Recognition: unknown
SOCIA-EVO: Automated Simulator Construction via Dual-Anchored Bi-Level Optimization
Pith reviewed 2026-05-10 06:32 UTC · model grok-4.3
The pith
SOCIA-EVO builds simulators that match observational data by separating structural changes from parameter tuning in LLM agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SOCIA-EVO introduces a dual-anchored evolutionary framework for automated simulator construction. It employs a static blueprint to enforce empirical constraints, a bi-level optimization to decouple structural refinement from parameter calibration, and a self-curating Strategy Playbook that manages remedial hypotheses via Bayesian-weighted retrieval. By falsifying ineffective strategies through execution feedback, SOCIA-EVO achieves robust convergence, generating simulators that are statistically consistent with observational data.
What carries the argument
The dual-anchored bi-level optimization anchored by a static blueprint and a self-curating Strategy Playbook, which together separate structural refinement from parameter calibration and use execution feedback to eliminate poor strategies.
If this is right
- Simulators can be produced automatically while maintaining statistical agreement with data instead of requiring hand-crafted structure and parameters.
- Contextual drift and mixed error types in long-horizon LLM agents are reduced because structure and calibration are optimized on separate levels.
- A Bayesian-weighted playbook allows the system to retrieve and test remedial hypotheses without manual intervention each time a strategy fails.
- Execution feedback serves as a direct falsification mechanism that prunes ineffective strategies and drives convergence.
- The resulting simulators become reliable testbeds because they are required to reproduce observed statistical behavior rather than just run without crashing.
Where Pith is reading between the lines
- The same separation of structure and parameters might apply to other automated code-generation tasks where agents must produce executable artifacts that match external constraints.
- If the blueprint can be derived from data summaries, the method could reduce reliance on domain experts for initial simulator specification.
- Repeated application across different observational datasets could test whether the playbook learns reusable strategy patterns that transfer between simulation domains.
- The approach suggests a route to make agent-based modeling more reproducible by tying simulator validity directly to falsifiable statistical checks.
Load-bearing premise
The static blueprint can hold empirical constraints fixed while the bi-level split keeps structural and parametric adjustments from interfering with each other or reintroducing drift in long agent runs.
What would settle it
Run the generated simulators on held-out observational data and check whether key statistical properties such as distributions, correlations, or long-term statistics deviate significantly from the original observations.
