Recognition: unknown
Efficient Test-Time Scaling via Temporal Reasoning Aggregation
Pith reviewed 2026-05-10 06:14 UTC · model grok-4.3
The pith
TRACE stops LLM reasoning early by checking if answers stay consistent and confidence stabilizes across recent steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
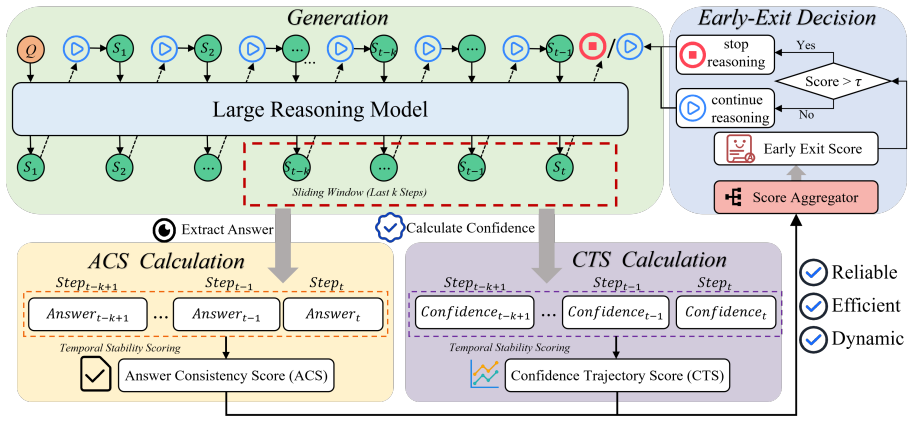
TRACE detects reasoning convergence over time by aggregating two complementary signals across recent reasoning steps: answer consistency, capturing the persistence of predicted answers, and confidence trajectory, modeling the temporal evolution of model confidence. Benefiting from these two factors, TRACE can accurately determine whether the reasoning process has converged, thereby promptly halting inference and effectively avoiding redundant reasoning steps.
What carries the argument
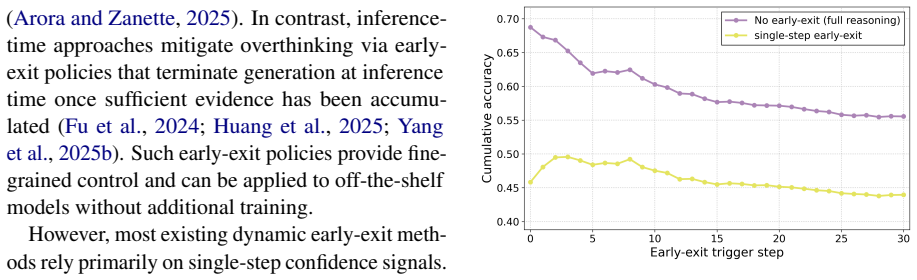
Temporal aggregation of answer consistency and confidence trajectory over recent reasoning steps, which replaces single-step confidence checks for deciding early termination.
If this is right
- Reduces average reasoning token usage by 25-30 percent across tested benchmarks.
- Keeps final accuracy within 1-2 percent of complete reasoning chains.
- Outperforms prior dynamic early-exit methods that rely on single-step signals.
- Requires no additional training, so it applies directly to existing models.
Where Pith is reading between the lines
- The same temporal-stability idea could be tested on non-reasoning tasks such as code generation or multi-turn dialogue to see if early stopping generalizes.
- Combining TRACE with token-budget limits might produce even larger savings on very long problems.
- If the two signals sometimes disagree, a simple weighted rule or learned threshold might further improve the accuracy-efficiency trade-off.
Load-bearing premise
That aggregating answer consistency and confidence trajectory over recent steps reliably detects reasoning convergence without prematurely stopping on incorrect paths or missing better answers in multi-step settings.
What would settle it
A benchmark run where TRACE terminates reasoning on problems that later steps would have corrected, producing measurably lower accuracy than full-length reasoning on the same set.
