Recognition: unknown
HORIZON: A Benchmark for In-the-wild User Behaviour Modeling
Pith reviewed 2026-05-10 06:16 UTC · model grok-4.3
The pith
HORIZON benchmark requires user models to generalize across domains, users, and long time periods instead of single-domain next-item prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HORIZON reformulates user modeling along three axes of dataset, task, and evaluation by creating a cross-domain, long-horizon version of Amazon Reviews data. It requires models to handle generalization across domains, across different users, and across time, with new setups for temporal shifts, sequence-length variation, and unseen users, plus metrics that test broad behavior understanding rather than isolated next-item accuracy. Experiments with popular sequential recommenders and LLM baselines that incorporate full histories reveal that current methods fall short of these real-world requirements.
What carries the argument
The HORIZON benchmark, built on a reformulated cross-domain long-term interaction dataset from Amazon Reviews, which supports pretraining and evaluation under heterogeneous conditions.
If this is right
- Sequential recommendation models must incorporate mechanisms for cross-domain transfer and retention of long interaction histories.
- Evaluation protocols should shift from single-domain next-item accuracy toward metrics that assess generalization to new users and time periods.
- LLM-based user models can be directly tested for robustness when histories span multiple domains and extended durations.
- Research priorities move toward building temporally stable and domain-agnostic user representations for deployment.
Where Pith is reading between the lines
- Widespread adoption of HORIZON could redirect benchmark design in recommendation systems away from isolated session prediction toward lifelong user modeling.
- The benchmark setup naturally connects to problems in continual learning, where models must adapt as new domains and users appear over time.
- One testable extension is whether pretraining on the full HORIZON corpus transfers to improved performance in live e-commerce systems with mixed product categories.
Load-bearing premise
The reformulated Amazon Reviews dataset with its cross-domain and long-term interactions accurately represents diverse real-world user behaviors without major selection or reporting biases from the original platform data.
What would settle it
A deployment study where models that score highest on HORIZON tasks show no measurable improvement in actual multi-domain user retention or satisfaction over time, or where models that underperform on HORIZON still succeed in live heterogeneous environments.
Figures




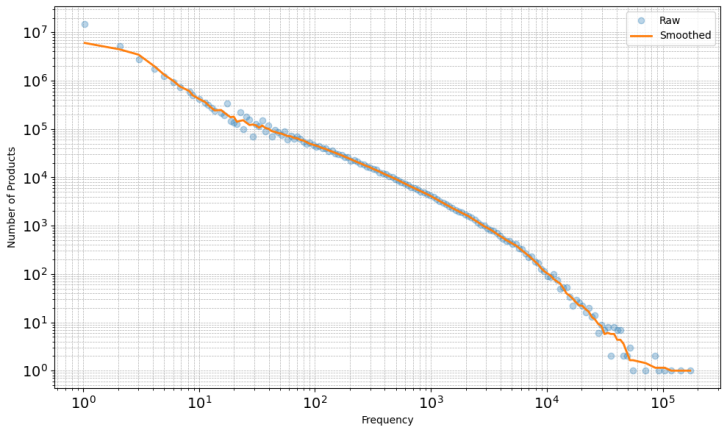
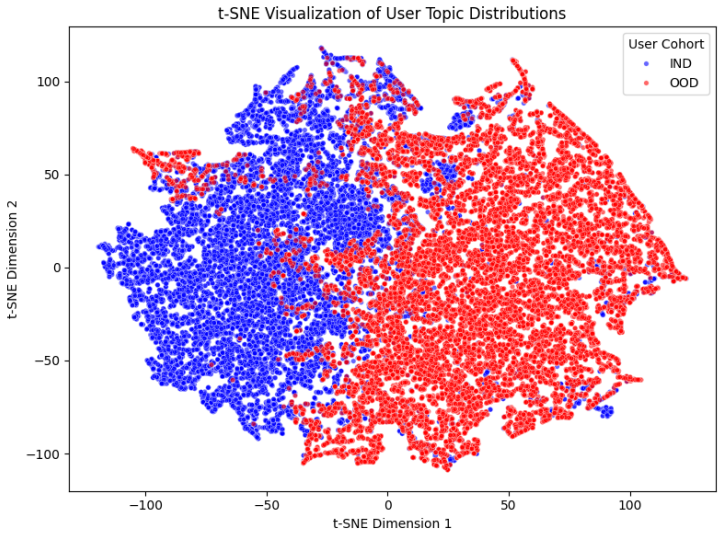
read the original abstract
User behavior in the real world is diverse, cross-domain, and spans long time horizons. Existing user modeling benchmarks however remain narrow, focusing mainly on short sessions and next-item prediction within a single domain. Such limitations hinder progress toward robust and generalizable user models. We present HORIZON, a new benchmark that reformulates user modeling along three axes i.e. dataset, task, and evaluation. Built from a large-scale, cross-domain reformulation of Amazon Reviews, HORIZON covers 54M users and 35M items, enabling both pretraining and realistic evaluation of models in heterogeneous environments. Unlike prior benchmarks, it challenges models to generalize across domains, users, and time, moving beyond standard missing-positive prediction in the same domain. We propose new tasks and evaluation setups that better reflect real-world deployment scenarios. These include temporal generalization, sequence-length