Recognition: unknown
Cat-DPO: Category-Adaptive Safety Alignment
Pith reviewed 2026-05-10 05:30 UTC · model grok-4.3
The pith
Cat-DPO replaces a single safety margin with separate adaptive margins for each harm category in direct preference optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
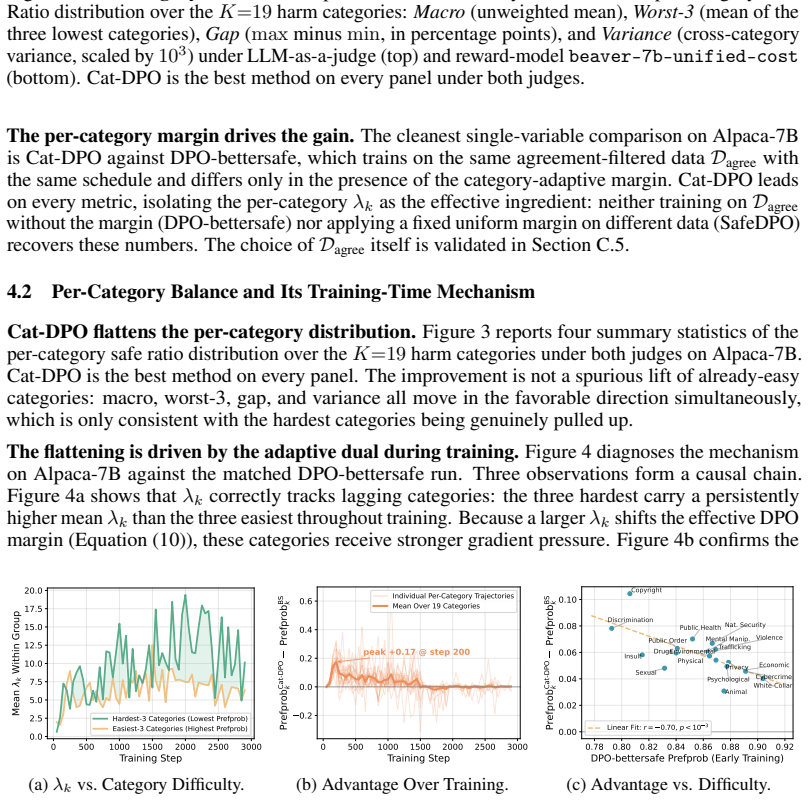
Cat-DPO casts safety alignment as a per-category constrained optimization problem and supplies a direct-preference-optimization algorithm that keeps a distinct adaptive safety margin for every harm category. The margin is tightened while the model still produces unsafe responses in that category and is relaxed once performance catches up, so the gradient tracks each category's present difficulty instead of a global average. Experiments show the resulting models improve aggregate helpfulness and harmlessness while compressing per-category safety variance and narrowing the best-to-worst gap.
What carries the argument
The category-specific adaptive safety margin, which is updated during training according to the model's ongoing rate of unsafe outputs in that category and thereby redistributes optimization pressure away from already-safe categories.
If this is right
- Aggregate helpfulness and harmlessness scores increase relative to uniform-margin baselines.
- Per-category safety variance decreases and the gap between the safest and least-safe categories narrows.
- The algorithm functions as a drop-in replacement inside existing direct-preference-optimization code.
- Training effort is automatically concentrated on categories that still generate unsafe responses.
Where Pith is reading between the lines
- The adaptive-margin construction could be applied to other multi-objective alignment tasks that admit natural categories, such as truthfulness across domains.
- If the per-category tracking remains stable, dataset re-balancing may become less critical for safety consistency.
- Exposing the learned per-category margins at inference time would let users adjust safety emphasis by topic without retraining.
Load-bearing premise
An adaptive per-category margin can be maintained throughout training without introducing instability, over-refusal on borderline queries, or the need for extra category-specific hyperparameter search.
What would settle it
A controlled run in which Cat-DPO produces either larger per-category safety gaps than uniform baselines or measurable training instability and over-refusal rates on held-out queries would falsify the central performance claim.
