Recognition: no theorem link
RoMathExam: A Longitudinal Dataset of Romanian Math Exams (1895-2025) with a Seven-Decade Core (1957-2025)
Pith reviewed 2026-05-14 21:58 UTC · model grok-4.3
The pith
A longitudinal dataset of Romanian math exams from 1895 to 2025 introduces a solution complexity metric validated as a proxy for difficulty across AI models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce RoMathExam as a longitudinal dataset of Romanian high-school mathematics exams and propose a solution complexity metric as a scalable intrinsic proxy for difficulty. Evaluation across GPT-5-mini, DeepSeek-R1, and Qwen3-235B-Thinking shows high cross-model synchronization with r > 0.72, confirming the metric isolates intrinsic mathematical depth. The dataset reveals a regime shift from volatile historical formats to a standardized algebra-dominant modern curriculum.
What carries the argument
The solution complexity metric, which quantifies the intrinsic difficulty of math problems based on solution steps or structure, serving as a proxy independent of student performance data.
If this is right
- The dataset supports reproducible research in difficulty modeling for low-resource languages.
- Longitudinal analysis can track curriculum evolution over decades.
- LLM evaluation can use the metric to test reasoning capabilities on authentic exam problems.
- Variant detection and deduplication become feasible through embeddings and tags.
Where Pith is reading between the lines
- Future work could calibrate the metric against modern student performance data to strengthen its validity.
- The approach might extend to other languages' exam corpora if similar digitization efforts are made.
- Such metrics could help design more balanced assessments by identifying overly complex problems.
Load-bearing premise
The solution complexity metric accurately reflects true student-experienced difficulty despite the absence of historical psychometric performance data for calibration.
What would settle it
Collecting actual student success rates on a subset of the problems and checking if they correlate with the solution complexity scores.
Figures

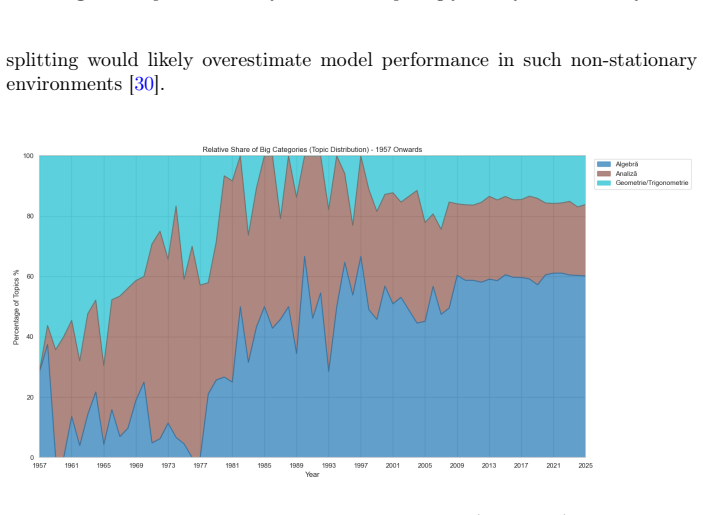
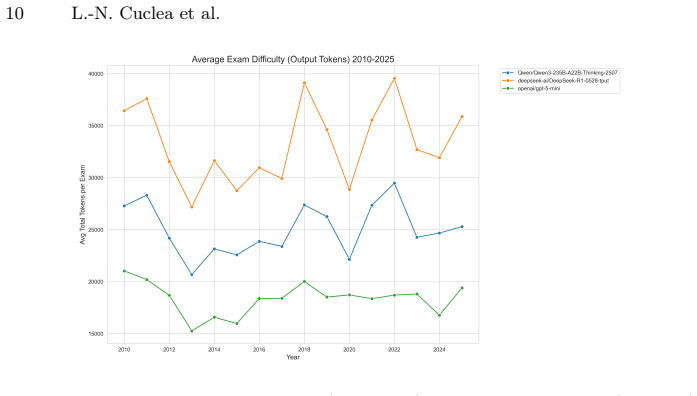

read the original abstract
AI in Education research increasingly relies on authentic, curriculum-grounded assessment data, yet large, well-structured exam corpora remain scarce for many languages and educational systems. We introduce RoMathExam, a longitudinal dataset of Romanian high-school mathematics exams spanning 1895-2025, with a robust standardized core for 1957-2025. The dataset contains 10,592 mathematics problems organized into 600+ complete exam sets across multiple tracks (M1-M4), covering both official national examination sessions and ministry-published training variants. Beyond high-fidelity digitization and a unified JSON schema with traceable provenance, RoMathExam is enriched with curriculum-aligned topic tags and dense text embeddings, enabling variant detection, deduplication, and similarity-based retrieval. To overcome the lack of historical psychometric data, we propose and validate a solution complexity metric as a scalable intrinsic proxy for difficulty. Our evaluation across three frontier reasoning models (GPT-5-mini, DeepSeek-R1, and Qwen3-235B-Thinking) reveals high cross-model synchronization (r > 0.72), confirming the metric's ability to isolate intrinsic mathematical depth from stochastic generation noise. We demonstrate the dataset's utility through a longitudinal analysis that quantifies a "regime shift" from volatile historical formats to a standardized, algebra-dominant modern curriculum. RoMathExam provides a foundation for reproducible research in difficulty modeling, curriculum analytics, and LLM evaluation in low-resource linguistic contexts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RoMathExam, a longitudinal dataset of 10,592 Romanian high-school mathematics problems from 600+ exam sets spanning 1895-2025 (core 1957-2025), with unified JSON schema, curriculum topic tags, and dense embeddings for deduplication and retrieval. It proposes a solution complexity metric as an intrinsic proxy for difficulty and validates it via Pearson r > 0.72 across three frontier LLMs (GPT-5-mini, DeepSeek-R1, Qwen3-235B-Thinking), then applies the metric to quantify a curriculum regime shift toward algebra dominance.