variation, and modeling unseen users, with metrics designed to assess general user behavior understanding rather than isolated next-item prediction. We benchmark popular sequential recommendation architectures alongside LLM-based baselines that leverage long-term interaction histories. Our results highlight the gap between current methods and the demands of real-world user modeling, while establishing HORIZON as a foundation for research on temporally robust, cross-domain, and general-purpose user models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces HORIZON, a benchmark for in-the-wild user behavior modeling constructed via large-scale cross-domain reformulation of the Amazon Reviews dataset (54M users, 35M items). It redefines user modeling along dataset, task, and evaluation axes, proposing tasks for temporal generalization, sequence-length variation, and unseen-user modeling that extend beyond single-domain next-item prediction. The paper benchmarks sequential recommendation architectures and LLM-based models on long-term histories, reporting performance gaps that illustrate limitations of existing methods for real-world deployment.
Significance. If the reformulated dataset and tasks validly capture diverse, cross-domain, long-horizon behaviors, HORIZON could provide a valuable new foundation for research on generalizable user models, shifting the field from narrow session-based prediction toward more realistic evaluation. The scale and explicit focus on generalization across domains/users/time are clear strengths, as is the inclusion of both traditional and LLM baselines.
major comments (2)
- [§3] §3 (Dataset Construction): The claim that the reformulated Amazon Reviews data enables realistic evaluation of generalization across domains, users, and time is load-bearing for the entire contribution, yet the manuscript provides no quantitative analysis or mitigation of platform-specific selection biases (e.g., reviewer self-selection, sparse self-reported interactions, or incomplete temporal coverage). This directly affects whether observed gaps reflect real-world demands or benchmark artifacts.
- [§5] §5 (Experiments and Results): The reported performance gaps between baselines and the new tasks lack error bars, statistical significance tests, or explicit details on data splits, preprocessing, and hyperparameter choices. Without these, it is difficult to assess whether the highlighted limitations of current methods are robust or sensitive to implementation decisions.
minor comments (2)
- [Abstract] The abstract states that new metrics assess 'general user behavior understanding rather than isolated next-item prediction,' but the specific metric definitions and how they differ from standard ranking metrics are not summarized early in the paper.
- [Figures/Tables] Figure captions and table headers could more explicitly link results to the three proposed axes (dataset/task/evaluation) to improve readability.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and recognition of HORIZON's potential to advance research on generalizable user models. We address each major comment below and commit to revisions that strengthen the manuscript's rigor and transparency.
read point-by-point responses
-
Referee: [§3] §3 (Dataset Construction): The claim that the reformulated Amazon Reviews data enables realistic evaluation of generalization across domains, users, and time is load-bearing for the entire contribution, yet the manuscript provides no quantitative analysis or mitigation of platform-specific selection biases (e.g., reviewer self-selection, sparse self-reported interactions, or incomplete temporal coverage). This directly affects whether observed gaps reflect real-world demands or benchmark artifacts.