Figures








read the original abstract
Test-time scaling improves the reasoning performance of large language models but often results in token-inefficient overthinking, where models continue reasoning beyond what is necessary for a correct answer. Existing dynamic early-exit methods typically rely on single-step confidence signals, which are often unreliable for detecting reasoning convergence in multi-step settings. To mitigate this limitation, we propose TRACE, a training-free framework for efficient test-time scaling that determines when to terminate reasoning based on temporal aggregation of multi-step evidence rather than instantaneous signals. TRACE detects reasoning convergence over time by aggregating two complementary signals across recent reasoning steps: answer consistency, capturing the persistence of predicted answers, and confidence trajectory, modeling the temporal evolution of model confidence. Benefiting from these two factors, TRACE can accurately determine whether the reasoning process has converged, thereby promptly halting inference and effectively avoiding redundant reasoning steps. Extensive experiments on multiple challenging benchmarks show that TRACE reduces reasoning token usage by 25-30% on average while maintaining accuracy within 1-2% of full-length reasoning, consistently outperforming existing dynamic reasoning methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TRACE, a training-free framework for efficient test-time scaling in LLMs. It determines reasoning termination by temporally aggregating two signals over recent steps—answer consistency (persistence of predicted answers) and confidence trajectory (evolution of model confidence)—rather than relying on single-step signals. The central claim is that this detects convergence reliably enough to reduce reasoning token usage by 25-30% on average while keeping accuracy within 1-2% of full-length reasoning and outperforming prior dynamic early-exit methods across multiple benchmarks.
Significance. If the aggregation reliably avoids premature termination on incorrect paths, TRACE would offer a practical, training-free way to curb overthinking in multi-step chain-of-thought without additional model training or fine-tuning. This addresses a clear inefficiency in current test-time scaling and could be broadly applicable to existing LLMs, provided the method generalizes beyond the reported benchmarks.
major comments (3)
- [§3] §3 (Method): The description of temporal aggregation does not specify the window length, combination weights between consistency and confidence, or the exact termination threshold. These choices are load-bearing for the central claim, as they directly determine whether local persistence implies global convergence; without them the 25-30% token reduction cannot be reproduced or stress-tested against late-stage corrections.
- [§4] §4 (Experiments): The reported 1-2% accuracy tolerance is presented as an aggregate figure, but no per-problem breakdown or error analysis is given for cases where models stabilize on incorrect intermediate answers before later revisions. This leaves the weakest assumption unexamined and risks concealing larger accuracy drops on multi-step problems.
- [§4.3] §4.3 (Baselines and ablations): The comparison to existing dynamic reasoning methods lacks detail on whether those baselines were re-implemented with the same stopping criteria or hyperparameter search; if not, the consistent outperformance claim rests on potentially mismatched implementations.
minor comments (2)
- [Abstract] The abstract and introduction use the term 'temporal aggregation' without an early equation or pseudocode; adding a compact definition in §2 or §3 would improve readability.
- [§4] Figure captions and axis labels in the experimental plots should explicitly state the window size and aggregation parameters used for each TRACE curve.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important aspects of clarity and experimental rigor in our work on TRACE. We respond to each major comment below and will revise the manuscript to incorporate the suggested improvements for better reproducibility and transparency.
read point-by-point responses
-
Referee: [§3] §3 (Method): The description of temporal aggregation does not specify the window length, combination weights between consistency and confidence, or the exact termination threshold. These choices are load-bearing for the central claim, as they directly determine whether local persistence implies global convergence; without them the 25-30% token reduction cannot be reproduced or stress-tested against late-stage corrections.