Significance. If the central claims hold, the dataset would constitute a valuable, reproducible resource for curriculum analytics and difficulty modeling in low-resource linguistic settings. The reported cross-model synchronization indicates the metric captures consistent structural features of problems, offering a scalable alternative where psychometric data are absent. However, its significance as a proxy for student-experienced difficulty remains limited by the lack of external calibration.
major comments (2)
- [Abstract] Abstract: the solution complexity metric is presented as a validated 'scalable intrinsic proxy for difficulty' with r > 0.72, yet no exact definition, formula, error analysis, or controls for model-specific biases are supplied, leaving the central validation claim only partially verifiable.
- [Metric evaluation section] The section describing the metric evaluation: cross-model agreement (GPT-5-mini, DeepSeek-R1, Qwen3-235B-Thinking) is reported but supplies no comparison to historical pass-rate data, teacher difficulty ratings, or student performance on the same items, so the claim that the metric isolates 'intrinsic mathematical depth' from stochastic noise lacks an external anchor and risks capturing shared model artifacts.
minor comments (2)
- [Dataset description] The exact number of complete exam sets should be stated precisely rather than '600+', and a table summarizing distribution by track (M1-M4) and decade would improve clarity.
- [Data collection section] Provenance and digitization details for the pre-1957 portion of the corpus should be expanded to allow readers to assess data quality and potential transcription biases.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, indicating where revisions have been made to strengthen the presentation of the solution complexity metric and its evaluation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the solution complexity metric is presented as a validated 'scalable intrinsic proxy for difficulty' with r > 0.72, yet no exact definition, formula, error analysis, or controls for model-specific biases are supplied, leaving the central validation claim only partially verifiable.
Authors: We agree that the abstract should make the metric fully verifiable on first reading. In the revised manuscript we have added a concise definition of the solution complexity metric together with its exact formula, a brief description of the error analysis (standard deviation across repeated inferences), and explicit controls for model-specific biases via pairwise correlations and variance reporting. These additions keep the abstract within length limits while rendering the validation claim directly checkable. revision: yes
-
Referee: [Metric evaluation section] The section describing the metric evaluation: cross-model agreement (GPT-5-mini, DeepSeek-R1, Qwen3-235B-Thinking) is reported but supplies no comparison to historical pass-rate data, teacher difficulty ratings, or student performance on the same items, so the claim that the metric isolates 'intrinsic mathematical depth' from stochastic noise lacks an external anchor and risks capturing shared model artifacts.
Authors: We acknowledge the absence of direct external anchors. The manuscript already notes that historical psychometric data are unavailable for the full longitudinal span, which motivated the intrinsic approach. The reported r > 0.72 is obtained across three architecturally and training-distinct frontier models, which reduces the likelihood of shared artifacts. To address the referee's concern we have added a new limitations subsection that (i) explicitly states the lack of historical pass-rate or teacher-rating data, (ii) reports a limited modern-era comparison with available national exam statistics, and (iii) discusses the rationale for treating cross-model consistency as an internal validation of structural depth. We do not claim the metric equals student-experienced difficulty; we position it as a reproducible proxy when external calibration is impossible. revision: partial
- Comprehensive external calibration against historical student performance or teacher ratings for the entire 1895-2025 period, which simply does not exist in accessible form.
