Recognition: unknown
Refinement of Accelerated Demonstrations via Incremental Iterative Reference Learning Control for Fast Contact-Rich Imitation Learning
Pith reviewed 2026-05-10 07:00 UTC · model grok-4.3
The pith
Incremental Iterative Reference Learning Control refines accelerated demonstrations to enable high-fidelity fast contact-rich imitation learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
I2RLC refines time-accelerated demonstrations by gradually increasing execution speed while updating the reference trajectory from observed tracking errors at each increment, resulting in high-fidelity trajectories suitable for training imitation learning policies that achieve 100% success rates and reduced contact forces in real-robot tasks like peg-in-hole and whiteboard erasing.
What carries the argument
Incremental Iterative Reference Learning Control (I2RLC), which applies IRLC iteratively at progressively higher speeds to adapt the reference trajectory and mitigate large early errors.
If this is right
- Refined demonstrations allow imitation learning policies to execute tasks faster than the original slow demonstrations.
- Policies trained on I2RLC trajectories achieve 100% success in peg-in-hole at both seen and unseen positions.
- I2RLC leads to lower contact forces in executed policies compared to IRLC-refined ones.
- The approach works for speeds from 3x to 10x and tasks including erasing and insertion.
Where Pith is reading between the lines
- This incremental approach may apply to other dynamic tasks where contact forces vary with speed, such as polishing or screwing.
- It could minimize the need for dangerous high-speed human demos in industrial settings.
- Future work might integrate I2RLC with reinforcement learning to further optimize the policies.
- The method's reliance on compliance control suggests testing on stiff robots to see if retuning is avoided.
Load-bearing premise
The compliance-controlled follower robot's tracking errors at each incremental speed accurately reflect the dynamics needed to update the reference without introducing new instabilities or requiring task-specific retuning.
What would settle it
Running the method on a new contact-rich task with different stiffness and checking whether the 22.5% spatial similarity gain and 100% policy success persist at 10x speed.
Figures








read the original abstract
Fast execution of contact-rich manipulation is critical for practical deployment, yet providing fast demonstrations for imitation learning (IL) remains challenging: humans cannot demonstrate at high speed, and naively accelerating demonstrations alters contact dynamics and induces large tracking errors. We present a method to autonomously refine time-accelerated demonstrations by repurposing Iterative Reference Learning Control (IRLC) to iteratively update the reference trajectory from observed tracking errors. However, applying IRLC directly at high speed tends to produce larger early-iteration errors and less stable transients. To address this issue, we propose Incremental Iterative Reference Learning Control (I2RLC), which gradually increases the speed while updating the reference, yielding high-fidelity trajectories. We validate on real-robot whiteboard erasing and peg-in-hole tasks using a teleoperation setup with a compliance-controlled follower and a 3D-printed haptic leader. Both IRLC and I2RLC achieve up to 10x faster demonstrations with reduced tracking error; moreover, I2RLC improves spatial similarity to the original trajectories by 22.5% on average over IRLC across three tasks and multiple speeds (3x-10x). We then use the refined trajectories to train IL policies; the resulting policies execute faster than the demonstrations and achieve 100% success rates in the peg-in-hole task at both seen and unseen positions, with I2RLC-trained policies exhibiting lower contact forces than those trained on IRLC-refined demonstrations. These results indicate that gradual speed scheduling coupled with reference adaptation provides a practical path to fast, contact-rich IL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Incremental Iterative Reference Learning Control (I2RLC) to refine time-accelerated demonstrations for contact-rich imitation learning tasks. It extends Iterative Reference Learning Control (IRLC) by gradually increasing speed while iteratively updating the reference trajectory based on tracking errors observed from a compliance-controlled follower robot in a teleoperation setup. Validation on real-robot whiteboard erasing and peg-in-hole tasks shows up to 10x faster execution, with I2RLC achieving 22.5% better average spatial similarity to original trajectories compared to IRLC, and the refined trajectories enabling imitation learning policies with 100% success rates and lower contact forces.
