Recognition: unknown
Beyond Surface Statistics: Robust Conformal Prediction for LLMs via Internal Representations
Pith reviewed 2026-05-10 08:01 UTC · model grok-4.3
The pith
Layer-wise internal entropy scores improve conformal prediction for LLMs under distribution shift better than output statistics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Layer-Wise Information scores, which quantify the reshaping of predictive entropy by input conditioning across transformer depth, serve as nonconformity measures that deliver a superior validity-efficiency frontier for conformal prediction sets on LLM question-answering benchmarks, particularly when calibration and deployment distributions diverge, while preserving competitive coverage at the nominal risk level in matched settings.
What carries the argument
Layer-Wise Information (LI) scores that measure input-induced reshaping of predictive entropy across model layers, inserted as the nonconformity score in a split conformal pipeline.
If this is right
- Conformal sets maintain the target coverage guarantee even when surface-level uncertainty signals become unreliable.
- At the same nominal risk level, the method produces smaller average prediction sets than text-level baselines under cross-domain shift.
- The approach works for both closed-ended multiple-choice and open-domain generation QA tasks.
- In-domain reliability remains competitive with existing output-based conformal methods.
Where Pith is reading between the lines
- If internal entropy reshaping is reliably informative under shift, similar layer-wise measures could be tested for other uncertainty tasks such as calibration of generated text length or factuality.
- The framework may reduce dependence on expensive post-training calibration data collection when deployment conditions are known to differ from training.
- A natural next test would be whether LI scores remain effective when the underlying LLM is fine-tuned or when the shift is adversarial rather than natural domain change.
Load-bearing premise
Layer-Wise Information scores derived from internal entropy reshaping stay more informative nonconformity measures than output statistics precisely when calibration and deployment distributions differ.
What would settle it
An experiment in which, under a controlled distribution shift, the LI-based prediction sets are larger at the same empirical coverage level than sets produced by output-entropy or self-consistency baselines would falsify the claimed superiority.
Figures

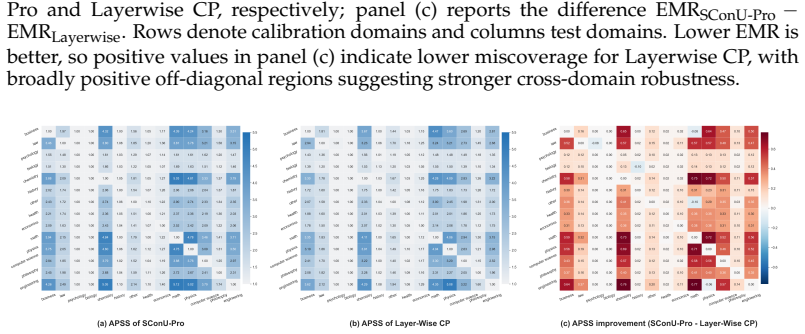
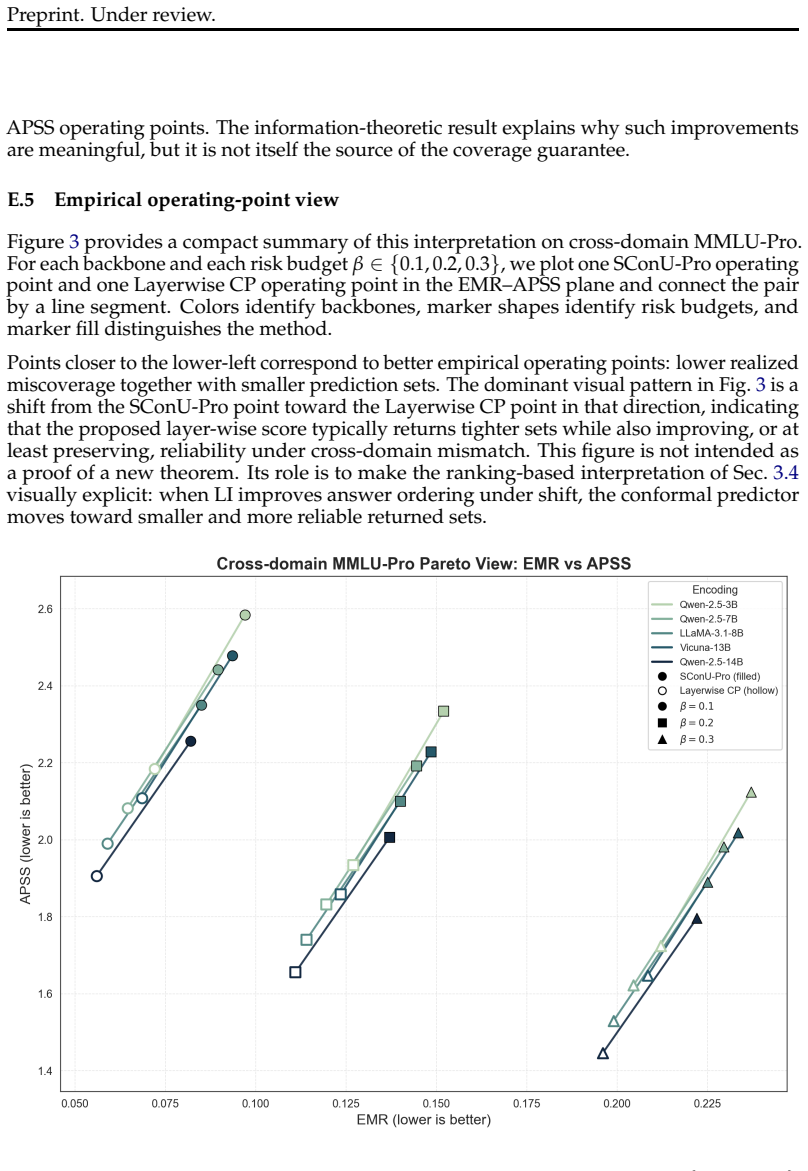

read the original abstract
Large language models are increasingly deployed in settings where reliability matters, yet output-level uncertainty signals such as token probabilities, entropy, and self-consistency can become brittle under calibration--deployment mismatch. Conformal prediction provides finite-sample validity under exchangeability, but its practical usefulness depends on the quality of the nonconformity score. We propose a conformal framework for LLM question answering that uses internal representations rather than output-facing statistics: specifically, we introduce Layer-Wise Information (LI) scores, which measure how conditioning on the input reshapes predictive entropy across model depth, and use them as nonconformity scores within a standard split conformal pipeline. Across closed-ended and open-domain QA benchmarks, with the clearest gains under cross-domain shift, our method achieves a better validity--efficiency trade-off than strong text-level baselines while maintaining competitive in-domain reliability at the same nominal risk level. These results suggest that internal representations can provide more informative conformal scores when surface-level uncertainty is unstable under distribution shift.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes using Layer-Wise Information (LI) scores—derived from how conditioning on the input reshapes predictive entropy across LLM layers—as nonconformity measures within a standard split conformal prediction pipeline for question answering. It reports that this yields a superior validity-efficiency trade-off relative to output-entropy and self-consistency baselines on closed-ended and open-domain QA benchmarks, with the largest gains under cross-domain shift, while coverage remains at the nominal risk level both in-domain and under shift.
