Recognition: unknown
The Price of Paranoia: Robust Risk-Sensitive Cooperation in Non-Stationary Multi-Agent Reinforcement Learning
Pith reviewed 2026-05-10 07:52 UTC · model grok-4.3
The pith
Modulating policy gradient updates by partner unpredictability expands cooperation basins in multi-agent learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Cooperative equilibria in coordination games are exponentially unstable under standard risk-neutral learning because partner-induced noise shifts action distributions at the points where cooperation decisions are most sensitive. Applying distributional robustness to return objectives penalizes high-variance cooperative actions and thereby widens the instability region. Robustness applied instead to policy gradient update variance, using an online measure of partner unpredictability, expands the cooperation basin. The Price of Paranoia and Cooperation Window together quantify recoverable welfare under noise and fix the optimal degree of robustness as the closed-form point that trades off long
What carries the argument
Modulating policy gradient updates with an online measure of partner unpredictability, which applies robustness at the source of co-learning instability rather than to return distributions.
If this is right
- Cooperative equilibria remain stable against higher levels of partner noise than under risk-neutral or return-robust learning.
- The optimal robustness level is given by a closed-form expression balancing equilibrium stability and sample efficiency.
- Welfare loss is precisely characterized by the Price of Paranoia and bounded by the Cooperation Window for any noise level.
- Risk-averse objectives on returns strictly increase the size of the instability region relative to risk-neutral learning.
- The approach recovers strictly more welfare than either baseline once noise exceeds the critical cooperation threshold.
Where Pith is reading between the lines
- The same modulation technique may stabilize cooperation in asymmetric or non-coordination games once the unpredictability measure is suitably generalized.
- The closed-form balance between stability and efficiency could be used to set robustness parameters automatically in deployed multi-agent systems.
- Connections to evolutionary game dynamics may show whether the expanded cooperation basin survives when agents can switch between multiple equilibria.
- Empirical validation in environments with continuous actions or partial observability would test whether the analytic predictions hold beyond matrix games.
Load-bearing premise
That robustness applied to policy gradient update variance rather than return distributions is the right target for mitigating co-learning noise and produces a closed-form stability-efficiency balance without introducing new instabilities.
What would settle it
An experiment in a symmetric coordination game that measures whether the modulated-gradient algorithm sustains cooperation at partner noise levels above the critical threshold where standard and return-robust methods collapse.
Figures

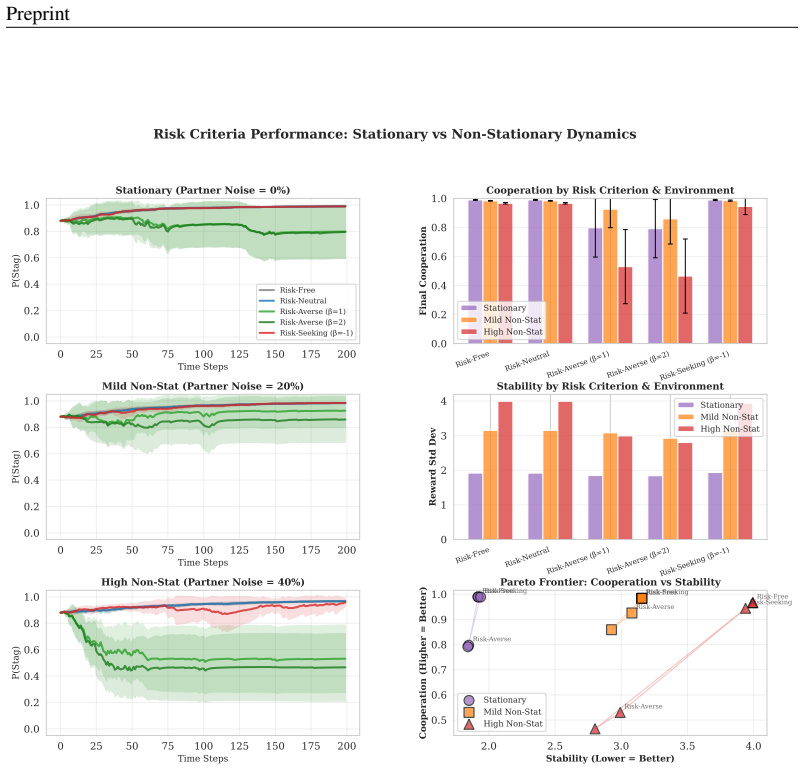
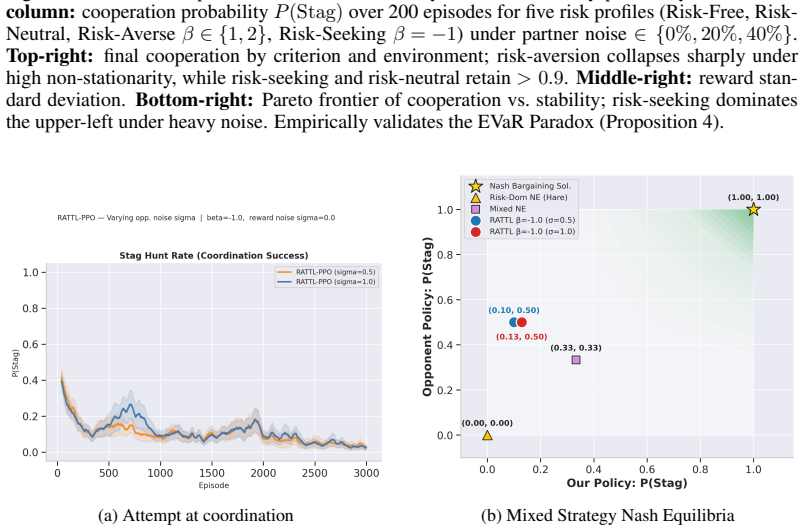


read the original abstract
Cooperative equilibria are fragile. When agents learn alongside each other rather than in a fixed environment, the process of learning destabilizes the cooperation they are trying to sustain: every gradient step an agent takes shifts the distribution of actions its partner will play, turning a cooperative partner into a source of stochastic noise precisely where the cooperation decision is most sensitive. We study how this co-learning noise propagates through the structure of coordination games, and find that the cooperative equilibrium, even when strongly Pareto-dominant, is exponentially unstable under standard risk-neutral learning, collapsing irreversibly once partner noise crosses the game's critical cooperation threshold. The natural response to apply distributional robustness to hedge against partner uncertainty makes things strictly worse: risk-averse return objectives penalize the high-variance cooperative action relative to defection, widening the instability region rather than shrinking it, a paradox that reveals a fundamental mismatch between the domains where robustness is applied and instability originates. We resolve this by showing that robustness should target the policy