Recognition: unknown
Think before Go: Hierarchical Reasoning for Image-goal Navigation
Pith reviewed 2026-05-10 05:39 UTC · model grok-4.3
The pith
Hierarchical vision-language planning plus reinforcement learning execution reaches distant image-specified goals without wandering.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
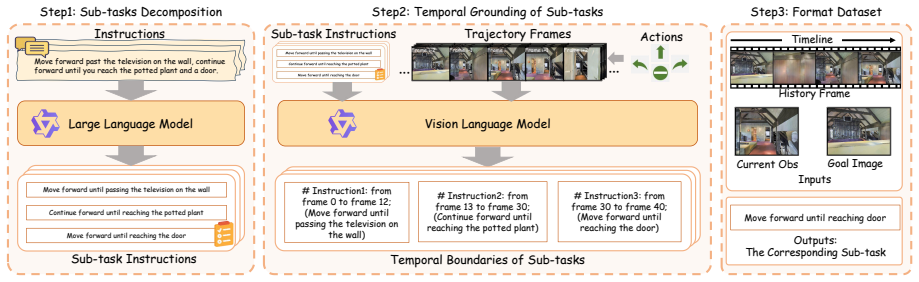
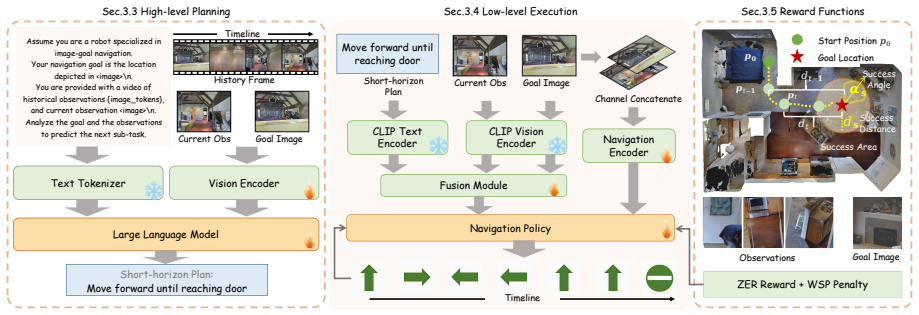
HRNav decomposes image-goal navigation into high-level planning, where a vision-language model trained on a self-collected dataset generates short-horizon plans, and low-level execution, where an online reinforcement learning policy selects actions conditioned on those plans, together with a Wandering Suppression Penalty that reduces wandering behavior.
What carries the argument
The HRNav hierarchical framework that uses a vision-language model to output short-horizon plans and conditions a reinforcement learning execution policy on those plans.
If this is right
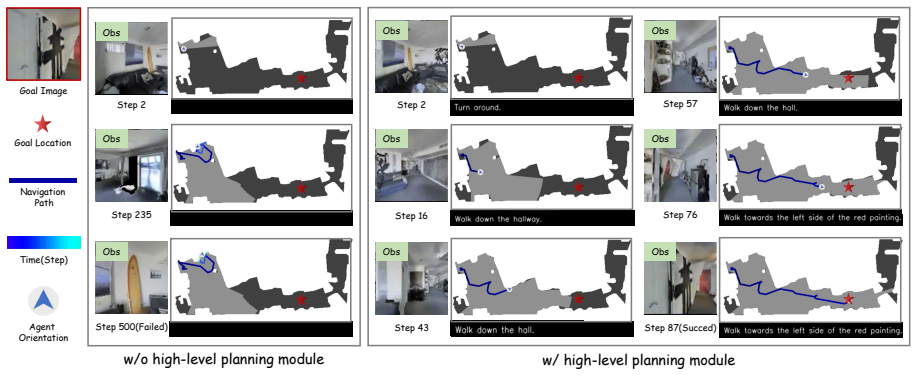
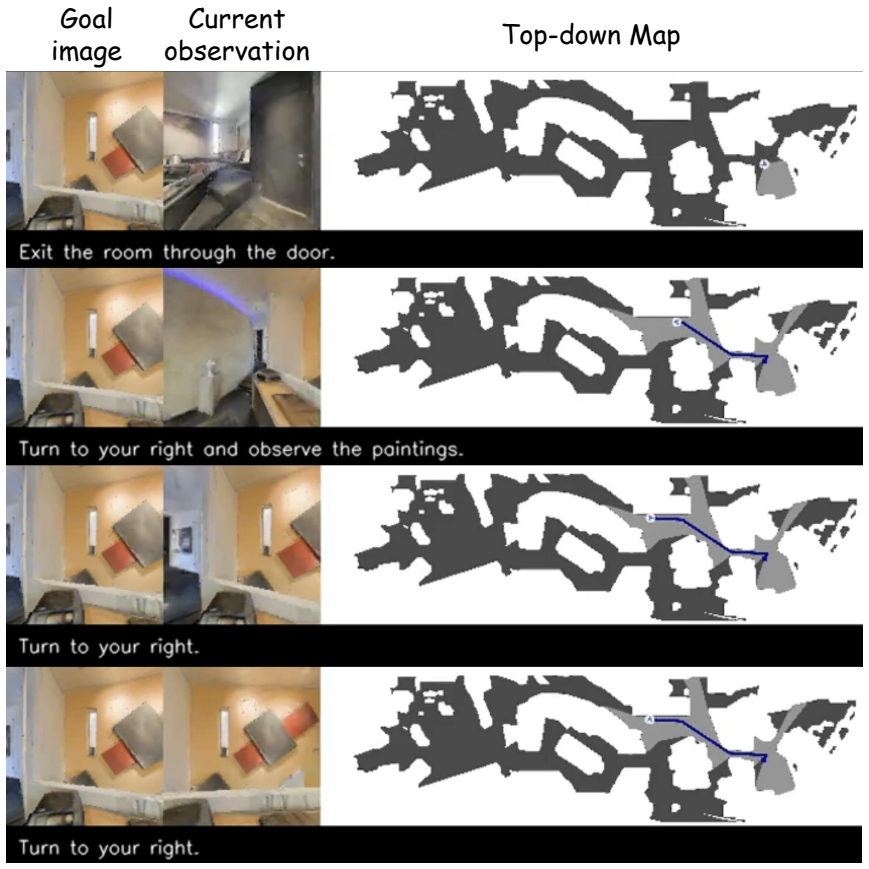
- Distant targets become reachable because intermediate plans supply visual and directional cues the low-level policy can follow.
- The reinforcement learning policy can focus on immediate action selection without solving the full long-term task.
- Wandering is suppressed because the penalty term discourages loops and inefficient movement.
- The same decomposition works in both simulated indoor environments and on physical robots.
Where Pith is reading between the lines
- The same high-level planning step could be reused for other long-horizon embodied tasks such as object rearrangement or search.
- Replacing the current vision-language model with a stronger one would likely produce even more accurate short plans and higher success rates.
- Adding explicit memory of past plans could further reduce repeated mistakes in partially observed spaces.
Load-bearing premise
A vision-language model trained on the authors' self-collected dataset can reliably generate short-horizon plans that meaningfully reduce the difficulty of the long-horizon navigation task.
What would settle it
Navigation success rates that remain unchanged or decline when the vision-language planner is replaced by random or null plans would falsify the claim that the high-level reasoning component is what enables better performance.