Significance. If the empirical results hold, the work is significant for demonstrating that internal representations can supply more informative nonconformity scores than surface statistics when calibration and test distributions differ. The use of unmodified split conformal prediction supplies finite-sample validity guarantees without introducing new parameters or fitting procedures, and the explicit comparison under distribution shift provides a falsifiable test of the central hypothesis that layer-wise entropy reshaping remains informative when output-level signals degrade.
minor comments (2)
- Abstract: the description of LI scores as measuring 'how conditioning on the input reshapes predictive entropy across model depth' would benefit from a one-sentence inline definition or reference to the exact aggregation formula to improve immediate readability.
- Experiments section: while coverage is stated to lie within finite-sample deviation of the nominal level, reporting the precise number of calibration and test examples per setting and confirming that the same random seed or split was used across all methods would strengthen reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work and the recommendation for minor revision. The referee's summary correctly captures our central contribution: using Layer-Wise Information (LI) scores derived from internal entropy reshaping as nonconformity measures within split conformal prediction, yielding improved validity-efficiency trade-offs especially under cross-domain shift while preserving finite-sample coverage guarantees.
Circularity Check
No significant circularity; standard split conformal with explicit new nonconformity score
full rationale
The paper defines Layer-Wise Information (LI) scores explicitly as a measure of entropy reshaping across layers and inserts them into the standard split conformal prediction pipeline. Validity follows from the finite-sample guarantee under exchangeability, while efficiency gains are shown via direct empirical comparison on QA benchmarks against output-entropy and self-consistency baselines. No equations reduce any reported quantity to a fitted parameter by construction, no self-citations are load-bearing for the central claim, and the derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Data points satisfy exchangeability so that split conformal prediction delivers finite-sample marginal coverage.
invented entities (1)
-
Layer-Wise Information (LI) scores
no independent evidence
Reference graph
Works this paper leans on
-
[1]
doi: 10.52202/079017-3203. URL https://proceedings.neurips.cc/paper files/ paper/2024/file/b6fa3ed9624c184bd73e435123bd576a-Paper-Conference.pdf. Kawin Ethayarajh, Yejin Choi, and Swabha Swayamdipta. Understanding dataset difficulty with V-usable information. In Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvari, Gang Niu, and Sivan Sabato (e...
-
[2]
PMLR, 17–23 Jul 2022. URL https://proceedings.mlr.press/v162/ethayarajh22a. html. Isaac Gibbs and Emmanuel Candes. Adaptive conformal inference under distribution shift. In M. Ranzato, A. Beygelzimer, Y. Dauphin, P .S. Liang, and J. Wortman Vaughan (eds.),Advances in Neural Information Processing Systems, volume 34, pp. 1660–1672. Curran Associates, Inc.,...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1093/jrsssb/qkaf008 2022
-
[3]
T rivia QA : A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension
URLhttps://proceedings.mlr.press/v235/huang24x.html. Junqi Jiang, Tom Bewley, Salim I. Amoukou, Francesco Leofante, Antonio Rago, Saumitra Mishra, and Francesca Toni. Representation consistency for accurate and coherent llm answer aggregation, 2025. URLhttps://arxiv.org/abs/2506.21590. Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Zettlemoyer. TriviaQA...
-
[4]
Lost in the Middle: How Language Models Use Long Contexts
URLhttps://arxiv.org/abs/2601.12471. Christopher Mohri and Tatsunori Hashimoto. Language models with conformal factuality guarantees, 2024. URLhttps://arxiv.org/abs/2402.10978. Ankit Pal, Logesh Kumar Umapathi, and Malaikannan Sankarasubbu. Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering. In Gerardo Flores, ...
work page internal anchor Pith review doi:10.1162/tacl 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.