Recognition: unknown
S-GRPO: Unified Post-Training for Large Vision-Language Models
Pith reviewed 2026-05-10 08:14 UTC · model grok-4.3
The pith
S-GRPO unifies supervised fine-tuning and reinforcement learning for large vision-language models through conditional ground-truth injection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
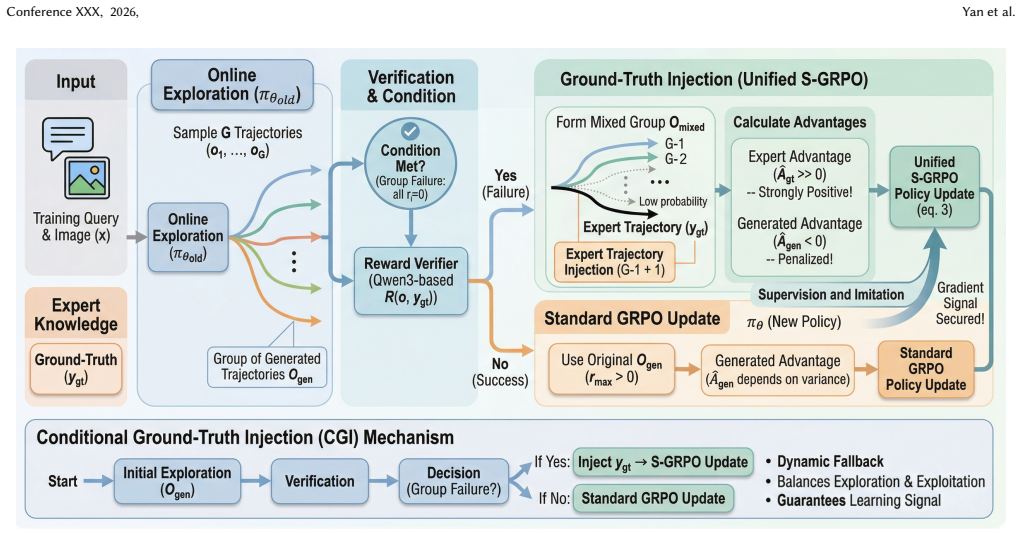
S-GRPO integrates imitation learning guidance into multi-trajectory preference optimization by introducing Conditional Ground-Truth Trajectory Injection (CGI). When a binary verifier identifies that all trajectories in a sampled group fail domain validation, CGI inserts the verified ground-truth trajectory into the pool and assigns it deterministic maximal reward. This reformulates the supervised objective as a high-advantage term in the policy gradient, enabling the model to balance exploitation of expert trajectories with exploration of novel visual concepts while avoiding optimization collapse.
What carries the argument
Conditional Ground-Truth Trajectory Injection (CGI) within the group-relative advantage estimation of policy optimization, which activates only on detected complete exploratory failure to anchor the learning signal.
If this is right
- Convergence on domain-specific tasks accelerates because the model receives guaranteed positive feedback instead of zero-reward groups.
- General-purpose multimodal abilities are preserved as the method avoids the distributional shift caused by exclusive use of SFT.
- Optimization stability improves in sparse-reward visual generation tasks where standard RL would encounter cold-start failures.
- The framework allows dynamic switching between supervised anchoring and free exploration based on group performance.
- Superior domain adaptation is achieved without requiring the model to spontaneously discover valid trajectories from scratch.
Where Pith is reading between the lines
- This injection technique could apply to other reinforcement learning setups where ground-truth is occasionally available but exploration is hard.
- Hybrid methods like this might lower the data requirements for fine-tuning by using verifiers more efficiently than full preference labeling.
- Testing on larger models or different modalities could reveal if the bridging effect scales beyond the reported vision-language tasks.
- Potential for combining with other verifiers or reward models to handle more complex reasoning chains.
Load-bearing premise
The binary verifier can consistently and accurately detect when every trajectory in a group is invalid without mislabeling correct ones.
What would settle it
A controlled experiment on a visual question answering or captioning task where the injection is disabled, showing that the model exhibits optimization collapse or significantly slower learning compared to the full S-GRPO method.