Significance. If the results hold, this method offers a valuable approach to generating fast, high-fidelity demonstrations for imitation learning in contact-rich scenarios where direct high-speed human demonstration is impractical. The real-robot experiments provide concrete evidence of improved trajectory similarity and policy performance, highlighting the benefit of incremental speed scheduling. This could facilitate more practical deployment of IL in manipulation tasks requiring speed and contact handling.
major comments (2)
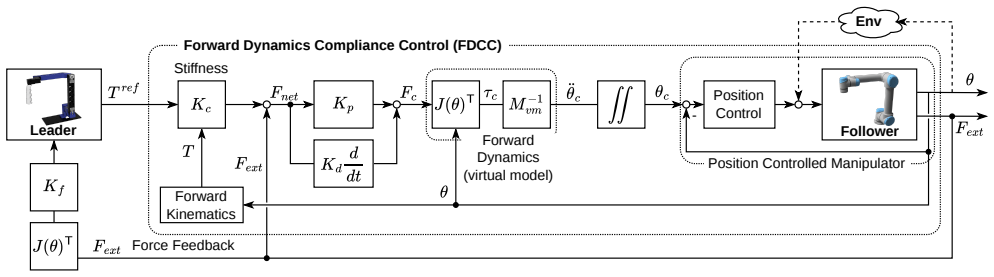
- [Abstract (validation description)] The central claim that I2RLC yields 22.5% better spatial similarity and superior IL policies with lower forces depends on the assumption that tracking errors from the compliance-controlled follower accurately capture the contact dynamics needed for reference updates. The abstract describes the follower as compliance-controlled but provides no ablation against position control and no confirmation that impedance parameters remain fixed across speeds (3x-10x) and tasks; if compliance filters transients, the refined references may not transfer to the final policy's execution regime.
- [Abstract] Abstract: the reported average 22.5% similarity gain and 100% success rates are stated without error bars, trial counts, or statistical tests, and the full methods must specify the number of runs per speed/task and how parameter choices (e.g., speed ramp schedule) were selected to substantiate the cross-task, cross-speed claims.
minor comments (1)
- [Abstract] The abstract refers to 'three tasks' but explicitly names only whiteboard erasing and peg-in-hole; the third task should be identified for clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects of experimental validation and clarity. We address each major comment below, providing explanations based on our setup and indicating revisions to the manuscript where additional details or discussion will be incorporated.
read point-by-point responses
-
Referee: [Abstract (validation description)] The central claim that I2RLC yields 22.5% better spatial similarity and superior IL policies with lower forces depends on the assumption that tracking errors from the compliance-controlled follower accurately capture the contact dynamics needed for reference updates. The abstract describes the follower as compliance-controlled but provides no ablation against position control and no confirmation that impedance parameters remain fixed across speeds (3x-10x) and tasks; if compliance filters transients, the refined references may not transfer to the final policy's execution regime.
Authors: We selected compliance control for the follower to enable safe physical interaction during teleoperation and to permit the reference updates to reflect realistic contact forces and compliance effects without risking damage to the robot or environment. The impedance parameters were held fixed across all speeds (3x-10x) and both tasks to maintain consistent dynamics in the refinement process; this choice is detailed in the methods section of the full manuscript. While we did not perform an explicit ablation against position control, the compliance setting was chosen precisely because position control would introduce excessive stiffness incompatible with contact-rich tasks. We agree that further discussion of this rationale would strengthen the paper and have added a paragraph in the revised methods and discussion sections explaining the fixed impedance parameters and why compliance better captures the necessary contact dynamics for transfer to the learned policies, which are executed on the same hardware. revision: partial
-
Referee: [Abstract] Abstract: the reported average 22.5% similarity gain and 100% success rates are stated without error bars, trial counts, or statistical tests, and the full methods must specify the number of runs per speed/task and how parameter choices (e.g., speed ramp schedule) were selected to substantiate the cross-task, cross-speed claims.