Figures

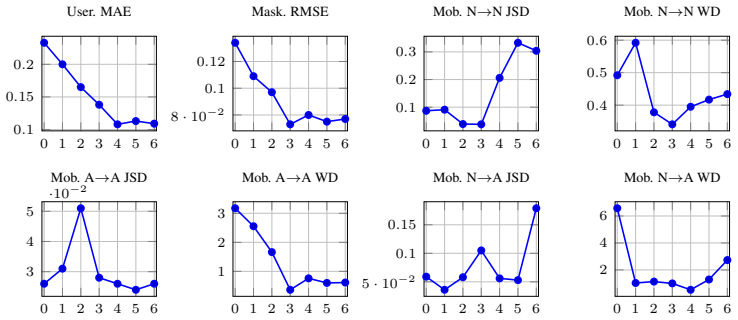
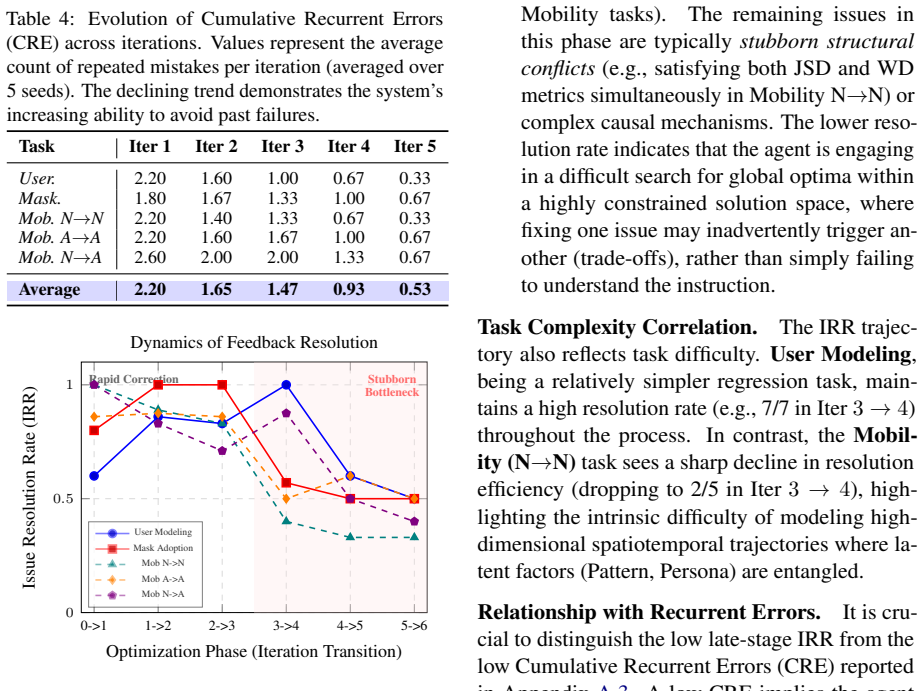


read the original abstract
Automated simulator construction requires distributional fidelity, distinguishing it from generic code generation. We identify two failure modes in long-horizon LLM agents: contextual drift and optimization instability arising from conflating structural and parametric errors. We propose SOCIA-EVO, a dual-anchored evolutionary framework. SOCIA-EVO introduces: (1) a static blueprint to enforce empirical constraints; (2) a bi-level optimization to decouple structural refinement from parameter calibration; and (3) a self-curating Strategy Playbook that manages remedial hypotheses via Bayesian-weighted retrieval. By falsifying ineffective strategies through execution feedback, SOCIA-EVO achieves robust convergence, generating simulators that are statistically consistent with observational data. The code and data of SOCIA-EVO are available here: https://github.com/cruiseresearchgroup/SOCIA/tree/evo.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SOCIA-EVO, a dual-anchored evolutionary framework for automated simulator construction with long-horizon LLM agents. It identifies contextual drift and optimization instability as key failure modes arising from conflating structural and parametric errors. The approach introduces (1) a static blueprint to enforce empirical constraints, (2) bi-level optimization to decouple structural refinement from parameter calibration, and (3) a self-curating Strategy Playbook that manages remedial hypotheses via Bayesian-weighted retrieval. Execution feedback is used to falsify ineffective strategies, with the central claim that this yields robust convergence to simulators that are statistically consistent with observational data. Code and data are released at the provided GitHub link.
Significance. If the decoupling and convergence claims hold under empirical validation, the work could meaningfully advance automated construction of faithful simulators in AI and complex-systems modeling by addressing drift and instability in LLM agents. The public release of code and data supports reproducibility and is a clear strength.
major comments (3)
- [Abstract] Abstract: the central claim that 'SOCIA-EVO achieves robust convergence, generating simulators that are statistically consistent with observational data' is asserted without any reported experimental results, error metrics, baseline comparisons, or implementation details on how convergence or statistical consistency were measured.
- [Abstract] Abstract: the bi-level optimization is described as decoupling 'structural refinement from parameter calibration' via a 'static blueprint' and 'dual-anchored' anchoring, yet no mechanism (e.g., formal constraint projection, drift-detection metric, or stability bound) is specified to guarantee that structural updates do not reintroduce contextual drift or parametric instability across long horizons in LLM-generated hypotheses.
