Recognition: unknown
SPS: Steering Probability Squeezing for Better Exploration in Reinforcement Learning for Large Language Models
Pith reviewed 2026-05-10 06:54 UTC · model grok-4.3
The pith
SPS interleaves standard RL with inverse RL on its own rollouts to counteract probability squeezing and expand exploration in reasoning models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The limitation in RL for reasoning LLMs arises from a squeezing effect that concentrates probability on few trajectories; SPS counters this by interleaving RL with IRL that uses the model's own on-policy rollouts as demonstrations to explicitly reshape the induced trajectory distribution, thereby increasing exploration and raising Pass@k without external supervision.
What carries the argument
Steering Probability Squeezing (SPS), the interleaving of RL optimization with IRL steps that treat current on-policy rollouts as demonstrations to reshape the trajectory probability distribution.
If this is right
- SPS raises Pass@k on standard reasoning benchmarks while preserving or improving Pass@1.
- The approach requires no additional labeled data or external reward models beyond the original rule-based signals.
- RL learning dynamics exhibit an empirical upper bound on Pass@k that pure RL training cannot exceed.
- Alternating RL and IRL phases provides a practical pathway for extending exploration capacity in reasoning-oriented models.
Where Pith is reading between the lines
- The identified upper bound on Pass@k implies that some exploration ceilings may be intrinsic to the RL objective itself rather than fixable by hyperparameter tuning alone.
- SPS-style alternation could be tested in non-reasoning RL settings where mode collapse similarly restricts output diversity.
- If the reshaping step generalizes, it may reduce the need for separate exploration bonuses or entropy regularization in LLM RL pipelines.
Load-bearing premise
The primary obstacle to exploration is probability squeezing that can be reversed by applying IRL to the model's own rollouts without introducing new biases or supervision.
What would settle it
Apply SPS to a reasoning task and measure no measurable increase in the number of distinct high-reward trajectories sampled or no improvement in Pass@k relative to standard RL training.
Figures




read the original abstract
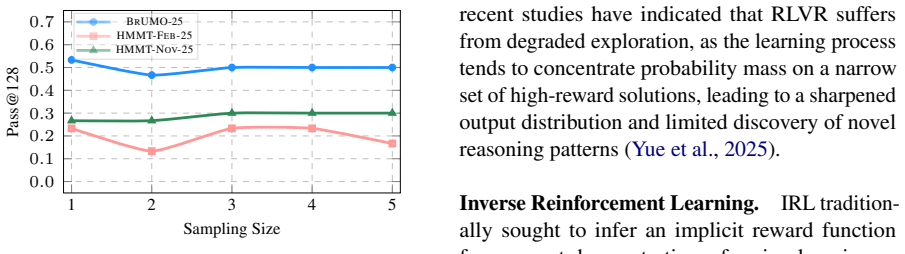
Reinforcement learning (RL) has emerged as a promising paradigm for training reasoning-oriented models by leveraging rule-based reward signals. However, RL training typically tends to improve single-sample success rates (i.e., Pass@1) while offering limited exploration of diverse reasoning trajectories, which is crucial for multi-sample performance (i.e., Pass@k). Our preliminary analysis reveals that this limitation stems from a fundamental squeezing effect, whereby probability mass is excessively concentrated on a narrow subset of high-reward trajectories, restricting genuine exploration and constraining attainable performance under RL training. To address this issue, in this work, we propose Steering Probability Squeezing (SPS), a training paradigm that interleaves conventional RL with inverse reinforcement learning (IRL). SPS treats on-policy rollouts as demonstrations and employs IRL to explicitly reshape the induced trajectory distribution, thereby enhancing exploration without introducing external supervision. Experiments on five commonly used reasoning benchmarks demonstrate that SPS can enable better exploration and improve Pass@k. Beyond algorithmic contributions, we provide an analysis of RL learning dynamics and identify an empirical upper bound on Pass@k, shedding light on intrinsic exploration limits in RL-based reasoning models. Our findings suggest that alternating between RL and IRL offers an effective pathway toward extending the exploration capacity of reasoning-oriented large language models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Steering Probability Squeezing (SPS), a training paradigm that interleaves standard RL with inverse reinforcement learning (IRL) for reasoning-oriented LLMs. It identifies a 'squeezing effect' in which RL concentrates probability mass on a narrow set of high-reward trajectories, limiting Pass@k. SPS treats the model's own on-policy rollouts as IRL demonstrations to reshape the induced trajectory distribution and improve exploration without external supervision. Experiments on five reasoning benchmarks report gains in Pass@k, accompanied by an analysis of RL dynamics and an empirical upper bound on attainable Pass@k.
