Recognition: unknown
Hive: A Multi-Agent Infrastructure for Algorithm- and Task-Level Scaling
Pith reviewed 2026-05-10 06:28 UTC · model grok-4.3
The pith
Hive enables efficient scaling of multi-agent LLM systems by caching logits across reasoning paths and scheduling resources according to agent contributions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Hive provides a description frontend to specify per-agent behaviors and test-time scaling algorithms, paired with a backend that includes a Logits Cache for reusing intermediate logits across redundant sampling paths and an Agent-Aware Scheduling mechanism that allocates compute and KV-cache resources based on quantified agent contributions.
What carries the argument
The Logits Cache, which reuses logits from overlapping sampling paths to reduce redundancy, and Agent-Aware Scheduling, which quantifies and uses agent contributions for resource allocation.
Load-bearing premise
That logits from overlapping sampling paths can be safely reused without altering the final model outputs and that agent contributions can be quantified precisely enough to guide effective scheduling.
What would settle it
Running an experiment where logits are cached and reused but the final outputs differ from a no-cache baseline, or where the scheduling leads to higher miss rates than standard methods.
Figures






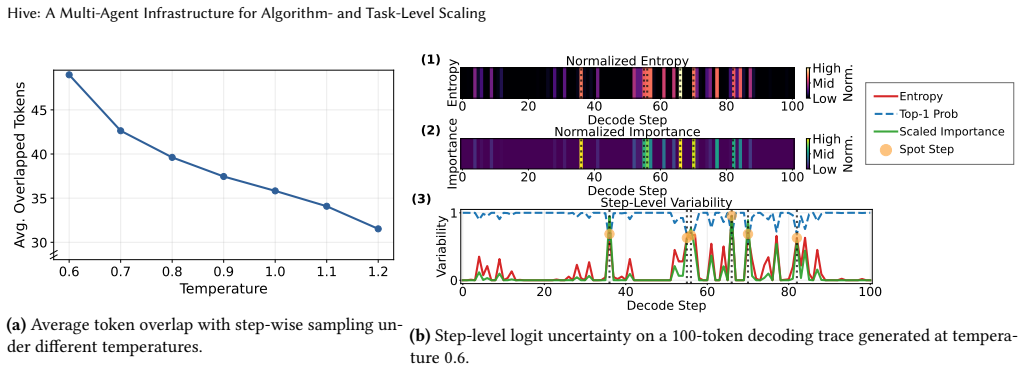


read the original abstract
Large language models are increasingly deployed as complex agentic systems that scale with task complexity. While prior work has extensively explored model- and system-level scaling, algorithm- and task-level scaling remain largely unaddressed, constraining the full potential of agentic systems. At the algorithm level, allocating additional inference-time computation can enhance workflow capacity but introduces cross-path redundancy: overlapping computations across multiple reasoning branches. At the task level, complex tasks can be decomposed into subproblems and delegated across multiple agents for improved scalability and parallelism. However, existing infrastructures' scheduling is unaware of the existence of multiple agents, missing opportunities to optimize resource allocation. We propose Hive, a multi-agent infrastructure that enables algorithm- and task-level scaling. Hive features a description frontend that captures per-agent behavior and supports test-time scaling algorithms. Leveraging this specification, our backend introduces two key mechanisms: Logits Cache that reuses intermediate logits across redundant sampling paths to mitigate cross-path redundancy at the algorithm level, and Agent-Aware Scheduling that efficiently allocates compute and KV-cache resources according to agent contributions at the task level. Experiments show that Logits Cache achieves an average speedup of $1.11\times$-$1.76\times$ for re-sampling, and Agent-Aware Scheduling reduces the hotspot miss rate by $33\%$-$51\%$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Hive, a multi-agent infrastructure for algorithm- and task-level scaling of LLM-based agentic systems. It introduces a description frontend to capture per-agent behavior and support test-time scaling, plus a backend with two mechanisms: Logits Cache, which reuses intermediate logits across redundant sampling paths to reduce cross-path computation, and Agent-Aware Scheduling, which allocates compute and KV-cache resources according to quantified agent contributions. The central empirical claims are that Logits Cache delivers 1.11×–1.76× average speedup on re-sampling and Agent-Aware Scheduling reduces hotspot miss rate by 33%–51%.