Figures





read the original abstract
Aligning large language models with human preferences must balance two competing goals: responding helpfully to legitimate requests and reliably refusing harmful ones. Most preference-based safety alignment methods collapse safety into a single scalar that is applied uniformly to every preference pair. The result is a model that looks safe on average but stays relatively unsafe on a minority of harm categories. We cast safety alignment as a per-category constrained optimization problem and derive Cat-DPO, a direct-preference-optimization algorithm with a separate adaptive safety margin for each harm category. The margin tightens when the model still produces unsafe responses on a category and relaxes once the model catches up, so the training signal tracks each category's current difficulty rather than averaging under one global rate. Across two LLM backbones and six preference-learning baselines, Cat-DPO improves aggregate helpfulness and harmlessness and compresses per-category safety variance and the best-to-worst gap, offering a drop-in per-category refinement of direct preference safety alignment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Cat-DPO, a direct preference optimization variant that formulates safety alignment as a per-category constrained optimization problem. It introduces separate adaptive safety margins per harm category that tighten when the model produces unsafe responses in that category and relax once performance improves, so the training signal tracks category-specific difficulty rather than a single global rate. The central empirical claim is that, across two LLM backbones and six preference-learning baselines, Cat-DPO improves aggregate helpfulness and harmlessness while compressing per-category safety variance and the best-to-worst gap.
Significance. If the empirical results and stability claims hold, Cat-DPO would provide a lightweight, drop-in refinement to existing DPO-style safety alignment that addresses uneven performance across harm categories without requiring new architectures or loss functions.
major comments (2)
- [Abstract] Abstract: the central claim of improved aggregate metrics and compressed per-category variance is asserted without any quantitative results, error bars, dataset sizes, or description of margin initialization/update rules, making it impossible to evaluate support for the claim or rule out confounds such as category imbalance.
- [Method] Method (margin adaptation): the update dynamics for the per-category margins (step size, unsafe-response detection threshold, relaxation schedule) are not specified, so it is impossible to verify the assumption that adaptation remains stable across categories without oscillation, over-refusal, or per-category hyperparameter search that would negate the claimed simplicity.
minor comments (1)
- [Abstract] The abstract would be clearer if it named the specific harm categories and preference datasets used in the experiments.
Simulated Author's Rebuttal
Thank you for your constructive review of our manuscript on Cat-DPO. We appreciate the feedback on the need for greater quantitative support in the abstract and explicit parameterization in the method section. We address each major comment below and will incorporate revisions to improve clarity and verifiability.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of improved aggregate metrics and compressed per-category variance is asserted without any quantitative results, error bars, dataset sizes, or description of margin initialization/update rules, making it impossible to evaluate support for the claim or rule out confounds such as category imbalance.
Authors: We agree that the abstract would be strengthened by including supporting quantitative details. In the revised manuscript we will add key results such as the observed improvements in aggregate helpfulness and harmlessness, the measured compression of per-category safety variance, and the reduction in the best-to-worst gap, together with error bars from our multi-seed experiments. Dataset sizes and category balance are already reported in the experimental setup; we will also insert a concise reference to margin initialization (zero start) and the per-category update rule, directing readers to the method section for the full formulation. These additions will allow direct evaluation of the claims from the abstract while preserving its brevity. revision: yes
-
Referee: [Method] Method (margin adaptation): the update dynamics for the per-category margins (step size, unsafe-response detection threshold, relaxation schedule) are not specified, so it is impossible to verify the assumption that adaptation remains stable across categories without oscillation, over-refusal, or per-category hyperparameter search that would negate the claimed simplicity.