Significance. If the central mechanism is shown to genuinely enlarge trajectory support rather than merely reweight within it, the work would offer a practical, supervision-free route to better exploration in RL for LLM reasoning. The empirical upper bound on Pass@k constitutes a concrete, falsifiable contribution that can guide future analyses of intrinsic limits. The interleaving approach and benchmark results, if robust, would be of interest to the RL-for-LLMs community.
major comments (2)
- [§3] §3 (SPS algorithm): The central claim that IRL applied to on-policy rollouts 'explicitly reshape[s] the induced trajectory distribution' to enhance exploration lacks a supporting argument or metric showing expansion of support. Because the demonstrations are drawn from the current (already squeezed) policy and the underlying reward is rule-based, standard IRL reduces to reweighting trajectories already present in the support; no divergence term, new sampling procedure, or proof of increased effective support is provided to counter the skeptic's concern that the method inherits the same exploration limit.
- [§5] §5 (Experiments): The reported Pass@k improvements are presented without statistical significance tests, variance across random seeds, or ablations that isolate the IRL component from the choice of interleaving frequency and weighting. Without these controls it is impossible to determine whether gains arise from the claimed distribution reshaping or from incidental effects of the interleaving schedule.
minor comments (2)
- [§2] The preliminary analysis of the squeezing effect (likely §2) would benefit from an explicit definition of the trajectory distribution and a quantitative measure (e.g., entropy or support size) before and after RL steps.
- [§3] Notation for the IRL objective and the combined RL+IRL update rule should be unified with the RL objective to avoid ambiguity in how the two steps interact.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below, offering clarifications on the SPS mechanism and committing to specific revisions that strengthen the empirical support without altering the core claims.
read point-by-point responses
-
Referee: [§3] §3 (SPS algorithm): The central claim that IRL applied to on-policy rollouts 'explicitly reshape[s] the induced trajectory distribution' to enhance exploration lacks a supporting argument or metric showing expansion of support. Because the demonstrations are drawn from the current (already squeezed) policy and the underlying reward is rule-based, standard IRL reduces to reweighting trajectories already present in the support; no divergence term, new sampling procedure, or proof of increased effective support is provided to counter the skeptic's concern that the method inherits the same exploration limit.
Authors: We appreciate the referee's concern regarding the theoretical grounding of the reshaping effect. While the demonstrations come from the current policy, the IRL step derives a reward model from these trajectories that is then used to guide the subsequent RL phase; this alternation prevents rapid collapse by periodically re-emphasizing a broader set of demonstrated behaviors under the rule-based reward. The observed Pass@k gains across benchmarks provide indirect evidence of expanded effective support, as higher multi-sample performance requires successful trajectories beyond the narrow mode favored by pure RL. That said, we agree a direct metric (such as trajectory entropy or the count of distinct high-reward paths) would make the support-expansion claim more explicit. We will add this analysis and a clarifying paragraph on the interleaving dynamics in the revision. revision: partial
-
Referee: [§5] §5 (Experiments): The reported Pass@k improvements are presented without statistical significance tests, variance across random seeds, or ablations that isolate the IRL component from the choice of interleaving frequency and weighting. Without these controls it is impossible to determine whether gains arise from the claimed distribution reshaping or from incidental effects of the interleaving schedule.