Significance. If the logits-reuse mechanism is shown to preserve output equivalence and the scheduling gains are reproducible with proper controls, the work could offer a practical infrastructure layer that improves efficiency for complex multi-agent workflows, addressing redundancy in inference-time scaling and agent-aware resource allocation where prior systems fall short.
major comments (3)
- [Logits Cache implementation] The Logits Cache mechanism (described in the backend section) claims to mitigate cross-path redundancy by reusing logits from overlapping sampling paths, yet provides no specification of prefix-identity detection, logits re-injection into the sampler, temperature/random-state handling, or any equivalence test confirming that cached paths produce identical token sequences and downstream agent outputs to the uncached baseline.
- [Experiments / Results] The experimental results reporting 1.11×–1.76× speedup for Logits Cache and 33%–51% hotspot-miss-rate reduction for Agent-Aware Scheduling contain no details on models, tasks, number of trials, baselines, statistical measures, or error bars, rendering it impossible to assess whether the numbers support the scaling claims.
- [Agent-Aware Scheduling] Agent-Aware Scheduling relies on accurate quantification of per-agent contributions for resource allocation, but the manuscript does not describe the quantification method, its sensitivity to task decomposition choices, or ablation against standard schedulers, which is load-bearing for the reported miss-rate improvement.
minor comments (2)
- [Abstract] The abstract states performance ranges without any experimental context; adding a brief clause on evaluation scale would improve clarity.
- [Notation and figures] Ensure consistent terminology for 'KV-cache' and 'logits' across sections and figures.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and will revise the paper to incorporate the requested clarifications and additional details.
read point-by-point responses
-
Referee: [Logits Cache implementation] The Logits Cache mechanism (described in the backend section) claims to mitigate cross-path redundancy by reusing logits from overlapping sampling paths, yet provides no specification of prefix-identity detection, logits re-injection into the sampler, temperature/random-state handling, or any equivalence test confirming that cached paths produce identical token sequences and downstream agent outputs to the uncached baseline.
Authors: We agree that the current description is high-level and lacks these critical implementation specifics. In the revised manuscript, we will expand the backend section with a detailed account of prefix-identity detection via KV-cache prefix matching, the logits re-injection logic into the sampler, explicit handling of temperature and random states to preserve determinism, and results from equivalence tests confirming identical token sequences and downstream agent outputs between cached and baseline paths. revision: yes
-
Referee: [Experiments / Results] The experimental results reporting 1.11×–1.76× speedup for Logits Cache and 33%–51% hotspot-miss-rate reduction for Agent-Aware Scheduling contain no details on models, tasks, number of trials, baselines, statistical measures, or error bars, rendering it impossible to assess whether the numbers support the scaling claims.
Authors: We acknowledge that the experimental reporting is insufficient for full reproducibility and evaluation. The revised version will include comprehensive details on the models evaluated, the specific tasks and benchmarks used, the number of trials per configuration, the baselines employed, and statistical measures including standard deviations and error bars to support the reported speedups and miss-rate reductions. revision: yes
-
Referee: [Agent-Aware Scheduling] Agent-Aware Scheduling relies on accurate quantification of per-agent contributions for resource allocation, but the manuscript does not describe the quantification method, its sensitivity to task decomposition choices, or ablation against standard schedulers, which is load-bearing for the reported miss-rate improvement.
Authors: We recognize that the quantification method and supporting analyses are not adequately described. In the revision, we will add a detailed explanation of the per-agent contribution quantification (combining static task analysis and dynamic profiling), sensitivity analysis to variations in task decomposition, and ablations against standard schedulers such as FIFO and shortest-job-first to substantiate the hotspot miss-rate improvements. revision: yes
Circularity Check
No circularity: empirical infrastructure paper with no derivations or fitted predictions
full rationale
The paper describes a new multi-agent infrastructure (Hive) featuring Logits Cache and Agent-Aware Scheduling, then reports empirical speedups (1.11×–1.76×) and miss-rate reductions (33%–51%) from experiments. No mathematical derivation chain, first-principles predictions, parameter fitting, or self-citation load-bearing steps exist. Claims rest on direct measurements of implemented components rather than any reduction of outputs to inputs by construction. This is self-contained engineering work; the reader's circularity score of 1.0 aligns with the absence of any load-bearing circular pattern.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Intermediate logits from LLM inference can be cached and reused across multiple reasoning paths without affecting the final output quality.