Authors: We agree that these hyperparameters are critical for reproducibility and should be stated explicitly in the method section. While the core aggregation logic is described in §3, the specific values (a sliding window of the most recent 4 steps, equal weights of 0.5 for the consistency and confidence signals, and a termination threshold of 0.75) appear only in the experimental setup. We will revise §3 to include a clear subsection on the aggregation formula, chosen hyperparameters, and their selection rationale from validation experiments. This change will make the 25-30% token reduction fully reproducible. revision: yes
-
Referee: [§4] §4 (Experiments): The reported 1-2% accuracy tolerance is presented as an aggregate figure, but no per-problem breakdown or error analysis is given for cases where models stabilize on incorrect intermediate answers before later revisions. This leaves the weakest assumption unexamined and risks concealing larger accuracy drops on multi-step problems.
Authors: The referee is correct that aggregate metrics alone leave open the possibility of hidden per-problem variance, particularly on multi-step problems where early stabilization on an incorrect answer could occur. Our current results report only overall accuracy and token savings. In the revision we will add a targeted error analysis (new paragraph in §4 and supporting table in the appendix) that quantifies the frequency of premature termination on incorrect paths and the resulting accuracy impact on a per-benchmark basis. This will directly examine the assumption that temporal aggregation reliably avoids such cases. revision: yes
-
Referee: [§4.3] §4.3 (Baselines and ablations): The comparison to existing dynamic reasoning methods lacks detail on whether those baselines were re-implemented with the same stopping criteria or hyperparameter search; if not, the consistent outperformance claim rests on potentially mismatched implementations.
Authors: We re-implemented the baselines following the original papers as closely as possible and tuned their hyperparameters on a held-out validation split to ensure a fair comparison. However, the manuscript does not document this process in sufficient detail. We will expand §4.3 with an explicit description of the re-implementation protocol, the stopping criteria applied to each baseline, and the hyperparameter ranges searched. This addition will substantiate the outperformance results and allow readers to verify the fairness of the comparison. revision: yes
Circularity Check
No circularity: TRACE is a defined heuristic with no self-referential reduction
full rationale
The paper introduces TRACE as an explicitly training-free heuristic that terminates reasoning by aggregating two observable signals (answer consistency and confidence trajectory) over a recent window. No equations, parameters, or termination rules are fitted to the target accuracy metric; the method is defined directly by its aggregation logic and then evaluated empirically on benchmarks. No self-citations are invoked as load-bearing uniqueness theorems, and no prediction is shown to be equivalent to its own inputs by construction. The derivation chain is therefore self-contained as a proposal of a new stopping rule rather than a tautological restatement of fitted or cited quantities.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multi-step temporal signals are more reliable than single-step confidence for detecting reasoning convergence
Reference graph
Works this paper leans on
-
[1]