Circularity Check
No significant circularity in metric definition or validation
full rationale
The solution complexity metric is introduced as an intrinsic proxy derived from problem structure, with validation performed via independent cross-model Pearson correlation (r > 0.72) on three separate frontier LLMs. No equations or steps reduce the metric to a fitted parameter on the same data, a self-citation chain, or a definitional tautology. Dataset construction, tagging, and longitudinal analysis remain independent of this validation step. This is the expected non-circular outcome for an intrinsically defined quantity checked against external model behavior.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Cross-model synchronization on solution complexity isolates intrinsic mathematical depth from stochastic generation noise
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the 2025 NAACL .https:// aclanthology.org/2025.naacl-long.139/
Adelani, D., et al.: IrokoBench: A New Benchmark for African Languages in the Age of Large Language Models. In: Proceedings of the 2025 NAACL .https:// aclanthology.org/2025.naacl-long.139/
work page 2025
-
[2]
Computational Linguistics34(4), 555–596 (2008).https://doi.org/10.1162/ coli.07-034-R2
Artstein, R., Poesio, M.: Inter-Coder Agreement for Computational Linguis- tics. Computational Linguistics34(4), 555–596 (2008).https://doi.org/10.1162/ coli.07-034-R2
work page 2008
-
[3]
Beckmann, N., Birney, D, Goode, N: Beyond Psychometrics: The Difference between Difficult Problem Solving and Complex Problem Solving.https://doi.org/10. 3389/fpsyg.2017.01739
-
[4]
Borcan, O., Lindahl, M., Mitrut, A.: Fighting corruption in education: What works and who benefits? American Economic Journal: Economic Policy9(1), 180–209 (2017)https://doi.org/10.1257/pol.20150074
-
[5]
Borodi, S.: Archive of Mathematics Examination Subjects (1895–2025).https:// sorinborodi.ro/subiecte_examene.html. Accessed: 2026-02-01
work page 2025
-
[6]
Cheng,Y.,Chang,Y.,Wu,Y.:ASurveyonDataContaminationforLargeLanguage Models.https://doi.org/10.48550/arXiv.2502.14425
-
[7]
Training Verifiers to Solve Math Word Problems
Cobbe, K., et al.: Training Verifiers to Solve Math Word Problems. (2021)https: //doi.org/10.48550/arXiv.2110.14168
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2110.14168 2021
-
[8]
https://doi.org/10.48550/arXiv.2409.11074
Cosma, A., Bucur, A-M, Radoi, E: RoMath: A Romanian Mathematics Dataset. https://doi.org/10.48550/arXiv.2409.11074
-
[9]
In: Proceedings of the 26th AIED Conference 2025
Ding, Z., et al.: Foundation Models for Low-Resource Language Education: A Vision Paper. In: Proceedings of the 26th AIED Conference 2025. Springer LNCS (2025). https://doi.org/10.48550/arXiv.2412.04774
-
[10]
Gilardi, F., Alizadeh, M., Kubli, M.: ChatGPT outperforms crowd workers for text-annotation tasks. Proc. Natl. Acad. Sci. U.S.A. 120 (30) e2305016120,https: //doi.org/10.1073/pnas.2305016120(2023). 14 L.-N. Cuclea et al
-
[11]
Hendrycks, D., et al.: Measuring Mathematical Problem Solving with the MATH Dataset.https://doi.org/10.48550/arXiv.2103.03874
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2103.03874
-
[12]
OECD Publishing, Paris (2017).https://doi.org/10.1787/9789264274051-en
Kitchen, H., et al.: OECD Reviews of School Resources: Romania 2017. OECD Publishing, Paris (2017).https://doi.org/10.1787/9789264274051-en
-
[13]
Cognitive Science36(5), 757–798 (2012).https://doi.org/10.1111/j
Koedinger, K.R., Corbett, A.T., Perfetti, C.: The Knowledge-Learning-Instruction Framework: Bridging the Science-Practice Chasm to Enhance Robust Student Learning. Cognitive Science36(5), 757–798 (2012).https://doi.org/10.1111/j. 1551-6709.2012.01245.x
work page doi:10.1111/j 2012
-
[14]
UT Austin (2025).https://doi.org/10.48550/ arXiv.2507.15378
Li, J., Mooney, R.: AlgoSimBench: Identifying Algorithmically Similar Problems for Competitive Programming. UT Austin (2025).https://doi.org/10.48550/ arXiv.2507.15378
-
[15]
Frontiers in Education (2025).https: //doi.org/10.3389/feduc.2025.1632132
Liu, Y., Xie, R, Chen, Z.: Towards actionable recommendations for exam prepa- ration using isomorphic problem banks. Frontiers in Education (2025).https: //doi.org/10.3389/feduc.2025.1632132
