Recognition: unknown
Natural gradient descent with momentum
Pith reviewed 2026-05-10 11:06 UTC · model grok-4.3
The pith
Natural momentum dynamics extend gradient descent to better optimize nonlinear manifolds such as neural networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
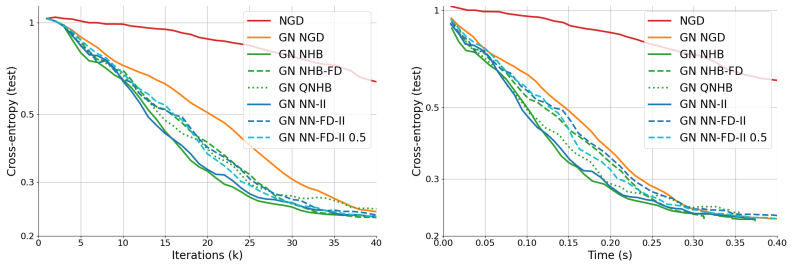
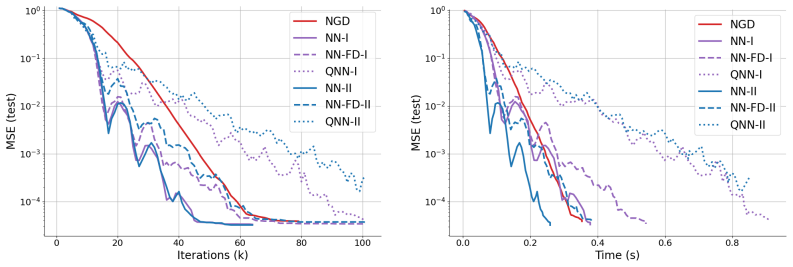
We introduce natural inertial dynamics that precondition gradient steps with the manifold's tangent-space metric and then apply momentum corrections, showing that these dynamics can improve the learning process over nonlinear model classes compared with non-inertial natural gradient descent.
What carries the argument
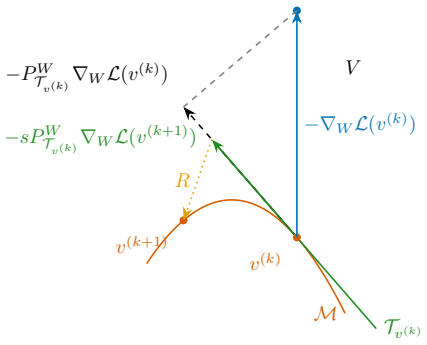
The natural gradient, obtained by inverting the Gram matrix of the generating system of the tangent space to the manifold at the current point, which yields a locally optimal direction in function space; this is then extended by adding velocity terms from classical inertial methods.
If this is right
- The same inertial construction applies directly to losses such as KL divergence in density estimation or residual norms in physics-informed problems.
- Natural momentum updates can reduce the total number of steps needed to reach a given accuracy when the parametrization is nonlinear.
- The approach remains compatible with any differentiable parametrization that admits a computable tangent-space Gram matrix.
Where Pith is reading between the lines
- The same momentum construction could be paired with other manifold-aware preconditioners beyond the basic Gram-matrix natural gradient.
- Scaling tests on high-dimensional tensor networks would clarify whether the inertia benefit persists when the tangent-space metric becomes expensive to form.
- Adaptive schedules for the momentum coefficient might be needed to keep the method stable across different manifold curvatures.
Load-bearing premise
That the added inertial terms produce reliably better trajectories on nonlinear manifolds without causing instability or requiring retuning that cancels any gain.
What would settle it
A side-by-side run on a low-dimensional nonlinear manifold (for example, a simple neural network fitting a known target) in which the natural momentum version requires more iterations or reaches a worse final loss than plain natural gradient descent.