- [Abstract] Abstract: the self-curating Strategy Playbook relies on 'Bayesian-weighted retrieval' and execution feedback for falsification, but the description provides no account of how the Bayesian weights are initialized or updated, nor how the static blueprint prevents propagation of errors from LLM-generated remedial hypotheses.
minor comments (1)
- [Abstract] The GitHub link is a positive for reproducibility; however, the abstract does not indicate whether the released code includes the full experimental pipeline or only the core framework.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. The points raised correctly identify opportunities to make the abstract more self-contained by referencing the empirical support and technical mechanisms described in the body of the paper. We address each comment below and have revised the abstract to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'SOCIA-EVO achieves robust convergence, generating simulators that are statistically consistent with observational data' is asserted without any reported experimental results, error metrics, baseline comparisons, or implementation details on how convergence or statistical consistency were measured.
Authors: We agree that the abstract would benefit from explicitly referencing the supporting evidence. The full manuscript reports extensive experiments that quantify statistical consistency using distributional metrics, include baseline comparisons against alternative simulator-construction approaches, and detail how convergence is assessed via execution-feedback loops. We have revised the abstract to include a concise summary of these results and metrics. revision: yes
-
Referee: [Abstract] Abstract: the bi-level optimization is described as decoupling 'structural refinement from parameter calibration' via a 'static blueprint' and 'dual-anchored' anchoring, yet no mechanism (e.g., formal constraint projection, drift-detection metric, or stability bound) is specified to guarantee that structural updates do not reintroduce contextual drift or parametric instability across long horizons in LLM-generated hypotheses.
Authors: The abstract is intentionally high-level. The manuscript body specifies the practical mechanisms: the static blueprint performs constraint validation on every structural proposal, while dual-anchoring monitors execution feedback to detect and correct drift. We do not claim formal theoretical guarantees; robustness is established empirically. We have updated the abstract to indicate these safeguards and added a brief discussion of observed empirical stability in the paper. revision: partial
-
Referee: [Abstract] Abstract: the self-curating Strategy Playbook relies on 'Bayesian-weighted retrieval' and execution feedback for falsification, but the description provides no account of how the Bayesian weights are initialized or updated, nor how the static blueprint prevents propagation of errors from LLM-generated remedial hypotheses.
Authors: We acknowledge that the abstract omits these operational details. The manuscript describes Bayesian weight initialization from uniform priors and their updating from execution success rates, together with the blueprint's validation gates that filter erroneous remedial hypotheses before they propagate. We have revised the abstract to mention these elements at a summary level. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's abstract and description present SOCIA-EVO as a framework relying on a static blueprint for empirical constraints, bi-level optimization to separate structural and parametric aspects, and a self-curating playbook with Bayesian retrieval plus execution feedback for falsifying strategies. No equations, fitted parameters renamed as predictions, or self-citations are exhibited that reduce the claimed convergence or statistical consistency to inputs by construction. The derivation chain depends on external observational data and iterative falsification, remaining self-contained without self-definitional loops or load-bearing self-references.
Axiom & Free-Parameter Ledger
free parameters (1)
- Bayesian weights for strategy retrieval
axioms (1)
- domain assumption Long-horizon LLM agents suffer from contextual drift and optimization instability due to conflating structural and parametric errors
invented entities (2)
-
Static blueprint
no independent evidence
-
Strategy Playbook
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[6]
