Recognition: unknown
Why Fine-Tuning Encourages Hallucinations and How to Fix It
Pith reviewed 2026-05-10 10:47 UTC · model grok-4.3
The pith
Supervised fine-tuning on new facts increases hallucinations about pre-trained knowledge primarily through interference among overlapping semantic representations, and self-distillation mitigates this by regularizing output drift.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
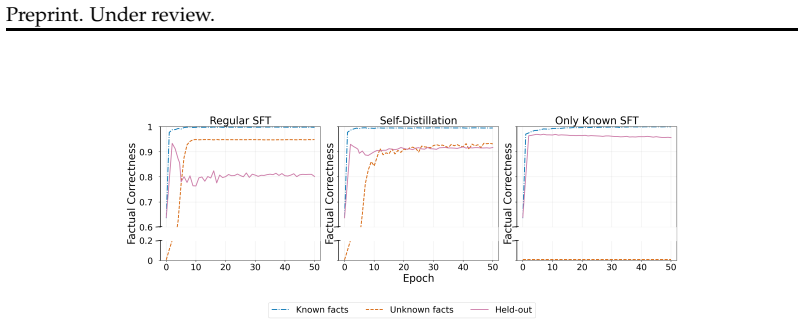
Supervised fine-tuning on new factual information degrades performance on pre-training knowledge by causing interference among overlapping semantic representations. Self-distillation mitigates hallucinations by regularizing the drift in output distributions, thereby preserving prior knowledge while enabling effective acquisition of new facts. Experiments confirm that localized semantic interference, rather than capacity limitations or behavior cloning, is the main driver of the increased hallucinations.
What carries the argument
Localized semantic interference among overlapping representations, addressed through output-distribution regularization in self-distillation.
If this is right
- Self-distillation enables factual learning with reduced hallucinations on pre-trained knowledge.
- Freezing parameter groups suppresses factual plasticity and reduces hallucinations in cases where new knowledge acquisition is not required.
- Mitigating semantic interference directly addresses the root cause of SFT-induced hallucinations.
Where Pith is reading between the lines
- Similar output-regularization methods could help retain knowledge across a wider range of fine-tuning tasks that do not involve new factual content.
- The interference pattern may appear in other training regimes that mix old and new information, such as multi-task learning.
- Testing the same regularization on models of different sizes could reveal whether larger capacity reduces the severity of representation overlap.
Load-bearing premise
The increase in hallucinations during supervised fine-tuning stems primarily from knowledge degradation due to localized semantic interference rather than from data quality issues or optimization dynamics.
What would settle it
If applying self-distillation during fine-tuning failed to reduce hallucinations on pre-training facts while new facts were still acquired accurately, the claim that semantic interference is the primary driver would be undermined.
Figures








read the original abstract
Large language models are prone to hallucinating factually incorrect statements. A key source of these errors is exposure to new factual information through supervised fine-tuning (SFT), which can increase hallucinations w.r.t. knowledge acquired during pre-training. In this work, we explore whether SFT-induced hallucinations can be mitigated using established tools from the continual learning literature, since they arise as a by-product of knowledge degradation during training. We propose a self-distillation-based SFT method that facilitates effective factual learning while minimizing hallucinations w.r.t. pre-existing knowledge by regularizing output-distribution drift. We also show that, in settings where new knowledge acquisition is unnecessary, suppressing factual plasticity by freezing parameter groups, can preserve task performance while reducing hallucinations. Lastly, we investigate the mechanism behind SFT-induced hallucinations through three hypotheses: capacity limitations, behavior cloning, and localized interference. Our experiments show that a main driver is interference among overlapping semantic representations, and that self-distillation succeeds by mitigating this interference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that supervised fine-tuning (SFT) on new facts increases hallucinations in LLMs relative to pre-trained knowledge, primarily due to interference among overlapping semantic representations rather than capacity limits or behavior cloning. It proposes a self-distillation SFT method that regularizes output-distribution drift to enable factual learning while reducing hallucinations, and shows that freezing parameter groups can suppress plasticity (and thus hallucinations) when new knowledge acquisition is unnecessary. Experiments across the three hypotheses support interference as the main driver and indicate that self-distillation mitigates it.
