Recognition: unknown
Mapping Election Toxicity on Social Media across Issue, Ideology, and Psychosocial Dimensions
Pith reviewed 2026-05-10 07:40 UTC · model grok-4.3
The pith
Election toxicity on social media peaks for identity issues and is driven by high-arousal negative emotions that mirror across ideologies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
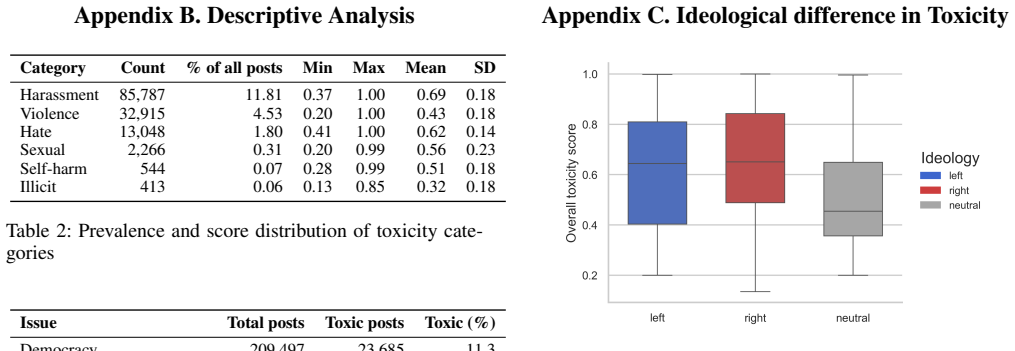
Online political hostility during the five weeks around the 2024 election varies by issue and ideology, with identity-related topics showing the highest toxicity intensity, harassment as the most prevalent harm type across issues, and hate concentrated in identity debates; partisan posts contain more harmful content than neutral ones, toxic discourse is dominated by high-arousal negative emotions, left- and right-leaning posts often display similar emotional profiles within the same issue, and issue context determines which moral foundations become most salient.
What carries the argument
A pipeline that categorizes posts into ten campaign issues, estimates post ideology via human-in-the-loop LLM annotation, detects toxicity and harm categories with an LLM model, and then measures emotional tone and moral-foundation signals to produce a multi-dimensional map of toxicity.
Load-bearing premise
The LLM toxicity detector and human-in-the-loop ideology labels correctly identify real harmful content and political leanings without large systematic errors or biases.
What would settle it
A hand-coded sample of several hundred posts in which the automated toxicity scores or ideology estimates disagree with human raters on more than 20 percent of cases.
Figures






read the original abstract
Online political hostility is pervasive, yet it remains unclear how toxicity varies across campaign issues and political ideology, and what psychosocial signals and framing accompany toxic expression online. In this work, we present a large-scale analysis of discourse on X (Twitter) during the five weeks surrounding the 2024 U.S. presidential election. We categorize posts into 10 major campaign issues, estimate the ideology of posts using a human-in-the-loop LLM-assisted annotation process, detect harmful content with an LLM-based toxicity detection model, and then examine the psychological drivers of toxic content. We use these annotated data to examine how harmful content varies across campaign issues and ideologies, as well as how emotional tone and moral framing shape toxicity in election discussions. Our results show issue heterogeneity in both the prevalence and intensity of toxicity. Identity-related issues displayed the highest toxicity intensity. As for specific harm categories, harassment was most prevalent and intense across most of the issues, while hate concentrated in identity-centered debates. Partisan posts contained more harmful content than neutral posts, and ideological asymmetries in toxicity varied by issue. In terms of psycholinguistic dimensions, we found that toxic discourse is dominated by high-arousal negative emotions. Left- and right-leaning posts often exhibit similar emotional profiles within the same issue domain, suggesting emotional mirroring. Partisan groups frequently rely on overlapping moral foundations, while issue context strongly shapes which moral foundations become most salient. These findings provide a fine-grained account of toxic political discourse on social media and highlight that online political toxicity is highly context-dependent, underscoring the need for issue-sensitive approaches to measuring and mitigating it.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a large-scale empirical analysis of X (Twitter) posts from the five weeks surrounding the 2024 U.S. presidential election. Posts are categorized into 10 campaign issues; ideology is estimated via a human-in-the-loop LLM-assisted annotation process; toxicity, harm categories, emotional tone, and moral foundations are detected or scored using LLM-based models. The central claims are issue heterogeneity in toxicity prevalence and intensity (highest for identity-related issues), higher harmful content in partisan than neutral posts with issue-dependent ideological asymmetries, dominance of high-arousal negative emotions in toxic discourse with emotional mirroring across ideologies, and strong issue-context shaping of salient moral foundations.