Authors: We acknowledge that the current experimental section would benefit from greater statistical rigor and targeted controls. In the revised manuscript we will report means and standard deviations over multiple random seeds, include paired statistical significance tests (e.g., t-tests) on the Pass@k deltas, and add ablations that vary interleaving frequency and the RL/IRL weighting hyperparameter while holding other factors fixed. These additions will allow readers to isolate the contribution of the IRL reshaping step from the interleaving schedule itself. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper identifies an empirical squeezing effect via preliminary analysis of RL dynamics, then proposes SPS as an interleaving of standard RL with IRL that treats on-policy rollouts as demonstrations to reshape trajectory distributions. This is presented as a new training paradigm and validated through experiments on five external reasoning benchmarks measuring Pass@k improvements. No load-bearing mathematical derivation, uniqueness theorem, or ansatz is shown to reduce by construction to the inputs; the central claim rests on algorithmic description plus independent empirical outcomes rather than self-definition, fitted inputs renamed as predictions, or self-citation chains. The method is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- interleaving frequency and weighting between RL and IRL steps
axioms (1)
- domain assumption On-policy rollouts constitute valid demonstrations for IRL that can reshape the trajectory distribution without external supervision
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Mislav Balunović, Jasper Dekoninck, Ivo Petrov, Nikola Jovanović, and Martin Vechev. 2025. Matharena: Evaluating llms on uncontaminated math competitions
2025
-
[4]
BRUMO. 2025. Brown university math olympiad 2025 ( BrUMO )
2025
- [5]
-
[6]
Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Hao-Si Li, Yuchen Fan, Huayu Chen, Weize Chen, Zhiyuan Liu, Hao Peng, Lei Bai, Wanli Ouyang, Yu Cheng, Bowen Zhou, and Ning Ding. 2025. The entropy mechanism of reinforcement learning for reasoning language models. ArXiv preprint, abs/2505.22617
work page internal anchor Pith review arXiv 2025
-
[7]
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Jun-Mei Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiaoling Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, and 179 others. 2025. https://api.semanticscholar.org/CorpusID:275789950 Deepseek-r1 incentivizes reasoning in llms through rein...
2025
- [8]
-
[9]
Hugging Face. 2025. Open r1: A fully open reproduction of deepseek-r1
2025
- [10]
-
[11]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Xiaodong Song, and Jacob Steinhardt. 2020. https://api.semanticscholar.org/CorpusID:221516475 Measuring massive multitask language understanding . ArXiv, abs/2009.03300
work page internal anchor Pith review arXiv 2020
-
[12]
HMMT. 2025. Harvard-mit mathematics tournaments ( HMMT )
2025
-
[13]
Yifu Huo, Chenglong Wang, Qiren Zhu, Shunjie Xing, Tong Xiao, Chunliang Zhang, Tongran Liu, and Jingbo Zhu. 2025. Heal: A hypothesis-based preference-aware analysis framework. In Findings of the Association for Computational Linguistics: EMNLP 2025, pages 8901--8919
2025
- [14]
-
[15]
Xue Jiang, Yihong Dong, Mengyang Liu, Hongyi Deng, Tian Wang, Yongding Tao, Rongyu Cao, Binhua Li, Zhi Jin, Wenpin Jiao, Fei Huang, Yongbin Li, and Ge Li. 2025. Coderl+: Improving code generation via reinforcement with execution semantics alignment. ArXiv preprint, abs/2510.18471
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Gonzalez, Haotong Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Haotong Zhang, and Ion Stoica. 2023. Efficient memory management for large language model serving with pagedattention. Proceedings of the 29th Symposium on Operating Systems Principles
2023
- [17]
-
[18]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. 2024. Let's verify step by step. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024 . OpenReview.net
2024
- [19]
-
[20]
Liu, and Jialu Liu
Tianqi Liu, Yao Zhao, Rishabh Joshi, Misha Khalman, Mohammad Saleh, Peter J. Liu, and Jialu Liu. 2024. Statistical rejection sampling improves preference optimization. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024 . OpenReview.net
2024
- [21]
-
[22]
MAA. 2025. American invitational mathematics examination ( AIME ). Mathematics Competition Series
2025
-
[23]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, and Ryan Lowe. 2022. Training language models to follow instructions with hum...