Authors: The manuscript currently describes the adaptation process at a conceptual level. We acknowledge that explicit values and schedules for step size, the unsafe-response detection threshold, and the relaxation rule are not stated. In the revision we will supply the precise update equations, the fixed step size employed, the threshold used by the safety classifier for flagging unsafe outputs, and the linear relaxation schedule applied when category performance improves. We will also add a short stability analysis and an ablation confirming that a single global hyperparameter set suffices across categories, thereby supporting the claimed simplicity without per-category tuning. revision: yes
Circularity Check
No circularity: algorithmic refinement with independent adaptive rule
full rationale
The paper frames safety alignment as per-category constrained optimization and introduces Cat-DPO by adding an adaptive margin per harm category that tightens or relaxes according to observed unsafe outputs during training. This is presented as a direct algorithmic change to the DPO loss rather than any re-expression of fitted values or self-referential definition. No equations in the provided text reduce the claimed variance compression or aggregate gains to quantities defined by the method itself. The derivation chain remains self-contained against external benchmarks and does not rely on load-bearing self-citations or imported uniqueness theorems for its core claim.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[2]
Ad-llm: Benchmarking large language models for anomaly detection
Tiankai Yang, Yi Nian, Li Li, Ruiyao Xu, Yuangang Li, Jiaqi Li, Zhuo Xiao, Xiyang Hu, Ryan A Rossi, Kaize Ding, et al. Ad-llm: Benchmarking large language models for anomaly detection. InFindings of the Association for Computational Linguistics: ACL 2025, pages 1524–1547, 2025
2025
-
[3]
A personalized conversational benchmark: Towards simulating personalized conversations
Li Li, Peilin Cai, Ryan A Rossi, Franck Dernoncourt, Branislav Kveton, Junda Wu, Tong Yu, Linxin Song, Tiankai Yang, Yuehan Qin, et al. A personalized conversational benchmark: Towards simulating personalized conversations.arXiv preprint arXiv:2505.14106, 2025
-
[4]
No attacker needed: Unintentional cross-user contamination in shared-state llm agents
Tiankai Yang, Jiate Li, Yi Nian, Shen Dong, Ruiyao Xu, Ryan Rossi, Kaize Ding, and Yue Zhao. No attacker needed: Unintentional cross-user contamination in shared-state llm agents. arXiv preprint arXiv:2604.01350, 2026
-
[5]
Yi Nian, Aojie Yuan, Haiyue Zhang, Jiate Li, and Yue Zhao. Auditable agents.arXiv preprint arXiv:2604.05485, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862, 2022
work page Pith review arXiv 2022
-
[7]
Safe RLHF: Safe reinforcement learning from human feedback
Josef Dai, Xuehai Pan, Ruiyang Sun, Jiaming Ji, Xinbo Xu, Mickel Liu, Yizhou Wang, and Yaodong Yang. Safe RLHF: Safe reinforcement learning from human feedback. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[8]
Deep reinforcement learning from human preferences.Advances in neural information processing systems, 30, 2017
Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences.Advances in neural information processing systems, 30, 2017
2017
-
[9]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36:53728–53741, 2023
2023
-
[10]
SafeDPO: A simple approach to direct preference optimization with enhanced safety
Geon-Hyeong Kim, Yu Jin Kim, Byoungjip Kim, Honglak Lee, Kyunghoon Bae, Youngsoo Jang, and Moontae Lee. SafeDPO: A simple approach to direct preference optimization with enhanced safety. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[11]
Stepwise alignment for constrained language model policy optimization.Advances in Neural Information Processing Systems, 37:104471–104520, 2024
Akifumi Wachi, Thien Q Tran, Rei Sato, Takumi Tanabe, and Youhei Akimoto. Stepwise alignment for constrained language model policy optimization.Advances in Neural Information Processing Systems, 37:104471–104520, 2024
2024
-
[12]
Hashimoto, and Percy Liang
Shiori Sagawa*, Pang Wei Koh*, Tatsunori B. Hashimoto, and Percy Liang. Distributionally robust neural networks. InInternational Conference on Learning Representations, 2020
2020
-
[13]
Group robust preference optimization in reward-free rlhf.Advances in Neural Information Processing Systems, 37:37100–37137, 2024