Figures








read the original abstract
We consider the problem of approximating a function by an element of a nonlinear manifold which admits a differentiable parametrization, typical examples being neural networks with differentiable activation functions or tensor networks. Natural gradient descent (NGD) for the optimization of a loss function can be seen as a preconditioned gradient descent where updates in the parameter space are driven by a functional perspective. In a spirit similar to Newton's method, a NGD step uses, instead of the Hessian, the Gram matrix of the generating system of the tangent space to the approximation manifold at the current iterate, with respect to a suitable metric. This corresponds to a locally optimal update in function space, following a projected gradient onto the tangent space to the manifold. Still, both gradient and natural gradient descent methods get stuck in local minima. Furthermore, when the model class is a nonlinear manifold or the loss function is not ideally conditioned (e.g., the KL-divergence for density estimation, or a norm of the residual of a partial differential equation in physics informed learning), even the natural gradient might yield non-optimal directions at each step. This work introduces a natural version of classical inertial dynamic methods like Heavy-Ball or Nesterov and show how it can improve the learning process when working with nonlinear model classes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes natural-gradient adaptations of classical inertial methods (Heavy-Ball and Nesterov) for loss minimization over nonlinear manifolds that admit differentiable parametrizations, such as neural networks and tensor networks. It argues that standard NGD can become trapped in local minima or produce suboptimal steps for ill-conditioned losses (e.g., KL divergence or PDE residuals) and claims that the introduction of natural inertial dynamics improves the learning process.
Significance. If the proposed natural inertial dynamics are rigorously defined, shown to be stable discretizations on the manifold, and empirically validated, the work would supply a principled acceleration technique for natural-gradient optimization on nonlinear model classes. At present the manuscript supplies only an assertion of improvement without derivations, stability analysis, or experiments, so the potential significance cannot yet be evaluated.
major comments (2)
- [Abstract] Abstract: the central claim that the natural inertial methods 'can improve the learning process' is stated without any supporting derivation, convergence analysis, or numerical evidence. This assertion is load-bearing for the paper's contribution and must be substantiated before the manuscript can be assessed.
- [Abstract] Abstract (description of the method): the construction does not specify how the momentum (velocity) term is defined or transported in the tangent bundle. Classical momentum accumulates in parameter space, while NGD preconditions via the Gram matrix of the tangent space; without an explicit rule for projecting or parallel-transporting the velocity, it is unclear whether the resulting discrete update remains a consistent first-order scheme on the manifold.
minor comments (1)
- The abstract lists example model classes (neural networks, tensor networks) and loss functions (KL divergence, PDE residuals) but supplies neither pseudocode nor a concrete update rule that would allow reproduction.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. We agree that the abstract requires revision to substantiate the central claims and to clarify the method construction. We will update the manuscript accordingly in the next version.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the natural inertial methods 'can improve the learning process' is stated without any supporting derivation, convergence analysis, or numerical evidence. This assertion is load-bearing for the paper's contribution and must be substantiated before the manuscript can be assessed.
Authors: We acknowledge that the abstract as written makes an unsubstantiated claim. The manuscript body provides geometric motivation for why inertial terms may help escape poor local minima on nonlinear manifolds, but it does not yet contain a full convergence analysis or systematic experiments. In the revision we will add a short section sketching stability of the discrete scheme under the Riemannian metric, include numerical comparisons on simple neural-network and tensor-network tasks, and rewrite the abstract to summarize these additions. revision: yes
-
Referee: [Abstract] Abstract (description of the method): the construction does not specify how the momentum (velocity) term is defined or transported in the tangent bundle. Classical momentum accumulates in parameter space, while NGD preconditions via the Gram matrix of the tangent space; without an explicit rule for projecting or parallel-transporting the velocity, it is unclear whether the resulting discrete update remains a consistent first-order scheme on the manifold.
Authors: The referee is correct that the abstract omits this detail. The full manuscript defines the velocity update by parallel-transporting the previous momentum vector to the current tangent space via the Levi-Civita connection of the pull-back metric and then adding the natural-gradient step; this construction is intended to keep the iterate consistent with the manifold geometry. We will revise the abstract to mention the parallel-transport step briefly and expand the methods section with the explicit discrete update equations together with a short argument that the scheme remains first-order consistent. revision: yes
Circularity Check
No circularity: derivation builds from standard NGD and inertial methods without self-referential reduction.
full rationale
The provided abstract and description introduce natural inertial dynamics by adapting classical Heavy-Ball/Nesterov momentum to the tangent space via the Gram matrix preconditioner of NGD. No equations, self-citations, or fitted parameters are shown that would make any claimed prediction equivalent to its inputs by construction. The central construction is presented as an extension of existing methods rather than a tautological renaming or load-bearing self-reference. This matches the expectation that most papers are non-circular when the derivation chain remains independent of the target result.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The approximation manifold admits a differentiable parametrization.
