Recognition: unknown
Abstain-R1: Calibrated Abstention and Post-Refusal Clarification via Verifiable RL
Pith reviewed 2026-05-10 07:03 UTC · model grok-4.3
The pith
A 3B model learns calibrated abstention from unanswerable queries and post-refusal clarification of missing information through verifiable rewards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
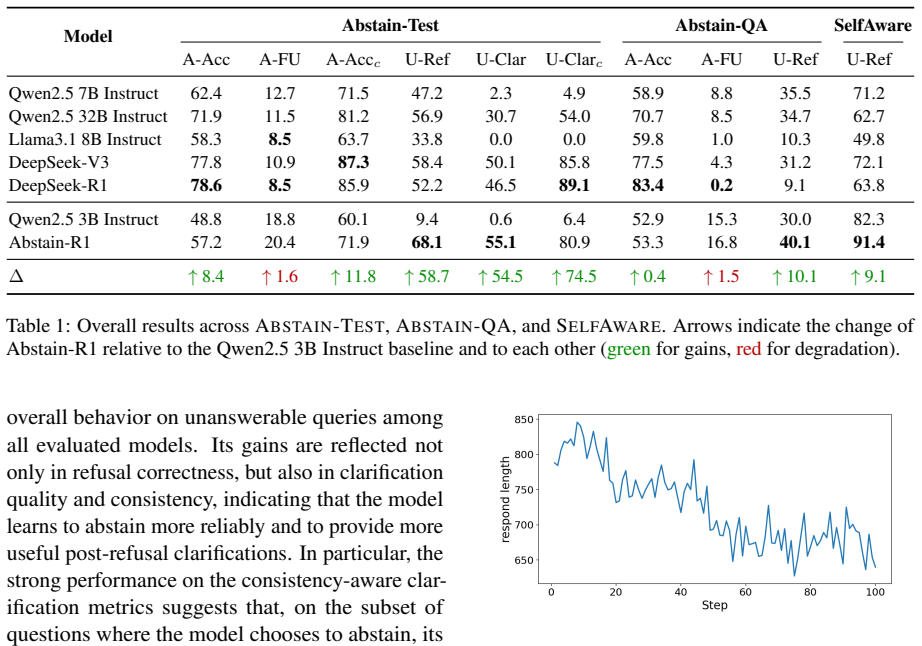
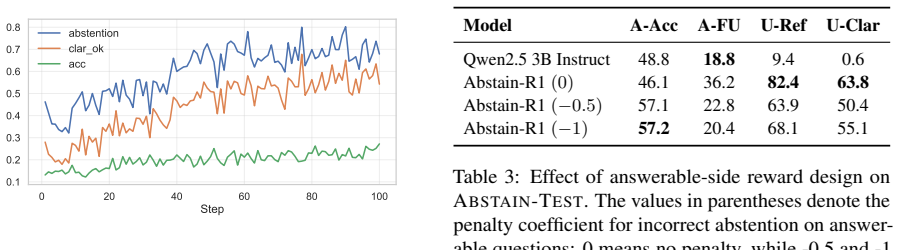
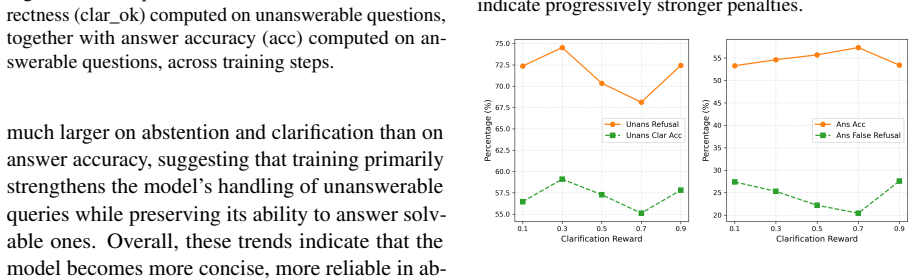
We propose a clarification-aware RLVR reward that, while rewarding correct answers on answerable queries, jointly optimizes explicit abstention and semantically aligned post-refusal clarification on unanswerable queries. Using this reward, we train Abstain-R1, a 3B model that improves abstention and clarification on unanswerable queries while preserving strong performance on answerable ones.