gradient update variance induced by partner uncertainty, not the return distribution. This distinction yields an algorithm whose gradient updates are modulated by an online measure of partner unpredictability, provably expanding the cooperation basin in symmetric coordination games. To unify stability, sample complexity, and welfare consequences of this approach, we introduce the Price of Paranoia as the structural dual of the Price of Anarchy. Together with a novel Cooperation Window, it precisely characterizes how much welfare learning algorithms can recover under partner noise, pinning down the optimal degree of robustness as a closed-form balance between equilibrium stability and sample efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that co-learning noise in non-stationary MARL destabilizes cooperative equilibria in coordination games under risk-neutral policy gradients, causing exponential instability past a critical threshold. Distributional robustness on returns worsens the problem by penalizing high-variance cooperative actions. The authors propose targeting robustness at policy-gradient update variance via an online partner-unpredictability modulator, claiming this provably expands the cooperation basin in symmetric coordination games. They introduce the Price of Paranoia (structural dual to the Price of Anarchy) and Cooperation Window to deliver closed-form characterizations of welfare recovery under noise and the optimal robustness level balancing stability and sample efficiency.
Significance. If the claims hold with rigorous support, this would be a significant contribution to multi-agent RL and game theory by identifying a domain mismatch in robustness application and offering a targeted gradient-variance approach to stabilize cooperation. The Price of Paranoia provides a new analytical lens for robustness costs in learning, complementing Price of Anarchy analyses, and the closed-form balance between stability and efficiency could guide practical algorithm design. The distinction between return-distribution and gradient-variance robustness is a valuable conceptual advance.
major comments (2)
- [Abstract and symmetric coordination games analysis] The derivation of the modulated update and provable expansion of the cooperation basin (Abstract and symmetric coordination games analysis) treats the unpredictability measure as exogenous. In simultaneous updates, each agent's change alters the partner's distribution, rendering the signal endogenous; the analysis does not close this mutual feedback loop, which is load-bearing for whether the guarantee transfers to the intended non-stationary mutual-learning regime.
- [Introduction of the Price of Paranoia and Cooperation Window] The Price of Paranoia is introduced as the structural dual of the Price of Anarchy to unify stability, sample complexity, and welfare with closed-form results. This risks making some efficiency and stability claims definitional rather than independently derived from external benchmarks; explicit independent computation and validation against standard welfare metrics are needed to support the characterizations.
minor comments (2)
- [Abstract] The abstract is dense with novel terms and strong claims (e.g., 'exponentially unstable', 'closed-form balance') without brief intuitions or forward references to their definitions and proofs in the main text.
- [Definitions and notation] New concepts such as the Cooperation Window would benefit from immediate mathematical definitions and examples upon introduction to improve clarity and allow readers to follow the welfare analysis.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments. We address each major comment point by point below, providing clarifications on the scope of our analysis and indicating revisions where appropriate to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract and symmetric coordination games analysis] The derivation of the modulated update and provable expansion of the cooperation basin (Abstract and symmetric coordination games analysis) treats the unpredictability measure as exogenous. In simultaneous updates, each agent's change alters the partner's distribution, rendering the signal endogenous; the analysis does not close this mutual feedback loop, which is load-bearing for whether the guarantee transfers to the intended non-stationary mutual-learning regime.