- domain assumption Agent contributions to task completion can be quantified to guide resource allocation in scheduling.
invented entities (3)
-
Hive infrastructure
no independent evidence
-
Logits Cache
no independent evidence
-
Agent-Aware Scheduling
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Gulavani, Alexey Tumanov, and Ramachandran Ramjee
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav S. Gulavani, Alexey Tumanov, and Ramachandran Ramjee. 2024. Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve. arXiv:2403.02310 [cs.LG]https://arxiv.org/abs/ 2403.02310
-
[2]
anomalyco. 2026. anomalyco/opencode: The open source AI coding agent.https://github.com/anomalyco/opencode. GitHub repository, accessed 2026-03-24
2026
-
[3]
Zhenni Bi, Kai Han, Chuanjian Liu, Yehui Tang, and Yunhe Wang
- [4]
- [5]
-
[6]
Hao Mark Chen, Zhiwen Mo, Guanxi Lu, Shuang Liang, Lingxiao Ma, Wayne Luk, and Hongxiang Fan. 2026. FastTTS: Accelerating Test-Time Scaling for Edge LLM Reasoning. InProceedings of the 31st ACM International Conference on Architectural Support for Program- ming Languages and Operating Systems, Volume 2(USA)(ASPLOS ’26). Association for Computing Machinery...
-
[7]
Mengzhao Chen, Wenqi Shao, Peng Xu, Jiahao Wang, Peng Gao, Kaipeng Zhang, and Ping Luo. 2025. EfficientQAT: Efficient Quantization-Aware Training for Large Language Models. InProceed- ings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Vienna, Austria, 10081–1...
2025
-
[8]
Renze Chen, Zhuofeng Wang, Beiquan Cao, Tong Wu, Size Zheng, Xiuhong Li, Xuechao Wei, Shengen Yan, Meng Li, and Yun Liang. 2024. ArkVale: Efficient Generative LLM Inference with Recallable Key- Value Eviction. InAdvances in Neural Information Processing Systems 37 (NeurIPS 2024).https://doi.org/10.52202/079017-3595
-
[9]
Yuheng Cheng, Ceyao Zhang, Zhengwen Zhang, Xiangrui Meng, Sirui Hong, Wenhao Li, Zihao Wang, Zekai Wang, Feng Yin, Jun- hua Zhao, and Xiuqiang He. 2024. Exploring Large Language Model based Intelligent Agents: Definitions, Methods, and Prospects. arXiv:2401.03428 [cs.AI]https://arxiv.org/abs/2401.03428
- [10]
-
[11]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Henni- gan, Eric Noland, Katie Millican, George van den Driessche, Bog- dan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Jack W. Rae, Oriol Vinyals, and L. Sifre....
work page internal anchor Pith review arXiv 2022
-
[12]
Junyan Hu, Parijat Bhowmick, Inmo Jang, Farshad Arvin, and Alexan- der Lanzon. 2021. A Decentralized Cluster Formation Containment Framework for Multirobot Systems.IEEE Transactions on Robotics37, 6 (2021), 1936–1955.https://doi.org/10.1109/TRO.2021.3071615
- [13]
-
[14]
Sam Ade Jacobs, Masahiro Tanaka, Chengming Zhang, Minjia Zhang, Shuaiwen Leon Song, Samyam Rajbhandari, and Yuxiong He
-
[15]
Deepspeed ulysses: System optimizations for enabling train- ing of extreme long sequence transformer models.arXiv preprint arXiv:2309.14509(2023)
work page internal anchor Pith review arXiv 2023
-
[16]
Hao Kang, Ziyang Li, Xinyu Yang, Weili Xu, Yinfang Chen, Junxiong Wang, Beidi Chen, Tushar Krishna, Chenfeng Xu, and Simran Arora
- [17]
-
[18]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Thomas Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeff Wu, and Dario Amodei. 2020. Scaling Laws for Neural Language Models.ArXiv abs/2001.08361 (2020).https://api.semanticscholar.org/CorpusID: 210861095
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[19]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica
-
[20]
InProceedings of the 29th symposium on operating systems principles
Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles. 611–626
-
[21]
Chengpeng Li, Mingfeng Xue, Zhenru Zhang, Jiaxi Yang, Beichen Zhang, Bowen Yu, Binyuan Hui, Junyang Lin, Xiang Wang, and Dayi- heng Liu. 2025. Start: Self-taught reasoner with tools. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Pro- cessing. 13523–13564
2025
-
[22]
Xinyi Li, Sai Wang, Siqi Zeng, Yu Wu, and Yi Yang. 2024. A survey on LLM-based multi-agent systems: workflow, infrastructure, and challenges.Vicinagearth1, 1 (2024), 9.https://doi.org/10.1007/s44336- 024-00009-2