-
[16]
Marinho, W., Clua, E., Martí, L., Marinho, K.: Predicting Item Response Theory Parameters Using Question Statements Texts. In: Proceedings of LAK23, pp. 123– 134 (2023).https://doi.org/10.1145/3576050.3576139
-
[17]
Biochemia medica22(3), 276–282 (2012).https://doi.org/10.11613/BM.2012.031
McHugh, M.L.: Interrater reliability: the kappa statistic. Biochemia medica22(3), 276–282 (2012).https://doi.org/10.11613/BM.2012.031
- [18]
-
[19]
Zenodo (2026).https: //doi.org/10.5281/zenodo.19255512
Cuclea, L.-N., Badea, S.-C., Dumitran, A.-M.: RoMathExam: A Longitudinal Dataset of Romanian Math Exams (1895–2025) [Dataset]. Zenodo (2026).https: //doi.org/10.5281/zenodo.19255512
-
[20]
GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models
Mirzadeh, I., et al.: GSM-Symbolic: Understanding the Reliability of Mathematical Reasoning in Large Language Models. In Proceedings of ICLR 2025.https://doi. org/10.48550/arXiv.2410.05229
-
[21]
In: L@S 2024 (2024).https://doi.org/10.48550/ arXiv.2405.20526
Moore, S., et al.: Automated Generation and Tagging of Knowledge Components from Multiple-Choice Questions. In: L@S 2024 (2024).https://doi.org/10.48550/ arXiv.2405.20526
-
[22]
IJAIED27, 1–23 (2017).https://doi.org/10.1007/s40593-021-00252-4
Pelánek, R.: Complexity and Difficulty of Items in Learning Systems. IJAIED27, 1–23 (2017).https://doi.org/10.1007/s40593-021-00252-4
-
[23]
University of Maryland (2025).https: //doi.org/10.48550/arXiv.2509.23486
Peters, S., et al.: Text-Based Approaches to Item Difficulty Modeling in Large- Scale Assessments: A Systematic Review. University of Maryland (2025).https: //doi.org/10.48550/arXiv.2509.23486
-
[24]
Postolică, V., Nechita, E., Lupu, C.: The Romanian Mathematics and Informatics Education. Journal of Education, Society and Behavioural Science4(2), 226–240 (2013).https://doi.org/10.9734/BJESBS/2014/5940
-
[25]
Pro-Matematica: Repository of Standardized Baccalaureate Variants.https:// pro-matematica.ro/bacalaureat/index.php. Accessed: 2026-02-01
work page 2026
-
[26]
In: Proceedings of the 60th Annual Meeting of ACL 2022, pp
Reif, E., et al.: A Recipe for Arbitrary Text Style Transfer with Large Language Models. In: Proceedings of the 60th Annual Meeting of ACL 2022, pp. 837–848 (2022).https://doi.org/10.18653/v1/2022.acl-short.94
-
[27]
arXiv preprint arXiv:2210.03057 , year=
Shi, F., et al.: Language Models are Multilingual Chain-of-Thought Reasoners. In Proceedings of ICLR 2023.https://arxiv.org/abs/2210.03057
-
[28]
In: 2017 Brazilian Conference on Intelligent Systems (BRACIS), pp
Silveira, I.C., Mauá, D.D.: University Entrance Exam as a Guiding Test for Arti- ficial Intelligence. In: 2017 Brazilian Conference on Intelligent Systems (BRACIS), pp. 415–420. IEEE (2017).https://doi.org/10.1109/BRACIS.2017.44 RoMathExam: Romanian Math Exam Dataset 15
-
[29]
Journal for Research in Mathematics Education12(1), 54–64 (1981).https: //doi.org/10.2307/748658
Silver, E.A.: Recall of Mathematical Problem Information: Solving Related Prob- lems. Journal for Research in Mathematics Education12(1), 54–64 (1981).https: //doi.org/10.2307/748658
-
[30]
In Proceedings 16th Conference of EACL, Main Volume, pages 1823–1832
Søgaard, A., Ebert, S., Bastings, J., Filippova, K: We Need To Talk About Random Splits. In Proceedings 16th Conference of EACL, Main Volume, pages 1823–1832. https://doi.org/10.18653/v1/2021.eacl-main.156
-
[31]
https://doi.org/10.48550/arXiv.2505
Wei, Y., et al.: KCluster: An LLM-based Clustering Approach to Knowledge Com- ponent Discovery. In: EDM 2025 (2025).https://doi.org/10.48550/arXiv.2505. 06469
-
[32]
A careful examination of large language model performance on grade school arithmetic
Zhang, H., et al.: A Careful Examination of Large Language Model Performance on Grade School Arithmetic. In: Proc. NeurIPS 2024https://doi.org/10.48550/ arXiv.2405.00332
-
[33]
arXiv:2305.12474 (2023).https://doi.org/10.48550/ arXiv.2305.12474
Zhang, X., et al.: Evaluating the Performance of Large Language Models on GAOKAO Benchmark. arXiv:2305.12474 (2023).https://doi.org/10.48550/ arXiv.2305.12474
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.