Authors: We agree that the abstract and methods require more precise reporting of experimental statistics and parameter selection to support the claims. In the revised manuscript we have expanded the experimental setup subsection to specify: five independent runs per speed multiplier and task for the similarity metrics; ten evaluation trials per trained policy for the success rates; the incremental speed ramp schedule (starting at 1x and increasing by 1x increments every two iterations until the target speed); and the selection process for the ramp (determined via preliminary stability tests to avoid large early errors). We have also added error bars to the reported 22.5% average similarity improvement, included a paired t-test result confirming statistical significance, and clarified that all parameters were held constant across the whiteboard erasing and peg-in-hole tasks. revision: yes
Circularity Check
No circularity: purely experimental method with independent robot validation
full rationale
The paper proposes an algorithmic procedure (I2RLC) that iteratively updates reference trajectories from observed tracking errors while ramping speed, then trains IL policies on the resulting data. All performance claims (22.5% spatial similarity gain, 100% success, lower forces) are measured directly from physical robot trials on whiteboard erasing and peg-in-hole tasks. No first-principles derivation, uniqueness theorem, or fitted-parameter prediction is offered; the method is self-contained against external benchmarks of real hardware execution. Any prior IRLC reference functions only as background and is not required to establish the incremental variant or its empirical outcomes.
Axiom & Free-Parameter Ledger
free parameters (2)
- speed ramp schedule
- IRLC update gains
axioms (1)
- domain assumption Tracking errors observed under compliance control can be directly used to correct the reference trajectory at each speed level without destabilizing the closed-loop system.
Reference graph
Works this paper leans on
-
[1]
Dexterous manipulation through imitation learning: A survey.arXiv preprint arXiv:2504.03515, 2025
S. An, Z. Meng, C. Tang, Y . Zhou, T. Liu, F. Ding, S. Zhang, Y . Mu, R. Song, W. Zhanget al., “Dexterous manipulation through imitation learning: A survey,”arXiv preprint arXiv:2504.03515, 2025
-
[2]
Diffusion policy: Visuomotor policy learning via ac- tion diffusion,
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song, “Diffusion policy: Visuomotor policy learning via ac- tion diffusion,”The International Journal of Robotics Research, p. 02783649241273668, 2023
2023
-
[3]
Learning fine-grained bimanual manipulation with low-cost hardware,
T. Zhao, V . Kumar, S. Levine, and C. Finn, “Learning fine-grained bimanual manipulation with low-cost hardware,”Robotics: Science and Systems, 2023
2023
-
[4]
Human-in-the-loop approach for teaching robot assembly tasks using impedance control interface,
L. Peternel, T. Petri ˇc, and J. Babi ˇc, “Human-in-the-loop approach for teaching robot assembly tasks using impedance control interface,” in IEEE International Conference on Robotics and Automation, 2015, pp. 1497–1502
2015
-
[5]
Soft and rigid object grasping with cross-structure hand using bilateral control-based imitation learning,
K. Yamane, Y . Saigusa, S. Sakaino, and T. Tsuji, “Soft and rigid object grasping with cross-structure hand using bilateral control-based imitation learning,”IEEE Robotics and Automation Letters, vol. 9, no. 2, pp. 1198–1205, 2023
2023
-
[6]
Alpha-αand bi-act are all you need: Importance of position and force information/control for imitation learning of unimanual and bimanual robotic manipulation with low-cost system,
M. Kobayashi, T. Buamanee, and T. Kobayashi, “Alpha-αand bi-act are all you need: Importance of position and force information/control for imitation learning of unimanual and bimanual robotic manipulation with low-cost system,”IEEE Access, 2025