Authors: We acknowledge that Amazon Reviews, as a self-reported dataset, inherently carries selection biases such as reviewer self-selection and variable temporal coverage. Our reformulation prioritizes cross-domain and long-horizon structures to better approximate real-world user behavior than single-domain next-item benchmarks, but we agree that explicit quantification of these biases is needed to support the generalization claims. In the revised manuscript, we will add quantitative analyses of user activity distributions, domain-specific temporal coverage, and interaction sparsity, along with a dedicated discussion of potential artifacts and their implications for the observed performance gaps. revision: yes
-
Referee: [§5] §5 (Experiments and Results): The reported performance gaps between baselines and the new tasks lack error bars, statistical significance tests, or explicit details on data splits, preprocessing, and hyperparameter choices. Without these, it is difficult to assess whether the highlighted limitations of current methods are robust or sensitive to implementation decisions.
Authors: We agree that greater statistical rigor and experimental transparency are essential for validating the reported gaps. The revised manuscript will include error bars (standard deviations across multiple runs), statistical significance tests for key performance differences, and comprehensive details on data splits, preprocessing pipelines, and hyperparameter selection in the main text and an expanded appendix to ensure reproducibility and robustness assessment. revision: yes
Circularity Check
No circularity: benchmark reformulation and task definition are constructive, not self-referential
full rationale
The paper creates HORIZON by reformulating Amazon Reviews into a cross-domain, long-term user interaction dataset and defines new generalization tasks (temporal, cross-user, cross-domain). No derivations, equations, or fitted parameters are presented as 'predictions' that reduce to the inputs by construction. Baselines are run on the new splits without any self-citation chain or ansatz that bears the central claim. The reported performance gap is an empirical observation on the released benchmark, not a logical tautology. This matches the expected honest non-finding for a dataset/task paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Amazon product reviews can serve as a proxy for diverse, cross-domain, long-horizon user behavior.
Reference graph
Works this paper leans on
-
[1]
Bridging Language and Items for Retrieval and Recommendation: Benchmarking LLMs as Semantic Encoders
Bridging language and items for retrieval and recommendation , author=. arXiv preprint arXiv:2403.03952 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
MIND : A Large-scale Dataset for News Recommendation
Wu, Fangzhao and Qiao, Ying and Chen, Jiun-Hung and Wu, Chuhan and Qi, Tao and Lian, Jianxun and Liu, Danyang and Xie, Xing and Gao, Jianfeng and Wu, Winnie and Zhou, Ming. MIND : A Large-scale Dataset for News Recommendation. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.331
-
[3]
Anand, Avinash and Goel, Arnav and Hira, Medha and Buldeo, Snehal and Kumar, Jatin and Verma, Astha and Gupta, Rushali and Shah, Rajiv Ratn , title =. Big Data and Artificial Intelligence: 11th International Conference, BDA 2023, Delhi, India, December 7–9, 2023, Proceedings , pages =. 2023 , isbn =. doi:10.1007/978-3-031-49601-1_4 , abstract =
-
[4]
Kapuriya, Janak and Shaikh, Anwar and Goel, Arnav and Hira, Medha and Singh, Apoorv and Saraf, Jay and Sanjana and Nauriyal, Vaibhav and Anand, Avinash and Wang, Zhengkui and Shah, Rajiv Ratn , title =. Proceedings of the 2nd International Workshop on Large Vision - Language Model Learning and Applications , pages =. 2025 , isbn =. doi:10.1145/3728483.376...