Advances in Neural Information Processing Systems , volume=
Large language models as urban residents: An llm agent framework for personal mobility generation , author=. Advances in Neural Information Processing Systems , volume=
-
[8]
Proceedings of the ACM on Software Engineering , volume=
Llm hallucinations in practical code generation: Phenomena, mechanism, and mitigation , author=. Proceedings of the ACM on Software Engineering , volume=. 2025 , publisher=
2025
-
[15]
ACM Transactions on Information Systems , volume=
A survey on the memory mechanism of large language model-based agents , author=. ACM Transactions on Information Systems , volume=. 2025 , publisher=
2025
-
[16]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
In prospect and retrospect: Reflective memory management for long-term personalized dialogue agents , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[17]
Journal of Artificial Societies and Social Simulation , volume=
Calibrating agent-based models using uncertainty quantification methods , author=. Journal of Artificial Societies and Social Simulation , volume=. 2022 , publisher=
2022
-
[19]
Teaching Large Language Models to Self-Debug , booktitle =
Xinyun Chen and Maxwell Lin and Nathanael Sch. Teaching Large Language Models to Self-Debug , booktitle =. 2024 , url =
2024
-
[23]
Advances in Neural Information Processing Systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[26]
International Conference on Learning Representations , year=
Teaching Large Language Models to Self-Debug , author=. International Conference on Learning Representations , year=
-
[27]
Ecological modelling , volume=
The ODD protocol: a review and first update , author=. Ecological modelling , volume=. 2010 , publisher=
2010
-
[30]
Introducing gpt-5 , author=. , year=
-
[31]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Serial position effects of large language models , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[32]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Found in the middle: Calibrating positional attention bias improves long context utilization , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[33]
Transactions of the Association for Computational Linguistics , volume=
Lost in the middle: How language models use long contexts , author=. Transactions of the Association for Computational Linguistics , volume=
-
[34]
Science China Information Sciences , volume=
The rise and potential of large language model based agents: A survey , author=. Science China Information Sciences , volume=. 2025 , publisher=
2025
-
[35]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Who wrote this code? watermarking for code generation , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[38]
Publications Manual , year = "1983", publisher =
1983
-
[39]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[40]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[41]
Dan Gusfield , title =. 1997
1997
-
[42]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[43]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[44]
Scientific Reports , volume=
On learning agent-based models from data , author=. Scientific Reports , volume=. 2023 , publisher=
2023
-
[45]
Epidemics , volume=
Using data-driven agent-based models for forecasting emerging infectious diseases , author=. Epidemics , volume=. 2018 , publisher=
2018
-
[46]
Scientific reports , volume=
Data-driven discovery of the governing equations of dynamical systems via moving horizon optimization , author=. Scientific reports , volume=. 2022 , publisher=
2022
-
[47]
Proceedings of the national academy of sciences , volume=
Discovering governing equations from data by sparse identification of nonlinear dynamical systems , author=. Proceedings of the national academy of sciences , volume=. 2016 , publisher=
2016
-
[49]
Frontiers of Computer Science , volume=
A survey on large language model based autonomous agents , author=. Frontiers of Computer Science , volume=. 2024 , publisher=
2024
-
[50]
Advances in Neural Information Processing Systems , volume=
Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation , author=. Advances in Neural Information Processing Systems , volume=
-
[51]
Decision Support Systems , volume=
Automated discovery of business process simulation models from event logs , author=. Decision Support Systems , volume=. 2020 , publisher=
2020
-
[52]
Complexity , volume=