NAACL 2024 , pages =
Jiahui Geng and Fengyu Cai and Yuxia Wang and Heinz Koeppl and Preslav Nakov and Iryna Gurevych , title =. NAACL 2024 , pages =. 2024 , url =
2024
-
[4]
EMNLP 2024 , pages =
Mozhi Zhang and Mianqiu Huang and Rundong Shi and Linsen Guo and Chong Peng and Peng Yan and Yaqian Zhou and Xipeng Qiu , title =. EMNLP 2024 , pages =. 2024 , url =
2024
-
[5]
QA-Calibration of Language Model Confidence Scores , booktitle =
Putra Manggala and Atalanti. QA-Calibration of Language Model Confidence Scores , booktitle =. 2025 , url =
2025
-
[13]
ICLR 2024 , publisher =
Miao Xiong and Zhiyuan Hu and Xinyang Lu and Yifei Li and Jie Fu and Junxian He and Bryan Hooi , title =. ICLR 2024 , publisher =. 2024 , url =
2024
-
[15]
2025 , howpublished =
AI-MO/aimo-validation-amc:. 2025 , howpublished =
2025
-
[16]
2024 , howpublished =
AIME Problems and Solutions , author =. 2024 , howpublished =
2024
-
[17]
ICLR 2024 , publisher =
Hunter Lightman and Vineet Kosaraju and Yuri Burda and Harrison Edwards and Bowen Baker and Teddy Lee and Jan Leike and John Schulman and Ilya Sutskever and Karl Cobbe , title =. ICLR 2024 , publisher =. 2024 , url =
2024
-
[20]
Distilling system 2 into system 1
Distilling system 2 into system 1 , author=. arXiv preprint arXiv:2407.06023 , year=
-
[21]
Token-Budget-Aware
Tingxu Han and Zhenting Wang and Chunrong Fang and Shiyu Zhao and Shiqing Ma and Zhenyu Chen , editor =. Token-Budget-Aware. ACL 2025 , pages =. 2025 , url =
2025
-
[27]
ICML 2025 , publisher =
Xingyu Chen and Jiahao Xu and Tian Liang and Zhiwei He and Jianhui Pang and Dian Yu and Linfeng Song and Qiuzhi Liu and Mengfei Zhou and Zhuosheng Zhang and Rui Wang and Zhaopeng Tu and Haitao Mi and Dong Yu , title =. ICML 2025 , publisher =. 2025 , url =
2025
-
[29]
Stop Overthinking:
Yang Sui and Yu. Stop Overthinking:. Trans. Mach. Learn. Res. , volume =. 2025 , url =
2025
-
[30]
Tree of Thoughts: Deliberate Problem Solving with Large Language Models , booktitle =
Shunyu Yao and Dian Yu and Jeffrey Zhao and Izhak Shafran and Tom Griffiths and Yuan Cao and Karthik Narasimhan , editor =. Tree of Thoughts: Deliberate Problem Solving with Large Language Models , booktitle =. 2023 , url =
2023
-
[31]
Le and Ed H
Xuezhi Wang and Jason Wei and Dale Schuurmans and Quoc V. Le and Ed H. Chi and Sharan Narang and Aakanksha Chowdhery and Denny Zhou , title =. ICLR 2023 , publisher =. 2023 , url =
2023
-
[32]
Chi and Quoc V
Jason Wei and Xuezhi Wang and Dale Schuurmans and Maarten Bosma and Brian Ichter and Fei Xia and Ed H. Chi and Quoc V. Le and Denny Zhou , editor =. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , booktitle =. 2022 , url =
2022
-
[34]
ICML 2025 , publisher =
Xinyu Guan and Li Lyna Zhang and Yifei Liu and Ning Shang and Youran Sun and Yi Zhu and Fan Yang and Mao Yang , title =. ICML 2025 , publisher =. 2025 , url =
2025
-
[35]
TEVC 2025 , year=
CoCoEvo: Co-Evolution of Programs and Test Cases to Enhance Code Generation , author=. TEVC 2025 , year=
2025
-
[38]
Reason- ing models can be effective without thinking.arXiv preprint arXiv:2504.09858, 2025
Wenjie Ma and Jingxuan He and Charlie Snell and Tyler Griggs and Sewon Min and Matei Zaharia , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2504.09858 , eprinttype =. 2504.09858 , timestamp =
-
[40]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[43]
AI-MO Project and Project Numina . 2025. Ai-mo/aimo-validation-amc: AMC math validation set. https://huggingface.co/datasets/AI-MO/aimo-validation-amc. Dataset on Hugging Face. Extracted from AMC12 2022 and AMC12 2023 problems from the Art of Problem Solving Wiki and adapted to integer outputs
