Recognition: unknown
The Illusion of Certainty: Decoupling Capability and Calibration in On-Policy Distillation
Pith reviewed 2026-05-10 06:41 UTC · model grok-4.3
The pith
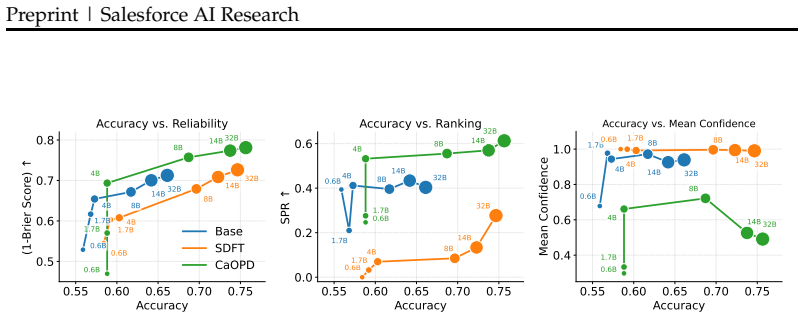
On-policy distillation boosts task accuracy but traps models in severe overconfidence due to an information mismatch between training and deployment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We identify a pervasive Scaling Law of Miscalibration: while OPD effectively improves task accuracy, it systematically traps models in severe overconfidence. We trace this failure to an information mismatch: teacher supervision is formed under privileged context available during training, whereas the deployed model must report confidence using only deployment-time information. We formalize this perspective theoretically, showing that teacher-conditioned success is generally not a valid target for deployment-time confidence and that helpful privileged context induces entropy collapse and a systematic optimism bias. To address this, we propose a calibration-aware OPD framework, CaOPD, that est
What carries the argument
The information mismatch between privileged teacher context during training and limited deployment-time information, which renders teacher-conditioned success an invalid target for confidence and produces optimism bias in the distilled model.
If this is right
- OPD will produce models whose accuracy rises while calibration worsens as training or scale increases.
- Gains in capability from distillation will not automatically yield accurate self-reported confidence.
- CaOPD can maintain competitive task accuracy while reaching Pareto-optimal calibration.
- The calibration gains of CaOPD extend to out-of-distribution inputs and continual learning settings.
Where Pith is reading between the lines
- Any distillation method that supplies richer context at training time than available at deployment may separate capability gains from calibration.
- Post-training pipelines could benefit from treating empirical confidence estimation as an explicit, separate objective.
- The observed decoupling may help explain why some instruction-tuned models remain overconfident on factual errors.
Load-bearing premise
That empirical confidence estimated from model rollouts provides a valid and superior target for distillation that avoids the optimism bias without introducing new selection effects or variance issues in the confidence labels.
What would settle it
A controlled experiment in which CaOPD models still exhibit overconfidence on deployment tasks with limited context, or in which rollout-derived confidence targets show no calibration improvement over standard OPD, would falsify the proposed remedy.
Figures






read the original abstract
On-policy distillation (OPD) is an increasingly important paradigm for post-training language models. However, we identify a pervasive Scaling Law of Miscalibration: while OPD effectively improves task accuracy, it systematically traps models in severe overconfidence. We trace this failure to an information mismatch: teacher supervision is formed under privileged context available during training, whereas the deployed model must report confidence using only deployment-time information. We formalize this perspective theoretically, showing that teacher-conditioned success is generally not a valid target for deployment-time confidence and that helpful privileged context induces entropy collapse and a systematic optimism bias. To address this, we propose a calibration-aware OPD framework, CaOPD, that estimates empirical confidence from model rollouts, replaces self-reported confidence with this student-grounded target, and distills the revised response through the same self-distillation pipeline. Experiments across various models and domains show that CaOPD achieves Pareto-optimal calibration while maintaining competitive capability, generalizing robustly under out-of-distribution and continual learning. Our findings highlight that capability distillation does not imply calibrated confidence, and that confidence should be treated as an essential objective in post-training. Code: https://github.com/SalesforceAIResearch/CaOPD
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that on-policy distillation (OPD) improves language model task accuracy but induces severe overconfidence, formalized as a 'Scaling Law of Miscalibration' arising from an information mismatch: teacher supervision uses privileged context unavailable at deployment. It theoretically shows that this leads to entropy collapse and optimism bias, making teacher-conditioned success invalid for calibration. The proposed CaOPD framework replaces self-reported confidence with empirical estimates from student rollouts and distills accordingly, with experiments demonstrating Pareto-optimal calibration, maintained capability, and robust generalization to out-of-distribution and continual learning settings.