Figures


read the original abstract
Current post-training methodologies for adapting Large Vision-Language Models (LVLMs) generally fall into two paradigms: Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL). Despite their prevalence, both approaches suffer from inefficiencies when applied in isolation. SFT forces the model's generation along a single expert trajectory, often inducing catastrophic forgetting of general multimodal capabilities due to distributional shifts. Conversely, RL explores multiple generated trajectories but frequently encounters optimization collapse - a cold-start problem where an unaligned model fails to spontaneously sample any domain-valid trajectories in sparse-reward visual tasks. In this paper, we propose Supervised Group Relative Policy Optimization (S-GRPO), a unified post-training framework that integrates the guidance of imitation learning into the multi-trajectory exploration of preference optimization. Tailored for direct-generation visual tasks, S-GRPO introduces Conditional Ground-Truth Trajectory Injection (CGI). When a binary verifier detects a complete exploratory failure within a sampled group of trajectories, CGI injects the verified ground-truth trajectory into the candidate pool. By assigning a deterministic maximal reward to this injected anchor, S-GRPO enforces a positive signal within the group-relative advantage estimation. This mechanism reformulates the supervised learning objective as a high-advantage component of the policy gradient, compelling the model to dynamically balance between exploiting the expert trajectory and exploring novel visual concepts. Theoretical analysis and empirical results demonstrate that S-GRPO gracefully bridges the gap between SFT and RL, drastically accelerates convergence, and achieves superior domain adaptation while preserving the base model's general-purpose capabilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Supervised Group Relative Policy Optimization (S-GRPO) as a unified post-training framework for Large Vision-Language Models (LVLMs). It integrates imitation learning guidance into multi-trajectory preference optimization via Conditional Ground-Truth Trajectory Injection (CGI): when a binary verifier detects total exploratory failure in a sampled group, the verified ground-truth trajectory is injected with deterministic maximal reward. This is claimed to reformulate the supervised objective as a high-advantage component of the policy gradient, bridging SFT (which suffers distributional shift and forgetting) and RL (which suffers cold-start collapse in sparse-reward visual tasks), while accelerating convergence, improving domain adaptation, and preserving general capabilities. Theoretical analysis and empirical results are asserted to validate the approach.
Significance. If the claimed unbiasedness of the augmented group-relative advantage and the empirical superiority hold under proper controls, S-GRPO could provide a practical mechanism for stable post-training of LVLMs that avoids both SFT's forgetting and RL's exploration failures. The explicit injection of a verified anchor in failure cases is a concrete design choice that merits evaluation against standard GRPO or PPO baselines in visual domains.
major comments (2)
- [Abstract / §3 (method)] The central claim that CGI 'reformulates the supervised learning objective as a high-advantage component of the policy gradient' without distorting group-relative advantages requires an explicit derivation. No equations are supplied showing the effect of the fixed-maximum outlier reward on the normalized advantages of the non-injected samples or proving that the resulting gradient remains unbiased (or has controlled variance) when injection occurs frequently in sparse-reward settings. This is load-bearing for the unification claim.
- [§4 (experiments)] The weakest assumption—that a binary verifier can reliably detect complete exploratory failure and that deterministic maximal-reward injection produces a stable positive signal—needs empirical validation. The manuscript must report the injection frequency across domains, ablation on verifier error rates, and comparison of advantage variance with/without CGI (e.g., in the main results table or §4.3).
minor comments (2)
- [Abstract] The abstract states 'theoretical analysis' but provides no equations, lemmas, or proof sketches; these should be added to §3 or an appendix even if informal.
- [§4.2] Baseline comparisons should explicitly include standard GRPO, PPO, and pure SFT with the same verifier and reward model to isolate the contribution of CGI.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and will revise the manuscript to incorporate the requested clarifications and additional analyses.
read point-by-point responses
-
Referee: [Abstract / §3 (method)] The central claim that CGI 'reformulates the supervised learning objective as a high-advantage component of the policy gradient' without distorting group-relative advantages requires an explicit derivation. No equations are supplied showing the effect of the fixed-maximum outlier reward on the normalized advantages of the non-injected samples or proving that the resulting gradient remains unbiased (or has controlled variance) when injection occurs frequently in sparse-reward settings. This is load-bearing for the unification claim.
Authors: We agree that an explicit derivation is needed to rigorously support the unification claim. In the revised manuscript we will expand §3 with a formal derivation. Let R_g be the group reward vector; when CGI injects a verified ground-truth trajectory with deterministic reward R_max, the group mean becomes (sum R_i + R_max)/(N+1). The normalized advantages for the original N trajectories are then (R_i - mean') / std', which increases their relative advantage without altering the sign or ordering among non-injected samples. Because injection occurs only on total failure (detected by the binary verifier) and the policy gradient is still computed as an expectation over the augmented group, the estimator remains unbiased with respect to the true advantage; variance is controlled by the fact that R_max is a fixed upper bound rather than an unbounded outlier. We will also include a short variance analysis for sparse-reward regimes. revision: yes
-
Referee: [§4 (experiments)] The weakest assumption—that a binary verifier can reliably detect complete exploratory failure and that deterministic maximal-reward injection produces a stable positive signal—needs empirical validation. The manuscript must report the injection frequency across domains, ablation on verifier error rates, and comparison of advantage variance with/without CGI (e.g., in the main results table or §4.3).