Agent-based computational models and generative social science , author=. Complexity , volume=. 1999 , publisher=
1999
-
[55]
Advances in Neural Information Processing Systems , volume=
Self-refine: Iterative refinement with self-feedback , author=. Advances in Neural Information Processing Systems , volume=
-
[56]
Advances in Neural Information Processing Systems , volume=
SWT-bench: Testing and validating real-world bug-fixes with code agents , author=. Advances in Neural Information Processing Systems , volume=
-
[59]
Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
Generative agents: Interactive simulacra of human behavior , author=. Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
-
[61]
Science , volume=
Competition-level code generation with alphacode , author=. Science , volume=. 2022 , publisher=
2022
-
[62]
Proceedings of the National Academy of Sciences , volume=
The frontier of simulation-based inference , author=. Proceedings of the National Academy of Sciences , volume=. 2020 , publisher=
2020
-
[63]
Political Analysis , volume=
Out of one, many: Using language models to simulate human samples , author=. Political Analysis , volume=. 2023 , publisher=
2023
-
[64]
Lisa P Argyle, Ethan C Busby, Nancy Fulda, Joshua R Gubler, Christopher Rytting, and David Wingate. 2023. Out of one, many: Using language models to simulate human samples. Political Analysis, 31(3):337--351
2023
-
[65]
Rauno Arike, Elizabeth Donoway, Henning Bartsch, and Marius Hobbhahn. 2025. https://doi.org/10.1609/aies.v8i1.36541 Evaluating goal drift in language model agents . Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, 8(1):192--203
-
[66]
Islem Bouzenia, Premkumar T. Devanbu, and Michael Pradel. 2025. https://doi.org/10.1109/ICSE55347.2025.00157 Repairagent: An autonomous, llm-based agent for program repair . In 47th IEEE/ACM International Conference on Software Engineering, ICSE 2025, Ottawa, ON, Canada, April 26 - May 6, 2025 , pages 2188--2200. IEEE
-
[67]
Steven L Brunton, Joshua L Proctor, and J Nathan Kutz. 2016. Discovering governing equations from data by sparse identification of nonlinear dynamical systems. Proceedings of the national academy of sciences, 113(15):3932--3937
2016
-
[68]
Manuel Camargo, Marlon Dumas, and Oscar Gonz \'a lez-Rojas. 2020. Automated discovery of business process simulation models from event logs. Decision Support Systems, 134:113284
2020
-
[69]
Mark Chen. 2021. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[70]
Xinyun Chen, Maxwell Lin, Nathanael Sch \" a rli, and Denny Zhou. 2024. https://openreview.net/forum?id=KuPixIqPiq Teaching large language models to self-debug . In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024 . OpenReview.net
2024
- [71]
-
[72]
Kyle Cranmer, Johann Brehmer, and Gilles Louppe. 2020. The frontier of simulation-based inference. Proceedings of the National Academy of Sciences, 117(48):30055--30062
2020
-
[73]
Joshua M Epstein. 1999. Agent-based computational models and generative social science. Complexity, 4(5):41--60
1999
- [74]
- [75]
-
[76]
Xiaobo Guo and Soroush Vosoughi. 2025. Serial position effects of large language models. In Findings of the Association for Computational Linguistics: ACL 2025, pages 927--953
2025
-
[77]
Samuel Holt, Max Ruiz Luyten, Antonin Berthon, and Mihaela van der Schaar. 2025. https://doi.org/10.48550/ARXIV.2506.09272 G-sim: Generative simulations with large language models and gradient-free calibration . CoRR, abs/2506.09272
-
[78]
Cheng-Yu Hsieh, Yung-Sung Chuang, Chun-Liang Li, Zifeng Wang, Long Le, Abhishek Kumar, James Glass, Alexander Ratner, Chen-Yu Lee, Ranjay Krishna, and 1 others. 2024. Found in the middle: Calibrating positional attention bias improves long context utilization. In Findings of the Association for Computational Linguistics: ACL 2024, pages 14982--14995
2024
-
[79]
Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xinying Song, and Denny Zhou. 2023. Large language models cannot self-correct reasoning yet. arXiv preprint arXiv:2310.01798
work page internal anchor Pith review arXiv 2023
- [80]
-
[81]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2023. Swe-bench: Can language models resolve real-world github issues? arXiv preprint arXiv:2310.06770
work page internal anchor Pith review arXiv 2023
- [82]
-
[83]
Taehyun Lee, Seokhee Hong, Jaewoo Ahn, Ilgee Hong, Hwaran Lee, Sangdoo Yun, Jamin Shin, and Gunhee Kim. 2024. Who wrote this code? watermarking for code generation. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 4890--4911
