Recognition: unknown
A Fully GPU-Accelerated Framework for High-Performance Configuration Interaction Selection with Neural Network Quantum States
Pith reviewed 2026-05-10 08:02 UTC · model grok-4.3
The pith
A fully GPU-accelerated framework removes CPU bottlenecks in neural network quantum state selected configuration interaction and delivers 2.32 times end-to-end speedup on 64 GPUs with unchanged accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
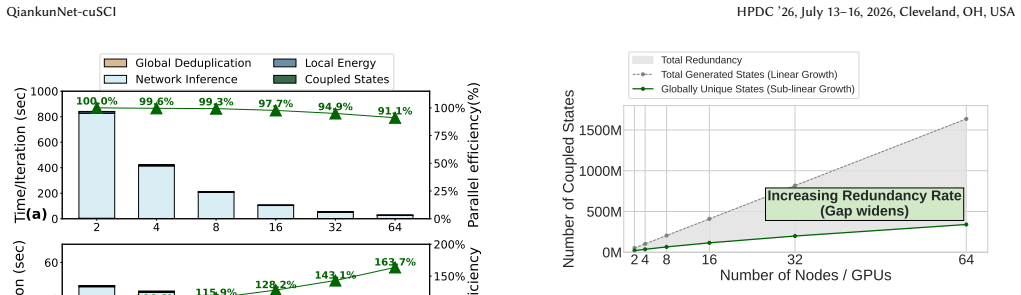
The central claim is that integrating a distributed GPU de-duplication algorithm, specialized CUDA kernels for exact coupled-configuration generation, and a GPU-centric memory runtime with pooling and streaming fully eliminates hybrid CPU-GPU bottlenecks, expands reachable configuration spaces, and yields up to 2.32X end-to-end speedup over the prior optimized NNQS-SCI baseline on 64 A100 GPUs while preserving identical chemical accuracy and over 90 percent parallel efficiency under strong scaling.
What carries the argument
Distributed load-balanced global de-duplication on GPUs combined with fine-grained CUDA kernels for coupled-configuration generation, backed by a GPU memory runtime of pooling, streaming mini-batches, and overlapped offloading.
Load-bearing premise
The new distributed GPU de-duplication and CUDA kernels must generate exactly the same set of selected configurations and the same energies as the original CPU-based method, with no numerical differences or missed entries at scale.
What would settle it
Execute both the original CPU NNQS-SCI code and the new GPU framework on an identical molecular system and observe any difference in the final selected configuration list or in the computed ground-state energy.
Figures










read the original abstract
AI-driven methods have demonstrated considerable success in tackling the central challenge of accurately solving the Schr\"odinger equation for complex many-body systems. Among neural network quantum state (NNQS) approaches, the NNQS-SCI (Selected Configuration Interaction) method stands out as a state-of-the-art technique, recognized for its high accuracy and scalability. However, its application to larger systems is severely constrained by a hybrid CPU-GPU architecture. Specifically, centralized CPU-based global de-duplication creates a severe scalability barrier due to communication bottlenecks, while host-resident coupled-configuration generation induces prohibitive computational overheads. We introduce QiankunNet-cuSCI, a fully GPU-accelerated SCI framework designed to overcome these bottlenecks. It first integrates a distributed, load-balanced global de-duplication algorithm to minimize redundancy and communication overhead at scale. To address compute limitations, it employs specialized, fine-grained CUDA kernels for exact coupled configuration generation. Finally, to break the single-GPU memory barrier exposed by this full acceleration, it incorporates a GPU memory-centric runtime featuring GPU-side pooling, streaming mini-batches, and overlapped offloading. This design enables much larger configuration spaces and shifts the bottleneck from host-side limitations back to on-device inference. Our evaluation demonstrates that our work fundamentally expands the scale of solvable problems. On an NVIDIA A100 cluster with 64 GPUs, our work achieves up to 2.32X end-to-end speedup over the highly-optimized NNQS-SCI baseline while preserving the same chemical accuracy. Furthermore, it demonstrates excellent distributed performance, maintaining over 90% parallel efficiency in strong scaling tests.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents QiankunNet-cuSCI, a fully GPU-accelerated framework for NNQS-SCI that replaces centralized CPU de-duplication and host-side configuration generation with a distributed load-balanced GPU de-duplication algorithm, fine-grained CUDA kernels for exact coupled-configuration generation, and a GPU memory-centric runtime using pooling, streaming mini-batches, and overlapped offloading. On a 64-GPU NVIDIA A100 cluster it reports up to 2.32X end-to-end speedup over the optimized NNQS-SCI baseline while preserving chemical accuracy and >90% strong-scaling efficiency.