Figures





read the original abstract
Image-goal navigation steers an agent to a target location specified by an image in unseen environments. Existing methods primarily handle this task by learning an end-to-end navigation policy, which compares the similarities of target and observation images and directly predicts the actions. However, when the target is distant or lies in another room, such methods fail to extract informative visual cues, leading the agent to wander around. Motivated by the human cognitive principle that deliberate, high-level reasoning guides fast, reactive execution in complex tasks, we propose Hierarchical Reasoning Navigation (HRNav), a framework that decomposes image-goal navigation into high-level planning and low-level execution. In high-level planning, a vision-language model is trained on a self-collected dataset to generate a short-horizon plan, such as whether the agent should walk through the door or down the hallway. This downgrades the difficulty of the long-horizon task, making it more amenable to the execution part. In low-level execution, an online reinforcement learning policy is utilized to decide actions conditioned on the short-horizon plan. We also devise a novel Wandering Suppression Penalty (WSP) to further reduce the wandering problem. Together, these components form a hierarchical framework for Image-Goal Navigation. Extensive experiments in both simulation and real-world environments demonstrate the superiority of our method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Hierarchical Reasoning Navigation (HRNav) for image-goal navigation in unseen environments. It decomposes the task into high-level planning via a vision-language model (VLM) trained on a self-collected dataset to output short-horizon plans (e.g., walk through a door), low-level execution via an online RL policy conditioned on those plans, and a Wandering Suppression Penalty (WSP) to curb wandering behavior. The central claim is that this hierarchical decomposition outperforms end-to-end policies, with supporting evidence from simulation and real-world experiments.
Significance. If the results hold, the work offers a concrete way to inject high-level visual reasoning into navigation policies, which could improve robustness on long-horizon image-goal tasks where pure end-to-end RL tends to wander. The explicit separation of planning and execution, together with the WSP term, is a practical contribution that aligns with cognitive principles and may generalize to other embodied tasks.
major comments (3)
- [Abstract] Abstract: the superiority claim ('extensive experiments... demonstrate the superiority of our method') is presented without any quantitative metrics, baseline comparisons, success rates, or SPL values. This is load-bearing because the motivation section explicitly contrasts the method against end-to-end policies that fail on distant targets.
- [Method] Method section (high-level planning): the claim that VLM-generated short-horizon plans 'downgrade the difficulty of the long-horizon task' rests on an unverified assumption that the plans generalize beyond the self-collected dataset. No plan accuracy, coverage, or out-of-distribution metrics are referenced, leaving open the possibility that the hierarchy provides no benefit and the method reduces to RL plus WSP.
- [Experiments] Experiments: without ablation results that isolate the VLM planning component from the WSP term (e.g., RL+WSP vs. full HRNav), it is impossible to attribute performance gains to the hierarchical reasoning rather than the penalty alone.
minor comments (2)
- Define all acronyms at first use (WSP, VLM, SPL if used) and ensure consistent capitalization of 'image-goal navigation'.
- [Experiments] The real-world experiment description should specify the robot platform, sensor suite, and how the self-collected dataset was gathered to allow reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below. Revisions have been made to the manuscript to incorporate the suggestions where feasible.
read point-by-point responses
-
Referee: [Abstract] Abstract: the superiority claim ('extensive experiments... demonstrate the superiority of our method') is presented without any quantitative metrics, baseline comparisons, success rates, or SPL values. This is load-bearing because the motivation section explicitly contrasts the method against end-to-end policies that fail on distant targets.
Authors: We agree that the abstract would be strengthened by including specific quantitative results. The revised abstract now reports key metrics including success rate and SPL from both simulation and real-world experiments, along with direct comparisons to end-to-end baselines to support the superiority claim. revision: yes
-
Referee: [Method] Method section (high-level planning): the claim that VLM-generated short-horizon plans 'downgrade the difficulty of the long-horizon task' rests on an unverified assumption that the plans generalize beyond the self-collected dataset. No plan accuracy, coverage, or out-of-distribution metrics are referenced, leaving open the possibility that the hierarchy provides no benefit and the method reduces to RL plus WSP.
Authors: The self-collected dataset was designed to capture a range of common indoor navigation scenarios to support generalization. Overall experimental gains over end-to-end policies provide indirect evidence of the planning component's value. In the revision we have added a dedicated discussion subsection on plan generalization along with qualitative examples of generated plans to clarify how they reduce long-horizon complexity. revision: partial
-
Referee: [Experiments] Experiments: without ablation results that isolate the VLM planning component from the WSP term (e.g., RL+WSP vs. full HRNav), it is impossible to attribute performance gains to the hierarchical reasoning rather than the penalty alone.
