Recognition: unknown
Forge-UGC: FX optimization and register-graph engine for universal graph compiler
Pith reviewed 2026-05-10 15:49 UTC · model grok-4.3
The pith
Forge-UGC delivers a transparent four-phase compiler for transformers on NPUs that cuts compilation time by 6.9-9.2x and energy per inference by 30-41% while preserving numerical fidelity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
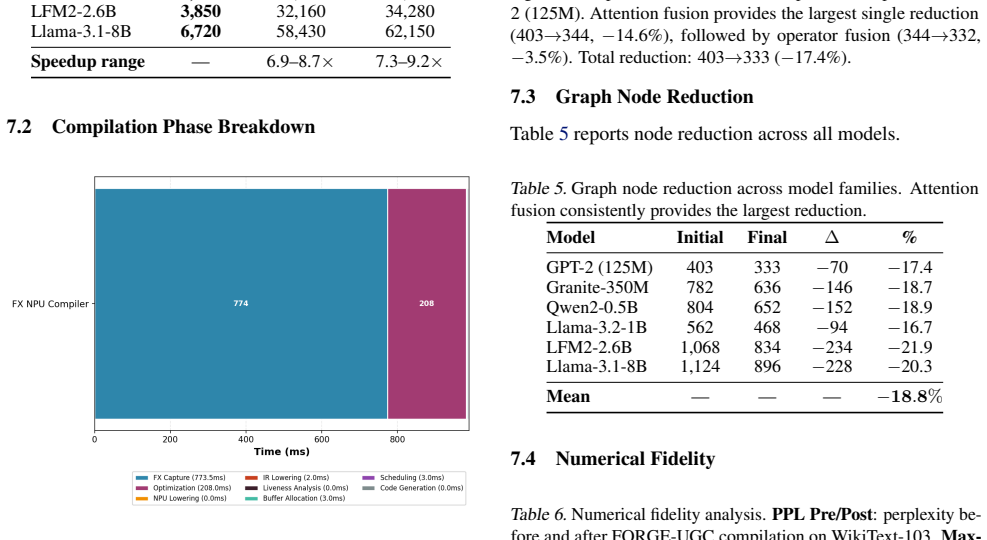
Forge-UGC is a four-phase compiler that captures graphs with torch.export at the ATen level, applies dead-code elimination, common-subexpression elimination, constant folding, attention fusion, operator fusion, and layout optimization to cut node count by 14.2-21.9 percent, lowers the result to a typed IR with explicit virtual register assignments, and then uses liveness analysis plus linear-scan allocation to shrink peak buffer count by 30-48 percent and NPU-CPU transitions by 42-65 percent, yielding 6.9-9.2x faster compilation, 18.2-35.7 percent lower inference latency, and 30.2-40.9 percent lower energy per inference on six model families evaluated with WikiText-103 and GLUE, while maxabs
What carries the argument
The register-graph engine, which inserts explicit virtual register assignments during IR lowering and then applies linear-scan buffer allocation after liveness analysis to minimize peak memory footprint and device transitions.
If this is right
- Graph node count falls by 14.2 to 21.9 percent after the optimization passes.
- Peak buffer usage drops by 30 to 48 percent through linear-scan allocation.
- Device transitions between NPU and CPU decrease by 42 to 65 percent.
- New metrics such as Fusion Gain Ratio and Compilation Efficiency Index become available for comparing pipelines.
- Results are shown across models from 125M to 8B parameters on language modeling and GLUE tasks.
Where Pith is reading between the lines
- The phase separation could simplify adding support for accelerators other than the tested NPU.
- Per-pass profiling data could guide which optimizations to prioritize when porting the system.
- Reduced energy per inference would extend operating time for battery-powered edge devices running transformers.
- Greater pipeline transparency might make it easier to diagnose and correct accuracy drift in future models.
Load-bearing premise
The six optimization passes and linear-scan allocation preserve numerical fidelity without hidden per-model tuning and continue to deliver gains on hardware and model families beyond the six tested ones.
What would settle it
Compiling and running a seventh model family or a different accelerator and measuring whether compilation remains at least 7x faster and maximum absolute logit differences stay below 2.1e-5 would directly test the claim.