- domain assumption The Gram matrix of the tangent-space generators is positive definite and usable as a preconditioner.
Reference graph
Works this paper leans on
-
[1]
P.-A. Absil, R. Mahony, and R. Sepulchre.Optimization Algorithms on Matrix Manifolds. Prince- ton University Press, Dec. 2008.isbn: 978-1-4008-3024-4.doi:10.1515/9781400830244
- [2]
- [3]
-
[4]
Naturalgradientworksefficientlyinlearning
Shun-ichi Amari. “Natural Gradient Works Efficiently in Learning”. In:Neural Computation10.2 (Feb. 1998), pp. 251–276.issn: 0899-7667, 1530-888X.doi:10.1162/089976698300017746
-
[5]
Neural Learning in Structured Parameter Spaces - Natural Riemannian Gra- dient
Shun-ichi Amari. “Neural Learning in Structured Parameter Spaces - Natural Riemannian Gra- dient”. In:Advances in Neural Information Processing Systems. Vol. 9. MIT Press, 1996
1996
-
[6]
H. Attouch and J. Fadili.From the Ravine Method to the Nesterov Method and Vice Versa: A Dynamical System Perspective. Feb. 2022. arXiv:2201.11643 [cs, math]
-
[7]
Hedy Attouch, Zaki Chbani, Jalal Fadili, and Hassan Riahi.First-Order Optimization Algorithms via Inertial Systems with Hessian Driven Damping. Nov. 2020.doi:10.48550/arXiv.1907. 10536. arXiv:1907.10536 [math]
-
[8]
May 2025.doi:10.48550/arXiv.2505.11938
Daan Bon, Benjamin Caris, and Olga Mula.Stable Nonlinear Dynamical Approximation with Dynamical Sampling. May 2025.doi:10.48550/arXiv.2505.11938. arXiv:2505.11938 [math]
-
[9]
Benedikt Brantner.Generalizing Adam to Manifolds for Efficiently Training Transformers. Dec
- [10]
-
[11]
M´ ethode g´ en´ erale pour la r´ esolution des syst` emes d’´ equations simul- tan´ ees
Augustin-Louis Cauchy. “M´ ethode g´ en´ erale pour la r´ esolution des syst` emes d’´ equations simul- tan´ ees”. In:Comptes rendus hebdomadaires des s´ eances de l’Acad´ emie des sciences. July 1847, pp. 536–538. 24
-
[12]
A Kaczmarz-inspired Approach to Accelerate the Optimization of Neural Network Wavefunctions
Gil Goldshlager, Nilin Abrahamsen, and Lin Lin. “A Kaczmarz-inspired Approach to Accelerate the Optimization of Neural Network Wavefunctions”. In:Journal of Computational Physics516 (Nov. 2024), p. 113351.issn: 00219991.doi:10.1016/j.jcp.2024.113351
- [13]
-
[14]
Andr´ es Guzm´ an-Cordero, Felix Dangel, Gil Goldshlager, and Marius Zeinhofer.Improving Energy Natural Gradient Descent through Woodbury, Momentum, and Randomization. Oct. 2025.doi: 10.48550/arXiv.2505.12149. arXiv:2505.12149 [cs]
- [15]
-
[16]
Johannes M¨ uller and Marius Zeinhofer.Achieving High Accuracy with PINNs via Energy Natural Gradients. Aug. 2023.doi:10.48550/arXiv.2302.13163. arXiv:2302.13163 [cs]
- [17]
-
[18]
Chenyi Li, Shuchen Zhu, Zhonglin Xie, and Zaiwen Wen.Accelerated Natural Gradient Method for Parametric Manifold Optimization. Apr. 2025.doi:10.48550/arXiv.2504.05753. arXiv: 2504.05753 [math]
- [19]
-
[20]
Optimizing neural networks with kronecker-factored approximate curvature.arXiv:1503.05671, 2020