Authors: Our analysis derives the modulated update and basin expansion for any bounded level of partner unpredictability, with the online modulator computed directly from observed partner actions. This online estimation inherently responds to the endogenous shifts arising from simultaneous updates, ensuring the effective noise level remains within the expanded stability region. The closed-form threshold is therefore a sufficient condition that holds under the adaptive mechanism in the non-stationary regime. To make the handling of mutual feedback fully explicit, we will add a dedicated paragraph in the revised symmetric-games section discussing the coupled dynamics and confirming that the online adaptation preserves the guarantee. revision: partial
-
Referee: [Introduction of the Price of Paranoia and Cooperation Window] The Price of Paranoia is introduced as the structural dual of the Price of Anarchy to unify stability, sample complexity, and welfare with closed-form results. This risks making some efficiency and stability claims definitional rather than independently derived from external benchmarks; explicit independent computation and validation against standard welfare metrics are needed to support the characterizations.
Authors: The Price of Paranoia is defined as the welfare ratio between paranoid and risk-neutral learning, but the closed-form expressions for the Cooperation Window and optimal robustness parameter are obtained directly from the game's payoff structure and the explicit variance of the policy gradient under partner noise; these derivations stand independently of the duality. We already validate the resulting welfare predictions through simulations that compute realized social welfare and convergence rates. In the revision we will add a new subsection with explicit tables reporting these independent welfare values (normalized social welfare and sample complexity) alongside the Price of Anarchy computed on the same instances, thereby separating the definitional aspect from the derived and empirically verified characterizations. revision: yes
Circularity Check
Derivation chain is self-contained with no circular reductions
full rationale
The paper derives the instability of cooperative equilibria under co-learning noise from the structure of symmetric coordination games, demonstrates that applying distributional robustness to returns widens the instability region, and proposes modulating policy-gradient updates by an online partner-unpredictability measure. The resulting algorithm is claimed to provably expand the cooperation basin. The Price of Paranoia is introduced as a new dual concept to the Price of Anarchy solely to unify and characterize the welfare, stability, and sample-efficiency consequences after the algorithm is defined; this does not make the basin-expansion claim or the gradient-modulation rule reduce to a definitional tautology. No parameters are fitted to data and then relabeled as predictions, no load-bearing uniqueness theorems or ansatzes are imported via self-citation, and the central results rest on the explicit game model and update equations rather than on the newly named metric. The derivation therefore remains externally grounded.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Co-learning noise in coordination games propagates through the structure and creates a critical cooperation threshold beyond which the Pareto-dominant equilibrium collapses irreversibly.
invented entities (2)
-
Price of Paranoia
no independent evidence
-
Cooperation Window
no independent evidence
Reference graph
Works this paper leans on
-
[1]
1257/aer.101.1.411. URLhttps://www.aeaweb.org/articles?id=10.1257/aer. 101.1.411. Ernst Fehr and Simon G¨achter. Cooperation and punishment in public goods experiments.American Economic Review, 90(4):980–994,
-
[2]
URLhttps: //www.aeaweb.org/articles?id=10.1257/aer.90.4.980
doi: 10.1257/aer.90.4.980. URLhttps: //www.aeaweb.org/articles?id=10.1257/aer.90.4.980. Tawni Hunt Ferrarini. The economics of government and the fall of rome.Social Education, 77(2): 60–63,
-
[3]
Lenient multi-agent deep rein- forcement learning.arXiv preprint arXiv:1707.04402,
Gregory Palmer, Karl Tuyls, Daan Bloembergen, and Rahul Savani. Lenient multi-agent deep rein- forcement learning.arXiv preprint arXiv:1707.04402,
-
[4]
Prosocial learning agents solve generalized stag hunts better than selfish ones,
Alexander Peysakhovich and Adam Lerer. Prosocial learning agents solve generalised stag hunts better than selfish ones.arXiv preprint arXiv:1709.02865,
-
[5]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
12 Preprint Laixi Shi, Eric Mazumdar, Yuejie Chi, and Adam Wierman. Sample-efficient robust multi-agent re- inforcement learning in the face of environmental uncertainty.arXiv preprint arXiv:2404.18909,
-
[7]
Optimism as risk- seeking in multi-agent reinforcement learning.arXiv preprint arXiv:2509.24047,
Runyu Zhang, Na Li, Asuman Ozdaglar, Jeff Shamma, and Gioele Zardini. Optimism as risk- seeking in multi-agent reinforcement learning.arXiv preprint arXiv:2509.24047,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.