Authors: We acknowledge that the current experimental section does not contain these specific diagnostics. In the revised manuscript we will add to §4: (i) injection-frequency statistics broken down by domain and task, (ii) an ablation that injects controlled verifier error rates (false-positive and false-negative rates) and measures downstream performance, and (iii) a direct comparison of advantage variance (mean and standard deviation of the normalized advantages) with and without CGI, reported both in the main results table and in §4.3. These additions will empirically substantiate the stability of the positive signal under realistic verifier conditions. revision: yes
Circularity Check
S-GRPO introduces an independent CGI mechanism without reducing claims to fitted inputs or self-citations by construction
full rationale
The paper's core contribution is the Conditional Ground-Truth Trajectory Injection (CGI) step within S-GRPO, which augments failed groups with a verified ground-truth trajectory carrying deterministic maximal reward before recomputing group-relative advantages. The abstract frames this as reformulating the supervised objective as a high-advantage policy-gradient component, but supplies no equations, derivations, or self-citations that reduce the claimed bridging of SFT and RL, the acceleration of convergence, or the advantage estimation to the inputs by definition. No fitted parameters are relabeled as predictions, no uniqueness theorems are imported from prior author work, and no ansatz is smuggled via citation. The mechanism is presented as a distinct algorithmic intervention rather than a tautological re-expression of existing objectives, making the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A binary verifier exists that can correctly identify when all sampled trajectories in a group constitute complete exploratory failure.
invented entities (2)
-
S-GRPO
no independent evidence
-
Conditional Ground-Truth Trajectory Injection (CGI)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Peter Anderson, Basura Fernando, Mark Johnson, and Stephen Gould. 2016. Spice: Semantic propositional image caption evaluation. InEuropean conference on computer vision. Springer, 382–398
2016
-
[2]
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. 2023. Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond.arXiv preprint arXiv:2308.12966(2023)
work page internal anchor Pith review arXiv 2023
-
[3]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. 2025. Qwen2.5-VL Technical Rep...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Jiawei Chen, Dingkang Yang, Yue Jiang, Mingcheng Li, Jinjie Wei, Xiaolu Hou, and Lihua Zhang. 2024. Efficiency in Focus: LayerNorm as a Catalyst for Fine-tuning Medical Visual Language Models. InProceedings of the 32nd ACM International Conference on Multimedia. 3122–3130
2024
-
[6]
Xinlei Chen, Hao Fang, Tsung-Yi Lin, Ramakrishna Vedantam, Saurabh Gupta, Pi- otr Dollár, and C Lawrence Zitnick. 2015. Microsoft coco captions: Data collection and evaluation server.arXiv preprint arXiv:1504.00325(2015)
work page internal anchor Pith review arXiv 2015
-
[7]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al . 2024. Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling.arXiv preprint arXiv:2412.05271(2024)
work page internal anchor Pith review arXiv 2024
-
[8]
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al . 2024. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 24185–24198
2024
-
[9]
Tianzhe Chu, Yuexiang Zhai, Jihan Yang, Shengbang Tong, Saining Xie, Dale Schuurmans, Quoc V Le, Sergey Levine, and Yi Ma. 2025. Sft memorizes, rl generalizes: A comparative study of foundation model post-training.arXiv preprint arXiv:2501.17161(2025)
work page internal anchor Pith review arXiv 2025
-
[10]
Dina Demner-Fushman, Sameer Antani, Matthew Simpson, and George R Thoma
-
[11]
Design and development of a multimodal biomedical information retrieval system.Journal of Computing Science and Engineering6, 2 (2012), 168–177
2012
- [12]
-
[13]
Hongyuan Dong, Zijian Kang, Weijie Yin, Xiao Liang, Chao Feng, and Jiao Ran
-
[14]
Scalable vision language model training via high quality data curation. arXiv preprint arXiv:2501.05952(2025)
-
[15]
Zhizhao Duan, Hao Cheng, Duo Xu, Xi Wu, Xiangxie Zhang, Xi Ye, and Zhen Xie
-
[16]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Cityllava: Efficient fine-tuning for vlms in city scenario. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 7180–7189