Significance. If the theoretical formalization and experimental results hold, this work would be significant for LLM post-training research. It demonstrates that capability gains from distillation do not imply calibration and introduces a practical framework (CaOPD) to address miscalibration while preserving performance. The emphasis on treating confidence as a separate objective, combined with the open-sourced code, could influence deployment practices where reliable uncertainty is needed.
major comments (3)
- Abstract: The theoretical formalization of the information mismatch, entropy collapse, and optimism bias is asserted without any equations, definitions of key terms, or derivation steps. This is load-bearing for the central claim that teacher-conditioned success is not a valid target for deployment-time confidence, as it remains unclear whether the bias definition is independent of the fitted quantities used in the proposed fix.
- Abstract: The CaOPD method relies on rollout-based empirical confidence as the distillation target, but provides no analysis or bounds on variance, selection bias from trajectory filtering, or finite-sample effects (especially at low per-prompt success rates). This is load-bearing for whether the estimator resolves the claimed optimism bias without introducing new miscalibration issues.
- Abstract: Claims of experimental support for the Scaling Law of Miscalibration, Pareto-optimal calibration, and robust OOD/continual learning generalization lack any quantitative details, metrics, baselines, rollout counts, or error analysis, making it impossible to assess the strength or reproducibility of the findings.
minor comments (2)
- Abstract: The acronym 'CaOPD' is introduced without expansion on first use.
- Abstract: The description of experiments mentions 'various models and domains' but provides no specifics on tasks, model sizes, or evaluation metrics, which would aid clarity even at the abstract level.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight opportunities to strengthen the clarity of the abstract and the rigor of supporting analyses. We address each major comment point by point below and indicate the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: Abstract: The theoretical formalization of the information mismatch, entropy collapse, and optimism bias is asserted without any equations, definitions of key terms, or derivation steps. This is load-bearing for the central claim that teacher-conditioned success is not a valid target for deployment-time confidence, as it remains unclear whether the bias definition is independent of the fitted quantities used in the proposed fix.
Authors: We appreciate this observation regarding the abstract's conciseness. The full manuscript provides the complete theoretical formalization in Section 3, including explicit definitions of the information mismatch, entropy collapse, and optimism bias, along with derivation steps showing that teacher-conditioned success is not a valid target. The optimism bias is defined via the information asymmetry between training and deployment and is independent of the specific quantities fitted in CaOPD. To address the concern, we will revise the abstract to briefly reference these key theoretical elements and their implications for the central claim. revision: partial
-
Referee: Abstract: The CaOPD method relies on rollout-based empirical confidence as the distillation target, but provides no analysis or bounds on variance, selection bias from trajectory filtering, or finite-sample effects (especially at low per-prompt success rates). This is load-bearing for whether the estimator resolves the claimed optimism bias without introducing new miscalibration issues.
Authors: This is a valid point. While the manuscript discusses the rollout-based estimator, we agree that explicit analysis of its statistical properties is needed. We will add a dedicated subsection providing theoretical bounds on estimator variance, analysis of selection bias from trajectory filtering, and finite-sample effects (with particular attention to low per-prompt success rates). This will be supported by additional derivations and targeted experiments to confirm the estimator addresses the optimism bias without new miscalibration. revision: yes
-
Referee: Abstract: Claims of experimental support for the Scaling Law of Miscalibration, Pareto-optimal calibration, and robust OOD/continual learning generalization lack any quantitative details, metrics, baselines, rollout counts, or error analysis, making it impossible to assess the strength or reproducibility of the findings.
Authors: We acknowledge that the abstract summarizes results at a high level. The full manuscript details quantitative results in Section 5, including specific metrics (e.g., ECE), accuracy values, baselines, rollout counts, and error analysis from repeated runs. We will revise the abstract to include key quantitative highlights and ensure all experimental parameters, metrics, and reproducibility details are explicitly stated in the main text and appendix. revision: partial
Circularity Check
No significant circularity in claimed derivation
full rationale
The paper reports an empirical Scaling Law of Miscalibration observed under OPD, attributes it conceptually to an information mismatch between privileged teacher context and deployment-time inputs, and introduces CaOPD as a distinct method that substitutes rollout-estimated empirical success rates for self-reported confidence. No equations, formal derivations, or self-citations are presented that reduce the central claims or the proposed fix to the original inputs by construction. The theoretical formalization is framed as a perspective on the mismatch rather than a self-referential proof, and the rollout target is a new quantity not equivalent to the teacher-conditioned supervision it replaces. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Teacher-conditioned success under privileged context is not a valid target for deployment-time confidence
invented entities (1)
-
CaOPD framework
no independent evidence
Forward citations
Cited by 2 Pith papers
-
KL for a KL: On-Policy Distillation with Control Variate Baseline
vOPD stabilizes on-policy distillation gradients by subtracting a closed-form per-token negative reverse KL baseline as a detached control variate, preserving unbiasedness while lowering variance and matching expensiv...