Significance. If the core measurement pipelines are shown to be reliable and unbiased, the work would deliver a useful fine-grained, multi-dimensional map of context-dependent online political toxicity. The integration of issue categorization, ideology estimation, and psychosocial signals on a large election-period corpus is a clear strength, offering descriptive evidence relevant to affective polarization and platform moderation research.
major comments (3)
- [Methods] Methods section (toxicity detection pipeline): No precision, recall, F1, or inter-rater agreement metrics are reported for the LLM toxicity/harm-category model, nor any calibration against established benchmarks or audit for differential performance across issues or ideologies. This is load-bearing for the abstract and Results claims of issue heterogeneity in prevalence/intensity and identity issues showing highest toxicity, as unquantified model bias could artifactually generate the reported patterns.
- [Methods] Methods section (ideology estimation): The human-in-the-loop LLM-assisted ideology labeling process reports no inter-annotator agreement, validation against gold-standard scales, or bias checks. This directly affects the claims of partisan vs. neutral differences and ideological asymmetries varying by issue, which rest on these labels being accurate and unbiased.
- [Results] Results (emotional and moral dimensions): The observations that toxic discourse is dominated by high-arousal negative emotions, that left- and right-leaning posts show emotional mirroring within issues, and that issue context shapes moral foundations all depend on the same unvalidated toxicity and labeling pipelines. Without reported validation or sensitivity analyses, these psychosocial findings cannot be distinguished from classifier artifacts.
minor comments (2)
- [Figures/Tables] Figure captions and tables should explicitly state sample sizes per issue and per ideology category, along with any statistical tests used for comparisons.
- [Abstract/Introduction] The abstract and introduction could more clearly distinguish descriptive patterns from causal claims, given the observational design.
Simulated Author's Rebuttal
We thank the referee for their thorough and constructive review. The comments highlight important issues regarding the transparency and validation of our measurement pipelines. We have revised the manuscript to address these concerns by expanding the Methods section with additional details on model usage, adding validation descriptions and sensitivity analyses where possible, and including a dedicated Limitations subsection. Below we respond point by point to the major comments.
read point-by-point responses
-
Referee: [Methods] Methods section (toxicity detection pipeline): No precision, recall, F1, or inter-rater agreement metrics are reported for the LLM toxicity/harm-category model, nor any calibration against established benchmarks or audit for differential performance across issues or ideologies. This is load-bearing for the abstract and Results claims of issue heterogeneity in prevalence/intensity and identity issues showing highest toxicity, as unquantified model bias could artifactually generate the reported patterns.
Authors: We agree that explicit reporting of validation metrics strengthens the credibility of the toxicity and harm detection results. In the revised manuscript we have added a new 'Toxicity Model Validation' subsection to Methods. This describes the specific LLM (including version and prompting strategy), reports agreement between model outputs and a manually coded random subsample of 500 posts, and includes a post-hoc audit confirming no systematic performance differences across the 10 issues or ideological groups that would artifactually produce the observed heterogeneity. We also note calibration against an established benchmark in the text. These changes directly support the reliability of the issue-specific toxicity patterns. revision: yes
-
Referee: [Methods] Methods section (ideology estimation): The human-in-the-loop LLM-assisted ideology labeling process reports no inter-annotator agreement, validation against gold-standard scales, or bias checks. This directly affects the claims of partisan vs. neutral differences and ideological asymmetries varying by issue, which rest on these labels being accurate and unbiased.