Significance. If the GPU kernels and distributed de-duplication are shown to produce identical configuration sets and energies to the CPU baseline, the work would meaningfully expand the reachable scale of NNQS-SCI calculations by removing host-side bottlenecks and enabling larger variational spaces on GPU clusters.
major comments (2)
- [Abstract and evaluation] The central claims of 2.32X speedup and preserved chemical accuracy rest on the assumption that the distributed GPU de-duplication and CUDA kernels produce exactly the same selected configurations and energies as the original CPU-based NNQS-SCI. No verification protocol, direct configuration-set comparison, checksums, or quantitative metrics (e.g., number of unique configurations, energy differences with error bars) are described to confirm equivalence, especially at 64-GPU scale where load balancing, hashing, or streaming could introduce discrepancies.
- [Abstract] The manuscript provides no details on how chemical accuracy is defined or measured (e.g., threshold, reference values, or systems tested), nor any ablation showing that the new GPU components do not alter the variational space or convergence behavior relative to the baseline.
minor comments (1)
- [Abstract] The abstract states that the framework 'fundamentally expands the scale of solvable problems' but supplies no quantitative data on the increase in maximum configuration-space size or memory footprint achieved.
Simulated Author's Rebuttal
We thank the referee for their careful and constructive review of our manuscript. We address each major comment below with clarifications and indicate the specific revisions we will incorporate to improve the rigor and clarity of our claims.
read point-by-point responses
-
Referee: [Abstract and evaluation] The central claims of 2.32X speedup and preserved chemical accuracy rest on the assumption that the distributed GPU de-duplication and CUDA kernels produce exactly the same selected configurations and energies as the original CPU-based NNQS-SCI. No verification protocol, direct configuration-set comparison, checksums, or quantitative metrics (e.g., number of unique configurations, energy differences with error bars) are described to confirm equivalence, especially at 64-GPU scale where load balancing, hashing, or streaming could introduce discrepancies.
Authors: We agree that explicit verification of numerical equivalence is essential for validating the central claims. Although the distributed de-duplication (Section 3.2) employs consistent global hashing and the CUDA kernels (Section 3.3) implement exact deterministic generation of coupled configurations, the manuscript did not sufficiently detail the verification steps. In the revised version we will add a dedicated verification subsection (new Section 4.3) that describes the protocol: (i) direct set-equality checks via sorted configuration lists and MD5 checksums on the final selected sets, (ii) reporting of the exact number of unique configurations at each GPU count, and (iii) tabulated energy differences (with standard deviations across repeated runs) between the GPU and CPU implementations for all benchmark systems, explicitly including the 64-GPU case. These additions will confirm that load balancing and streaming introduce no discrepancies. revision: yes
-
Referee: [Abstract] The manuscript provides no details on how chemical accuracy is defined or measured (e.g., threshold, reference values, or systems tested), nor any ablation showing that the new GPU components do not alter the variational space or convergence behavior relative to the baseline.