Shyam Sundhar Ramesh, Yifan Hu, Iason Chaimalas, Viraj Mehta, Pier Giuseppe Sessa, Haitham Bou Ammar, and Ilija Bogunovic. Group robust preference optimization in reward-free rlhf.Advances in Neural Information Processing Systems, 37:37100–37137, 2024
2024
-
[14]
Towards robust alignment of language models: Distributionally robustifying direct preference optimization
Junkang Wu, Yuexiang Xie, Zhengyi Yang, Jiancan Wu, Jiawei Chen, Jinyang Gao, Bolin Ding, Xiang Wang, and Xiangnan He. Towards robust alignment of language models: Distributionally robustifying direct preference optimization. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[15]
Robust LLM alignment via distributionally robust direct preference optimization
Zaiyan Xu, Sushil Vemuri, Kishan Panaganti, Dileep Kalathil, Rahul Jain, and Deepak Ra- machandran. Robust LLM alignment via distributionally robust direct preference optimization. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. 10
2025
-
[16]
Keertana Chidambaram, Karthik Vinary Seetharaman, and Vasilis Syrgkanis. Direct preference optimization with unobserved preference heterogeneity: The necessity of ternary preferences. arXiv preprint arXiv:2510.15716, 2025
-
[17]
Pku-saferlhf: Towards multi-level safety alignment for llms with human preference
Jiaming Ji, Donghai Hong, Borong Zhang, Boyuan Chen, Josef Dai, Boren Zheng, Tianyi Alex Qiu, Jiayi Zhou, Kaile Wang, Boxun Li, et al. Pku-saferlhf: Towards multi-level safety alignment for llms with human preference. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 31983–32016, 2025
2025
-
[18]
Rank analysis of incomplete block designs: I
Ralph Allan Bradley and Milton E Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons.Biometrika, 39(3/4):324–345, 1952
1952
-
[19]
Fine-Tuning Language Models from Human Preferences
Daniel M Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. Fine-tuning language models from human preferences. arXiv preprint arXiv:1909.08593, 2019
work page internal anchor Pith review arXiv 1909
-
[20]
Cambridge University Press, 2004
Stephen Boyd and Lieven Vandenberghe.Convex Optimization. Cambridge University Press, 2004
2004
-
[21]
Stanford University Press Stanford, 1958
Kenneth Joseph Arrow, Leonid Hurwicz, Hirofumi Uzawa, Hollis Burnley Chenery, Selmer Johnson, and Samuel Karlin.Studies in linear and non-linear programming, volume 2. Stanford University Press Stanford, 1958
1958
-
[22]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
From hard refusals to safe-completions: Toward output-centric safety training
Yuan Yuan, Tina Sriskandarajah, Anna-Luisa Brakman, Alec Helyar, Alex Beutel, Andrea Vallone, and Saachi Jain. From hard refusals to safe-completions: Toward output-centric safety training.arXiv preprint arXiv:2508.09224, 2025
-
[26]
Xstest: A test suite for identifying exaggerated safety behaviours in large language models
Paul Röttger, Hannah Kirk, Bertie Vidgen, Giuseppe Attanasio, Federico Bianchi, and Dirk Hovy. Xstest: A test suite for identifying exaggerated safety behaviours in large language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers),...
2024
-
[27]
Springer, 2008
Vivek S Borkar and Vivek S Borkar.Stochastic approximation: a dynamical systems viewpoint, volume 100. Springer, 2008
2008
-
[28]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[29]
GNN-as-judge: Unleashing the power of LLMs for graph learning with GNN feedback
Ruiyao Xu and Kaize Ding. GNN-as-judge: Unleashing the power of LLMs for graph learning with GNN feedback. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[30]
Coact: Co-active llm preference learning with human-ai synergy, 2026
Ruiyao Xu, Mihir Parmar, Tiankai Yang, Zhengyu Hu, Yue Zhao, and Kaize Ding. Coact: Co-active llm preference learning with human-ai synergy, 2026
2026
-
[31]
A general theoretical paradigm to understand learning from human preferences
Mohammad Gheshlaghi Azar, Zhaohan Daniel Guo, Bilal Piot, Remi Munos, Mark Rowland, Michal Valko, and Daniele Calandriello. A general theoretical paradigm to understand learning from human preferences. InInternational Conference on Artificial Intelligence and Statistics, pages 4447–4455. PMLR, 2024. 11
2024
-
[32]
Model alignment as prospect theoretic optimization
Kawin Ethayarajh, Winnie Xu, Niklas Muennighoff, Dan Jurafsky, and Douwe Kiela. Model alignment as prospect theoretic optimization. InForty-first International Conference on Machine Learning, 2024
2024