What carries the argument
The clarification-aware RLVR reward, which scores abstention plus post-refusal clarifications for whether they correctly identify the key missing information.
If this is right
- Models can refuse to answer when information is insufficient instead of guessing.
- Post-refusal clarifications become specific about gaps rather than generic.
- Small models reach abstention performance levels comparable to larger systems.
- Accuracy on answerable queries stays intact while abstention improves.
- Reliable uncertainty handling can be instilled through reward design.
Where Pith is reading between the lines
- This reward approach might lower hallucination rates in open-ended user interactions.
- Similar verification rewards could be designed for other reliability problems such as factual consistency.
- The method might transfer to specialized domains like medical or legal queries where admitting uncertainty matters.
- Combining the reward with chain-of-thought verification could further strengthen calibration.
Load-bearing premise
The reward can automatically verify that a clarification identifies the key missing information without introducing bias or needing human judgment.
What would settle it
A held-out collection of unanswerable queries where Abstain-R1's clarifications routinely fail to name the critical missing fact or where reward verification disagrees with human assessment of the clarifications.
Figures











read the original abstract
Reinforcement fine-tuning improves the reasoning ability of large language models, but it can also encourage them to answer unanswerable queries by guessing or hallucinating missing information. Existing abstention methods either train models to produce generic refusals or encourage follow-up clarifications without verifying whether those clarifications identify the key missing information. We study queries that are clear in meaning but cannot be reliably resolved from the given information, and argue that a reliable model should not only abstain, but also explain what is missing. We propose a clarification-aware RLVR reward that, while rewarding correct answers on answerable queries, jointly optimizes explicit abstention and semantically aligned post-refusal clarification on unanswerable queries. Using this reward, we train Abstain-R1, a 3B model that improves abstention and clarification on unanswerable queries while preserving strong performance on answerable ones. Experiments on Abstain-Test, Abstain-QA, and SelfAware show that Abstain-R1 substantially improves over its base model and achieves unanswerable-query behavior competitive with larger systems including DeepSeek-R1, suggesting that calibrated abstention and clarification can be learned through verifiable rewards rather than emerging from scale alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Abstain-R1, a 3B model trained via a clarification-aware RLVR reward. The central claim is that this reward jointly optimizes correct answers on answerable queries and explicit abstention plus semantically aligned post-refusal clarification on unanswerable queries, yielding improved abstention and clarification on benchmarks including Abstain-Test, Abstain-QA, and SelfAware while preserving performance on answerable queries and remaining competitive with larger models such as DeepSeek-R1.
Significance. If the reward mechanism is robust, the work shows that calibrated abstention and clarification can be instilled via verifiable reinforcement learning in smaller models rather than emerging solely from scale. The joint optimization of abstention and clarification through rewards, together with the emphasis on verifiable components, is a strength that could support more reliable LLM behavior.
major comments (2)
- [Abstract and reward formulation] Abstract and the reward formulation section: The clarification-aware RLVR reward is said to optimize 'semantically aligned post-refusal clarification' on unanswerable queries, yet no equation, procedure, or external verifier is specified for automatically determining whether a clarification identifies the key missing information. This is load-bearing for the central claim, because an unspecified mechanism (e.g., LLM judge, embedding similarity, or heuristic) risks circularity or systematic bias, which would undermine whether the reported gains on unanswerable queries reflect genuine calibration rather than reward hacking.