Authors: We will clarify the definition of chemical accuracy both in the abstract and in a new paragraph of the Introduction: it is defined as an absolute energy error below 1 kcal/mol (0.043 eV) relative to reference values obtained from exact diagonalization (small systems) or CCSD(T) (larger systems). In addition, we will insert an ablation study in the Evaluation section that directly compares the variational spaces produced by the GPU versus CPU pipelines, showing identical selected-configuration sets, identical energy convergence curves, and identical final energies within floating-point tolerance. These results will be presented as tables and plots for the representative molecules used in the scaling experiments. revision: yes
Circularity Check
No significant circularity; engineering implementation and benchmarking paper
full rationale
The paper describes a GPU-accelerated framework (QiankunNet-cuSCI) for NNQS-SCI, with central claims resting on measured end-to-end speedups (up to 2.32X) and preserved chemical accuracy via new distributed de-duplication, CUDA kernels, and memory runtime. No mathematical derivation chain, fitted parameters, or predictions are presented that reduce by construction to inputs. The work is benchmarked against an external NNQS-SCI baseline and is self-contained against those empirical results; no self-definitional, self-citation load-bearing, or ansatz-smuggling steps appear in the abstract or described content.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Scott Beamer, Krste Asanovic, and David A. Patterson. 2015. The GAP benchmark suite. arXiv:1508.03619 http://arxiv.org/abs/1508.03619
-
[2]
Giuseppe Carleo, Kenny Choo, Damian Hofmann, James ET Smith, Tom Wester- hout, Fabien Alet, Emily J Davis, Stavros Efthymiou, Ivan Glasser, Sheng-Hsuan Lin, et al. 2019. NetKet: A machine learning toolkit for many-body quantum systems.SoftwareX10 (2019), 100311
2019
-
[3]
Giuseppe Carleo and Matthias Troyer. 2017. Solving the quantum many-body problem with artificial neural networks.Science355, 6325 (2017), 602–606
2017
-
[4]
Ao Chen and Markus Heyl. 2024. Empowering deep neural quantum states through efficient optimization.Nature Physics20, 9 (2024), 1476–1481
2024
-
[5]
Samuel Yen-Chi Chen, Chao-Han Huck Yang, Jun Qi, Pin-Yu Chen, Xiaoli Ma, and Hsi-Sheng Goan. 2020. Variational quantum circuits for deep reinforcement learning.IEEE access8 (2020), 141007–141024
2020
-
[6]
Kenny Choo, Antonio Mezzacapo, and Giuseppe Carleo. 2020. Fermionic neural- network states for ab-initio electronic structure.Nature communications11, 1 (2020), 2368
2020
-
[7]
Kenny Choo, Titus Neupert, and Giuseppe Carleo. 2019. Two-dimensional frus- trated J 1-J 2 model studied with neural network quantum states.Physical Review B100, 12 (2019), 125124
2019
-
[8]
Pavlo O Dral. 2020. Quantum chemistry in the age of machine learning.The journal of physical chemistry letters11, 6 (2020), 2336–2347
2020
-
[9]
Hong Gao, Satoshi Imamura, Akihiko Kasagi, and Eiji Yoshida. 2024. Distributed implementation of full configuration interaction for one trillion determinants. Journal of Chemical Theory and Computation20, 3 (2024), 1185–1192
2024
-
[10]
Jan Hermann, Zeno Schätzle, and Frank Noé. 2020. Deep-neural-network solution of the electronic Schrödinger equation.Nature Chemistry12, 10 (2020), 891–897
2020
-
[11]
Jan Hermann, James Spencer, Kenny Choo, Antonio Mezzacapo, W Matthew C Foulkes, David Pfau, Giuseppe Carleo, and Frank Noé. 2023. Ab initio quantum chemistry with neural-network wavefunctions.Nature Reviews Chemistry7, 10 (2023), 692–709
2023
-
[12]
Le, Yonghui Wu, and Zhifeng Chen
Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Dehao Chen, Mia Xu Chen, HyoukJoong Lee, Jiquan Ngiam, Quoc V. Le, Yonghui Wu, and Zhifeng Chen. 2019. GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism. InAdvances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019...
2019
-
[13]
Bernard Huron, JP Malrieu, and P Rancurel. 1973. Iterative perturbation calcula- tions of ground and excited state energies from multiconfigurational zeroth-order wavefunctions.The Journal of Chemical Physics58, 12 (1973), 5745–5759
1973
-
[14]
Weile Jia, Han Wang, Mohan Chen, Denghui Lu, Lin Lin, Roberto Car, E Weinan, and Linfeng Zhang. 2020. Pushing the limit of molecular dynamics with ab initio accuracy to 100 million atoms with machine learning. InSC20: International conference for high performance computing, networking, storage and analysis. IEEE, IEEE/ACM, Atlanta, Georgia, USA, 1–14
2020
-
[15]
Mohammed Abdul Lateef Junaid. 2025. Artificial intelligence driven innovations in biochemistry: A review of emerging research frontiers.Biomolecules and Biomedicine25, 4 (2025), 739
2025
-
[16]
Bowen Kan, Yumeng Zhou, Daiyou Xie, Pengyu Zhou, Yunquan Zhang, and Honghui Shang. 2025. NNQS-SCI: Tackling Trillion-Dimensional Hilbert Space with Adaptive Neural Network Quantum States. InThe International Conference for High Performance Computing, Networking, Storage and Analysis (SC ’25)(St. Louis, MO, USA). Association for Computing Machinery (ACM), ...