2025
-
[7]
Y . Kanai, A. Kanazawa, H. Ichiwara, H. Ito, N. Noguchi, and T. Ogata, “Input-gated bilateral teleoperation: An easy-to-implement force feedback teleoperation method for low-cost hardware,”arXiv preprint arXiv:2509.08226, 2025
-
[8]
Improving low-cost teleoperation: Augmenting gello with force,
S. Sujit, L. Nunziante, D. O. Lillrank, R. F. J. Dossa, and K. Arulku- maran, “Improving low-cost teleoperation: Augmenting gello with force,” inIEEE/SICE International Symposium on System Integration, 2025, pp. 747–752
2025
-
[9]
J. J. Liu, Y . Li, K. Shaw, T. Tao, R. Salakhutdinov, and D. Pathak, “Factr: Force-attending curriculum training for contact-rich policy learning,”arXiv preprint arXiv:2502.17432, 2025
-
[10]
Motion retouch: Motion mod- ification using four-channel bilateral control,
K. Inami, S. Sakaino, and T. Tsuji, “Motion retouch: Motion mod- ification using four-channel bilateral control,” inIEEE International Conference on Mechatronics, 2025, pp. 1–6
2025
-
[11]
Superhuman performance of surgical tasks by robots using iterative learning from human-guided demonstrations,
J. Van Den Berg, S. Miller, D. Duckworth, H. Hu, A. Wan, X.- Y . Fu, K. Goldberg, and P. Abbeel, “Superhuman performance of surgical tasks by robots using iterative learning from human-guided demonstrations,” inIEEE International Conference on Robotics and Automation, 2010, pp. 2074–2081
2010
-
[12]
Iterative reference learning for cartesian impedance control of robot manipulators,
J. M. S. Ducaju, B. Olofsson, and R. Johansson, “Iterative reference learning for cartesian impedance control of robot manipulators,” in IEEE/RSJ International Conference on Intelligent Robots and Systems, 2024, pp. 11 171–11 178
2024
-
[13]
Hybrid force-impedance control for fast end-effector motions,
M. Iskandar, C. Ott, A. Albu-Sch ¨affer, B. Siciliano, and A. Dietrich, “Hybrid force-impedance control for fast end-effector motions,”IEEE Robotics and Automation Letters, vol. 8, no. 7, pp. 3931–3938, 2023
2023
-
[14]
High-speed ring insertion by dynamic observable contact hand,
Y . Karako, S. Kawakami, K. Koyama, M. Shimojo, T. Senoo, and M. Ishikawa, “High-speed ring insertion by dynamic observable contact hand,” inIEEE International Conference on Robotics and Automation, 2019, pp. 2744–2750
2019
-
[15]
Twist snake: Plastic table-top cable- driven robotic arm with all motors located at the base link
K. Tanaka and M. Hamaya, “Twist snake: Plastic table-top cable- driven robotic arm with all motors located at the base link.” in IEEE International Conference on Robotics and Automation, 2023, pp. 7345–7351
2023
-
[16]
High-speed electrical connec- tor assembly by structured compliance in a finray-effect gripper,
R. M. Hartisch and K. Haninger, “High-speed electrical connec- tor assembly by structured compliance in a finray-effect gripper,” IEEE/ASME Transactions on Mechatronics, vol. 29, no. 2, pp. 810– 819, 2023
2023
-
[17]
Soft robotic dynamic in-hand pen spinning,
Y . Yao, U. Yoo, J. Oh, C. G. Atkeson, and J. Ichnowski, “Soft robotic dynamic in-hand pen spinning,” inIEEE International Conference on Robotics and Automation, 2025, pp. 1–7
2025
-
[18]
Sliceit!-a dual simulator framework for learning robot food slicing,
C. C. Beltran-Hernandez, N. Erbetti, and M. Hamaya, “Sliceit!-a dual simulator framework for learning robot food slicing,” inIEEE International Conference on Robotics and Automation, 2024, pp. 4296–4302
2024
-
[19]
Learning vari- able compliance control from a few demonstrations for bimanual robot with haptic feedback teleoperation system,
T. Kamijo, C. C. Beltran-Hernandez, and M. Hamaya, “Learning vari- able compliance control from a few demonstrations for bimanual robot with haptic feedback teleoperation system,” inIEEE/RSJ International Conference on Intelligent Robots and Systems, 2024, pp. 12 663– 12 670