-
[17]
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Zhenyu Qiu, Wei Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, and Rongrong Ji. 2023. MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models.ArXivabs/2306.13394 (2023). https://api.semanticscholar.org/ CorpusID:259243928
work page internal anchor Pith review arXiv 2023
-
[18]
Jiahui Gao, Renjie Pi, Jipeng Zhang, Jiacheng Ye, Wanjun Zhong, Yufei Wang, Lanqing HONG, Jianhua Han, Hang Xu, Zhenguo Li, and Lingpeng Kong. 2025. G-LLaVA: Solving Geometric Problem with Multi-Modal Large Language Model. InThe Thirteenth International Conference on Learning Representations. https: //openreview.net/forum?id=px1674Wp3C
2025
-
[19]
Zhangwei Gao, Zhe Chen, Erfei Cui, Yiming Ren, Weiyun Wang, Jinguo Zhu, Hao Tian, Shenglong Ye, Junjun He, Xizhou Zhu, et al. 2024. Mini-InternVL: a flexible- transfer pocket multi-modal model with 5% parameters and 90% performance. Visual Intelligence2, 1 (2024), 1–17
2024
-
[20]
LoRA: Low-Rank Adaptation of Large Language Models
J. Edward Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, and Weizhu Chen. 2021. LoRA: Low-Rank Adaptation of Large Language Models.ArXivabs/2106.09685 (2021). https://api.semanticscholar.org/CorpusID: 235458009
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[21]
Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A
James Kirkpatrick, Razvan Pascanu, Neil C. Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A. Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, Demis Hassabis, Claudia Clopath, Dharshan Kumaran, and Raia Hadsell. 2016. Overcoming catastrophic forgetting in neural networks. Proceedings of the National Academy of Sciences114 (...
2016
-
[22]
Komal Kumar, Tajamul Ashraf, Omkar Thawakar, Rao Muhammad Anwer, Hisham Cholakkal, Mubarak Shah, Ming-Hsuan Yang, Phillip H. S. Torr, Fa- had Shahbaz Khan, and Salman Khan. 2025. LLM Post-Training: A Deep Dive into Reasoning Large Language Models. arXiv:2502.21321 [cs.CL] https: //arxiv.org/abs/2502.21321
- [23]
-
[24]
Selvaraju, Akhilesh Deepak Gotmare, Shafiq R
Junnan Li, Ramprasaath R. Selvaraju, Akhilesh Deepak Gotmare, Shafiq R. Joty, Caiming Xiong, and Steven C. H. Hoi. 2021. Align before Fuse: Vision and Language Representation Learning with Momentum Distillation. InNeural Infor- mation Processing Systems. https://api.semanticscholar.org/CorpusID:236034189
2021
-
[25]
Xiang Lisa Li and Percy Liang. 2021. Prefix-Tuning: Optimizing Continuous Prompts for Generation.Proceedings of the 59th Annual Meeting of the Asso- ciation for Computational Linguistics and the 11th International Joint Confer- ence on Natural Language Processing (Volume 1: Long Papers)(2021), 4582–4597. https://api.semanticscholar.org/CorpusID:230433941
2021
- [26]
-
[27]
Chin-Yew Lin. 2004. Rouge: A package for automatic evaluation of summaries. InText summarization branches out. 74–81
2004
-
[28]
Yong Lin, Lu Tan, Hangyu Lin, Wei Xiong, Zeming Zheng, Renjie Pi, Jipeng Zhang, Shizhe Diao, Haoxiang Wang, Hanze Dong, Han Zhao, Yuan Yao, and T. Zhang
-
[29]
InConference on Empirical Meth- ods in Natural Language Processing
Mitigating the Alignment Tax of RLHF. InConference on Empirical Meth- ods in Natural Language Processing. https://api.semanticscholar.org/CorpusID: 261697277
-
[30]
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. 2023. Improved Baselines with Visual Instruction Tuning
2023
-
[31]
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. 2024. LLaVA-NeXT: Improved reasoning, OCR, and world knowl- edge. https://llava-vl.github.io/blog/2024-01-30-llava-next/
2024
-
[32]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual Instruc- tion Tuning. InNeurIPS
2023
-
[33]
Training language models to follow instructions with human feedback
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schul- man, Jacob Hilton, Fraser Kelton, Luke E. Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Francis Christiano, Jan Leike, and Ryan J. Lowe. 2022. Training language models to follow instruction...
work page internal anchor Pith review arXiv 2022
-
[34]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a Method for Automatic Evaluation of Machine Translation. InProceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Pierre Isabelle, Eugene Charniak, and Dekang Lin (Eds.). Association for Computational Linguistics, Philadelphia, Pennsylvania, USA, 31...