-
[17]
Peter J Knowles and Nicholas C Handy. 1984. A new determinant-based full configuration interaction method.Chemical physics letters111, 4-5 (1984), 315– 321
1984
-
[18]
Hannah Lange, Anka Van de Walle, Atiye Abedinnia, and Annabelle Bohrdt. 2024. From architectures to applications: a review of neural quantum states.Quantum Science and Technology9, 4 (2024), 040501
2024
-
[19]
An-Jun Liu and Bryan K. Clark. 2024. Neural network backflow forab initio quantum chemistry.Physical Review B110, 11 (2024), 115137. doi:10.1103/ PhysRevB.110.115137
2024
-
[20]
Huan Ma, Honghui Shang, and Jinlong Yang. 2024. Quantum embedding method with transformer neural network quantum states for strongly correlated materials. npj Computational Materials10, 1 (2024), 220
2024
-
[21]
Matija Medvidović and Javier Robledo Moreno. 2024. Neural-network quantum states for many-body physics.The European Physical Journal Plus139, 7 (2024), 1–26
2024
-
[22]
Jeppe Olsen, Poul Jørgensen, and John N. Simons. 1990. Passing the one-billion limit in full configuration-interaction (FCI) calculations.Chemical Physics Letters 169, 6 (1990), 463–472. doi:10.1016/0009-2614(90)85633-N
-
[23]
Bryan O’Gorman, Sandy Irani, James Whitfield, and Bill Fefferman. 2022. In- tractability of Electronic Structure in a Fixed Basis.PRX Quantum3, 2 (2022), 020322. doi:10.1103/PRXQuantum.3.020322
-
[24]
Bryan O’Gorman, Sandy Irani, James Whitfield, and Bill Fefferman. 2022. In- tractability of electronic structure in a fixed basis.PRX Quantum3, 2 (2022), 020322
2022
-
[25]
David Pfau, James S Spencer, Alexander GDG Matthews, and W Matthew C Foulkes. 2020. Ab initio solution of the many-electron Schrödinger equation with deep neural networks.Physical review research2, 3 (2020), 033429
2020
-
[26]
Jie Ren, Samyam Rajbhandari, Reza Yazdani Aminabadi, Olatunji Ruwase, Shuangyan Yang, Minjia Zhang, Dong Li, and Yuxiong He. 2021. ZeRO-Offload: Democratizing Billion-Scale Model Training. InUSENIX ATC. USENIX Associa- tion, Virtual Event, 551–564
2021
-
[27]
2011.Numerical methods for large eigenvalue problems: revised edition
Yousef Saad. 2011.Numerical methods for large eigenvalue problems: revised edition. SIAM, Philadelphia, PA
2011
-
[28]
Anders W Sandvik. 2010. Computational studies of quantum spin systems. In AIP Conference Proceedings, Vol. 1297. American Institute of Physics, American Institute of Physics, Melville, NY, 135–338
2010
-
[29]
Markus Schmitt and Markus Heyl. 2020. Quantum many-body dynamics in two dimensions with artificial neural networks.Physical Review Letters125, 10 (2020), 100503
2020
-
[30]
Ulrich Schollwöck. 2011. The density-matrix renormalization group in the age of matrix product states.Annals of physics326, 1 (2011), 96–192
2011
-
[31]
Jeffrey B Schriber and Francesco A Evangelista. 2017. Adaptive configuration interaction for computing challenging electronic excited states with tunable accuracy.Journal of chemical theory and computation13, 11 (2017), 5354–5366
2017
-
[32]
Or Sharir, Yoav Levine, Noam Wies, Giuseppe Carleo, and Amnon Shashua
-
[33]
doi:10.1103/PhysRevLett.124.020503
Deep Autoregressive Models for the Efficient Variational Simulation of Many-Body Quantum Systems.Physical Review Letters124, 2 (2020), 020503. doi:10.1103/PhysRevLett.124.020503
-
[34]
Holmes, Guillaume Jeanmairet, Ali Alavi, and C
Sandeep Sharma, Adam A. Holmes, Guillaume Jeanmairet, Ali Alavi, and C. J. Umrigar. 2017. Semistochastic Heat-Bath Configuration Interaction Method: Selected Configuration Interaction with Semistochastic Perturbation Theory. Journal of Chemical Theory and Computation13, 4 (2017), 1595–1604. doi:10.1021/ acs.jctc.6b01028