Authors: We acknowledge that explicit ablations are necessary for clear attribution of gains. The revised experiments section now includes new ablation studies comparing the full HRNav against an RL+WSP baseline (without VLM planning) to isolate the contribution of the hierarchical reasoning component. revision: yes
Circularity Check
No circularity in hierarchical decomposition or experimental claims
full rationale
The paper's core contribution is a design choice to decompose image-goal navigation into a VLM-based short-horizon planner (trained on a self-collected dataset) and an RL executor augmented by a novel Wandering Suppression Penalty. No equations, fitted parameters, or predictions are shown to reduce by construction to their own inputs; the short-horizon plans are generated outputs rather than tautological re-labelings of training data. No self-citations are invoked as load-bearing uniqueness theorems or to smuggle in ansatzes. Experimental superiority is asserted via independent simulation and real-world evaluations rather than internal consistency alone, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Human cognitive principle that deliberate high-level reasoning guides fast reactive execution in complex tasks
- domain assumption Vision-language model trained on self-collected dataset generates useful short-horizon plans
invented entities (1)
-
Wandering Suppression Penalty (WSP)
no independent evidence
Forward citations
Cited by 1 Pith paper
-
SpaAct: Spatially-Activated Transition Learning with Curriculum Adaptation for Vision-Language Navigation
SpaAct activates spatial awareness in VLMs using action retrospection, future frame prediction, and progressive curriculum learning to reach SOTA on VLN-CE benchmarks.
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education
Clancey, William J. Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education. Proceedings of the Eighth International Joint Conference on Artificial Intelligence (IJCAI-83)
-
[9]
Classification Problem Solving
Clancey, William J. Classification Problem Solving. Proceedings of the Fourth National Conference on Artificial Intelligence
-
[10]
, title =
Robinson, Arthur L. , title =. 1980 , doi =. https://science.sciencemag.org/content/208/4447/1019.full.pdf , journal =
1980
-
[11]
New Ways to Make Microcircuits Smaller---Duplicate Entry
Robinson, Arthur L. New Ways to Make Microcircuits Smaller---Duplicate Entry. Science
-
[12]
Clancey and Glenn Rennels , abstract =
Diane Warner Hasling and William J. Clancey and Glenn Rennels , abstract =. Strategic explanations for a diagnostic consultation system , journal =. 1984 , issn =. doi:https://doi.org/10.1016/S0020-7373(84)80003-6 , url =
-
[13]
and Rennels, Glenn R
Hasling, Diane Warner and Clancey, William J. and Rennels, Glenn R. and Test, Thomas. Strategic Explanations in Consultation---Duplicate. The International Journal of Man-Machine Studies
-
[14]
Poligon: A System for Parallel Problem Solving
Rice, James. Poligon: A System for Parallel Problem Solving
-
[15]
Transfer of Rule-Based Expertise through a Tutorial Dialogue
Clancey, William J. Transfer of Rule-Based Expertise through a Tutorial Dialogue
-
[16]
The Engineering of Qualitative Models
Clancey, William J. The Engineering of Qualitative Models
-
[17]
2017 , eprint=
Attention Is All You Need , author=. 2017 , eprint=
2017
-
[18]
Pluto: The 'Other' Red Planet
NASA. Pluto: The 'Other' Red Planet
-
[19]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Towards learning a generalist model for embodied navigation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[20]
2020 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Look, listen, and act: Towards audio-visual embodied navigation , author=. 2020 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2020 , organization=
2020
-
[21]
MobileVLA-R1: Reinforcing Vision-Language-Action for Mobile Robots , author=. arXiv preprint arXiv:2511.17889 , year=
-
[22]
Vln-r1: Vision-language navigation via reinforcement fine-tuning.arXiv preprint arXiv:2506.17221,
VLN-R1: Vision-Language Navigation via Reinforcement Fine-Tuning , author=. arXiv preprint arXiv:2506.17221 , year=
-
[23]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Navigating to objects specified by images , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[24]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
CAVEN: An Embodied Conversational Agent for Efficient Audio-Visual Navigation in Noisy Environments , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[25]
Advances in Neural Information Processing Systems , volume=
FGPrompt: fine-grained goal prompting for image-goal navigation , author=. Advances in Neural Information Processing Systems , volume=
-
[26]
arXiv preprint arXiv:2405.14128 , year=
Transformers for Image-Goal Navigation , author=. arXiv preprint arXiv:2405.14128 , year=
-
[27]
Advances in Neural Information Processing Systems , volume=
Zson: Zero-shot object-goal navigation using multimodal goal embeddings , author=. Advances in Neural Information Processing Systems , volume=