-
[33]
Simpo: Simple preference optimization with a reference-free reward.Advances in Neural Information Processing Systems, 37:124198–124235, 2024
Yu Meng, Mengzhou Xia, and Danqi Chen. Simpo: Simple preference optimization with a reference-free reward.Advances in Neural Information Processing Systems, 37:124198–124235, 2024
2024
-
[34]
AlphaDPO: Adaptive reward margin for direct preference optimization
Junkang Wu, Xue Wang, Zhengyi Yang, Jiancan Wu, Jinyang Gao, Bolin Ding, Xiang Wang, and Xiangnan He. AlphaDPO: Adaptive reward margin for direct preference optimization. In Forty-second International Conference on Machine Learning, 2025
2025
-
[35]
Hyung Gyu Rho. Margin adaptive dpo: Leveraging reward model for granular control in preference optimization.arXiv preprint arXiv:2510.05342, 2025
-
[36]
Amapo: Adaptive margin-attached preference optimization for language model alignment, 2025
Ruibo Deng, Duanyu Feng, and Wenqiang Lei. Amapo: Adaptive margin-attached preference optimization for language model alignment, 2025
2025
-
[37]
Routledge, 2021
Eitan Altman.Constrained Markov decision processes. Routledge, 2021
2021
-
[38]
Constrained reinforcement learning has zero duality gap.Advances in Neural Information Processing Systems, 32, 2019
Santiago Paternain, Luiz Chamon, Miguel Calvo-Fullana, and Alejandro Ribeiro. Constrained reinforcement learning has zero duality gap.Advances in Neural Information Processing Systems, 32, 2019
2019
-
[39]
Natural policy gradient primal-dual method for constrained markov decision processes.Advances in Neural Information Processing Systems, 33:8378–8390, 2020
Dongsheng Ding, Kaiqing Zhang, Tamer Basar, and Mihailo Jovanovic. Natural policy gradient primal-dual method for constrained markov decision processes.Advances in Neural Information Processing Systems, 33:8378–8390, 2020
2020
-
[40]
Mankowitz, and Shie Mannor
Chen Tessler, Daniel J. Mankowitz, and Shie Mannor. Reward constrained policy optimization. InInternational Conference on Learning Representations, 2019
2019
-
[41]
One-shot safety alignment for large language models via optimal dualization.Advances in Neural Information Processing Systems, 37:84350–84383, 2024
Xinmeng Huang, Shuo Li, Edgar Dobriban, Osbert Bastani, Hamed Hassani, and Dongsheng Ding. One-shot safety alignment for large language models via optimal dualization.Advances in Neural Information Processing Systems, 37:84350–84383, 2024
2024
-
[42]
Fairness without demographics in repeated loss minimization
Tatsunori Hashimoto, Megha Srivastava, Hongseok Namkoong, and Percy Liang. Fairness without demographics in repeated loss minimization. InInternational Conference on Machine Learning, pages 1929–1938. PMLR, 2018
1929
-
[43]
Beyond one-preference-fits-all alignment: Multi-objective direct preference optimization
Zhanhui Zhou, Jie Liu, Jing Shao, Xiangyu Yue, Chao Yang, Wanli Ouyang, and Yu Qiao. Beyond one-preference-fits-all alignment: Multi-objective direct preference optimization. In Findings of the Association for Computational Linguistics: ACL 2024, pages 10586–10613, 2024
2024
-
[44]
binding-category-only
OpenAI. GPT-4.1.https://openai.com/index/gpt-4-1/, 2025. 12 A Full Derivation of Cat-DPO We work in the same setting as Section 3: policy πθ, reference model πref, latent helpfulness reward r(x, y), binary unsafe indicator h(x, y)∈ {0,1} , category set C(x)⊆ K , per-category constrained problem (4), and category-augmented reward (6). A.1 Closed-Form Optim...
2025
-
[45]
How do I cook pasta?
benign: A normal, safe question with no safety risk. Examples: “How do I cook pasta?”, “Explain quantum physics.”
-
[46]
How do knife safety practices work?
risky_but_answerable: The prompt touches on sensitive topics but CAN be answered safely and helpfully with appropriate care. Examples: “How do knife safety practices work?”, “What are common signs of drug addiction?”, “How do hackers typically break into systems?” (can be answered for defensive security education)
-
[47]
How do I make a bomb?
inherently_harmful: The prompt is explicitly requesting harmful content that cannot be responsibly answered. Examples: “How do I make a bomb?”, “Give me a plan to kidnap someone.” Output your answer in the following JSON format only, no other text: {"class": "<benign | risky_but_answerable | inherently_harmful>", "reason": "<one sentence explanation>"} Us...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.