-
[35]
Qwen Team. 2026. Qwen3.5: Towards Native Multimodal Agents. https://qwen. ai/blog?id=qwen3.5
2026
-
[36]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning Transferable Visual Models From Natural Language Supervision. InInternational Conference on Machine Learning. https://api.semanticscholar.org/CorpusID:231591445
2021
-
[37]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. 2023. Direct Preference Optimization: Your Language Model is Secretly a Reward Model.ArXivabs/2305.18290 (2023). https://api. semanticscholar.org/CorpusID:258959321
work page internal anchor Pith review arXiv 2023
-
[38]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov
-
[39]
Proximal Policy Optimization Algorithms
Proximal Policy Optimization Algorithms.ArXivabs/1707.06347 (2017). https://api.semanticscholar.org/CorpusID:28695052
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[40]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Jun-Mei Song, Mingchuan Zhang, Y. K. Li, Yu Wu, and Daya Guo. 2024. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models.ArXivabs/2402.03300 (2024). https://api.semanticscholar.org/CorpusID:267412607
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, and et al. S. H. Cai. 2026. Kimi K2.5: Visual Agentic Intelligence. arXiv:2602.02276 [cs.CL] https://arxiv.org/abs/ 2602.02276
work page internal anchor Pith review arXiv 2026
-
[42]
Qwen Team. 2025. Qwen3 Technical Report. arXiv:2505.09388 [cs.CL] https: //arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Lawrence Zitnick, and Devi Parikh
Ramakrishna Vedantam, C. Lawrence Zitnick, and Devi Parikh. 2014. CIDEr: Consensus-based image description evaluation.2015 IEEE Conference on Com- puter Vision and Pattern Recognition (CVPR)(2014), 4566–4575. https://api. semanticscholar.org/CorpusID:9026666
2014
-
[44]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. 2024. Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution.arXiv preprint arXiv:2409.12191(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [45]
-
[46]
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. 2025. InternVL3.5: Ad- vancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency. arXiv preprint arXiv:2508.18265(2025)
work page internal anchor Pith review arXiv 2025
- [47]
-
[48]
Zhiheng Xi, Wenxiang Chen, Boyang Hong, Senjie Jin, Rui Zheng, Wei He, Yiwen Ding, Shichun Liu, Xin Guo, Junzhe Wang, Honglin Guo, Wei Shen, Xiaoran Fan, Yuhao Zhou, Shihan Dou, Xiao Wang, Xinbo Zhang, Peng Sun, Tao Gui, Qi Zhang, and Xuanjing Huang. 2024. Training Large Language Models for Reasoning through Reverse Curriculum Reinforcement Learning. InIn...
2024
-
[49]
Wenyi Xiao and Leilei Gan. 2025. Fast-Slow Thinking GRPO for Large Vision-Language Model Reasoning. https://api.semanticscholar.org/CorpusID: 278129704
2025
- [50]
-
[51]
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Honglin Yu, Weinan Dai, Yuxuan Song, Xiang Wei, Haodong Zhou, Jingjing Liu, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Wei Zhang, Yi Chen, Xiaoshuai Wang, and Hongsheng Li. 2025. On-Policy Reward Modeling for Stable Reinforcement Learning in Vision-Language Models.IEEE Transactions on Pattern Analysis and Machine Intelligence47 (2025), 1245–1258
2025
- [53]
-
[54]
Chujie Zheng, Shixuan Liu, Mingze Li, Xionghui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, Jingren Zhou, and Junyang Lin
-
[55]
Group Sequence Policy Optimization
Group Sequence Policy Optimization.ArXivabs/2507.18071 (2025). https: //api.semanticscholar.org/CorpusID:280017753
work page internal anchor Pith review arXiv 2025
-
[56]
Yaowei Zheng, Junting Lu, Shenzhi Wang, Zhangchi Feng, Dongdong Kuang, and Yuwen Xiong. 2025. EasyR1: An Efficient, Scalable, Multi-Modality RL Training Framework. https://github.com/hiyouga/EasyR1
2025
-
[57]
Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, Zheyan Luo, Zhangchi Feng, and Yongqiang Ma. 2024. LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations). Association for Computational Linguistics, Bangkok, Thaila...
work page internal anchor Pith review arXiv 2024
-
[58]
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. 2023. Instruction-Following Evaluation for Large Language Models.ArXivabs/2311.07911 (2023). https://api.semanticscholar.org/ CorpusID:265157752
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[59]
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. 2025. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models. arXiv preprint arXiv:2504.10479(2025)
work page internal anchor Pith review arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.