Significance. If the central empirical claims hold after addressing controls, the work would provide a practical, low-overhead mitigation for a common failure mode in post-training and a mechanistic account grounded in continual-learning ideas. The self-distillation and selective-freezing approaches are straightforward to implement and could be adopted quickly; the interference hypothesis, if cleanly isolated, would also inform representation-level diagnostics for hallucination risk.
major comments (2)
- [Experiments on hypotheses] The section describing the three-hypothesis experiments: the attribution of SFT-induced hallucinations to localized semantic interference (rather than data quality, optimization dynamics, or other correlated factors) is load-bearing for the 'main driver' conclusion, yet the reported comparisons lack explicit controls such as matched data curation, fixed optimizer hyperparameters, or regression of interference metrics (e.g., embedding cosine or activation overlap) against those confounds. Without such ablations, the results remain compatible with general regularization effects.
- [Self-distillation SFT method] The self-distillation method (output-distribution regularization): the claim that it specifically mitigates semantic interference would be strengthened by a direct comparison to other standard regularizers (e.g., label smoothing or KL to a frozen teacher without the self-distillation schedule) to show that the benefit is not explained by generic regularization alone.
minor comments (2)
- [Abstract] The abstract and method sections should report effect sizes, confidence intervals, and the statistical tests used for the hallucination-rate differences; the current description leaves the magnitude and reliability of the improvements unclear.
- [Method] Notation for the output-distribution regularization term and the freezing criteria should be defined explicitly (e.g., which layers or parameter groups are frozen and under what condition) to allow exact reproduction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comments point by point below and will revise the paper accordingly to strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [Experiments on hypotheses] The section describing the three-hypothesis experiments: the attribution of SFT-induced hallucinations to localized semantic interference (rather than data quality, optimization dynamics, or other correlated factors) is load-bearing for the 'main driver' conclusion, yet the reported comparisons lack explicit controls such as matched data curation, fixed optimizer hyperparameters, or regression of interference metrics (e.g., embedding cosine or activation overlap) against those confounds. Without such ablations, the results remain compatible with general regularization effects.
Authors: We agree that the current set of experiments would benefit from additional controls to more rigorously isolate localized semantic interference as the primary driver. In the revised manuscript, we will add ablations that enforce matched data curation across all conditions, fix optimizer hyperparameters explicitly, and include regression analyses correlating interference metrics (such as embedding cosine similarity and activation overlap) with hallucination rates while controlling for confounds. These additions will help distinguish the interference hypothesis from general regularization effects. revision: yes
-
Referee: [Self-distillation SFT method] The self-distillation method (output-distribution regularization): the claim that it specifically mitigates semantic interference would be strengthened by a direct comparison to other standard regularizers (e.g., label smoothing or KL to a frozen teacher without the self-distillation schedule) to show that the benefit is not explained by generic regularization alone.
Authors: We thank the referee for highlighting this opportunity to demonstrate specificity. In the revision, we will include direct empirical comparisons of our self-distillation SFT method against label smoothing and against standard KL divergence to a frozen teacher (without the self-distillation schedule). These controls will clarify whether the reduction in hallucinations arises specifically from regularizing output-distribution drift in the context of new factual learning, as opposed to generic regularization. revision: yes
Circularity Check
No circularity: empirical claims rest on independent experimental comparisons
full rationale
The paper advances no mathematical derivation chain or first-principles predictions. Its central claims—that interference among overlapping semantic representations drives SFT hallucinations and that self-distillation mitigates it—are supported by direct experimental comparisons across three hypotheses (capacity limits, behavior cloning, localized interference). These rest on observable metrics and ablations rather than any quantity defined in terms of itself, any fitted parameter renamed as a prediction, or load-bearing self-citations. The proposed self-distillation method is an application of a standard continual-learning technique whose success is measured against external benchmarks (hallucination rates, factual retention) without reducing to the inputs by construction. The analysis is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Supervised fine-tuning on new factual information degrades performance on pre-training knowledge in LLMs
- domain assumption Output-distribution drift during SFT is a controllable proxy for knowledge degradation
Forward citations
Cited by 1 Pith paper
-
Hallucinations Undermine Trust; Metacognition is a Way Forward
LLMs need metacognition to align expressed uncertainty with their actual knowledge boundaries, moving beyond knowledge expansion to reduce confident errors.