2025
-
[44]
Daman Arora and Andrea Zanette. 2025. https://doi.org/10.48550/ARXIV.2502.04463 Training language models to reason efficiently . CoRR, abs/2502.04463
-
[45]
Xingyu Chen, Jiahao Xu, Tian Liang, Zhiwei He, Jianhui Pang, Dian Yu, Linfeng Song, Qiuzhi Liu, Mengfei Zhou, Zhuosheng Zhang, Rui Wang, Zhaopeng Tu, Haitao Mi, and Dong Yu. 2025 a . https://openreview.net/forum?id=MSbU3L7V00 Do NOT think that much for 2+3=? on the overthinking of long reasoning models . In ICML 2025. OpenReview.net
2025
-
[46]
Zhuokun Chen, Zeren Chen, Jiahao He, Mingkui Tan, Jianfei Cai, and Bohan Zhuang. 2025 b . https://doi.org/10.48550/ARXIV.2507.17307 R-stitch: Dynamic trajectory stitching for efficient reasoning . CoRR, abs/2507.17307
-
[47]
MAA Committees. 2024. https://artofproblemsolving.com/wiki/index.php/AIME_Problems_and_Solutions Aime problems and solutions . Online. Retrieved from Art of Problem Solving Wiki
2024
-
[48]
arXiv preprint arXiv:2502.08235 , year =
Alejandro Cuadron, Dacheng Li, Wenjie Ma, Xingyao Wang, Yichuan Wang, Siyuan Zhuang, Shu Liu, Luis Gaspar Schroeder, Tian Xia, Huanzhi Mao, Nicholas Thumiger, Aditya Desai, Ion Stoica, Ana Klimovic, Graham Neubig, and Joseph E. Gonzalez. 2025. https://doi.org/10.48550/ARXIV.2502.08235 The danger of overthinking: Examining the reasoning-action dilemma in a...
-
[49]
DeepSeek - AI. 2025. https://doi.org/10.48550/ARXIV.2501.12948 Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning . CoRR, abs/2501.12948
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.12948 2025
-
[50]
Jinzong Dong, Zhaohui Jiang, Dong Pan, and Haoyang Yu. 2025. https://doi.org/10.1609/AAAI.V39I15.33792 Combining priors with experience: Confidence calibration based on binomial process modeling . In AAAI 25, pages 16317--16326. AAAI Press
-
[51]
Lorenzo Jaime Yu Flores, Ori Ernst, and Jackie CK Cheung. 2025. https://doi.org/10.18653/V1/2025.ACL-SHORT.15 Improving the calibration of confidence scores in text generation using the output distribution's characteristics . In ACL 2025, pages 172--182. Association for Computational Linguistics
-
[52]
Yichao Fu, Junda Chen, Siqi Zhu, Zheyu Fu, Zhongdongming Dai, Aurick Qiao, and Hao Zhang. 2024. https://doi.org/10.48550/ARXIV.2412.20993 Efficiently serving LLM reasoning programs with certaindex . CoRR, abs/2412.20993
-
[53]
Jiahui Geng, Fengyu Cai, Yuxia Wang, Heinz Koeppl, Preslav Nakov, and Iryna Gurevych. 2024. https://doi.org/10.18653/v1/2024.naacl-long.366 A survey of confidence estimation and calibration in large language models . In NAACL 2024, pages 6577--6595. Association for Computational Linguistics
-
[54]
Xinyu Guan, Li Lyna Zhang, Yifei Liu, Ning Shang, Youran Sun, Yi Zhu, Fan Yang, and Mao Yang. 2025. https://openreview.net/forum?id=5zwF1GizFa rstar-math: Small llms can master math reasoning with self-evolved deep thinking . In ICML 2025. OpenReview.net
2025
-
[55]
Tingxu Han, Zhenting Wang, Chunrong Fang, Shiyu Zhao, Shiqing Ma, and Zhenyu Chen. 2025. https://aclanthology.org/2025.findings-acl.1274/ Token-budget-aware LLM reasoning . In ACL 2025, pages 24842--24855. Association for Computational Linguistics
2025
-
[56]
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, Jie Liu, Lei Qi, Zhiyuan Liu, and Maosong Sun. 2024. https://doi.org/10.18653/V1/2024.ACL-LONG.211 Olympiadbench: A challenging benchmark for promoting AGI with olympiad-level bilingual multimodal scientific problems . In ACL 2024, ...