-
[5]
2025 , eprint=
Attributing Culture-Conditioned Generations to Pretraining Corpora , author=. 2025 , eprint=
2025
-
[6]
2023 , eprint=
Advancements in Scientific Controllable Text Generation Methods , author=. 2023 , eprint=
2023
-
[7]
Cho, Eunjoon and Myers, Seth A. and Leskovec, Jure , title =. Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , pages =. 2011 , isbn =. doi:10.1145/2020408.2020579 , abstract =
-
[8]
Proceedings of the 14th ACM Conference on Recommender Systems , pages =
Meng, Zaiqiao and McCreadie, Richard and Macdonald, Craig and Ounis, Iadh , title =. Proceedings of the 14th ACM Conference on Recommender Systems , pages =. 2020 , isbn =. doi:10.1145/3383313.3418479 , abstract =
-
[9]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
2024 , eprint=
Gemma 2: Improving Open Language Models at a Practical Size , author=. 2024 , eprint=
2024
-
[11]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[12]
Sobkowicz, Antoni and Stokowiec, Wojciech , year =
-
[13]
The faiss library , author=. arXiv preprint arXiv:2401.08281 , year=
work page internal anchor Pith review arXiv
-
[14]
Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =
Jin, Wei and Mao, Haitao and Li, Zheng and Jiang, Haoming and Luo, Chen and Wen, Hongzhi and Han, Haoyu and Lu, Hanqing and Wang, Zhengyang and Li, Ruirui and Li, Zhen and Cheng, Monica and Goutam, Rahul and Zhang, Haiyang and Subbian, Karthik and Wang, Suhang and Sun, Yizhou and Tang, Jiliang and Yin, Bing and Tang, Xianfeng , title =. Proceedings of the...
2023
-
[15]
Harper, F. Maxwell and Konstan, Joseph A. , title =. 2015 , issue_date =. doi:10.1145/2827872 , journal =
-
[16]
Proceedings of the 14th acm conference on recommender systems , pages=
Exploring data splitting strategies for the evaluation of recommendation models , author=. Proceedings of the 14th acm conference on recommender systems , pages=
-
[17]
Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
Take a fresh look at recommender systems from an evaluation standpoint , author=. Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[18]
ACM Transactions on Information Systems , volume=
A critical study on data leakage in recommender system offline evaluation , author=. ACM Transactions on Information Systems , volume=. 2023 , publisher=
2023
-
[19]
Advances in Neural Information Processing Systems , volume=
On the generalizability and predictability of recommender systems , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
Mind: A large-scale dataset for news recommendation , author=. Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
-
[21]
COSPLAY: Concept Set Guided Personalized Dialogue Generation Across Both Party Personas , url=
Hou, Yupeng and Hu, Binbin and Zhang, Zhiqiang and Zhao, Wayne Xin , title =. Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =. 2022 , isbn =. doi:10.1145/3477495.3531955 , abstract =
-
[22]
2016 , eprint=
Session-based Recommendations with Recurrent Neural Networks , author=. 2016 , eprint=
2016
-
[23]
Self-Attentive Sequential Recommendation , year=
Kang, Wang-Cheng and McAuley, Julian , booktitle=. Self-Attentive Sequential Recommendation , year=
-
[24]
Advances in Neural Information Processing Systems , volume=
Amazon-m2: A multilingual multi-locale shopping session dataset for recommendation and text generation , author=. Advances in Neural Information Processing Systems , volume=
-
[25]
Sun, Fei and Liu, Jun and Wu, Jian and Pei, Changhua and Lin, Xiao and Ou, Wenwu and Jiang, Peng , title =. Proceedings of the 28th ACM International Conference on Information and Knowledge Management , pages =. 2019 , isbn =. doi:10.1145/3357384.3357895 , abstract =
-
[26]
Pancha, Nikil and Zhai, Andrew and Leskovec, Jure and Rosenberg, Charles , title =. Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages =. 2022 , isbn =. doi:10.1145/3534678.3539156 , abstract =
-
[27]
A Reproducible Analysis of Sequential Recommender Systems , year=
