Recognition: unknown
SpecPylot: Python Specification Generation using Large Language Models
Pith reviewed 2026-05-10 08:42 UTC · model grok-4.3
The pith
SpecPylot pairs large language models with symbolic execution to generate and refine verifiable contracts for Python programs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SpecPylot synthesizes icontract annotations for Python programs by prompting LLMs for candidate contracts and then using Crosshair's symbolic execution engine to validate them, updating the contracts whenever a counterexample reveals a mismatch with observed behavior while keeping the program source unchanged.
What carries the argument
The SpecPylot loop of LLM-generated candidate contracts followed by Crosshair bounded symbolic search that detects mismatches and drives targeted contract updates.
If this is right
- Most programs receive contracts that Crosshair can verify without changes to the source code.
- Only the generated annotations are revised when mismatches are found, preserving the original implementation.
- Coverage-driven pytest stubs are produced automatically alongside the contracts.
- Detailed execution artifacts from the symbolic runs support debugging of specification issues.
- The approach remains limited by the depth of bounded symbolic exploration and by variability across different LLMs.
Where Pith is reading between the lines
- Teams could adopt the generated contracts as a starting point for manual review rather than starting from a blank specification.
- The same pattern of LLM proposal plus symbolic refinement might apply to other contract languages if equivalent symbolic checkers exist.
- Repeated runs with varied LLM prompts could be used to widen the set of candidate contracts before symbolic refinement begins.
- The generated contracts and test stubs could serve as regression checks when the underlying program is later modified.
Load-bearing premise
The contracts proposed by the language model are close enough to correct behavior that bounded symbolic search can locate and correct the remaining differences.
What would settle it
A collection of Python functions on which every LLM-proposed contract set lies outside the reachable correction distance of Crosshair's bounded symbolic engine, so that no sequence of counterexample-driven updates produces a passing contract.
Figures


read the original abstract
Automatically generating formal specifications could reduce the effort needed to improve program correctness, but in practice, this is still challenging. Many developers avoid writing contracts by hand, which limits the use of automated verification tools. Recent large language models (LLMs) can generate specifications from code, but these specifications often fail in terms of verification. The reason is syntax errors, overly strict constraints, or mismatches with program behavior. We present SpecPylot, a Python tool that synthesizes executable specifications for Python programs as icontract annotations and checks them using crosshair's symbolic execution. The tool relies on LLMs to propose candidate contracts and uses crosshair to validate them. When crosshair finds a concrete counterexample, SpecPylot updates only the generated contracts and leaves the program itself untouched. In addition, the tool can produce coverage-driven pytest stubs and keep detailed execution artifacts that are useful during debugging. Overall, the evaluation indicates that SpecPylot is able to generate crosshair-compatible contracts for most programs, but it also highlights the practical limits introduced by bounded symbolic exploration and differences in LLM behavior.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents SpecPylot, a Python tool that uses LLMs to propose candidate icontract annotations for programs, then employs Crosshair's bounded symbolic execution to detect counterexamples and refine only the contracts (leaving the program code unchanged). It additionally generates coverage-driven pytest stubs and retains execution artifacts for debugging. The central claim is that this process yields crosshair-compatible contracts for most programs, subject to limits from bounded exploration and LLM variability.
Significance. If the claims hold with proper quantification, the work demonstrates a practical integration of LLM-generated candidates with symbolic validation for specification synthesis, which could reduce manual effort in adopting verification tools. The design choice to update contracts rather than programs and to preserve debugging artifacts is a clear strength. However, the unevaluated nature of the reported results limits immediate significance for the field.
major comments (2)
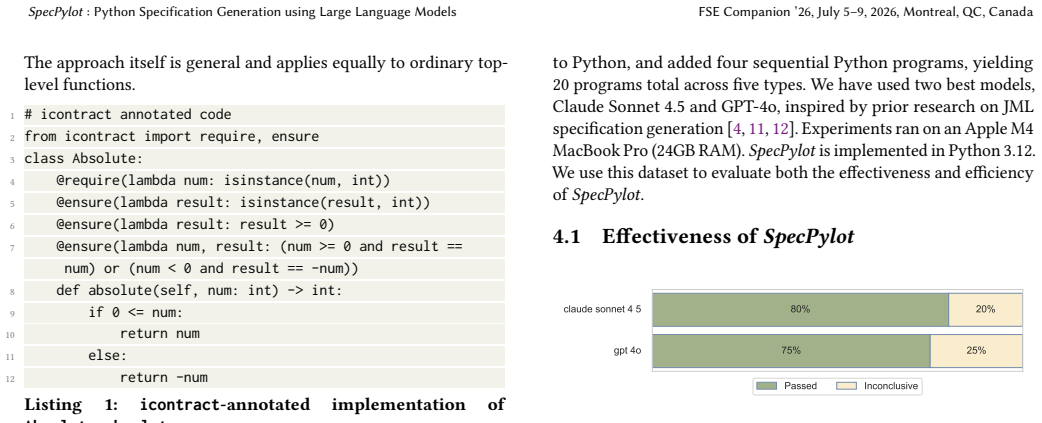
- [§5] §5 (Evaluation): The claim that SpecPylot 'is able to generate crosshair-compatible contracts for most programs' is unsupported by any quantitative data, including test-suite size, success rate, failure-mode breakdown, or baseline comparisons. Without these, the central effectiveness claim cannot be assessed.