-
[28]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
OVER-NAV: Elevating Iterative Vision-and-Language Navigation with Open-Vocabulary Detection and StructurEd Representation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[29]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Lookahead Exploration with Neural Radiance Representation for Continuous Vision-Language Navigation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[30]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Renderable neural radiance map for visual navigation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[31]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Improving vision-and-language navigation by generating future-view image semantics , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[32]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Scaling data generation in vision-and-language navigation , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[33]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Kerm: Knowledge enhanced reasoning for vision-and-language navigation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[34]
Conference on Robot Learning , pages=
Vision-and-dialog navigation , author=. Conference on Robot Learning , pages=. 2020 , organization=
2020
-
[35]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
DiaLoc: An Iterative Approach to Embodied Dialog Localization , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[36]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Zero experience required: Plug & play modular transfer learning for semantic visual navigation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[37]
2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=
Memory-augmented reinforcement learning for image-goal navigation , author=. 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=. 2022 , organization=
2022
-
[38]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Curious representation learning for embodied intelligence , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[39]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
MemoNav: Working Memory Model for Visual Navigation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[40]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Hop: History-and-order aware pre-training for vision-and-language navigation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[41]
Conference on Robot Learning , pages=
Topological semantic graph memory for image-goal navigation , author=. Conference on Robot Learning , pages=. 2023 , organization=
2023
-
[42]
Advances in Neural Information Processing Systems , volume=
Avlen: Audio-visual-language embodied navigation in 3d environments , author=. Advances in Neural Information Processing Systems , volume=
-
[43]
2017 IEEE international conference on robotics and automation (ICRA) , pages=
Target-driven visual navigation in indoor scenes using deep reinforcement learning , author=. 2017 IEEE international conference on robotics and automation (ICRA) , pages=. 2017 , organization=
2017
-
[44]
Workshop on Reincarnating Reinforcement Learning at ICLR 2023 , year=
Offline visual representation learning for embodied navigation , author=. Workshop on Reincarnating Reinforcement Learning at ICLR 2023 , year=
2023
-
[45]
Computer Vision and Pattern Recognition (CVPR), 2018 IEEE Conference on , year=
Gibson env: real-world perception for embodied agents , author=. Computer Vision and Pattern Recognition (CVPR), 2018 IEEE Conference on , year=
2018
-
[46]
Conference on Robot Learning , pages=
Last-mile embodied visual navigation , author=. Conference on Robot Learning , pages=. 2023 , organization=
2023
-
[47]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Neural topological slam for visual navigation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[48]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Instance-aware Exploration-Verification-Exploitation for Instance ImageGoal Navigation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[49]
Advances in Neural Information Processing Systems , volume=
No rl, no simulation: Learning to navigate without navigating , author=. Advances in Neural Information Processing Systems , volume=
-
[50]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Habitat: A platform for embodied ai research , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[51]
Advances in neural information processing systems , volume=
Habitat 2.0: Training home assistants to rearrange their habitat , author=. Advances in neural information processing systems , volume=
-
[52]
Matterport3D: Learning from RGB-D Data in Indoor Environments
Matterport3d: Learning from rgb-d data in indoor environments , author=. arXiv preprint arXiv:1709.06158 , year=
-
[53]
Habitat-Matterport 3D Dataset (HM3D): 1000 Large-scale 3D Environments for Embodied AI
Habitat-matterport 3d dataset (hm3d): 1000 large-scale 3d environments for embodied ai , author=. arXiv preprint arXiv:2109.08238 , year=