2022
-
[24]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. 2023. https://api.semanticscholar.org/CorpusID:265295009 Gpqa: A graduate-level google-proof q&a benchmark . ArXiv, abs/2311.12022
work page internal anchor Pith review arXiv 2023
-
[25]
Learning dynamics of llm finetuning.arXiv preprint arXiv:2407.10490,
Yi Ren and Danica J. Sutherland. 2024. Learning dynamics of llm finetuning. ArXiv preprint, abs/2407.10490
-
[26]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Proximal policy optimization algorithms. ArXiv preprint, abs/1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Jun-Mei Song, Mingchuan Zhang, Y. K. Li, Yu Wu, and Daya Guo. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. ArXiv preprint, abs/2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Ziegler, Ryan Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul Christiano
Nisan Stiennon, Long Ouyang, Jeff Wu, Daniel M. Ziegler, Ryan J. Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul Christiano. 2020. Learning to summarize from human feedback. ArXiv preprint, abs/2009.01325
- [29]
-
[30]
Hao Sun, Thomas Pouplin, Nicol \'a s Astorga, Tennison Liu, and Mihaela van der Schaar. 2024. Improving llm generation with inverse and forward alignment: Reward modeling, prompting, fine-tuning, and inference-time optimization. In The First Workshop on System-2 Reasoning at Scale, NeurIPS'24
2024
- [31]
-
[32]
Xinyu Tang, Yuliang Zhan, Zhixun Li, Wayne Xin Zhao, Zhenduo Zhang, Zujie Wen, Zhiqiang Zhang, and Jun Zhou. 2025. Rethinking sample polarity in reinforcement learning with verifiable rewards
2025
-
[33]
ModelScope Team. 2024. EvalScope : Evaluation framework for large models
2024
- [34]
-
[35]
Chenglong Wang, Yang Gan, Yifu Huo, Yongyu Mu, Murun Yang, Qiaozhi He, Tong Xiao, Chunliang Zhang, Tongran Liu, and Jingbo Zhu. 2025 b . Rovrm: A robust visual reward model optimized via auxiliary textual preference data. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 25336--25344
2025
- [36]
-
[37]
Chenglong Wang, Hang Zhou, Kaiyan Chang, Bei Li, Yongyu Mu, Tong Xiao, Tongran Liu, and JingBo Zhu. 2024 a . Hybrid alignment training for large language models. In Findings of the Association for Computational Linguistics: ACL 2024, pages 11389--11403, Bangkok, Thailand. Association for Computational Linguistics
2024
-
[38]
Chenglong Wang, Hang Zhou, Yimin Hu, Yifu Huo, Bei Li, Tongran Liu, Tong Xiao, and Jingbo Zhu. 2024 b . ESRL: efficient sampling-based reinforcement learning for sequence generation. In Thirty-Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence, IAAI 2024, Fourteenth S...
2024
-
[39]
Guojian Wang, Faguo Wu, Xiao Zhang, and Jianxiang Liu. 2023. Learning diverse policies with soft self-generated guidance. International Journal of Intelligent Systems, 2023(1):4705291
2023
-
[40]
Yihong Wu, Liheng Ma, Lei Ding, Muzhi Li, Xinyu Wang, Kejia Chen, Zhan Su, Zhanguang Zhang, Chenyang Huang, Yingxue Zhang, Mark Coates, and Jian-Yun Nie. 2025. It takes two: Your grpo is secretly dpo. ArXiv preprint, abs/2510.00977
work page internal anchor Pith review arXiv 2025
- [41]
- [42]
-
[43]
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, Keming Lu, Mingfeng Xue, Runji Lin, Tianyu Liu, Xingzhang Ren, and Zhenru Zhang. 2024. Qwen2.5-math technical report: Toward mathematical expert model via self-improvement. ArXiv preprint, abs/2409.12122
work page internal anchor Pith review arXiv 2024
-
[44]
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, and 16 others. 2025. Dapo: An open-source llm reinforcement learning system at scale. ArXiv preprint, abs/2503.14476
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Shiji Song, and Gao Huang. 2025. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model? ArXiv preprint, abs/2504.13837
work page Pith review arXiv 2025
-
[46]
Linfeng Zhang, Chenglong Bao, and Kaisheng Ma. 2021. Self-distillation: Towards efficient and compact neural networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(8):4388--4403
2021
-
[47]
Yifan Zhang and Team Math-AI. 2024. American invitational mathematics examination (aime) 2024
2024
-
[48]
Yifan Zhang and Team Math-AI. 2025. American invitational mathematics examination (aime) 2025
2025
-
[49]
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, Jingren Zhou, and Junyang Lin. 2025. Group sequence policy optimization. ArXiv preprint, abs/2507.18071
work page internal anchor Pith review arXiv 2025
-
[50]
Hang Zhou, Chenglong Wang, Yimin Hu, Tong Xiao, Chunliang Zhang, and Jingbo Zhu. 2024. Prior constraints-based reward model training for aligning large language models. In Proceedings of the 23rd Chinese National Conference on Computational Linguistics (Volume 1: Main Conference), pages 1395--1407
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.