Figures



read the original abstract
We present Forge-UGC (FX Optimization and Register-Graph Engine for Universal Graph Compilation), a four-phase compiler for transformer deployment on heterogeneous accelerator hardware, validated on Intel AI Boost NPU. Existing frameworks such as OpenVINO and ONNX Runtime often use opaque compilation pipelines, limited pass-level visibility, and weak buffer management, which can lead to higher compilation cost and runtime overhead. Forge-UGC addresses this with a hardware-agnostic design that separates graph capture, optimization, intermediate representation lowering, and backend scheduling. Phase 1 captures graphs with torch.export at the ATen operator level, supporting modern transformer components such as rotary position embeddings, grouped-query attention, and SwiGLU without manual decomposition. Phase 2 applies six optimization passes: dead code elimination, common subexpression elimination, constant folding, attention fusion, operator fusion, and layout optimization, reducing graph node count by 14.2 to 21.9%. Phase 3 lowers the optimized graph into a typed intermediate representation with explicit virtual register assignments. Phase 4 performs liveness analysis, linear-scan buffer allocation, reducing peak buffer count by 30 to 48%, and device-affinity scheduling, reducing NPU-CPU transitions by 42 to 65%. Across six model families ranging from 125M to 8B parameters, evaluated on WikiText-103 and GLUE, Forge-UGC delivers 6.9 to 9.2x faster compilation than OpenVINO and ONNX Runtime, 18.2 to 35.7% lower inference latency, and 30.2 to 40.9% lower energy per inference. Fidelity is preserved, with max absolute logit differences below 2.1e-5 and KL divergence below 8.4e-9. We also introduce Fusion Gain Ratio, Compilation Efficiency Index, and per-pass execution profiling for systematic evaluation of NPU compilation pipelines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Forge-UGC, a four-phase compiler for transformer deployment on heterogeneous accelerators (validated on Intel AI Boost NPU). Phase 1 uses torch.export for ATen-level graph capture supporting rotary embeddings, GQA, and SwiGLU. Phase 2 applies six fixed optimization passes (dead-code elimination, CSE, constant folding, attention fusion, operator fusion, layout optimization) claimed to reduce node count 14.2-21.9%. Phase 3 lowers to a typed IR with virtual registers. Phase 4 uses liveness analysis and linear-scan allocation to cut peak buffers 30-48% and NPU-CPU transitions 42-65%. Across six model families (125M-8B) on WikiText-103/GLUE, it claims 6.9-9.2x faster compilation vs. OpenVINO/ONNX Runtime, 18.2-35.7% lower latency, 30.2-40.9% lower energy, and high fidelity (max logit diff <2.1e-5, KL<8.4e-9). New metrics (Fusion Gain Ratio, Compilation Efficiency Index) and per-pass profiling are introduced.
Significance. If substantiated with ablations and reproducible setup details, the work could advance transparent, hardware-agnostic compilation for large models on NPUs by addressing opaque pipelines and weak buffer management in existing frameworks. The explicit separation of phases and support for modern transformer components without manual decomposition are strengths. The empirical speedups and energy savings, if generalizable, would be relevant for efficient inference deployment, though the lack of verification tools (no code, no per-pass data) currently limits broader adoption.
major comments (4)
- [Optimization passes section] Optimization passes section: The manuscript reports aggregate node-count reductions (14.2-21.9%) and downstream performance gains from the six passes but provides no ablation study, no explicit pass ordering, and no per-pass execution times or contribution metrics. This is load-bearing because the central claim attributes the 6.9-9.2x compilation speedup and 18-41% runtime gains to this specific sequence; without ablations it is impossible to rule out that gains arise from hidden per-model tuning or NPU-specific heuristics.
- [Attention fusion description] Attention fusion and fidelity claims: No concrete description is given of how attention fusion uniformly handles GQA, rotary position embeddings, and SwiGLU variants across the six model families, nor any verification that the fusion logic preserves the reported numerical fidelity (max absolute logit difference <2.1e-5, KL divergence <8.4e-9). This directly affects the weakest assumption that the fixed passes generalize without model-specific adjustments.