2024
-
[20]
Adaptive compliance policy: Learning approximate compliance for diffusion guided control,
Y . Hou, Z. Liu, C. Chi, E. Cousineau, N. Kuppuswamy, S. Feng, B. Burchfiel, and S. Song, “Adaptive compliance policy: Learning approximate compliance for diffusion guided control,” inIEEE In- ternational Conference on Robotics and Automation, 2025, pp. 4829– 4836
2025
-
[21]
Robotic compliant object prying using diffusion policy guided by vision and force observations,
J. H. Kang, S. Joshi, R. Huang, and S. K. Gupta, “Robotic compliant object prying using diffusion policy guided by vision and force observations,”IEEE Robotics and Automation Letters, 2025
2025
-
[22]
Dynamic movement primitives in robotics: A tutorial survey,
M. Saveriano, F. J. Abu-Dakka, A. Kramberger, and L. Peternel, “Dynamic movement primitives in robotics: A tutorial survey,”The International Journal of Robotics Research, vol. 42, no. 13, pp. 1133– 1184, 2023
2023
-
[23]
Imitation learn- ing for variable speed contact motion for operation up to control bandwidth,
S. Sakaino, K. Fujimoto, Y . Saigusa, and T. Tsuji, “Imitation learn- ing for variable speed contact motion for operation up to control bandwidth,”IEEE Open Journal of the Industrial Electronics Society, vol. 3, pp. 116–127, 2022
2022
-
[24]
Forward dynamics compliance control (FDCC): A new approach to cartesian compliance for robotic manipulators,
S. Scherzinger, A. Roennau, and R. Dillmann, “Forward dynamics compliance control (FDCC): A new approach to cartesian compliance for robotic manipulators,” inIEEE/RSJ International Conference on Intelligent Robots and Systems, 2017, pp. 4568–4575
2017
-
[25]
Real- time motion generation and data augmentation for grasping moving objects with dynamic speed and position changes,
K. Yamamoto, H. Ito, H. Ichiwara, H. Mori, and T. Ogata, “Real- time motion generation and data augmentation for grasping moving objects with dynamic speed and position changes,” inIEEE/SICE International Symposium on System Integration, 2024, pp. 390–397
2024
-
[26]
DemoSpeedup: Accelerating visuomotor policies via entropy-guided demonstration acceleration,
L. Guo, Z. Xue, Z. Xu, and H. Xu, “DemoSpeedup: Accelerating visuomotor policies via entropy-guided demonstration acceleration,” inConference on Robot Learning, 2025, pp. 599–609
2025
-
[27]
SAIL: Faster-than- demonstration execution of imitation learning policies,
N. R. Arachchige, Z. Chen, W. Jung, W. C. Shin, R. Bansal, P. Barroso, Y . H. He, Y . C. Lin, B. Joffe, S. Kousiket al., “SAIL: Faster-than- demonstration execution of imitation learning policies,” inConference on Robot Learning, 2025, pp. 721–749
2025
-
[28]
Policy optimization with demonstra- tions,
B. Kang, Z. Jie, and J. Feng, “Policy optimization with demonstra- tions,” inInternational Conference on Machine Learning, 2018, pp. 2469–2478
2018
-
[29]
From imitation to refinement-residual rl for precise assembly,
L. Ankile, A. Simeonov, I. Shenfeld, M. Torne, and P. Agrawal, “From imitation to refinement-residual rl for precise assembly,” in IEEE International Conference on Robotics and Automation, 2025, pp. 01–08
2025
-
[30]
A survey of iterative learning control,
D. A. Bristow, M. Tharayil, and A. G. Alleyne, “A survey of iterative learning control,”IEEE Control Systems Magazine, vol. 26, no. 3, pp. 96–114, 2006
2006
-
[31]
Gello: A general, low- cost, and intuitive teleoperation framework for robot manipulators,
P. Wu, Y . Shentu, Z. Yi, X. Lin, and P. Abbeel, “Gello: A general, low- cost, and intuitive teleoperation framework for robot manipulators,” in IEEE/RSJ International Conference on Intelligent Robots and Systems, 2024, pp. 12 156–12 163
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.