2024
-
[84]
Yunseo Lee, John Youngeun Song, Dongsun Kim, Jindae Kim, Mijung Kim, and Jaechang Nam. 2025. https://doi.org/10.48550/ARXIV.2504.20799 Hallucination by code generation llms: Taxonomy, benchmarks, mitigation, and challenges . CoRR, abs/2504.20799
-
[85]
Fernando Lejarza and Michael Baldea. 2022. Data-driven discovery of the governing equations of dynamical systems via moving horizon optimization. Scientific reports, 12(1):11836
2022
-
[86]
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, R \'e mi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, and 1 others. 2022. Competition-level code generation with alphacode. Science, 378(6624):1092--1097
2022
- [87]
-
[88]
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. 2023. Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation. Advances in Neural Information Processing Systems, 36:21558--21572
2023
-
[89]
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024 b . Lost in the middle: How language models use long contexts. Transactions of the Association for Computational Linguistics, 12:157--173
2024
-
[90]
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, and 1 others. 2023. Self-refine: Iterative refinement with self-feedback. Advances in Neural Information Processing Systems, 36:46534--46594
2023
-
[91]
Josie McCulloch, Jiaqi Ge, Jonathan A Ward, Alison Heppenstall, J Gareth Polhill, and Nick Malleson. 2022. Calibrating agent-based models using uncertainty quantification methods. Journal of Artificial Societies and Social Simulation, 25(2)
2022
- [92]
-
[93]
Corrado Monti, Marco Pangallo, Gianmarco De Francisci Morales, and Francesco Bonchi. 2023. On learning agent-based models from data. Scientific Reports, 13(1):9268
2023
-
[94]
Henning S. Mortveit, Stephen C. Adams, Faraz Dadgostari, Samarth Swarup, and Peter A. Beling. 2022. https://doi.org/10.48550/ARXIV.2203.11414 BESSIE: A behavior and epidemic simulator for use with synthetic populations . CoRR, abs/2203.11414
-
[95]
u ndler, Mark M \
Niels M \"u ndler, Mark M \"u ller, Jingxuan He, and Martin Vechev. 2024. Swt-bench: Testing and validating real-world bug-fixes with code agents. Advances in Neural Information Processing Systems, 37:81857--81887
2024
- [96]
-
[97]
OpenAI. 2025. Introducing gpt-5
2025
-
[98]
Charles Packer, Vivian Fang, Shishir G Patil, Kevin Lin, Sarah Wooders, and Joseph E Gonzalez. 2023. Memgpt: Towards llms as operating systems. arXiv preprint arXiv:2310.08560
work page internal anchor Pith review arXiv 2023
-
[99]
Joon Sung Park, Joseph O'Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. 2023. Generative agents: Interactive simulacra of human behavior. In Proceedings of the 36th annual acm symposium on user interface software and technology, pages 1--22
2023
-
[100]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: Language agents with verbal reinforcement learning. Advances in Neural Information Processing Systems, 36:8634--8652
2023
- [101]
-
[102]
Zhen Tan, Jun Yan, I-Hung Hsu, Rujun Han, Zifeng Wang, Long Le, Yiwen Song, Yanfei Chen, Hamid Palangi, George Lee, and 1 others. 2025. In prospect and retrospect: Reflective memory management for long-term personalized dialogue agents. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), page...
2025
-
[103]
Yuchen Tian, Weixiang Yan, Qian Yang, Xuandong Zhao, Qian Chen, Wen Wang, Ziyang Luo, Lei Ma, and Dawn Song. 2025. https://doi.org/10.1609/AAAI.V39I24.34717 Codehalu: Investigating code hallucinations in llms via execution-based verification . In AAAI-25, Sponsored by the Association for the Advancement of Artificial Intelligence, February 25 - March 4, 2...
-
[104]
Srinivasan Venkatramanan, Bryan Lewis, Jiangzhuo Chen, Dave Higdon, Anil Vullikanti, and Madhav Marathe. 2018. Using data-driven agent-based models for forecasting emerging infectious diseases. Epidemics, 22:43--49
2018
-
[105]
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. 2023. Voyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291
work page internal anchor Pith review arXiv 2023
-
[106]
Jiawei Wang, Renhe Jiang, Chuang Yang, Zengqing Wu, Makoto Onizuka, Ryosuke Shibasaki, Noboru Koshizuka, and Chuan Xiao. 2024 a . Large language models as urban residents: An llm agent framework for personal mobility generation. Advances in Neural Information Processing Systems, 37:124547--124574
2024
- [107]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.