walk-forward protocol (expanding window with 1,260-day in-sample periods, 252-day out-of-sample periods, re-optimization every 63 days), and the falsification threshold (a workflow is falsified if its walk-forward p-value falls below 0.05 in more than 5 % of the null environments after multiplicity adjustment). These additions will allow direct replication of the finding that many published results fail the audit. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes an external falsification audit that tests complete workflows against synthetic martingale-difference nulls and microstructure placebos, then quantifies inflation via a magnitude gap between in-sample optimization and disjoint walk-forward realizations (adjusted for multiplicity). No load-bearing step reduces by construction to a fitted parameter or self-citation; the central claims rest on independently generated synthetic benchmarks and simulation-validated scaling rather than re-labeling the target result. The derivation is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Martingale-difference sequences and microstructure placebos constitute valid null environments for detecting spurious predictability
Reference graph
Works this paper leans on
-
[1]
S. Athey. The impact of machine learning on economics. In The Economics of Artificial Intelligence: An Agenda, pages 507--547. University of Chicago Press, 2019
2019
-
[2]
D. H. Bailey and M. L \'o pez de Prado. The deflated sharpe ratio: Correcting for selection bias, backtest overfitting, and non-normality. The Journal of Portfolio Management, 40 0 (5): 0 94--107, 2014
2014
-
[3]
Belloni, V
A. Belloni, V. Chernozhukov, and C. Hansen. Inference on treatment effects after selection among high-dimensional controls. The Review of Economic Studies, 81 0 (2): 0 608--650, 2014
2014
-
[4]
Bergmeir, R
C. Bergmeir, R. J. Hyndman, and B. Koo. A note on the validity of cross-validation for evaluating autoregressive time series prediction. Computational Statistics & Data Analysis, 120: 0 70--83, 2018
2018
-
[5]
J. L. Campbell, H. Ham, Z. Lu, and K. Wood. Expectations matter: When (not) to use machine learning earnings forecasts. SSRN Electronic Journal, 2024. URL https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4495297. Working Paper
2024
-
[6]
J. Y. Campbell, A. W. Lo, and A. C. MacKinlay. The Econometrics of Financial Markets. Princeton University Press, 1997
1997
-
[7]
M. M. Carhart. On persistence in mutual fund performance. The Journal of Finance, 52 0 (1): 0 57--82, 1997
1997
-
[8]
R. Cont. Empirical properties of asset returns: stylized facts and statistical issues. Quantitative Finance, 1 0 (2): 0 223--236, 2001
2001
-
[9]
F. X. Diebold. Comparing predictive accuracy, twenty years later: A personal perspective on the use and abuse of diebold-mariano tests. Journal of Business & Economic Statistics, 33 0 (1): 0 1--1, 2015. doi:10.1080/07350015.2014.983236
-
[10]
R. F. Engle. Autoregressive conditional heteroscedasticity with estimates of the variance of united kingdom inflation. Econometrica, 50 0 (4): 0 987--1007, 1982
1982
-
[11]
E. F. Fama and K. R. French. Common risk factors in the returns on stocks and bonds. Journal of Financial Economics, 33 0 (1): 0 3--56, 1993. doi:10.1016/0304-405X(93)90023-5
-
[12]
Giné and R
E. Giné and R. Nickl. Mathematical Foundations of Infinite-Dimensional Statistical Models. Cambridge Series in Statistical and Probabilistic Mathematics. Cambridge University Press, Cambridge, 2016
2016
-
[13]
S. Gu, B. Kelly, and D. Xiu. Empirical asset pricing via machine learning. The Review of Financial Studies, 33 0 (5): 0 2223--2273, 2020
2020
-
[14]
P. R. Hansen. A test for superior predictive ability. Journal of Business & Economic Statistics, 23 0 (4): 0 365--380, 2005
2005
-
[15]
C. R. Harvey, Y. Liu, and H. Zhu. ...and the cross-section of expected returns. The Review of Financial Studies, 29 0 (1): 0 5--68, 2016
2016
-
[16]
K. Hou, C. Xue, and L. Zhang. Replicating anomalies. The Review of Financial Studies, 33 0 (5): 0 2019--2133, 2020. doi:10.1093/rfs/hhy131
-
[17]
G. W. Imbens and D. B. Rubin. Causal Inference in Statistics, Social, and Biomedical Sciences. Cambridge University Press, 2015
2015
-
[18]
T. I. Jensen, B. Kelly, and L. H. Pedersen. Is there a replication crisis in finance? The Journal of Finance, 78 0 (5): 0 2465--2518, 2023
2023
-
[19]
J. D. Lee, D. L. Sun, Y. Sun, and J. E. Taylor. Exact post-selection inference, with application to the lasso. The Annals of Statistics, 44 0 (3): 0 907--927, 2016
2016
-
[20]
Lopez de Prado
M. Lopez de Prado. Advances in Financial Machine Learning. John Wiley & Sons, 2018
2018
-
[21]
Mandelbrot
B. Mandelbrot. The variation of certain speculative prices. The Journal of Business, 36 0 (4): 0 394--419, 1963
1963
-
[22]
W. K. Newey and K. D. West. A simple, positive semi-definite, heteroskedasticity and autocorrelation consistent covariance matrix. Econometrica, 55 0 (3): 0 703--708, 1987
1987
-
[23]
W. K. Newey and K. D. West. Automatic lag selection in covariance matrix estimation. The Review of Economic Studies, 61 0 (4): 0 631--653, 1994
1994
-
[24]
Sch \"a fer and K
J. Sch \"a fer and K. Strimmer. A shrinkage approach to large-scale covariance matrix estimation and implications for functional genomics. Statistical Applications in Genetics and Molecular Biology, 4 0 (1): 0 Article 32, 2005
2005
-
[25]
X. Shao. The dependent wild bootstrap. Journal of the American Statistical Association, 105 0 (489): 0 218--235, 2010
2010
-
[26]
J. H. van Binsbergen, X. Han, and A. Lopez-Lira. Man versus machine learning: The term structure of earnings expectations and conditional biases. The Review of Financial Studies, 36 0 (6): 0 2361--2396, 2023
2023
-
[27]
H. R. Varian. Big data: New tricks for econometrics. Journal of Economic Perspectives, 28 0 (2): 0 3--28, 2014
2014
-
[28]
M. J. Wainwright. High-Dimensional Statistics: A Non-Asymptotic Viewpoint. Cambridge Series in Statistical and Probabilistic Mathematics. Cambridge University Press, Cambridge, 2019. ISBN 978-1108498029
2019
-
[29]
H. White. A reality check for data snooping. Econometrica, 68 0 (5): 0 1097--1126, 2000
2000
-
[30]
Zhang, Y
Y. Zhang, Y. Zhu, and J. T. Linnainmaa. Man versus machine learning revisited. The Review of Financial Studies, 38 0 (12): 0 3768--3790, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.