-
[23]
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al. 2025. Deepseek-v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556(2025)
work page internal anchor Pith review arXiv 2025
-
[24]
Hao Liu, Matei Zaharia, and Pieter Abbeel. 2023. Ring attention with blockwise transformers for near-infinite context.arXiv preprint arXiv:2310.01889(2023). 12 Hive: A Multi-Agent Infrastructure for Algorithm- and Task-Level Scaling
work page internal anchor Pith review arXiv 2023
- [25]
-
[26]
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Kather- ine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark
-
[27]
InThirty- seventh Conference on Neural Information Processing Systems.https: //openreview.net/forum?id=S37hOerQLB
Self-Refine: Iterative Refinement with Self-Feedback. InThirty- seventh Conference on Neural Information Processing Systems.https: //openreview.net/forum?id=S37hOerQLB
-
[28]
Moonshot AI. 2026. Kimi Code: Next-Gen AI Code Agent | Automated Programming & CLI.https://www.kimi.com/codeAccessed: 2026-04- 15
2026
-
[29]
nlile. 2026. 24-game.https://huggingface.co/datasets/nlile/24-game Accessed: 2026-04-11
2026
-
[30]
OpenAI. 2025. Introducing GPT-5.4.https://openai.com/index/ introducing-gpt-5-4/. Accessed: 2026-04-15
2025
-
[31]
openclaw. 2026. openclaw/openclaw: Your own personal AI assistant. Any OS. Any Platform. The lobster way.https://github.com/openclaw/ openclaw. GitHub repository, accessed 2026-03-24
2026
- [32]
-
[33]
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. 2024. Splitwise: Efficient generative llm inference using phase splitting. In2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA). IEEE, 118–132
2024
-
[34]
Qwen Team. [n. d.].Qwen3-Coder-Next Technical Report. Technical Re- port.https://github.com/QwenLM/Qwen3-Coder/blob/main/qwen3_ coder_next_tech_report.pdfAccessed: 2026-02-03
2026
- [35]
-
[36]
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. 2026. Kimi K2. 5: Visual Agentic Intelligence.arXiv preprint arXiv:2602.02276(2026)
work page internal anchor Pith review arXiv 2026
-
[37]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. At- tention Is All You Need.CoRRabs/1706.03762 (2017). arXiv:1706.03762 http://arxiv.org/abs/1706.03762
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[38]
Junlin Wang, Jue WANG, Ben Athiwaratkun, Ce Zhang, and James Zou
-
[39]
InThe Thirteenth International Conference on Learning Representations
Mixture-of-Agents Enhances Large Language Model Capabilities. InThe Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=h0ZfDIrj7T
-
[40]
Yongtong Wu, Shaoyuan Chen, Yinmin Zhong, Rilin Huang, Yixuan Tan, Wentao Zhang, Liyue Zhang, Shangyan Zhou, Yuxuan Liu, Shun- feng Zhou, Mingxing Zhang, Xin Jin, and Panpan Huang. 2026. Du- alPath: Breaking the Storage Bandwidth Bottleneck in Agentic LLM Inference. arXiv:2602.21548 [cs.DC]https://arxiv.org/abs/2602.21548
-
[41]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. Tree of thoughts: Deliberate problem solving with large language models.Advances in neural information processing systems36 (2023), 11809–11822
2023
-
[43]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations
2022
- [44]
-
[45]
Qiyuan Zhang, Fuyuan Lyu, Zexu Sun, Lei Wang, Weixu Zhang, Wenyue Hua, Haolun Wu, Zhihan Guo, Yufei Wang, Niklas Muen- nighoff, et al . 2025. A survey on test-time scaling in large lan- guage models: What, how, where, and how well?arXiv preprint arXiv:2503.24235(2025)
work page internal anchor Pith review arXiv 2025
-
[46]
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody H Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. 2024. Sglang: Efficient execution of structured lan- guage model programs.Advances in neural information processing systems37 (2024), 62557–62583
2024
-
[47]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xu- anzhe Liu, Xin Jin, and Hao Zhang. 2024. {DistServe}: Disaggregating prefill and decoding for goodput-optimized large language model serving. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 193–210. 13
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.