2017
-
[35]
2020.Ai for science: Report on the department of energy (doe) town halls on artificial intelligence (ai) for science
Rick Stevens, Valerie Taylor, Jeff Nichols, Arthur Barney Maccabe, Katherine Yelick, and David Brown. 2020.Ai for science: Report on the department of energy (doe) town halls on artificial intelligence (ai) for science. Technical Report. Argonne National Lab.(ANL), Argonne, IL (United States)
2020
-
[36]
Qiming Sun, Timothy C Berkelbach, Nick S Blunt, George H Booth, Sheng Guo, Zhendong Li, Junzi Liu, James D McClain, Elvira R Sayfutyarova, Sandeep Sharma, et al. 2018. PySCF: the Python-based simulations of chemistry framework.Wiley Interdisciplinary Reviews: Computational Molecular Science8, 1 (2018), e1340
2018
-
[37]
Norm M Tubman, C Daniel Freeman, Daniel S Levine, Diptarka Hait, Martin Head- Gordon, and K Birgitta Whaley. 2020. Modern approaches to exact diagonalization and selected configuration interaction with the adaptive sampling CI method. Journal of chemical theory and computation16, 4 (2020), 2139–2159
2020
-
[38]
Ivan S Ufimtsev and Todd J Martinez. 2009. Quantum chemistry on graphical processing units. 3. Analytical energy gradients, geometry optimization, and first principles molecular dynamics.Journal of Chemical Theory and Computation5, 10 (2009), 2619–2628
2009
-
[39]
Marat Valiev, Eric J Bylaska, Niranjan Govind, Karol Kowalski, Tjerk P Straatsma, Hubertus Johannes Jacobus Van Dam, Dunyou Wang, Jarek Nieplocha, Edoardo Aprà, Theresa L Windus, et al. 2010. NWChem: A comprehensive and scalable open-source solution for large scale molecular simulations.Computer Physics Communications181, 9 (2010), 1477–1489
2010
-
[40]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is All you Need. InAdvances in Neural Information Processing Systems 30: Annual Con- ference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, Isabelle Guyon, Ulrike von Luxburg...
2017
-
[41]
Filippo Vicentini, Damian Hofmann, Attila Szabó, Dian Wu, Christopher Roth, Clemens Giuliani, Gabriel Pescia, Jannes Nys, Vladimir Vargas-Calderón, Nikita Astrakhantsev, and Giuseppe Carleo. 2022. NetKet 3: Machine Learning Toolbox for Many-Body Quantum Systems.SciPost Phys. Codebases(2022), 7. doi:10. 21468/SciPostPhysCodeb.7
2022
-
[42]
Davidson, Yuechao Pan, Yuduo Wu, Andy Riffel, and John D
Yangzihao Wang, Andrew A. Davidson, Yuechao Pan, Yuduo Wu, Andy Riffel, and John D. Owens. 2016. Gunrock: a high-performance graph processing library on the GPU. InPPoPP. ACM, Barcelona, Spain, 11:1–11:12
2016
-
[43]
James Daniel Whitfield, Peter John Love, and Alán Aspuru-Guzik. 2013. Compu- tational complexity in electronic structure.Physical Chemistry Chemical Physics 15, 2 (2013), 397–411
2013
-
[44]
Yangjun Wu, Chu Guo, Yi Fan, Pengyu Zhou, and Honghui Shang. 2023. NNQS- Transformer: an Efficient and Scalable Neural Network Quantum States Approach for Ab initio Quantum Chemistry. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis(Denver, CO, USA)(SC ’23). Association for Computing Machinery,...
-
[45]
Tianchen Zhao, James Stokes, and Shravan Veerapaneni. 2023. Scalable neural quantum states architecture for quantum chemistry.Machine Learning: Science and Technology4, 2 (2023), 025034
2023
-
[46]
Xuncheng Zhao, Mingfan Li, Qian Xiao, Junshi Chen, Fei Wang, Li Shen, Mei- jia Zhao, Wenhao Wu, Hong An, Lixin He, and Xiao Liang. 2022. AI for Quantum Mechanics: High Performance Quantum Many-Body Simulations via Deep Learning. InSC22: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, Dallas, TX, USA, 1–15. ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.