- [Experiments] Experiments section: The abstract reports substantial improvements and competitiveness with larger models, but the manuscript provides insufficient detail on exact baselines, statistical tests, number of evaluation runs, or the precise automatic metric used to score clarification quality. Without these, the quantitative support for the joint optimization claim cannot be fully assessed.
minor comments (1)
- [Abstract] The abstract could more explicitly contrast the proposed reward against prior abstention methods that use generic refusals or unverified clarifications.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the significance of our work and for the constructive major comments. We address each point below and have made revisions to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract and reward formulation] Abstract and the reward formulation section: The clarification-aware RLVR reward is said to optimize 'semantically aligned post-refusal clarification' on unanswerable queries, yet no equation, procedure, or external verifier is specified for automatically determining whether a clarification identifies the key missing information. This is load-bearing for the central claim, because an unspecified mechanism (e.g., LLM judge, embedding similarity, or heuristic) risks circularity or systematic bias, which would undermine whether the reported gains on unanswerable queries reflect genuine calibration rather than reward hacking.
Authors: We thank the referee for this observation. The reward formulation in the manuscript describes the high-level structure but indeed omits the precise implementation details for determining semantic alignment to keep the main text concise. We will revise to include the full specification, including the equation for the clarification reward and the use of an independent embedding-based verifier to ensure no circularity. This addition will strengthen the central claim by making the method fully reproducible and verifiable. revision: yes
-
Referee: [Experiments] Experiments section: The abstract reports substantial improvements and competitiveness with larger models, but the manuscript provides insufficient detail on exact baselines, statistical tests, number of evaluation runs, or the precise automatic metric used to score clarification quality. Without these, the quantitative support for the joint optimization claim cannot be fully assessed.
Authors: We acknowledge the need for greater experimental rigor in reporting. In the revised version, we will expand the Experiments section to include a complete list of baselines with their exact model sizes and training details, results averaged over multiple independent evaluation runs with mean and standard deviation, statistical significance tests, and the precise automatic metric for clarification quality. These details will allow full assessment of the joint optimization claim. revision: yes
Circularity Check
No significant circularity; reward defined externally and results measured on held-out data.
full rationale
The paper defines a clarification-aware RLVR reward as an independent training objective that rewards correct answers on answerable queries plus explicit abstention and semantically aligned clarification on unanswerable ones. It then applies this reward to train Abstain-R1 and evaluates the resulting model on separate benchmarks (Abstain-Test, Abstain-QA, SelfAware). No equation, procedure, or self-citation reduces the reported gains to a fitted parameter, renamed input, or load-bearing prior result by the authors themselves. The verification of semantic alignment is presented as part of the proposed verifiable reward rather than derived from the model's outputs or evaluation metrics. This is standard RL fine-tuning with an externally specified reward and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Language Models are Few-Shot Learners
Language models are few-shot learners.arXiv preprint arXiv:2005.14165. Ding Chen, Qingchen Yu, Pengyuan Wang, Wentao Zhang, Bo Tang, Feiyu Xiong, Xinchi Li, Minchuan Yang, and Zhiyu Li. 2025. xverify: Efficient an- swer verifier for reasoning model evaluations.arXiv preprint arXiv:2504.10481. Qinyuan Cheng, Tianxiang Sun, Xiangyang Liu, Wen- wei Zhang, Zh...
work page internal anchor Pith review arXiv 2005
-
[2]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language under- standing.arXiv preprint arXiv:2009.03300. Shengding Hu, Yifan Luo, Huadong Wang, Xingyi Cheng, Zhiyuan Liu, and Maosong Sun. 2023. Won’t get fooled again: Answering questions with false premises.arXiv preprint arXiv:2307.02394. Hugging Face. 2025. Math-verify: A robust mathemati- cal expression evaluation librar...
work page internal anchor Pith review arXiv 2009
-
[3]
Proximal Policy Optimization Algorithms
Evaluating the moral beliefs encoded in llms. Advances in Neural Information Processing Systems, 36:51778–51809. John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Proxi- mal policy optimization algorithms.arXiv preprint arXiv:1707.06347. Taiwei Shi, Sihao Chen, Bowen Jiang, Linxin Song, Longqi Yang, and Jieyu Zhao. 2026....
work page internal anchor Pith review Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.