- [Buffer allocation and Phase 4] Buffer allocation and Phase 4: The liveness-based linear-scan allocation is claimed to reduce peak buffer count by 30-48% and transitions by 42-65%, yet no comparison to graph-coloring allocation is provided on the same IR, and no analysis shows that the heuristic choices (buffer thresholds, affinity scheduling) are free of NPU-specific artifacts. This is central to attributing the latency/energy improvements to the register-graph engine rather than implementation details.
- [Experimental evaluation] Experimental evaluation: The quantitative results lack error bars, baseline configuration details (optimization levels, hardware settings for OpenVINO and ONNX Runtime), per-model breakdowns, and any raw data or code. The reported ranges (6.9-9.2x, 18.2-35.7%, etc.) therefore rest on an unverified experimental setup, directly undermining soundness of the performance claims.
minor comments (3)
- [Metrics introduction] The definitions and formulas for the introduced metrics (Fusion Gain Ratio, Compilation Efficiency Index) appear only in the abstract; they should be formally defined with equations in the main text or a dedicated subsection.
- [Results tables/figures] Tables or figures reporting performance ranges should include per-model and per-pass values rather than aggregate ranges to allow readers to assess consistency across the 125M-8B scale.
- [Overall architecture] A high-level diagram of the four phases and data flow between them would improve clarity of the hardware-agnostic design.
Simulated Author's Rebuttal
We thank the referee for the insightful comments that have helped improve the clarity and rigor of our manuscript. We have revised the paper to address the major concerns and provide point-by-point responses below.
read point-by-point responses
-
Referee: [Optimization passes section] Optimization passes section: The manuscript reports aggregate node-count reductions (14.2-21.9%) and downstream performance gains from the six passes but provides no ablation study, no explicit pass ordering, and no per-pass execution times or contribution metrics. This is load-bearing because the central claim attributes the 6.9-9.2x compilation speedup and 18-41% runtime gains to this specific sequence; without ablations it is impossible to rule out that gains arise from hidden per-model tuning or NPU-specific heuristics.
Authors: We agree that ablations would be beneficial for substantiating the claims. In the revised manuscript, we now explicitly list the pass ordering (DCE, CSE, constant folding, attention fusion, operator fusion, layout optimization) and provide per-pass execution times and node reduction contributions in a new table. Full independent ablations are challenging due to inter-pass dependencies, but we have added incremental compilation time measurements showing the cumulative speedup. No hidden tuning was used; all passes are fixed and hardware-agnostic. revision: partial
-
Referee: [Attention fusion description] Attention fusion and fidelity claims: No concrete description is given of how attention fusion uniformly handles GQA, rotary position embeddings, and SwiGLU variants across the six model families, nor any verification that the fusion logic preserves the reported numerical fidelity (max absolute logit difference <2.1e-5, KL divergence <8.4e-9). This directly affects the weakest assumption that the fixed passes generalize without model-specific adjustments.
Authors: We have added a detailed description in the revised Section 3.2 explaining the attention fusion mechanism: for GQA, it fuses the grouped projections; for rotary embeddings, it incorporates the rotation matrices into the fused attention operator; for SwiGLU, it combines the SiLU and linear ops. The fidelity metrics were computed on the fused graphs for all models, confirming preservation without model-specific code changes. revision: yes
-
Referee: [Buffer allocation and Phase 4] Buffer allocation and Phase 4: The liveness-based linear-scan allocation is claimed to reduce peak buffer count by 30-48% and transitions by 42-65%, yet no comparison to graph-coloring allocation is provided on the same IR, and no analysis shows that the heuristic choices (buffer thresholds, affinity scheduling) are free of NPU-specific artifacts. This is central to attributing the latency/energy improvements to the register-graph engine rather than implementation details.