Reference graph
Works this paper leans on
-
[1]
Zorik Gekhman, Gal Yona, Roee Aharoni, Matan Eyal, Amir Feder, Roi Reichart, and Jonathan Herzig
URLhttps://arxiv.org/abs/2412.11965. Zorik Gekhman, Gal Yona, Roee Aharoni, Matan Eyal, Amir Feder, Roi Reichart, and Jonathan Herzig. Does fine-tuning llms on new knowledge encourage hallucinations?,
-
[2]
Gao, D., Wang, H., Li, Y., et al
URLhttps://arxiv.org/abs/2405.05904. Zorik Gekhman, Eyal Ben David, Hadas Orgad, Eran Ofek, Yonatan Belinkov, Idan Szpektor, Jonathan Herzig, and Roi Reichart. Inside-out: Hidden factual knowledge in llms, 2025. URLhttps://arxiv.org/abs/2503.15299. Zorik Gekhman, Roee Aharoni, Eran Ofek, Mor Geva, Roi Reichart, and Jonathan Herzig. Thinking to recall: How...
-
[3]
Distilling the Knowledge in a Neural Network
URLhttps://arxiv.org/abs/1503.02531. Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, and Ting Liu. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.ACM Transactions on Information Systems, 43(2):1–55, January 2025. ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1145/3703155 2025
-
[4]
How do language models learn facts? dynamics, curricula and hallucinations
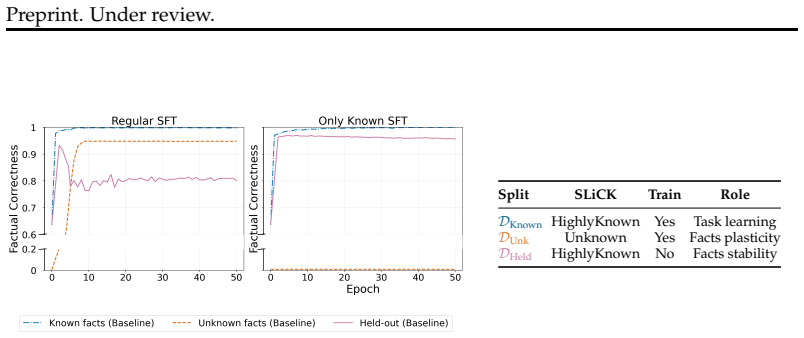
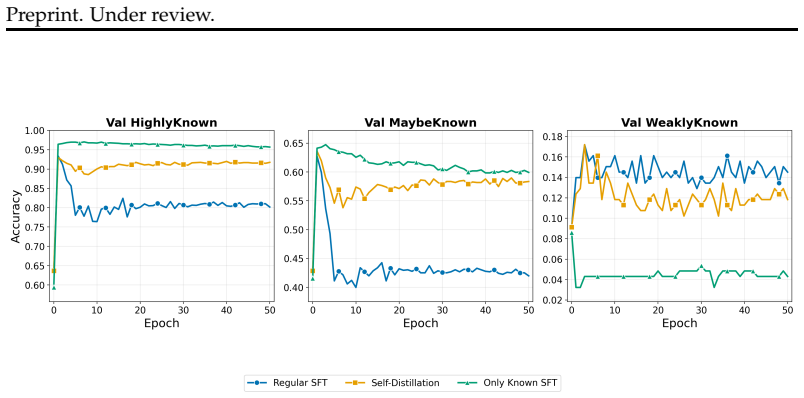
URLhttps://arxiv.org/abs/2503.21676. A Results Over Other SLiCK Classification Groups The main experiments focus onHighlyKnownfacts throughout, on both the training and validation sides. This choice follows a consistent principle. On the training side, the role of DKnown is to teach the model the QA task format without introducing any new factual content....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.