work page internal anchor Pith review arXiv
-
[54]
On Evaluation of Embodied Navigation Agents
On evaluation of embodied navigation agents , author=. arXiv preprint arXiv:1807.06757 , year=
work page internal anchor Pith review arXiv
-
[55]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Visual graph memory with unsupervised representation for visual navigation , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[56]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Li, Hongxin and Wang, Zeyu and Yang, Xu and Yang, Yuran and Mei, Shuqi and Zhang, Zhaoxiang , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2024 , pages =
2024
-
[57]
Ovrl-v2: A simple state-of-art baseline for imagenav and objectnav
Ovrl-v2: A simple state-of-art baseline for imagenav and objectnav , author=. arXiv preprint arXiv:2303.07798 , year=
-
[58]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Segment anything , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[59]
2021 , url=
Dhruv Shah and Benjamin Eysenbach and Gregory Kahn and Nicholas Rhinehart and Sergey Levine , booktitle=. 2021 , url=
2021
-
[60]
Conference on Robot Learning , pages=
Rapid Exploration for Open-World Navigation with Latent Goal Models , author=. Conference on Robot Learning , pages=. 2022 , organization=
2022
-
[61]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Deep residual learning for image recognition , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[62]
2009 IEEE conference on computer vision and pattern recognition , pages=
Imagenet: A large-scale hierarchical image database , author=. 2009 IEEE conference on computer vision and pattern recognition , pages=. 2009 , organization=
2009
-
[63]
Proceedings of the national academy of sciences , volume=
Maps of random walks on complex networks reveal community structure , author=. Proceedings of the national academy of sciences , volume=. 2008 , publisher=
2008
-
[64]
Proceedings of the Asian conference on computer vision , pages=
Cluster contrast for unsupervised person re-identification , author=. Proceedings of the Asian conference on computer vision , pages=
-
[65]
Advances in Neural Information Processing Systems , volume=
Object goal navigation using goal-oriented semantic exploration , author=. Advances in Neural Information Processing Systems , volume=
-
[66]
Advances in neural information processing systems , volume=
History aware multimodal transformer for vision-and-language navigation , author=. Advances in neural information processing systems , volume=
-
[67]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[68]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Object-goal visual navigation via effective exploration of relations among historical navigation states , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[69]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Imagine Before Go: Self-Supervised Generative Map for Object Goal Navigation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[70]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Towards learning a generic agent for vision-and-language navigation via pre-training , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[71]
IEEE robotics & automation magazine , volume=
Simultaneous localization and mapping: part I , author=. IEEE robotics & automation magazine , volume=. 2006 , publisher=
2006
-
[72]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Iterative vision-and-language navigation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[73]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Envedit: Environment editing for vision-and-language navigation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[74]
ArXiv , year=
Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling , author=. ArXiv , year=
-
[75]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Visual navigation with spatial attention , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[76]
Dd-ppo: Learning near-perfect pointgoal navigators from 2.5 billion frames
Dd-ppo: Learning near-perfect pointgoal navigators from 2.5 billion frames , author=. arXiv preprint arXiv:1911.00357 , year=
-
[77]
Adam: A Method for Stochastic Optimization
Adam: A method for stochastic optimization , author=. arXiv preprint arXiv:1412.6980 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[78]
European Conference on Computer Vision , pages=
Prioritized semantic learning for zero-shot instance navigation , author=. European Conference on Computer Vision , pages=. 2025 , organization=
2025
-
[79]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
REGNav: Room Expert Guided Image-Goal Navigation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[80]
2025 IEEE International Conference on Robotics and Automation (ICRA) , pages=
LiteVLoc: Map-lite visual localization for image goal navigation , author=. 2025 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2025 , organization=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.