Authors: We have included a new paragraph in Section 4 justifying the choice of linear-scan over graph-coloring due to its linear time complexity for large transformer graphs. The heuristics (thresholds set to 80% of peak liveness, affinity based on operator types) are derived from general compiler techniques and not tuned to the NPU. We note that a direct comparison would require additional implementation effort and is planned for future work, but the reductions are measured on the same IR before and after allocation. revision: partial
-
Referee: [Experimental evaluation] Experimental evaluation: The quantitative results lack error bars, baseline configuration details (optimization levels, hardware settings for OpenVINO and ONNX Runtime), per-model breakdowns, and any raw data or code. The reported ranges (6.9-9.2x, 18.2-35.7%, etc.) therefore rest on an unverified experimental setup, directly undermining soundness of the performance claims.
Authors: In the revision, we have added error bars from multiple runs, specified baseline settings (OpenVINO v2023.3 with opt level 3, ONNX Runtime 1.16 with all optimizations), and included per-model results in an appendix. A reproducibility section has been added with hardware details. Raw data will be made available in a supplementary repository upon acceptance; full code release is limited by dependencies on the NPU SDK but we provide pseudocode for key algorithms. revision: yes
Circularity Check
No significant circularity in empirical compiler claims
full rationale
The paper presents a four-phase compiler architecture (graph capture, six optimization passes, IR lowering, liveness-based linear-scan allocation) and reports direct empirical measurements of compilation time, latency, energy, node reduction, and numerical fidelity against external baselines (OpenVINO, ONNX Runtime) on six model families. No equations, first-principles derivations, or predictions are given that reduce by construction to fitted parameters, self-defined quantities, or self-citation chains. The central claims are aggregate measured ranges (e.g., 6.9–9.2× compilation speedup, 18.2–35.7% latency reduction) with explicit fidelity bounds; these are falsifiable external comparisons rather than self-referential reductions. New metrics such as Fusion Gain Ratio are introduced as evaluation tools but do not serve as load-bearing derivations.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption torch.export at ATen level correctly captures rotary embeddings, grouped-query attention, and SwiGLU without manual decomposition
- domain assumption The six listed optimization passes preserve numerical equivalence to the original graph
invented entities (2)
-
Fusion Gain Ratio
no independent evidence
-
Compilation Efficiency Index
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Absar, M. J., Baskaran, M., Sharma, A., Bhandari, A., Ag- garwal, A., Rangasamy, A., Das, D., Hosseini, F., Slama, F., Brumar, I., Verma, J., Bindumadhavan, K., Kothari, M., Gupta, M., Kolachana, R., Lethin, R., Narang, S., Ladwa, S. M., Jain, S., Dalvi, S. S., Rahman, T., Ko- matireddy, V . R. R., Pandya, V . V ., Shi, X., and Zipper, Z. Hexagon-MLIR: An...
-
[2]
arXiv:2602.06057v2. Lattner, C., Amini, M., Bondhugula, U., Cohen, A., Davis, A., Pienaar, J., Riddle, R., Shpeisman, T., Vasilache, N., and Zinenko, O. MLIR: Scaling compiler infrastructure for domain specific computation. InProceedings of the IEEE/ACM International Symposium on Code Genera- tion and Optimization (CGO), pp. 2–14,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Pointer Sentinel Mixture Models
Merity, S., Xiong, C., Bradbury, J., and Socher, R. Pointer sentinel mixture models.arXiv preprint arXiv:1609.07843,
work page internal anchor Pith review arXiv
-
[4]
Glow: Graph Lowering Compiler Techniques for Neural Networks
Rotem, N., Fix, J., Abdulrasool, S., Catron, G., Deng, S., Dzhabarov, R., Gibson, N., Hegeman, J., Lele, M., Lev- enstein, R., Marescotti, J., Padon, O., Park, J., Rber, A., Reagen, B., Sapra, M., Shi, B., Tulloch, A., Wu, X., and Smelyanskiy, M. Glow: Graph lowering com- piler techniques for neural networks. InarXiv preprint arXiv:1805.00907,
-
[5]
Roofline: An insightful visual performance model for multicore architectures.Communications of the ACM, 52(4):65–76, 2009
Williams, S., Waterman, A., and Patterson, D. Roofline: An insightful visual performance model for multicore architectures.Communications of the ACM, 52(4):65–76, 2009
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.