-
[57]
Jiameng Huang, Baijiong Lin, Guhao Feng, Jierun Chen, Di He, and Lu Hou. 2025. https://doi.org/10.48550/ARXIV.2508.05337 Efficient reasoning for large reasoning language models via certainty-guided reflection suppression . CoRR, abs/2508.05337
-
[58]
Romain Lacombe, Kerrie Wu, and Eddie Dilworth. 2025. https://doi.org/10.48550/ARXIV.2508.15050 Don't think twice! over-reasoning impairs confidence calibration . CoRR, abs/2508.15050
-
[59]
Kefan Li, Yuan Yuan, Hongyue Yu, Tingyu Guo, and Shijie Cao. 2025. https://doi.org/10.48550/ARXIV.2502.10802 Cocoevo: Co-evolution of programs and test cases to enhance code generation . TEVC 2025
-
[60]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. 2024. https://openreview.net/forum?id=v8L0pN6EOi Let's verify step by step . In ICLR 2024. OpenReview.net
2024
-
[61]
Xiaoou Liu, Tiejin Chen, Longchao Da, Chacha Chen, Zhen Lin, and Hua Wei. 2025. https://doi.org/10.1145/3711896.3736569 Uncertainty quantification and confidence calibration in large language models: A survey . In KDD 2025, pages 6107--6117. ACM
-
[62]
Xin Liu and Lu Wang. 2025. https://doi.org/10.48550/ARXIV.2506.02536 Answer convergence as a signal for early stopping in reasoning . CoRR, arXiv:2506.02536
-
[63]
Ximing Lu, Seungju Han, David Acuna, Hyunwoo Kim, Jaehun Jung, Shrimai Prabhumoye, Niklas Muennighoff, Mostofa Patwary, Mohammad Shoeybi, Bryan Catanzaro, and Yejin Choi. 2025. https://doi.org/10.48550/ARXIV.2504.04383 Retro-search: Exploring untaken paths for deeper and efficient reasoning . CoRR, abs/2504.04383
-
[64]
Putra Manggala, Atalanti - Anastasia Mastakouri, Elke Kirschbaum, Shiva Prasad Kasiviswanathan, and Aaditya Ramdas. 2025. https://openreview.net/forum?id=D2hhkU5O48 Qa-calibration of language model confidence scores . In ICLR 2025. OpenReview.net
2025
-
[65]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. 2023. https://doi.org/10.48550/ARXIV.2311.12022 GPQA: A graduate-level google-proof q & a benchmark . CoRR, abs/2311.12022
work page internal anchor Pith review doi:10.48550/arxiv.2311.12022 2023
-
[66]
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. 2024. https://doi.org/10.48550/ARXIV.2408.03314 Scaling LLM test-time compute optimally can be more effective than scaling model parameters . CoRR, arXiv:2408.03314
-
[67]
Yang Sui, Yu - Neng Chuang, Guanchu Wang, Jiamu Zhang, Tianyi Zhang, Jiayi Yuan, Hongyi Liu, Andrew Wen, Shaochen Zhong, Na Zou, Hanjie Chen, and Xia Hu. 2025. https://openreview.net/forum?id=HvoG8SxggZ Stop overthinking: A survey on efficient reasoning for large language models . Trans. Mach. Learn. Res., 2025
2025
-
[68]
Gemini Team. 2025. https://doi.org/10.48550/ARXIV.2507.06261 Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities . CoRR, abs/2507.06261
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.06261 2025
-
[69]
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, Chuning Tang, Congcong Wang, Dehao Zhang, Enming Yuan, Enzhe Lu, Fengxiang Tang, Flood Sung, Guangda Wei, Guokun Lai, and 75 others. 2025. https://doi.org/10.48550/ARXIV.2501.12599 Kimi k1.5: Scaling reinforcement learning with ll...