Betello, Filippo and Purificato, Antonio and Siciliano, Federico and Trappolini, Giovanni and Bacciu, Andrea and Tonellotto, Nicola and Silvestri, Fabrizio , journal=. A Reproducible Analysis of Sequential Recommender Systems , year=
-
[28]
Acm transactions on interactive intelligent systems (tiis) , volume=
The movielens datasets: History and context , author=. Acm transactions on interactive intelligent systems (tiis) , volume=. 2015 , publisher=
2015
-
[29]
ACM Computing Surveys (CSUR) , volume=
A survey on session-based recommender systems , author=. ACM Computing Surveys (CSUR) , volume=. 2021 , publisher=
2021
-
[30]
Justifying recommendations using distantly-labeled reviews and fine-grained aspects , author=. Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) , pages=
2019
-
[31]
arXiv preprint arXiv:2403.13344 , year=
USE: Dynamic User Modeling with Stateful Sequence Models , author=. arXiv preprint arXiv:2403.13344 , year=
-
[32]
arXiv preprint arXiv:2503.14772 , year=
VIKI: Systematic Cross-Platform Profile Inference of Online Users , author=. arXiv preprint arXiv:2503.14772 , year=
-
[33]
Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
Towards universal sequence representation learning for recommender systems , author=. Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
-
[34]
Proceedings of the 42nd International ACM SIGIR conference on research and development in information retrieval , pages=
Cross: Cross-platform recommendation for social e-commerce , author=. Proceedings of the 42nd International ACM SIGIR conference on research and development in information retrieval , pages=
-
[35]
arXiv preprint arXiv:2103.01696 , year=
Cross-domain recommendation: challenges, progress, and prospects , author=. arXiv preprint arXiv:2103.01696 , year=
-
[36]
Matrix Factorization Techniques for Recommender Systems , year=
Koren, Yehuda and Bell, Robert and Volinsky, Chris , journal=. Matrix Factorization Techniques for Recommender Systems , year=
-
[37]
RecBole: Towards a Unified, Comprehensive and Efficient Framework for Recommendation Algorithms , booktitle=
Wayne Xin Zhao and Shanlei Mu and Yupeng Hou and Zihan Lin and Yushuo Chen and Xingyu Pan and Kaiyuan Li and Yujie Lu and Hui Wang and Changxin Tian and Yingqian Min and Zhichao Feng and Xinyan Fan and Xu Chen and Pengfei Wang and Wendi Ji and Yaliang Li and Xiaoling Wang and Ji. RecBole: Towards a Unified, Comprehensive and Efficient Framework for Recomm...
-
[38]
RecBole 2.0: Towards a More Up-to-Date Recommendation Library , journal=
Wayne Xin Zhao and Yupeng Hou and Xingyu Pan and Chen Yang and Zeyu Zhang and Zihan Lin and Jingsen Zhang and Shuqing Bian and Jiakai Tang and Wenqi Sun and Yushuo Chen and Lanling Xu and Gaowei Zhang and Zhen Tian and Changxin Tian and Shanlei Mu and Xinyan Fan and Xu Chen and Ji. RecBole 2.0: Towards a More Up-to-Date Recommendation Library , journal=
-
[39]
content-based filtering: differences and similarities , author=
Collaborative filtering vs. content-based filtering: differences and similarities , author=. arXiv preprint arXiv:1912.08932 , year=
-
[40]
matrix factorization revisited , author=
Neural collaborative filtering vs. matrix factorization revisited , author=. Proceedings of the 14th ACM Conference on Recommender Systems , pages=
-
[41]
Llamarec: Two-stage recommendation using large language models for ranking, 2023
Llamarec: Two-stage recommendation using large language models for ranking , author=. arXiv preprint arXiv:2311.02089 , year=
-
[42]
Proceedings of the ACM Web Conference 2024 , pages=
Can small language models be good reasoners for sequential recommendation? , author=. Proceedings of the ACM Web Conference 2024 , pages=
2024
-
[43]
Proceedings of the 18th ACM Conference on Recommender Systems , pages =
Klenitskiy, Anton and Volodkevich, Anna and Pembek, Anton and Vasilev, Alexey , title =. Proceedings of the 18th ACM Conference on Recommender Systems , pages =. 2024 , isbn =. doi:10.1145/3640457.3688195 , abstract =
-
[44]
Edward J Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , booktitle=. Lo. 2022 , url=
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.