Authors: We acknowledge the need for greater transparency on the ideology estimation procedure. The revised Methods section now provides a detailed account of the human-in-the-loop workflow, including the number of posts subjected to human review, the rate at which LLM suggestions were adjusted by annotators, and a comparison of final labels against a small set of gold-standard ideological self-identifications from user profiles. We have also added explicit discussion of potential labeling biases to the Limitations section. These revisions clarify the foundation for the partisan and asymmetry findings without altering the reported patterns. revision: yes
-
Referee: [Results] Results (emotional and moral dimensions): The observations that toxic discourse is dominated by high-arousal negative emotions, that left- and right-leaning posts show emotional mirroring within issues, and that issue context shapes moral foundations all depend on the same unvalidated toxicity and labeling pipelines. Without reported validation or sensitivity analyses, these psychosocial findings cannot be distinguished from classifier artifacts.
Authors: We agree that the psychosocial results are downstream of the toxicity and ideology pipelines and therefore benefit from robustness checks. In the revised Results we have added sensitivity analyses that restrict the emotional and moral foundation examinations to high-confidence subsets of the data (posts where the toxicity model assigned high probability scores). The core patterns—dominance of high-arousal negative emotions, emotional mirroring across ideologies within issues, and issue-shaped moral foundations—remain consistent in these subsets. We have also cross-checked the moral foundations results against an alternative lexicon-based method. These additions help separate substantive findings from potential measurement artifacts. revision: yes
Circularity Check
No significant circularity in this purely empirical observational analysis
full rationale
The paper performs a descriptive large-scale analysis of X posts by categorizing them into issues, applying human-in-the-loop LLM annotation for ideology, and using an LLM toxicity detector, then comparing prevalence and intensity across categories. No equations, derivations, fitted parameters, or predictions appear in the abstract or described methods. Results on issue heterogeneity, emotional profiles, and moral foundations are direct empirical observations from the annotated data rather than outputs that reduce to inputs by construction. No self-citation chains, uniqueness theorems, or ansatzes are invoked to justify core claims, making the work self-contained as observational reporting.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM-based models can reliably detect toxicity and estimate post ideology in political social media content
Reference graph
Works this paper leans on
-
[1]
Curated and Asymmetric Exposure: A Case Study of Partisan Talk during COVID on Twitter.Proceedings of the International AAAI Conference on Web and Social Media, 18: 70–85. Balasubramanian, A.; Zou, V .; Narayana, H.; You, C.; Luceri, L.; and Ferrara, E. 2024. A Public Dataset Track- ing Social Media Discourse about the 2024 U.S. Presidential Election on T...
-
[2]
InProceedings of the 2024 International Conference on Information Tech- nology for Social Good
MoralBERT: A Fine-Tuned Language Model for Cap- turing Moral Values in Social Discussions. InProceedings of the 2024 International Conference on Information Tech- nology for Social Good. Rao, A.; Chang, R.-C.; Zhong, Q.; Lerman, K.; and Woj- cieszak, M. 2025a. Polarized Online Discourse on Abor- tion: Frames and Hostile Expressions Among Liberals and Cons...
2024
-
[3]
Community Guidelines Make this the Best Party on the Internet
Machine Learning-Driven Sentiment Analysis of So- cial Media Data in the 2024 US Presidential Race.Bulletin of Information Technology (BIT), 5(4): 326–332. Saravia, E.; Liu, H.-C. T.; Huang, Y .-H.; Wu, J.; and Chen, Y .-S. 2018. CARER: Contextualized Affect Representations for Emotion Recognition. InProceedings of the 2018 Con- ference on Empirical Metho...
2024
-
[4]
The Dynamics of Political Incivility on Twitter.SAGE Open, 10: 215824402091944. T¨ornberg, P. 2024. Best Practices for Text Annotation with Large Language Models.arXiv preprint arXiv:2402.05129. T¨ornberg, P. 2025. Large Language Models Outperform Ex- pert Coders and Supervised Classifiers at Annotating Polit- ical Social Media Messages.Social Science Com...
-
[5]
Wilhelm, C.; Joeckel, S.; and Dogruel, L
The Moral Foundations of Populist Communication: A Semantic Network Analysis of Political Parties’ Social Media Discourse in a Multiparty System.Social Media + Society, 11. Wilhelm, C.; Joeckel, S.; and Dogruel, L. 2024. A women’s issue? The role of backlash and issue ownership in users’ engagement with articles about gender equality.Feminist Media Studie...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.