James Martens and Roger Grosse.Optimizing Neural Networks with Kronecker-factored Approx- imate Curvature. June 2020. arXiv:1503.05671 [cs, stat]
-
[21]
May 2024.doi:10.48550/arXiv.2402.07318
Johannes M¨ uller and Marius Zeinhofer.Position: Optimization in SciML Should Employ the Function Space Geometry. May 2024.doi:10.48550/arXiv.2402.07318. arXiv:2402.07318 [math]
-
[22]
A Method for Solving the Convex Programming Problem with Convergence Rate O(1/Kˆ2)
Yurii Nesterov. “A Method for Solving the Convex Programming Problem with Convergence Rate O(1/Kˆ2)”. In:Proceedings of the USSR Academy of Sciences269 (1983), pp. 543–547
1983
-
[23]
Anthony Nouy and Bertrand Michel. “Weighted least-squares approximation with determinantal point processes and generalized volume sampling”. In:SMAI Journal of computational mathe- matics11 (2025), pp. 1–36.issn: 2426-8399.doi:10.5802/smai-jcm.117
-
[24]
Ohad Kammar.A Note on Fr´ echet Diffrentiation under Lebesgue Integrals. 2016
2016
-
[25]
Adaptive Natural Gradient Learning Algorithms for Various Stochastic Models
H Park, S.-I Amari, and K Fukumizu. “Adaptive Natural Gradient Learning Algorithms for Various Stochastic Models”. In:Neural Networks13.7 (Sept. 2000), pp. 755–764.issn: 08936080. doi:10.1016/S0893-6080(00)00051-4
-
[26]
On the Difficulty of Training Recurrent Neural Networks
Razvan Pascanu, Tomas Mikolov, and Yoshua Bengio. “On the Difficulty of Training Recurrent Neural Networks”. In:Proceedings of the 30th International Conference on Machine Learning. Ed. by Sanjoy Dasgupta and David McAllester. Vol. 28. Proceedings of Machine Learning Research. Atlanta, Georgia, USA: PMLR, June 2013, pp. 1310–1318
2013
-
[27]
Jan Peters and Stefan Schaal. “Natural Actor-Critic”. In:Neurocomputing71.7-9 (Mar. 2008), pp. 1180–1190.issn: 09252312.doi:10.1016/j.neucom.2007.11.026
-
[28]
Some methods of speeding up the convergence of iteration methods
B.T. Polyak. “Some Methods of Speeding up the Convergence of Iteration Methods”. In:USSR Computational Mathematics and Mathematical Physics4.5 (Jan. 1964), pp. 1–17.issn: 00415553. doi:10.1016/0041-5553(64)90137-5
-
[29]
Nilo Schwencke and Cyril Furtlehner.ANaGRAM: A Natural Gradient Relative to Adapted Model for Efficient PINNs Learning. Dec. 2024.doi:10.48550/arXiv.2412.10782. arXiv:2412.10782 [cs]. 25
-
[30]
Weijie Su, Stephen Boyd, and Emmanuel J. Candes.A Differential Equation for Modeling Nes- terov’s Accelerated Gradient Method: Theory and Insights. Oct. 2015.doi:10.48550/arXiv. 1503.01243. arXiv:1503.01243 [stat]
work page internal anchor Pith review doi:10.48550/arxiv 2015
-
[31]
Hongyi Zhang and Suvrit Sra.Towards Riemannian Accelerated Gradient Methods. June 2018. doi:10.48550/arXiv.1806.02812. arXiv:1806.02812 [cs, math]. A Proof of Proposition 4.1 ( Quasi-Natural Heavy-Ball ap- proximation) First we develop ∥ψ(k)T p(k) −ψ (k)T p(k)∥X =β k∥ψ(k)T p(k−1) −ψ (k)T G(k)† X G(k,k−1) X p(k−1)∥X =β k∥ψ(k)T (I−G (k)† X G(k,k−1) X )p(k−1...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.