- [§3] §3 (Approach, refinement loop): The validation step assumes Crosshair's bounded symbolic search will surface all mismatches between LLM-proposed contracts and program behavior. The abstract itself notes 'practical limits introduced by bounded symbolic exploration,' yet no analysis quantifies how often violations fall outside the bound (e.g., large arrays or deeper recursion) and are therefore silently accepted as compatible.
minor comments (2)
- [Abstract] The abstract and §5 refer to 'the evaluation' without specifying the programs, LLMs, or Crosshair configuration parameters used, making replication difficult.
- [§3] Notation for contract refinement steps could be clarified with a small pseudocode listing or state diagram in §3.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments highlight important areas for strengthening the evaluation and discussion of limitations. We address each major comment below and commit to revisions that improve the manuscript's rigor without misrepresenting the current work.
read point-by-point responses
-
Referee: [§5] §5 (Evaluation): The claim that SpecPylot 'is able to generate crosshair-compatible contracts for most programs' is unsupported by any quantitative data, including test-suite size, success rate, failure-mode breakdown, or baseline comparisons. Without these, the central effectiveness claim cannot be assessed.
Authors: We agree that the evaluation section would benefit from more detailed quantitative support. The current manuscript reports that the tool succeeds on most programs in our evaluated set and notes LLM variability and bounded exploration as factors, but it does not include explicit metrics such as the number of programs/functions tested, success percentages, failure-mode categorization, or comparisons to baselines (e.g., unrefined LLM outputs). In the revised version we will expand §5 with these details: test-suite composition and size, success rates for generating crosshair-compatible contracts, a breakdown of failure cases (syntax, over-constraining, behavioral mismatch, timeouts), and baseline comparisons where feasible. This will make the effectiveness claim directly assessable. revision: yes
-
Referee: [§3] §3 (Approach, refinement loop): The validation step assumes Crosshair's bounded symbolic search will surface all mismatches between LLM-proposed contracts and program behavior. The abstract itself notes 'practical limits introduced by bounded symbolic exploration,' yet no analysis quantifies how often violations fall outside the bound (e.g., large arrays or deeper recursion) and are therefore silently accepted as compatible.
Authors: We acknowledge that while the abstract and §3 note the practical limits of bounded exploration, the paper does not quantify the rate at which violations might be missed due to bounds on array sizes, recursion depth, or other parameters. Providing a precise frequency is inherently difficult because determining all possible mismatches would require exhaustive (and often undecidable) verification. In the revision we will add a dedicated discussion subsection that specifies the exact Crosshair bounds employed, provides concrete examples of potential missed cases (e.g., deep recursion or large inputs), and clarifies that the approach targets practical, bounded compatibility rather than soundness guarantees. We will also note this as an explicit limitation for future work. revision: partial
Circularity Check
No circularity; tool evaluation rests on external LLM and symbolic-execution components
full rationale
The manuscript describes an engineering tool (SpecPylot) that invokes an external LLM to propose icontract candidates and then invokes the independent Crosshair symbolic executor to detect mismatches and drive refinement. No equations, fitted parameters, or self-referential definitions appear in the derivation or evaluation claims. Success is measured by observable outcomes of these external components on benchmark programs; the bounded-search limitation is explicitly flagged rather than hidden by construction. The central claim therefore does not reduce to any of the enumerated circularity patterns and remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Bounded symbolic execution with Crosshair is sufficient to detect meaningful mismatches between generated contracts and program behavior.