-
Beyond GRPO and On-Policy Distillation: An Empirical Sparse-to-Dense Reward Principle for Language-Model Post-Training
Sparse RL on a strong teacher followed by dense distillation to the student outperforms direct GRPO on the student for math tasks, with a forward-KL + OPD bridge enabling further gains.
Reference graph
Works this paper leans on
-
[1]
In standard OPD, val(c) would typically be near 1.0, reflecting the teacher’s optimism inherited during training
Generate Verbalized Confidence:Given an input prompt x, the model (in student mode, i.e., conditioned only on x) generates a complete trajectory y= (a , c), where a is the reasoning trajectory and c is the confidence segment. In standard OPD, val(c) would typically be near 1.0, reflecting the teacher’s optimism inherited during training
-
[2]
We sampleK inde- pendent rollouts (ak, ck)∼π θ(· |x) and evaluate each with an objective task verifier to compute the empirical success rate ˆµ(x) = 1 K ∑K k=1 R(x, ak)
Approximate True Confidence:Instead of trusting the single-pass verbalized confidence, we estimate the student’s actual competence via empirical execution. We sampleK inde- pendent rollouts (ak, ck)∼π θ(· |x) and evaluate each with an objective task verifier to compute the empirical success rate ˆµ(x) = 1 K ∑K k=1 R(x, ak). This serves as a statistically ...
-
[3]
We take the student’s reasoning trajectorya from Step 1, but explicitly discard its original confidence segment c
Revise the Completion (Target Replacement):This is the core decoupling step of CaOPD. We take the student’s reasoning trajectorya from Step 1, but explicitly discard its original confidence segment c. We construct the revised completion ˜y= (a , ˆµ(x)) by overwriting the confidence tokens with the string representation of the empirical success rate. This ...
-
[4]
open-book
Construct Revised Teacher Context:To ensure the model learns advanced reasoning capabilities, we construct a privileged context z by prepending the user question with environmental feedback, ground-truth demonstrations, or correct solutions, creating an “open-book” setting for the teacher. Crucially, the confidence score withinz — originally near 1.0 — is...
-
[5]
Nc1ccn(Cc2ccc(Cl)cc2C(F)(F)F)
Compute Reverse KL Loss:Both the student πθ(· | ˜y<t, x) and the teacher πθ(· | ˜y<t, x, ˜z) perform a forward pass on the revised completion ˜y. The per-token reverse KL divergence (Equation (7)) is computed between these two distributions. As discussed in Section 4.2, this naturally decomposes into aCapability Cloningcomponent at reasoning positions and...
-
[6]
EMA Teacher Tracking:In self-distillation, the teacher is the same model with different conditioning (Section 2.1). To stabilize the teacher’s distribution during training, we maintain an Exponential Moving Average (EMA) (Tarvainen & Valpola, 2017) copy of the model weightsθ ema, updated at every gradient step:θ ema ←(1−α)θ ema +α θ. The teacher distribut...
2017
-
[7]
The engine generates a fresh batch of K studentrollouts (ak, ck)∼π θ(· |x) for each prompt on-the-fly
Dynamic Rollout Generation:Periodically during training, the latest model weights θ are synchronized to a high-throughput inference engine (vLLM (Kwon et al., 2023)). The engine generates a fresh batch of K studentrollouts (ak, ck)∼π θ(· |x) for each prompt on-the-fly
2023
-
[8]
The empirical success rate ˆµ(x) = 1 K ∑K k=1 R(x,a k)is computed strictly from thiscurrentbatch of rollouts
Online Target Computation:These newly generated student rollouts are immediately evaluated by the objective task verifier R(x, ak). The empirical success rate ˆµ(x) = 1 K ∑K k=1 R(x,a k)is computed strictly from thiscurrentbatch of rollouts
-
[9]
amortized offline
Target Replacement:The freshly computed ˆµ(x) is used to construct the revised comple- tion ˜yand revised teacher context ˜zfor the subsequent gradient optimization steps. This online, on-policy generation mechanism ensures that the supervision signal for confi- dence dynamically adapts to the model’s learning trajectory. As the model becomes more capable...
2022
-
[10]
• SDFT(Shenfeld et al., 2026) andSDPO(Hübotter et al., 2026): These represent the current state-of-the-art in on-policy self-distillation
Capability-Focused Paradigms.These methods primarily optimize for task success (capability) and serve to empirically illustrate the severe overconfidence degradation typical in standard post-training pipelines. • SDFT(Shenfeld et al., 2026) andSDPO(Hübotter et al., 2026): These represent the current state-of-the-art in on-policy self-distillation. The mod...
2026
-
[11]
Calibration Forgetting
Calibration-Aware RL Methods.To demonstrate that CaOPD is superior not only to standard distillation but also to specialized calibration techniques, we benchmark against state-of-the-art methods that explicitly shape rewards to penalize miscalibration. • RLCR(Damani et al., 2025): A reinforcement learning approach that integrates proper scoring rules (suc...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.