work page internal anchor Pith review doi:10.48550/arxiv.2501.12599 2025
-
[70]
Chenlong Wang, Yuanning Feng, Dongping Chen, Zhaoyang Chu, Ranjay Krishna, and Tianyi Zhou. 2025. https://doi.org/10.18653/v1/2025.findings-emnlp.394 Wait, we don ' t need to ``wait''! removing thinking tokens improves reasoning efficiency . In EMNLP 2025, pages 7459--7482. Association for Computational Linguistics
-
[71]
Le, Ed H
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V. Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023. https://openreview.net/forum?id=1PL1NIMMrw Self-consistency improves chain of thought reasoning in language models . In ICLR 2023. OpenReview.net
2023
-
[72]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022. http://papers.nips.cc/paper\_files/paper/2022/hash/9d5609613524ecf4f15af0f7b31abca4-Abstract-Conference.html Chain-of-thought prompting elicits reasoning in large language models . In NeurIPS 2022
2022
-
[73]
Miao Xiong, Zhiyuan Hu, Xinyang Lu, Yifei Li, Jie Fu, Junxian He, and Bryan Hooi. 2024. https://openreview.net/forum?id=gjeQKFxFpZ Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms . In ICLR 2024. OpenReview.net
2024
-
[74]
Fengli Xu, Qianyue Hao, Zefang Zong, Jingwei Wang, Yunke Zhang, Jingyi Wang, Xiaochong Lan, Jiahui Gong, Tianjian Ouyang, Fanjin Meng, Chenyang Shao, Yuwei Yan, Qinglong Yang, Yiwen Song, Sijian Ren, Xinyuan Hu, Yu Li, Jie Feng, Chen Gao, and Yong Li. 2025. https://doi.org/10.48550/ARXIV.2501.09686 Towards large reasoning models: A survey of reinforced re...
-
[75]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 40 others. 2025 a . https://doi.org/10.48550/ARXIV.2505.09388 Qwen3 technical report . CoRR, arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388 2025
-
[76]
Chenxu Yang, Qingyi Si, Yongjie Duan, Zheliang Zhu, Chenyu Zhu, Zheng Lin, Li Cao, and Weiping Wang. 2025 b . https://doi.org/10.48550/ARXIV.2504.15895 Dynamic early exit in reasoning models . CoRR, abs/2504.15895
-
[77]
Wenkai Yang, Shuming Ma, Yankai Lin, and Furu Wei. 2025 c . https://doi.org/10.48550/ARXIV.2502.18080 Towards thinking-optimal scaling of test-time compute for LLM reasoning . CoRR, abs/2502.18080
-
[78]
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. http://papers.nips.cc/paper\_files/paper/2023/hash/271db9922b8d1f4dd7aaef84ed5ac703-Abstract-Conference.html Tree of thoughts: Deliberate problem solving with large language models . In NeurIPS 2023
2023
-
[79]
Zhaojian Yu, Yinghao Wu, Yilun Zhao, Arman Cohan, and Xiao - Ping Zhang. 2025. https://doi.org/10.48550/ARXIV.2504.00810 Z1: efficient test-time scaling with code . CoRR, arXiv:2504.00810
-
[80]
Mozhi Zhang, Mianqiu Huang, Rundong Shi, Linsen Guo, Chong Peng, Peng Yan, Yaqian Zhou, and Xipeng Qiu. 2024. https://doi.org/10.18653/V1/2024.EMNLP-MAIN.173 Calibrating the confidence of large language models by eliciting fidelity . In EMNLP 2024, pages 2959--2979. Association for Computational Linguistics
-
[81]
Xinran Zhao, Hongming Zhang, Xiaoman Pan, Wenlin Yao, Dong Yu, Tongshuang Wu, and Jianshu Chen. 2024. https://doi.org/10.18653/V1/2024.FINDINGS-ACL.515 Fact-and-reflection (far) improves confidence calibration of large language models . In ACL 2024, pages 8702--8718. Association for Computational Linguistics
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.