invented entities (1)
-
SpecPylot
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Toufique Ahmed and Premkumar Devanbu. 2022. Few-shot training llms for project-specific code-summarization. InProceedings of the 37th IEEE/ACM inter- national conference on automated software engineering. 1–5
2022
-
[2]
Anoud Alshnakat, Dilian Gurov, Christian Lidström, and Philipp Rümmer. 2020. Constraint-based contract inference for deductive verification.Deductive Software Verification: Future Perspectives: Reflections on the Occasion of 20 Years of KeY (2020), 149–176
2020
-
[3]
Ragib Shahariar Ayon. 2026. Specpylot Tool Demonstration. https://youtu.be/K az4Bvb93ro. [Online; accessed Jan-2026]
2026
-
[4]
Ragib Shahariar Ayon and Shibbir Ahmed. 2026. AutoReSpec: A Framework for Generating Specification using Large Language Models. InProceedings of the 2026 IEEE/ACM Third International Conference on AI Foundation Models and Software Engineering (FORGE ’26)(Rio de Janeiro, Brazil). ACM, New York, NY, USA, 1–11. doi:10.1145/3793655.3793731
-
[5]
SpecPylot: Python Specification Generation using Large Language Models
Ragib Shahariar Ayon and Shibbir Ahmed. 2026. Replication Package of the FSE 2026 Tool Demo Paper Entitled "SpecPylot: Python Specification Generation using Large Language Models". Zenodo. doi:10.5281/zenodo.19491112 Accepted at the 34th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (FSE Compan...
-
[6]
Saikat Chakraborty, Shuvendu Lahiri, Sarah Fakhoury, Akash Lal, Madanlal Musuvathi, Aseem Rastogi, Aditya Senthilnathan, Rahul Sharma, and Nikhil Swamy. 2023. Ranking llm-generated loop invariants for program verification. In Findings of the Association for Computational Linguistics: EMNLP 2023. 9164–9175
2023
-
[7]
Patrick Cousot, Radhia Cousot, Manuel Fähndrich, and Francesco Logozzo. 2013. Automatic inference of necessary preconditions. InInternational Workshop on Verification, Model Checking, and Abstract Interpretation. Springer, 128–148
2013
-
[8]
Michael D Ernst, Jeff H Perkins, Philip J Guo, Stephen McCamant, Carlos Pacheco, Matthew S Tschantz, and Chen Xiao. 2007. The Daikon system for dynamic detection of likely invariants.Science of computer programming69, 1-3 (2007), 35–45
2007
- [9]
-
[10]
Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang. 2024. Large language models for software engineering: A systematic literature review.ACM Transactions on Software Engineering and Methodology33, 8 (2024), 1–79
2024
-
[11]
Thanh Le-Cong, Bach Le, and Toby Murray. 2025. Can LLMs Reason About Program Semantics? A Comprehensive Evaluation of LLMs on Formal Specifica- tion Inference. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (Eds.)...
-
[12]
Lezhi Ma, Shangqing Liu, Yi Li, Xiaofei Xie, and Lei Bu. 2025. SpecGen: Automated Generation of Formal Program Specifications via Large Language Models. In2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). 16–28. doi:10.1109/ICSE55347.2025.00129
-
[13]
Facundo Molina, Pablo Ponzio, Nazareno Aguirre, and Marcelo Frias. 2021. EvoSpex: An evolutionary algorithm for learning postconditions. In2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE). IEEE, 1223–1235
2021
-
[14]
Kexin Pei, David Bieber, Kensen Shi, Charles Sutton, and Pengcheng Yin. 2023. Can large language models reason about program invariants?. InInternational Conference on Machine Learning. PMLR, 27496–27520
2023
-
[15]
Marko Ristin. 2017. icontract-hypothesis - Combine contracts and automatic testing. https://github.com/mristin/icontract-hypothesis. [Online; accessed 20-July-2022]
2017
-
[16]
Phillip Schanely. 2017. CrossHair - An analysis tool for Python that blurs the line between testing and type systems. https://github.com/pschanely/CrossHair. [Online; accessed 20-July-2022]
2017
- [17]
- [18]
- [19]
-
[20]
Zhengran Zeng, Hanzhuo Tan, Haotian Zhang, Jing Li, Yuqun Zhang, and Ling- ming Zhang. 2022. An extensive study on pre-trained models for program under- standing and generation. InProceedings of the 31st ACM SIGSOFT international symposium on software testing and analysis. 39–51
2022
-
[21]
Jiyang Zhang, Marko Ristin, Phillip Schanely, Hans Wernher van de Venn, and Milos Gligoric. 2022. Python-by-Contract Dataset. InProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE). ACM, 1652–1656
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.